一、安装
pip install requests二、基本使用
1、基本使用
类型 : models.Response
r.text : 获取网站源码
r.encoding :访问或定制编码方式
r.url :获取请求的 url
r.content :响应的字节类型
r.status_code :响应的状态码
r.headers :响应的头信息
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# 一个类型 六个属性
# Response 类型
print(type(response))
# 设置响应的编码格式
response.encoding = 'utf-8'
# 以字符串形式返回网页源码
print(response.text)
# 返回url地址
print(response.url)
# 返回的是二进制的数据
print(response.content)
# 返回响应的状态码
print(response.status_code)
# 返回的是响应头
print(response.headers)2、与urllib区别
# urllib
# (1) 一个类型以及六个方法
# (2)get请求
# (3)post请求 百度翻译
# (4)ajax的get请求
# (5)ajax的post请求
# (6)cookie登陆 微博
# (7)代理
# requests
# (1)一个类型以及六个属性
# (2)get请求
# (3)post请求
# (4)代理
# (5)cookie 验证码
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd':'北京'
}
############################### GET ##########################
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
# 总结:
# (1)参数使用params传递
# (2)参数无需urlencode编码
# (3)不需要请求对象的定制
# (4)请求资源路径中的?可以加也可以不加
############################# POST ##########################
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url,data=data,headers=headers)
content =response.text
import json
obj = json.loads(content,encoding='utf-8')
print(obj)
# 总结:
# (1)post请求 是不需要编解码
# (2)post请求的参数是data
# (3)不需要请求对象的定制三、代理
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
data = {
'wd' : 'ip'
}
proxy = {
'http':'120.194.55.139:6969'
}
response = requests.get(url=url,params=data,headers=headers,proxies=proxy)
content = response.text
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)四、cookie定制(破解验证码)
找登录接口
