到目前为止,我强调了在开发应用程序时,您通常会使用现有的LLM。这为您节省了大量时间,并可以更快地得到一个工作原型。
但是,有一种情况下,您可能会发现有必要从头开始预训练自己的模型。如果您的目标领域使用的词汇和语言结构在日常语言中并不常用,您可能需要进行领域适应以实现良好的模型性能。
例如,想象一下您是一个开发人员,正在构建一个应用程序,帮助律师和律师助理总结法律摘要。法律写作使用了非常特定的术语,如第一个例子中的"mens rea"和第二个例子中的"res judicata"。这些词在法律界外很少使用,这意味着它们不太可能在现有LLM的训练文本中广泛出现。因此,模型可能难以理解这些术语或正确使用它们。

另一个问题是,法律语言有时在不同的上下文中使用日常词汇,如第三个例子中的"consideration"。这与友善无关,而是指的是使协议可执行的合同的主要元素。出于类似的原因,如果您尝试在医疗应用中使用现有的LLM,可能会遇到挑战。
医学语言包含许多不常用的词汇来描述医学状况和程序。这些可能不会经常出现在由网络抓取和书籍文本组成的训练数据集中。有些领域也以高度特异的方式使用语言。
这最后一个医学语言的例子可能只是一串随机字符,但它实际上是医生用来写处方的速记。这段文字对于药剂师来说意义非凡,意思是饭后和睡前口服一片,每天四次。

因为模型通过原始预训练任务学习它们的词汇和语言理解,所以从头开始预训练您的模型将为法律、医学、金融或科学等高度专业化的领域产生更好的模型。
现在,让我们回到BloombergGPT,首次在2023年由Bloomberg的Shijie Wu、Steven Lu和同事们在一篇论文中宣布。BloombergGPT是一个已经为特定领域预训练的大型语言模型的例子,这个领域是金融。
