python爬虫-requests
说明
无疑,py3上也可以使用urllib2库,但入门时走的py2路线,所以坚持了这一贯的曲风。而这之后会刻意转py3,requests库的使用就成了重中之重。可实在没什么好讲述的,有了urllib2基础之后,基于一个“使用对照表”,一切就仿佛顺理成章。
自然非熟练情况下,并不总能记住。最近用requests库的时候老把这篇笔记翻来看,也算勉强“敷衍”了自身的需求。大概我这样的坏毛很难纠改了——“但凡没有外力迫使,一切交予时间”。所以我坚定不移的相信,只要周期足够,掌握是早晚事儿而已。
下面主要说明一下自己使用的时候明显察觉到的区别:
1. 不需要urllib.urlencode()实现url编码,get和post请求方式直接上参数,分别对应:前者params,后者data
2. 拿到服务器返还的response后urllib2不需要编码处理,而requsets需要,实现方式为:response.encoding=response.apparent_encoding
3. urllib2对文字与照片(这样说不准确,应该是二进制文件)的处理都是response.read();requests分别对应text方法和content方法,即:response.text,response.content
4. requests有个response.raise_for_status()在我看来是个神器,省去了自己写判断状态码的麻烦,这很“人生苦短,我用Python”
5. 外加一个,requests模块的session很简单
以下笔记基于中国大学MOOC,嵩天老师的《Python网络爬虫与信息提取》课程,不足之处还望各友指教
基于python3实现
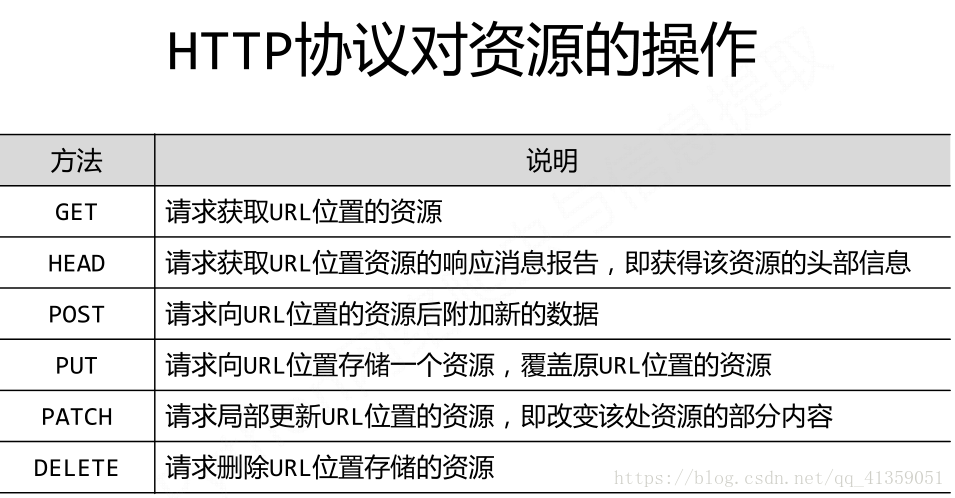
主要方法:
requests.request() 构造一个请求头,支持以下各种方法的基础
requests.get() GET请求方式
requests.head() HEAD
requests.post() POST
requests.put() PUT
requests.patch() 向页面提交局部修改请求,PATCH
requests.delete() 向页面提交删除请求
response = requests.get(url)
response.status_code 响应状态码
response.text 内容
response.encoding 猜测编码方式
response.apparent_encoding 从返回内容中分析的编码方式(备选编码方式)
response.content HTTP响应内容的二进制形式
response.headers 返回响应头
response.cookies返回cookies值
requests.utils.dict_from_cookiejar(response.cookies)cookies值转换成字典
异常:
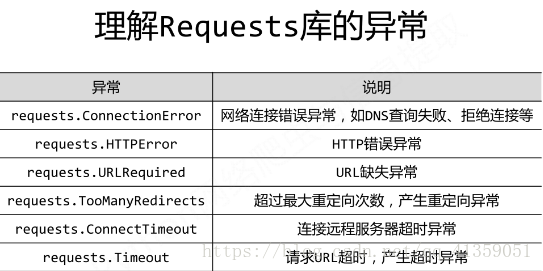
response.raise_for_status() 如果响应状态码不是200,抛出HTTPError异常
参数
requests.request(method, url, **kwargs)kwargs共13个参数
1. 如果method=GET, params=kv(字典), 实现拼接url地址(params可以字典,字节序列,添加到url中)
2. 如果method=POST, data=kv(字典),实现发送form表单(data可以字典,字节序列,文件对象)
3. 续POST,json=kv,JSON格式的数据,作为请求体的一部分
4. headers,字典,HTTP定制头
5. cookies,字典或CookieJar, Request中的cookie
6. auth,元组,支持HTTP认证功能
7. files,字典类型,传输文件
8. timeout,设定超时时间,秒为单位
9. proxies,字典类型,设定访问代理服务器,可以增加登陆认证
10. allow_redirects,True/False,默认True,重定向开关
11. stream,True/False,默认True,获取内容立即下载开关
12. verify,True/Flase,默认T,认证SSL证书开关
13. cert,本地SSL证书
session对象
ssion = requests.session(),其他使用方法不变