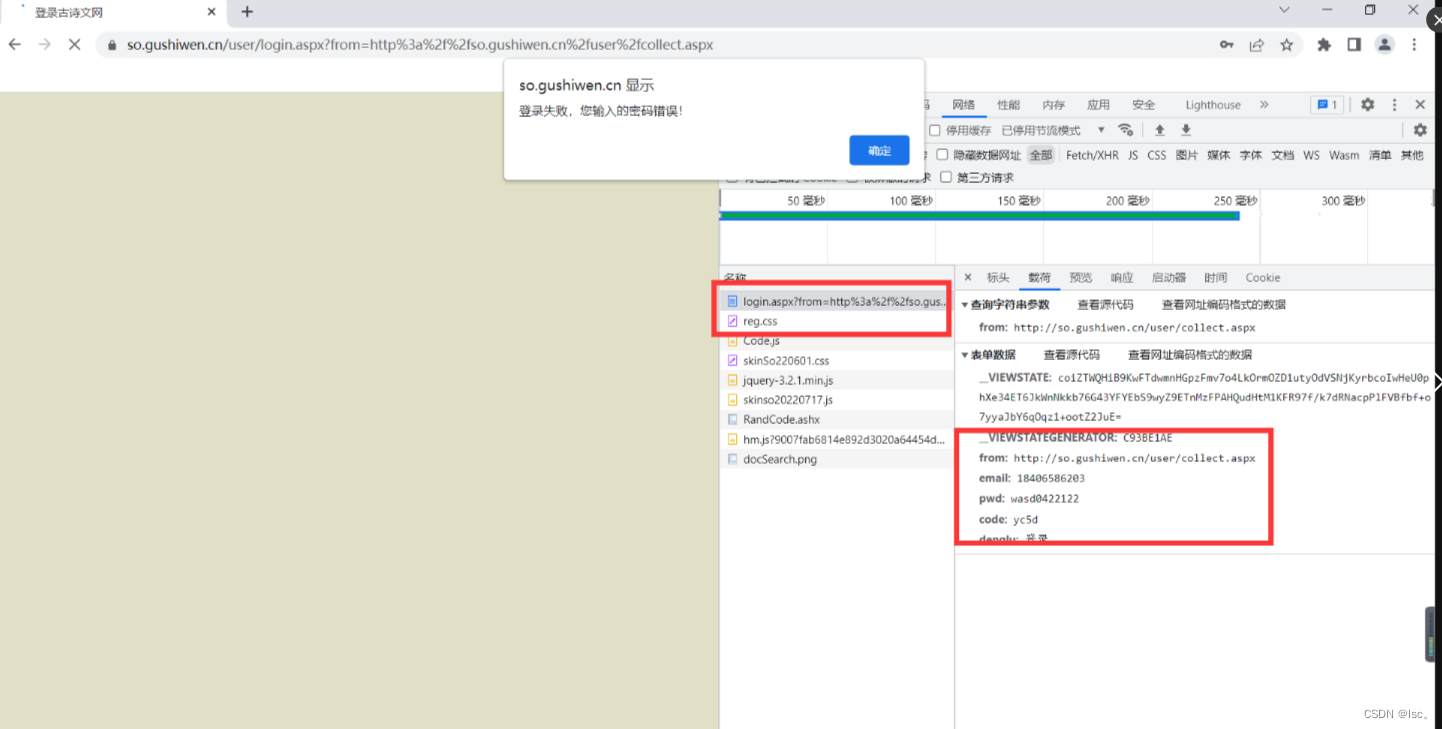
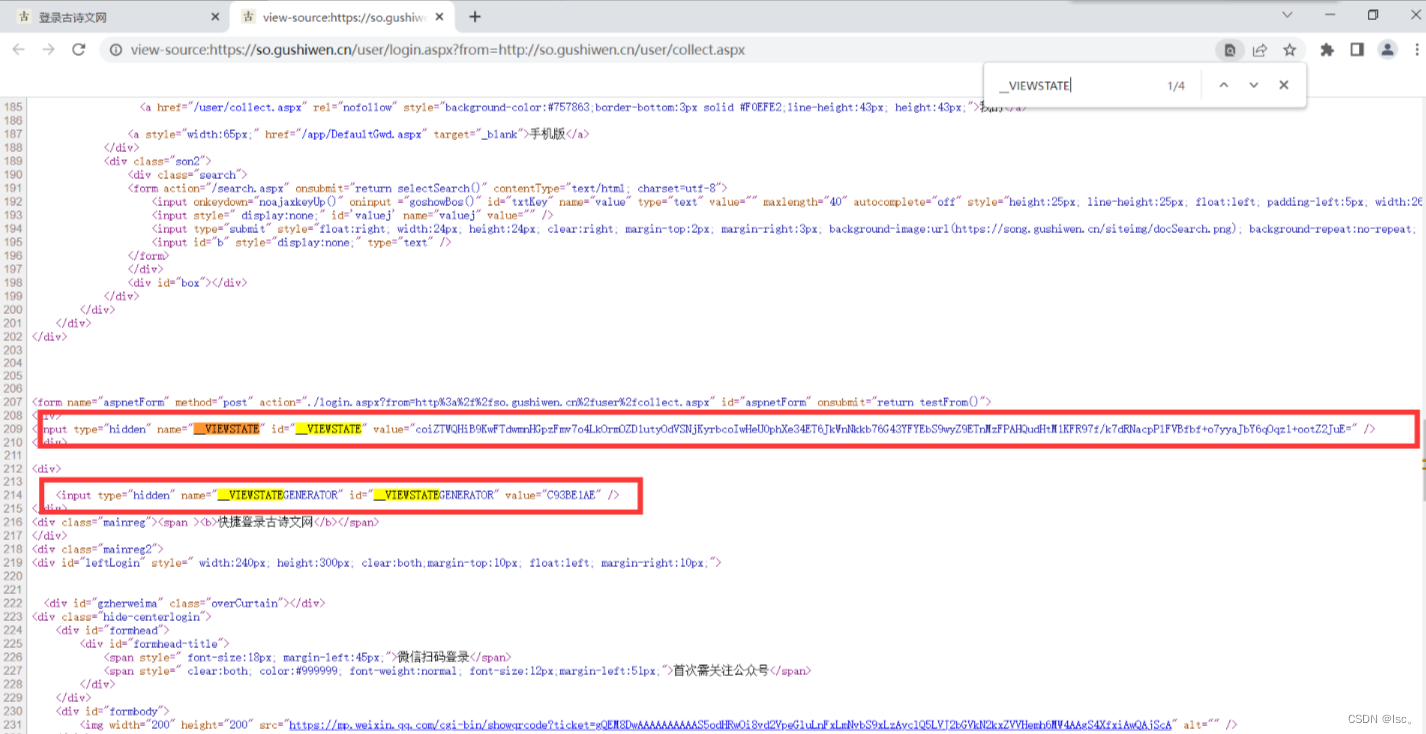
找参数的值
python代码
import requests
# 登录页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
# 获取页面的源码
response = requests.get(url=url,headers=headers)
content = response.text
# 解析页面源码 获取__VIEWSTATE __VIEWSTATEGENERATOR 这里使用bs4解析
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取__VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# 接下来处理验证码
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 下载验证码图片
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# 使用上面方法下载验证码后会使验证码更新,从而使的每次都会提醒验证码错误
# requests里面有个方法session() 通过session的返回值就能使请求变为一个对象
session = requests.session()
# 验证码的url地址
response_code = session.get(code_url)