Bloomberg的研究人员选择将金融数据和通用税务数据结合起来,预训练一个在金融基准上取得最佳结果的模型,同时在通用LLM基准上保持竞争性能。因此,研究人员选择了由51%的金融数据和49%的公共数据组成的数据。

在他们的论文中,Bloomberg的研究人员更详细地描述了模型的架构。他们还讨论了他们是如何从Chinchilla的缩放法则开始寻求指导,以及他们在哪里不得不做出权衡。
这两张图比较了包括BloombergGPT在内的一些LLM与研究人员讨论的缩放法则。
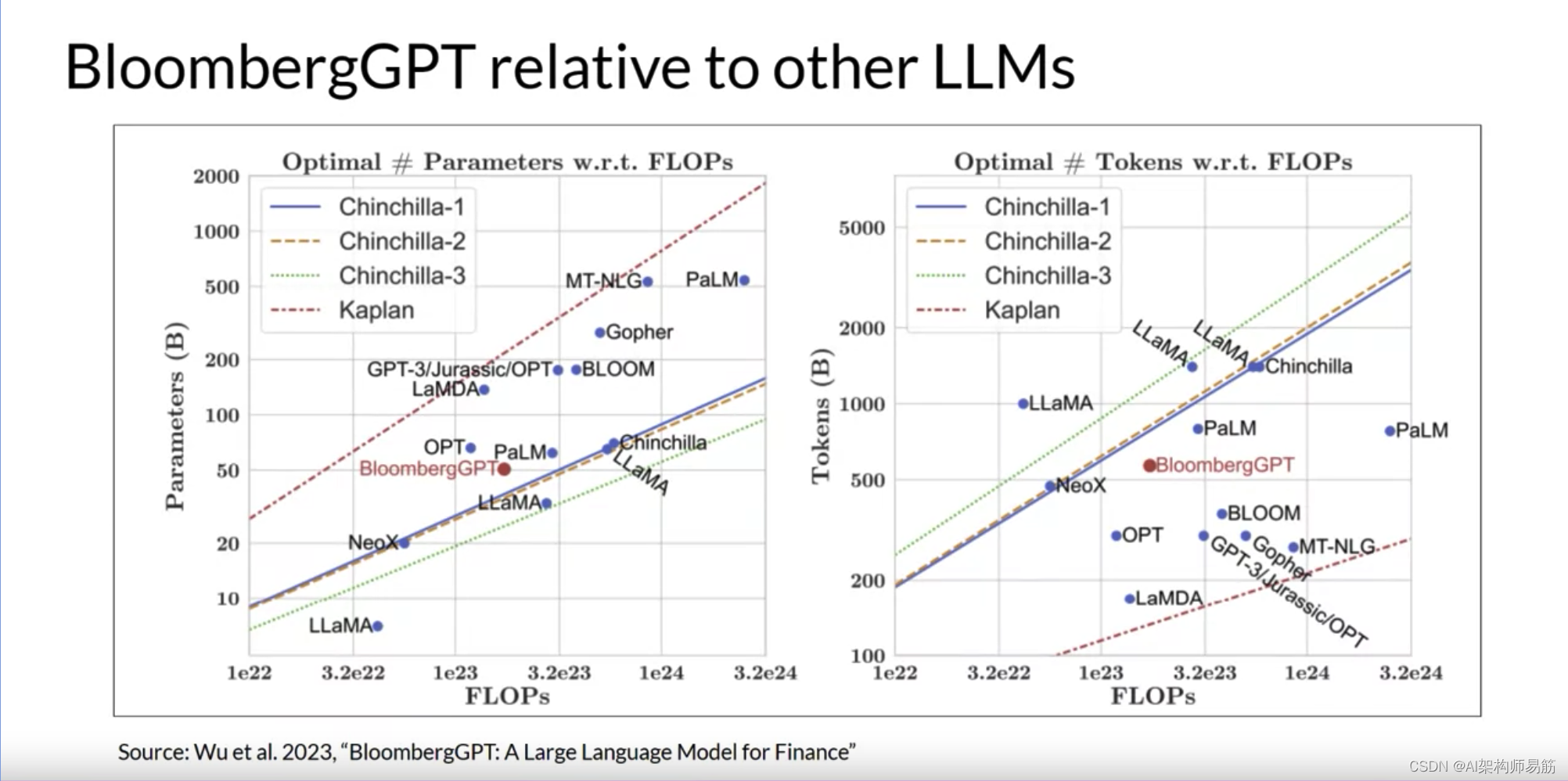
左边,对角线追踪了一系列计算预算的最佳模型大小,以十亿参数为单位。
右边,线追踪了计算最佳训练数据集大小,以令牌数量为单位。
每张图上的虚线粉红线表示Bloomberg团队用于训练新模型的计算预算。
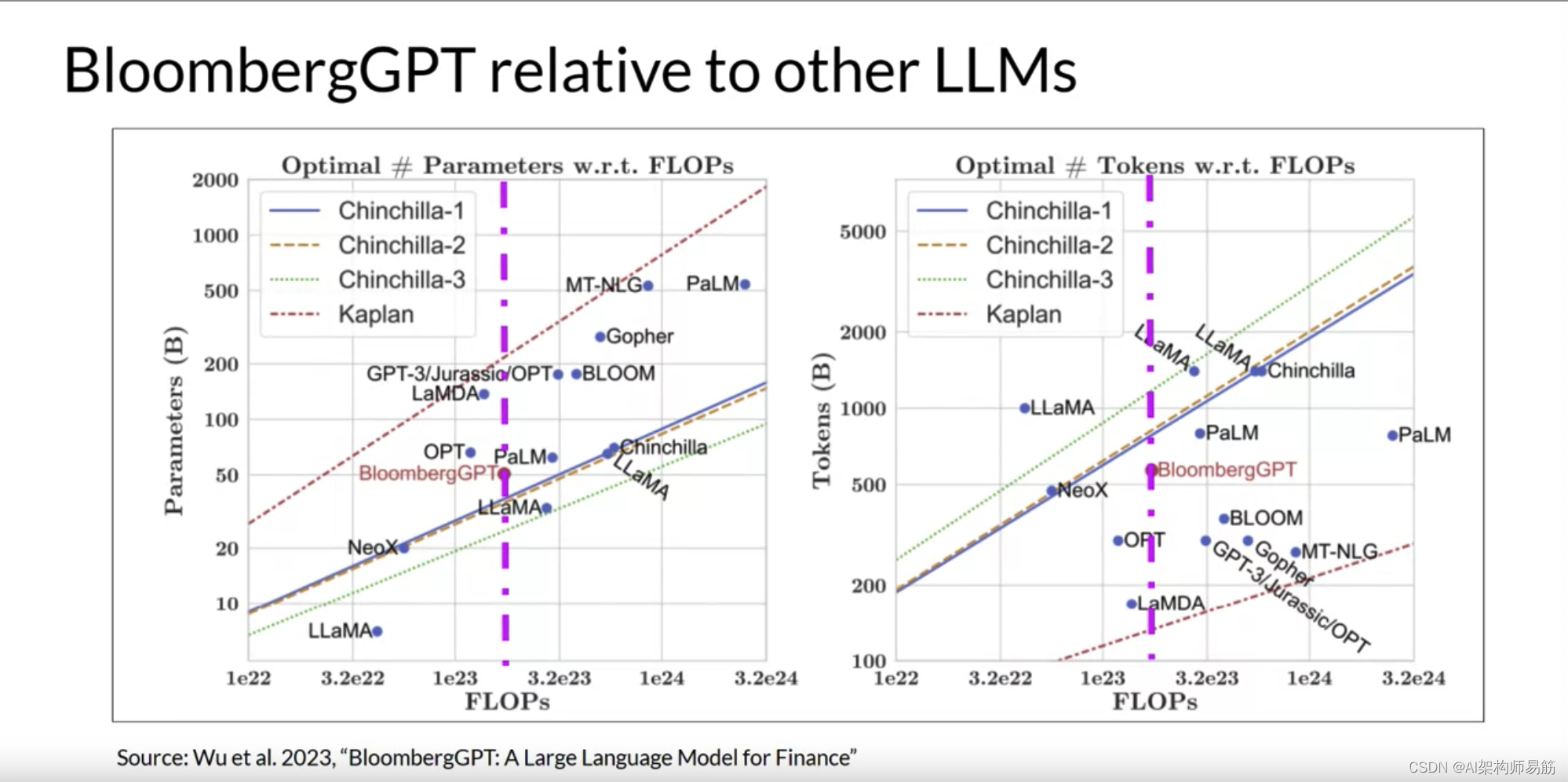
粉红色阴影区域对应于Chinchilla论文中确定的计算最佳缩放损失。
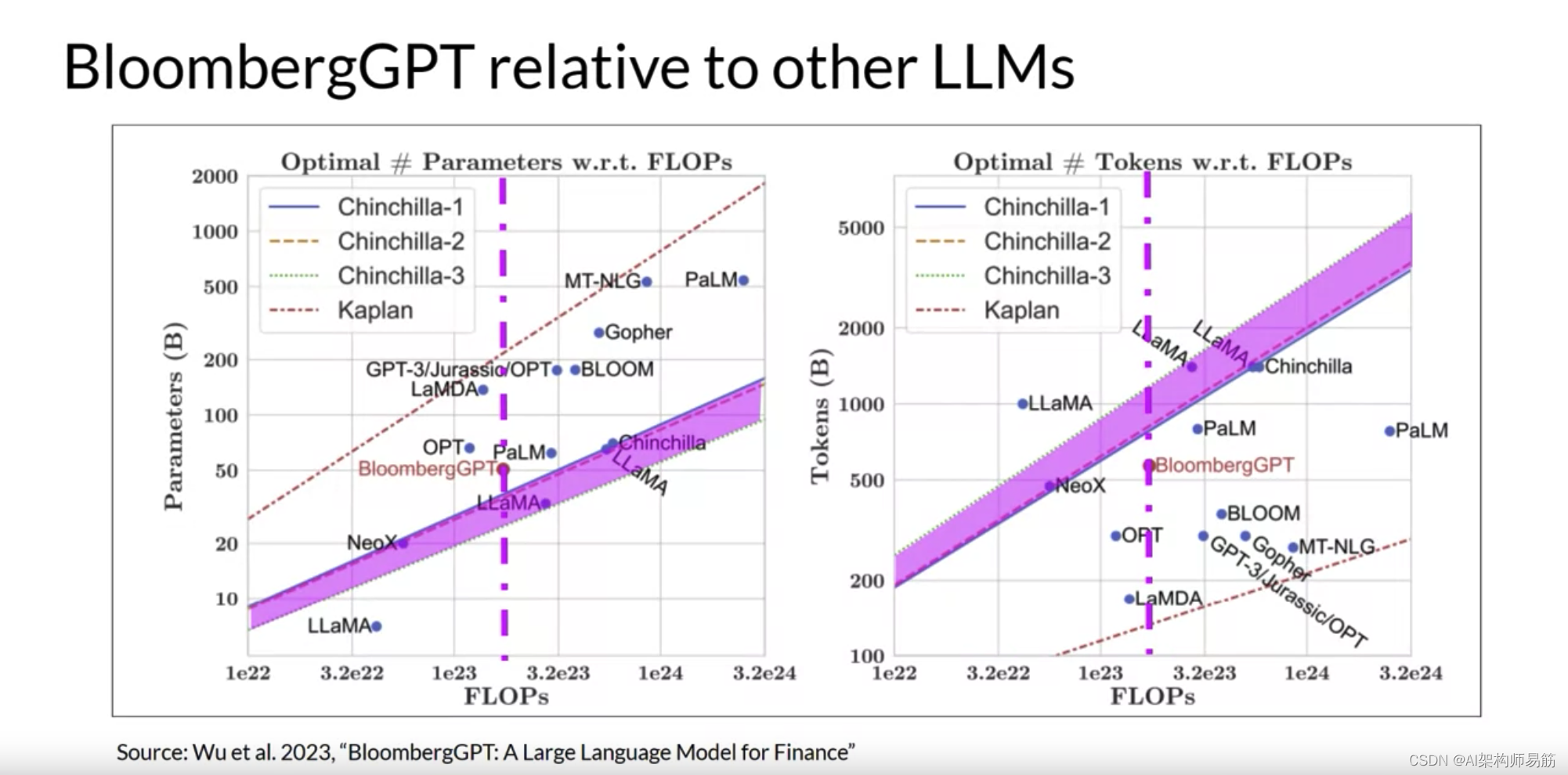
