
1.概述
默认: 【Flink】FlinkConsumer是如何保证一个partition对应一个thread的
当分区与并行度不一样呢?
2.原理
采用取模运算;平衡 kafka partition与并行度关系。
计算公式
kafkaPartition mod 并行度总数 = 分配到并行度中的partition
例子:partition 个数为 6;并行度为 3
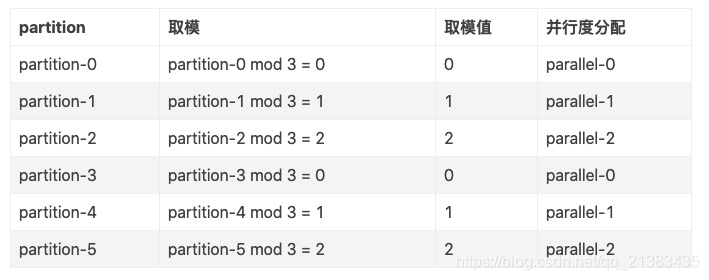
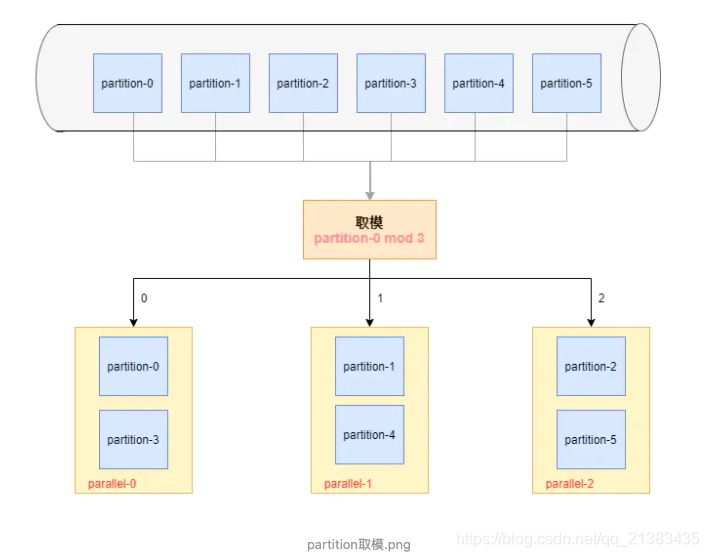
图示如下:
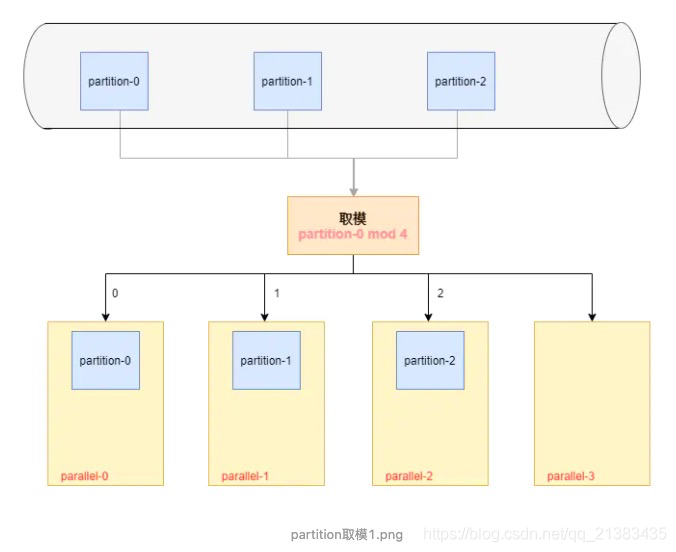
如上分析,如果并行度 大于 partition总数,那么多余的并行度分配不到 partition,该并行度也就不会有数据 如下图:3个kafka partition,flink设置4个并行度为例,编号为3的并行度将获取不到数据
3.源码分析
由于源码比较多,为了代码便于阅读,只抽取关键的代码
FlinkKafkaConsumerBase
public abstract class FlinkKafkaConsumerBase<T> extends RichParallelSourceFunction<T> implements
CheckpointListener,
ResultTypeQueryable<T>,
CheckpointedFunction {
/**
* The partition discoverer, used to find new partitions.
