Python爬虫:requests进阶
处理cookie
一般来说我们要处理的cookie都是需要登录操作的,过程是客户端登陆以后,获得服务器返回的cookie,然后带着cookie去请求url获得相关内容。因此需要将上述两个操作连起来,可以使用session进行请求。session可以认为是一连串的请求,并且在这个过程中cookie不会丢失。
使用session
import requests
# 会话
session = requests.session()
data = {
#填网页抓取后需要登陆的登陆参数名,比如
#“loginname”:"password"
}
#登录
url = ""
session.post(url,data=data)
#上面的session中是有cookie的
resp = session.get("XXXXX") # XXXX表示存储数据的请求网页,需要在开发者模式下的network中寻找相关数据
使用cookie
另一种方式是不使用session,在网页登陆以后,在开发者模式下获取请求页面的cookie值,把它加入到headers中进行请求。
import requests
resp = requests.get("XXXX",headers={
"Cookie":"XXXXXXXXX"
})
使用防盗链处理一些反爬
防盗链:可以认为是溯源,当前本次请求的上一级是谁。referer防盗链是基于获取HTTP请求中的 referer header,根据 referer 跟踪来源,对来源进行识别和判断。
实例:抓取梨视频
1.分析源代码,在运行时发现一个srcurl,事实上这个srcurl并不是视频真正的地址,所以我们需要进一步考虑
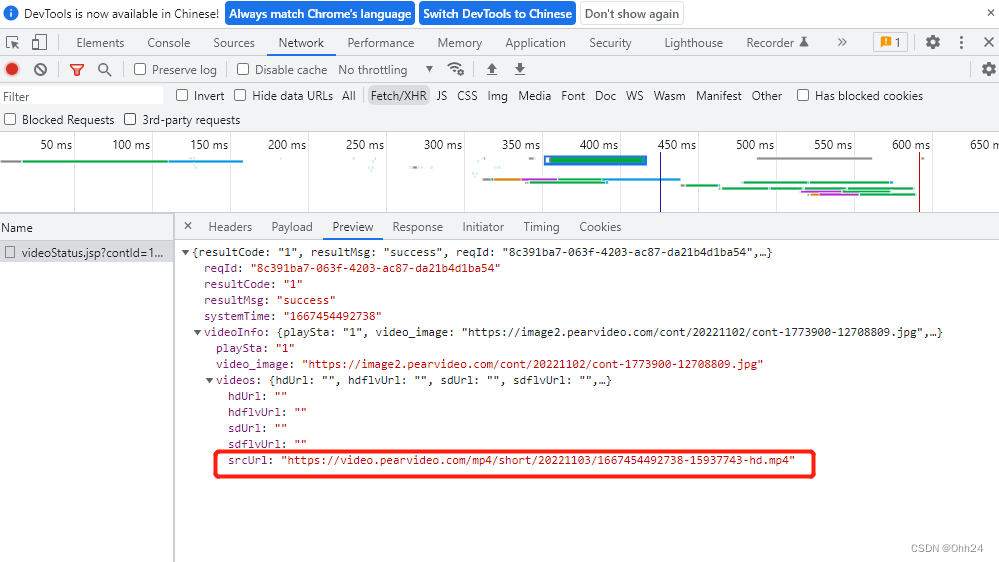
2.通关观察可以发现真实的url地址是将最后地址的前半部分去掉systemtime加上字符串“content”和打开视频的url最后部分


代码:
#1.拿到contID
#2.拿到videoStatus返回的json -> srcURL
#3.srcUL中的内容进行修整
#4.下载视频
import requests
url = "https://www.pearvideo.com/video_1773900"
contID = url.split("_")[1]
videoStatusUrl = "https://www.pearvideo.com/videoStatus.jsp?contId=1773900&mrd=0.3066916683965706"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
#防盗链
"Referer": "https://www.pearvideo.com/video_1773900"
}
resp = requests.get(videoStatusUrl,headers=headers)
dic =resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime,f"cont-{contID}")
#下载视频
with open("a.mp4",mode="wb") as f:
f.write(requests.get(srcUrl).content)
proxy(不推荐使用)
proxies = {
"https": "https://XXXXXX"
}
requests.get("XXXXXX",proxies=proxies)