在模型大小方面,您可以看到BloombergGPT大致遵循了给定计算预算为130万GPU小时,或大约2.3亿petaflops的Chinchilla方法。模型只是略高于粉红色阴影区域,表明参数数量接近最佳。
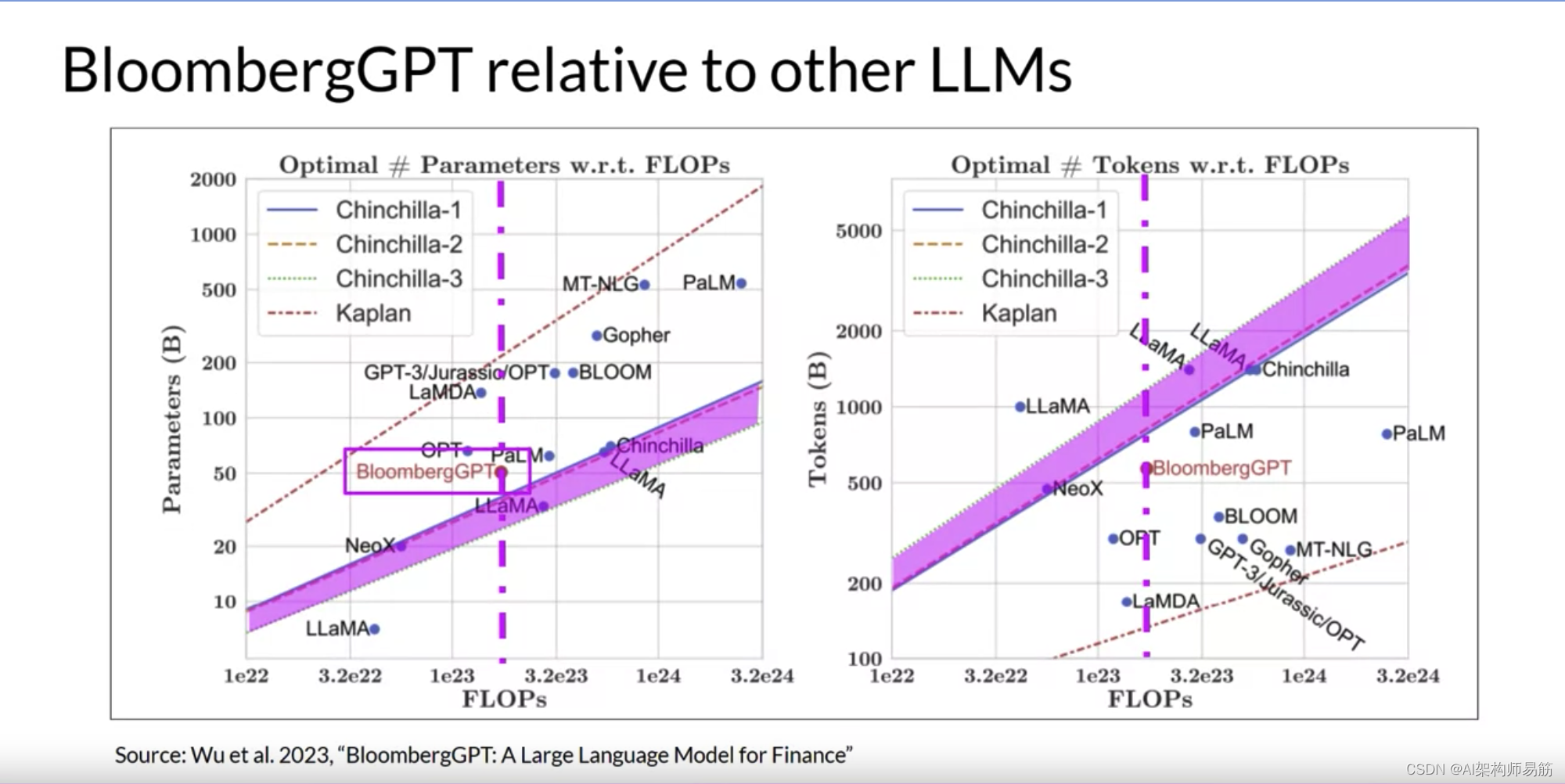
然而,用于预训练BloombergGPT的实际令牌数量为5690亿,低于可用计算预算的推荐Chinchilla值。小于最佳的训练数据集是由于金融领域数据的有限可用性。
