版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/youzi_yun/article/details/78385108
import requests
get请求
<!--get请求-->
response = requests.get(url, params, kwargs)
<!--只请求url-->
response = requests.get(url)
<!--带参数请求-->
params = {"key":"value"}
response = requests.get(url, params = params)
<!--伪装客户端类型请求-->
<!--去浏览器请求一个网址,直接复制过来,这个是火狐浏览器的-->
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}
response = request.get(url, headers = headers)
<!--ip代理-->
<!--为了让服务器认为请求不是从一个ip过去的,避免被封-->
proxies = {
"http":"http://用户名:密码@代理ip:端口",
"https":"https://用户名:密码@代理ip:端口",
}
response = request.get(url, proxies = proxies)
<!--如果有ip_port列表,通过random随机取出一个-->
ip_port_list = [ip_port1,ip_port2]
ip_port = random.choice(ip_port_list)
<!--超时时间-->
response = request.get(url, timeout=3)
<!--请求一个url,等待响应的时间,若3秒无响应,报错。-->
<!--当使用代理ip时,可以设置超时时间,若超时,直接挂掉(用try捕获异常),换下一个ip-->
只请求head
response_header = requests.head(url,kwargs)
<!--在做增量爬虫的时候,可以只请求head,根据Last-Modified(请求资源的最后修改时间)来判断目标网页是否更新数据-->获取response参数
<!--响应码-->
response.status_code
<!--编码方式-->
response.encoding
<!--响应的内容-->
response.text
<!--requests会基于http头部对响应的编码进行解码,-->
<!--二进制响应内容, 可以自己解码-->
response.content
response.content.decode() # 默认为utf-8
<!--响应的url-->
response.url
post请求
- 找到提交表单的url
- 分析表单提交的数据内容,Network中这个url的Form Data
- 返回的数据格式 NetWork中,这个url的Response
<!--post请求-->
response = requests.post(url,data,json,kwargs)
- 如果返回的数据格式是json,需要转化为Python字典
- 由于json转化为Python字典跟简单,所以爬虫中,尽量找能返回json数据格式字符串的url
- 如何找到?
- 开发者模式 Network
- 抓包工具
- fiddler
- wireshark(win/linux)
- tcpdump(linux)
找json格式数据思路:
- 在Network中源码Preview中搜索想要找的数据中的一条,搜到之后,发现是保存在标签中的;
- 找ajax请求的数据XHR,如果返回的json数据还不是想要的;
- 开发者模式切换到手机端,一般手机端用json传递数据可能性大些;
- 在手机端看ajax数据XHR,如果还没有;
- 一条一条看,(css,js,png这些可以直接排除,,最重要的是带?的请求)是否是json格式的数据,如果是,查看Preview,找到了。。
- 找到之后,回到Header,获取请求方式和url;
- 将这个url在浏览器中打开,由于get请求携带的参数众多,一个一个试着删除,只留下不会更改源数据的参数。
这样就找到了需要获取json格式数据的url,在Python中获取后,转化为dict格式,通过key获取需要的数据。
- 好用的浏览器json美化插件:
- json handle,功能强大
- json formatter,简单
json和字典之间的转换
<!--json字符串 -> python字典-->
json.loads("json字符串")
<!--json类文件对象 -> python字典-->
json.load(f)
<!--python字典 -> json字符串-->
json.dumps(dict)
<!--python字典 -> json类文件对象-->
json.dump(dict, f)
<!--这里的json类文件对象是指具有read()或write()方法的 f = open("文件","r")的f-->session
- 被实例化后,会自动维护cookies和session保持会话,可以直接用session.get来获取页面
- post请求提交的表单,可以通过form表单中的标签获得action,以及input输入框的name
session = requests.session(url, headers=headers, data=data)
response1 = session.get(url)requests.utils
这里有很多小工具,比如:
<!--cookie和字典之间的转化-->
response.cookies # 类型为cookiejar对象
dict_cookie = requests.utils.dict_from_cookiejar(response.cookies)
jar_cookie = requests.utils.cookiejar_from_dict(dict_cookie)
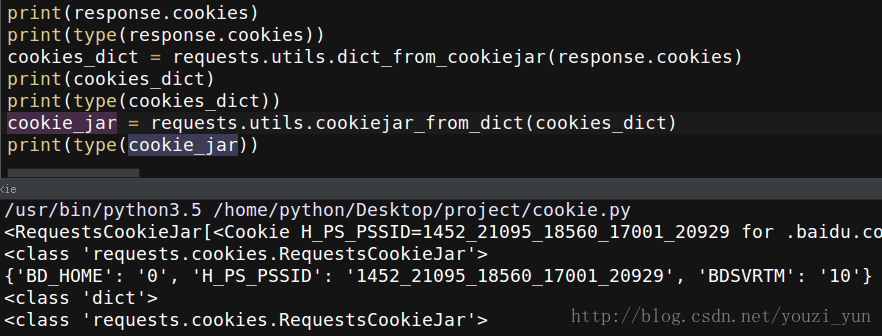
当cookie_jar再转换为dict格式的时候,原来存储cookie的源url已经不见了