版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
Flink是处理unbounded和bounded data的分布式的计算引擎,擅长batch和stream的处理方式(spark更擅长batch的方式,spark streaming的本质也是微批的处理方式,所以实时性spark比flink要差一些),具有内存计算的速度,可以部署Yarn,Mesos集群上。
Flink的特性
- batch & stream process
- state management
- event-time
- exactly-once consistency guarantees for state
Unbounded & Bounded data
先上图:
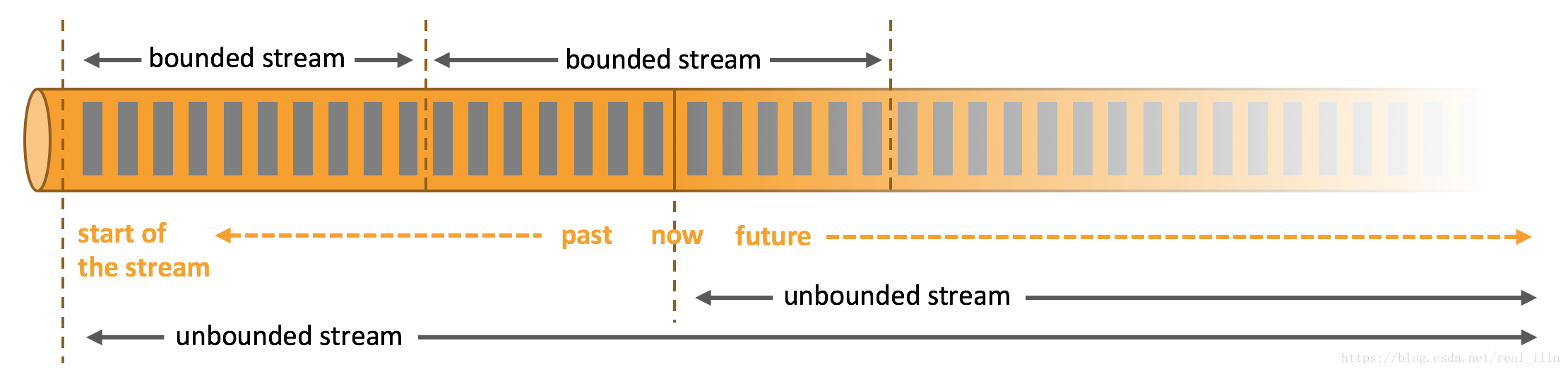
- unbounded data
无界数据,只定义了开始没有定义结束,数据就像长江的流水一样源源不断的注入大海。所以对于吃入的数据必须迅速的处理,不能等到所有的数据收集完再处理(当然也收集不完)。处理无界数据必须要有一定的顺序,比如数据产生的时间等。 - bounded data
有界数据,定义了开始和结束。往往是已经存在的数据集,比如在数据库中存储的数据。处理数据时没有必要按照顺序读入。可以用批处理的方式处理。
部署模式
是计算引擎就需要计算资源(CPU,内存),Flink 可以与Hadoop Yarn, Apache Mesos, Kubernetes等资源管理的集群集成,也可以使用standalone模式。当运行一个Flink应用时,Flink会自动计算应用所需要的并行度和需要的内存资源,并向Resource Manager申请资源,如果申请失败则会重新申请。
- Hadoop Yarn
- Apache Mesos
- Kubernetes
- Standalone
运行规模
- 多个task并行执行;
- 使用异步和递增的checkpoint机制保存应用的运行状态;
- 在最小程序影响处理量的基础上确保exactly-once语意;
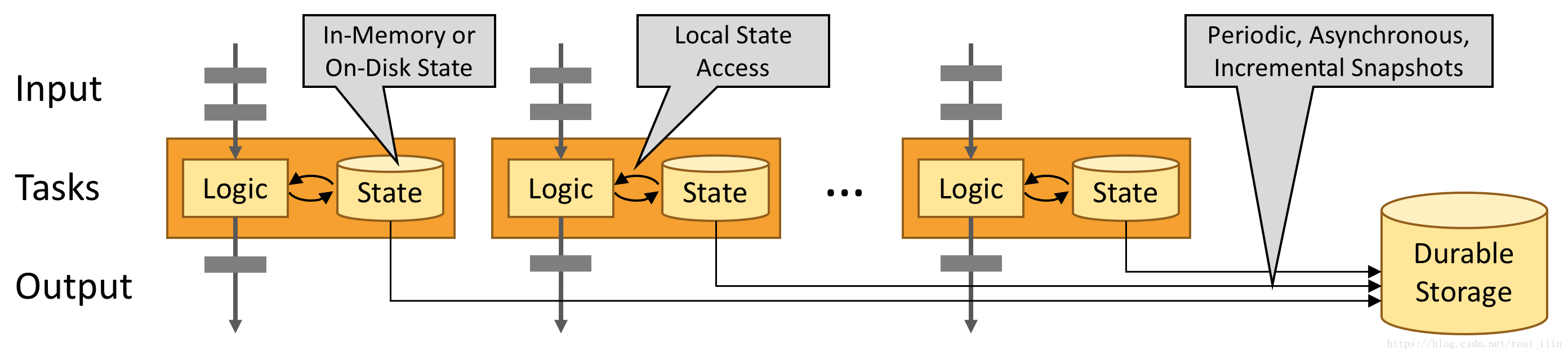
运行时如果内存存不下task的state时,会保存在磁盘上,如下图:
Application types
- Event-driven Applications
- Data Analytics Applications
- Data Pipeline Applications