什么是flink? 刚接触这个词的同学 可能会觉得比较难懂,网上搜教程 也是一套一套的官话, 如果大家熟悉stream流,那或许会比较好理解 就是流式处理。博主也是刚学习,简单做了个入门小结,后续学习 文章也会不断完善
通俗解释什么是flink及其应用场景
flink是一个流式处理框架,且高性能。说通俗点就是把数据转成流的形式进行处理,可以在多进程中执行,而且是分布式架构 支持集群部署
那么实际应用场景是怎么样的呢?还是通俗点举例,我们可以将文本文件中的内容,通过flink流式读取、统计等操作,这是最基础的操作;也可以监听服务器端口,不断从端口获取数据 并进行处理;还可以把消息队列中的消息进行读取; 此外,用于IOT场景也是没有问题的。比如某社交网站,要实时统计点赞排行榜,就可以通过flink进行处理。换句话说,有数据的地方,都可以用flink处理。
flink是基于内存的,所以高效;
与大多数组件一样,内存不安全,所以会有持久化的功能 checkPoint
flink本身就是为大数据服务的,所以避免宕机风险 能够支持集群部署
当然 杀鸡焉用牛刀 ,flink一般是在大数据量的情况下,才会使用的。
flink处理流程及核心API
在此之前,我们看看在flink出现之前的上一代架构:
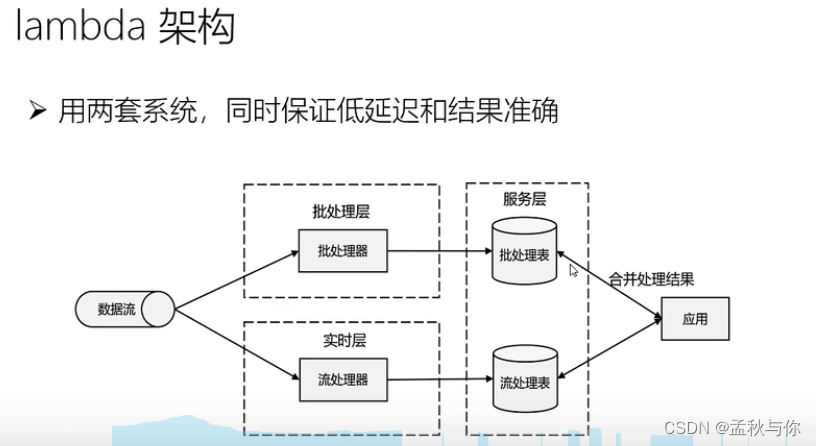
批处理:有序 低速
流处理:无序 高速
lambda架构是有两套处理方式的,而flink的出现,可以实现批流处理。
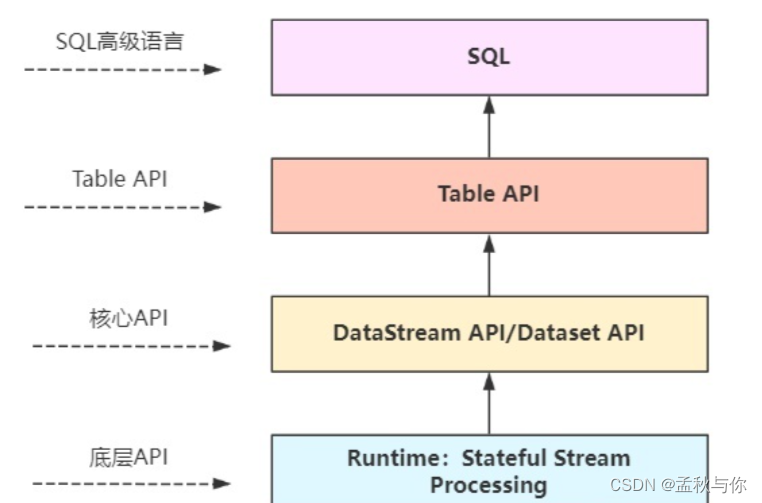
flink的四层API
- 流处理和批处理 都是基于DataStream和DataSet
- 早期flink批处理都是基于DataSet API ,在1.12版本开始 统一使用 DataStream 就可实现批流处理
flink代码快速入门
下面快速入门 在springboot环境中flink的应用 , 注意导包不要导错了。
我们的demo业务场景是 统计words.txt中 每个单词出现的次数。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
/**
* DataSet API 批处理 (有序 低速)
*
*/
/**
* flink 分层api
*
* SQL 最高层语言
* table API 声明式领域专用语言
* DataStream / DataSet API 核心Apis
* (流处理和批处理 基于这两者 早期flink批处理都是基于DataSet API 在1.12版本开始 统一使用 DataStream 就可实现批流处理)
* 有状态流处理 底层APIs
*/
@RestController
public class DataSetAPIBatchWordCount {
@PostConstruct
public void test() throws Exception {
// 1. 创建一个执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件中读取数据
// 继承自Operator Operator 继承自DataSet , DataSource基于DataSet
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
// 3. 逻辑处理: 将每行数据进行分词 转换成二元组类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap(
// 将每行打散 放到一个收集器里
(String line, Collector<Tuple2<String, Long>> out) -> {
// 将一行文本进行分词
String[] words = line.split(" ");
// 将每个单词转换成二元组分组
for (String word : words) {
// 每来一个单词 计数1
out.collect(Tuple2.of(word, 1L));
}
// 因为有泛型擦除 所以需要指定回类型
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照word进行分组 groupBy可以传入索引位置 0表示索引 of(word 0)
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5. 分组内 进行累加 1表示索引 of(word 索引0 , 1L 索引1);
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
// 6. 打印输出
sum.print();
}
}
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
/**
* DataStream API 批处理
* (启动jar包时 指定模式)
*/
@RestController
public class DataStreamAPIBatchWordCount {
@PostConstruct
public void test() throws Exception {
// 1. 创建流式的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件 (有界流)
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
// 3. 转换计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组操作 wordAndOneTuple.keyBy(0) 根据0索引位置分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(item -> item.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6. 打印
sum.print();
// 7. 启动执行 上面步骤只是定义了流的执行流程
env.execute();
// 数字表示子任务编号 (默认是cpu的核心数 同一个词会出现在同一个子任务上进行叠加)
// 3> (java,1)
// 9> (test,1)
// 5> (hello,1)
// 3> (java,2)
// 5> (hello,2)
// 9> (test,2)
// 9> (world,1)
// 9> (test,3)
}
}
文本文件位于根目录的input目录下
test
hello test
world
hello java
java
test
运行:启动application中的main方法即可
flink重要概念
JobManger
TaskManger
JobManger是调度中心,将客户端的数据收集成任务,分发给TaskManger执行,
TaskManger是真正执行任务的地方。
JobManger可以理解为master, TaskManger可以理解为worker (slaver)