* 分区 discover
*/
private transient volatile AbstractPartitionDiscoverer partitionDiscoverer;
/**
* Describes whether we are discovering partitions for fixed topics or a topic pattern.
* topic 描述
*/
private final KafkaTopicsDescriptor topicsDescriptor;
//构造器
public FlinkKafkaConsumerBase(
List<String> topics,
Pattern topicPattern,
KafkaDeserializationSchema<T> deserializer,
long discoveryIntervalMillis,
boolean useMetrics) {
// topicsDescriptor 创建
this.topicsDescriptor = new KafkaTopicsDescriptor(topics, topicPattern);
//...
}
@Override
public void open(Configuration configuration) throws Exception {
// create the partition discoverer
this.partitionDiscoverer = createPartitionDiscoverer(
topicsDescriptor,
getRuntimeContext().getIndexOfThisSubtask(),//当前并行度 id
getRuntimeContext().getNumberOfParallelSubtasks());//所有并行度总数
this.partitionDiscoverer.open();
//获取当前并行度 分配的 kafka partitions
final List<KafkaTopicPartition> allPartitions = partitionDiscoverer.discoverPartitions();
//...
}
/**
* Creates the partition discoverer that is used to find new partitions for this subtask.
*
* @param topicsDescriptor Descriptor that describes whether we are discovering partitions for fixed topics or a topic pattern.
* @param indexOfThisSubtask The index of this consumer subtask.
* @param numParallelSubtasks The total number of parallel consumer subtasks.
*
* @return The instantiated partition discoverer
*/
protected abstract AbstractPartitionDiscoverer createPartitionDiscoverer(
KafkaTopicsDescriptor topicsDescriptor,
int indexOfThisSubtask,
int numParallelSubtasks);
}
AbstractPartitionDiscoverer : 该类为抽象类,有些方法实现在各个版本的kafka实现类中
public abstract class AbstractPartitionDiscoverer {
/**
* 当前并行度 id
* Index of the consumer subtask that this partition discoverer belongs to.
*/
private final int indexOfThisSubtask;
/**
* 所有并行度总数
* The total number of consumer subtasks.
*/
private final int numParallelSubtasks;
public List<KafkaTopicPartition> discoverPartitions() throws WakeupException, ClosedException {
//获取 所有 partitions
List<KafkaTopicPartition> newDiscoveredPartitions =
//各版本的kafka实现类中
getAllPartitionsForTopics(topicsDescriptor.getFixedTopics());
//移除掉不属于该并行度 中的 partition
Iterator<KafkaTopicPartition> iter = newDiscoveredPartitions.iterator();
KafkaTopicPartition nextPartition;
while (iter.hasNext()) {
nextPartition = iter.next();
if (!setAndCheckDiscoveredPartition(nextPartition)) {
iter.remove();
}
}
}
//判断是否是当前并行度的 任务
public boolean setAndCheckDiscoveredPartition(KafkaTopicPartition partition) {
if (isUndiscoveredPartition(partition)) {
discoveredPartitions.add(partition);
return KafkaTopicPartitionAssigner.assign(partition, numParallelSubtasks) == indexOfThisSubtask;
}
return false;
}
}
KafkaTopicPartitionAssigner
public class KafkaTopicPartitionAssigner {
//取模算法
public static int assign(KafkaTopicPartition partition, int numParallelSubtasks) {
int startIndex = ((partition.getTopic().hashCode() * 31) & 0x7FFFFFFF) % numParallelSubtasks;
return (startIndex + partition.getPartition()) % numParallelSubtasks;
}
}