# 注意此时要使用二进制的数据 因为我们要是用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制的数据写到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 获取了验证码的图片之后 下载到本地 然后观察验证码 然后在控制台输入这个验证码 就可以将这个值给code的参数
code_name = input('请输入你的验证码:')
# 点击登录
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '自己账号',
'pwd': '自己密码',
'code': code_name,
'denglu': '登录'
}
response_post = session.post(url=url_post,headers=headers,data=data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding='utf-8')as fp:
fp.write(content_post)五、破解验证码——超级鹰(公司级别)
登录超级鹰官网:超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大
若之前没有注册,则需要注册新的用户,并且进行充值。
进入 用户中心 后点击 开发文档

选择袭击使用的语言案例。
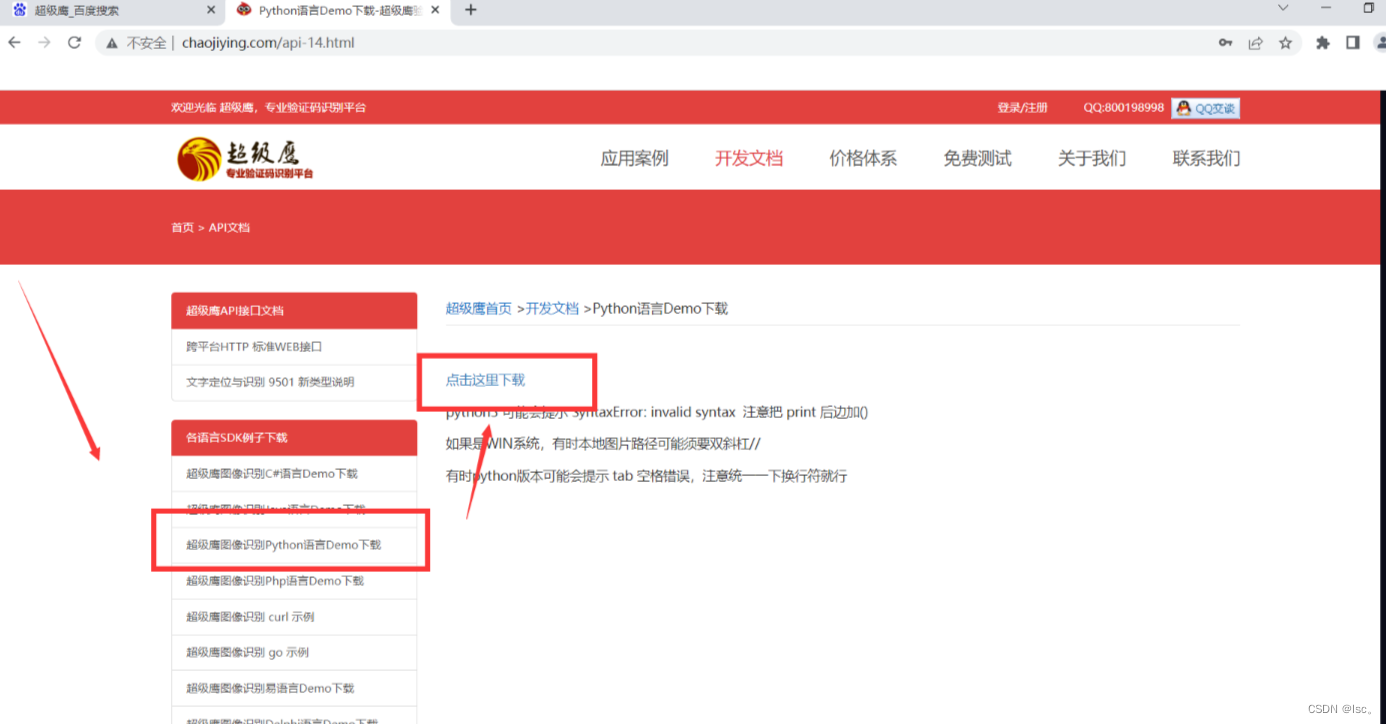
下载好压缩包解压,并且把一下两个文件在pycharm中打开。
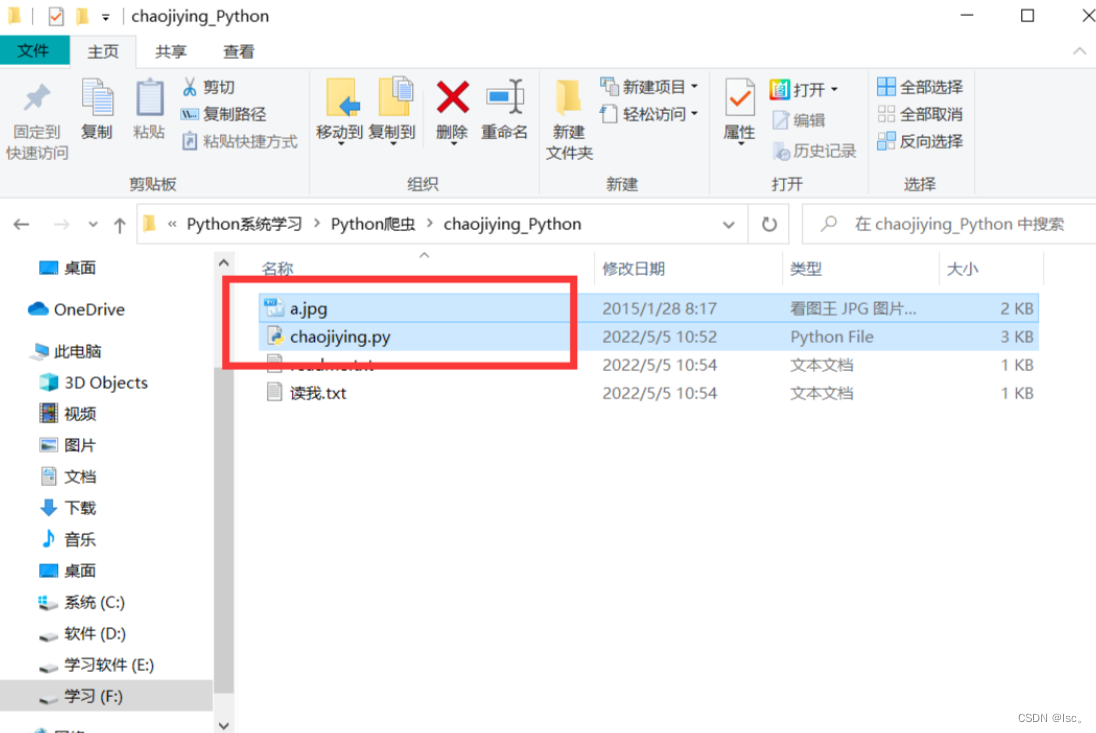
代码中修改如下四处地方。

软件ID的获取方法如下:
进入用户中心 --> 软件id --> 生成软件ID --> 复制软件id到代码中

到此,运行代码就可以自动识别图片中的验证码了。