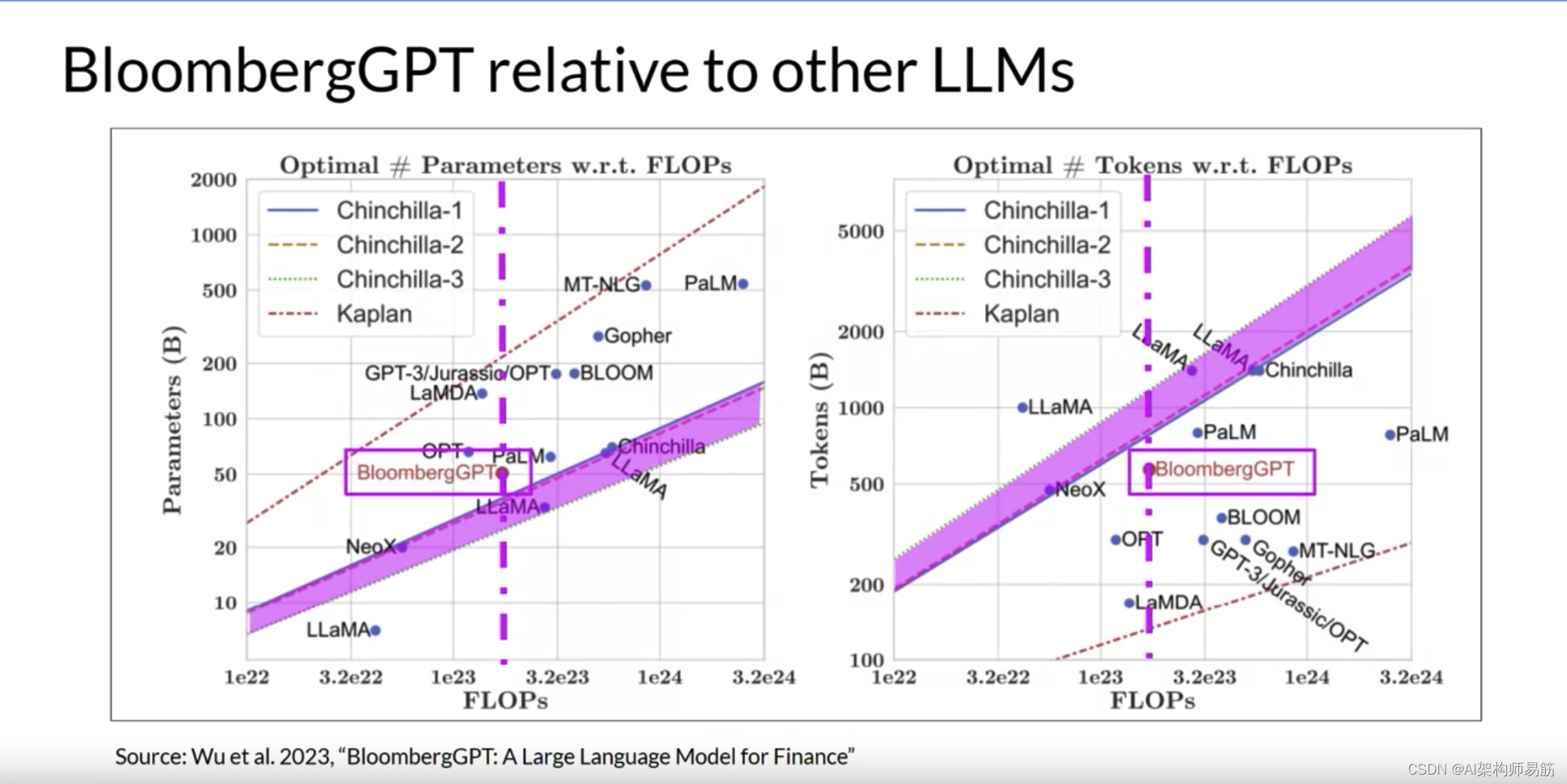
显示实际约束可能迫使您在预训练自己的模型时做出权衡。
恭喜您完成了第一周的学习,您已经涵盖了很多内容,所以让我们花一分钟回顾一下您所看到的。
-
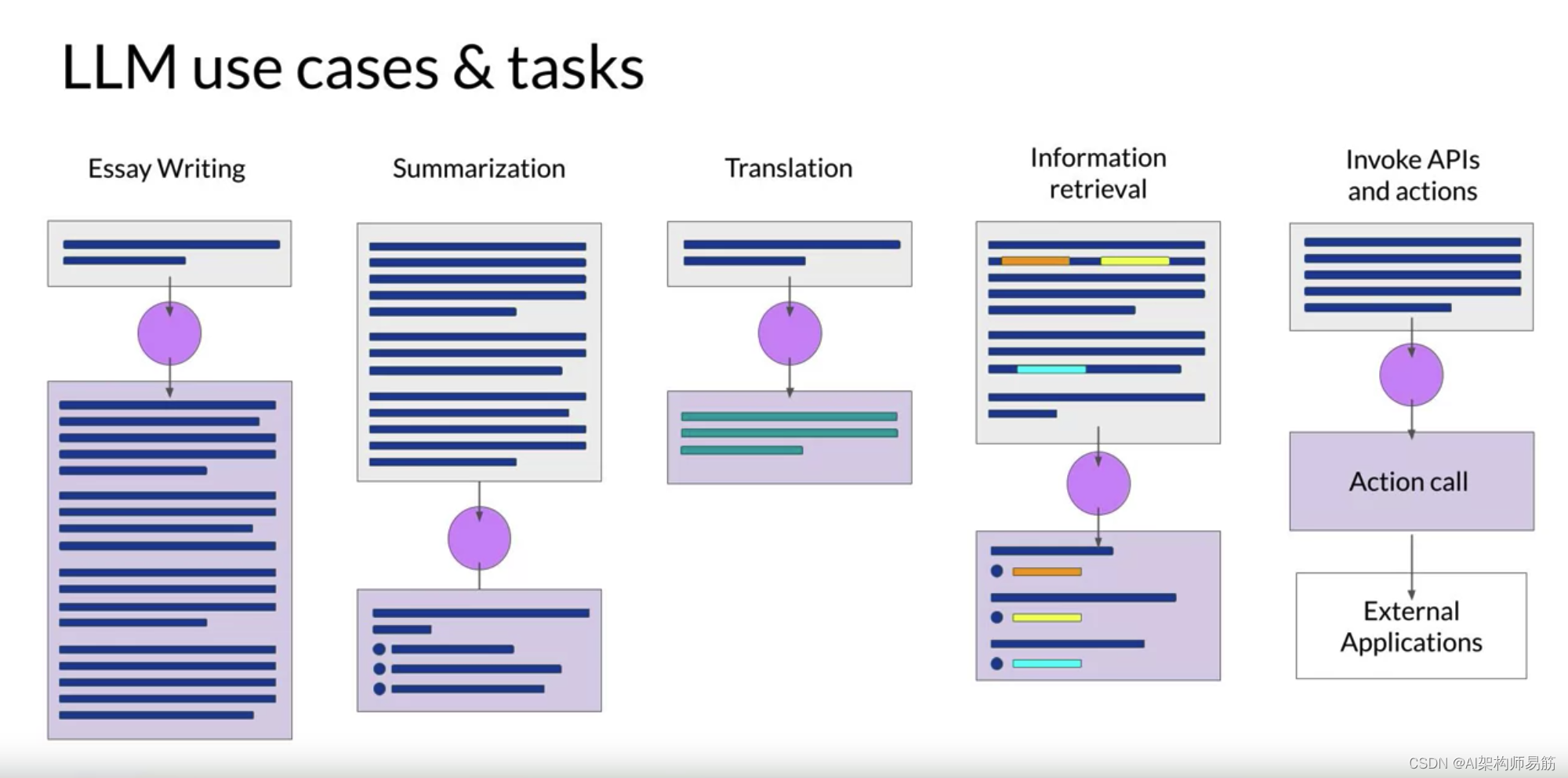
Mike带您了解了LLM的一些常见用途,如写作、对话摘要和翻译。
-
然后,他详细介绍了为这些模型提供动力的Transforms架构。
-
并讨论了您在推理时可以使用的一些参数来影响模型的输出。
-
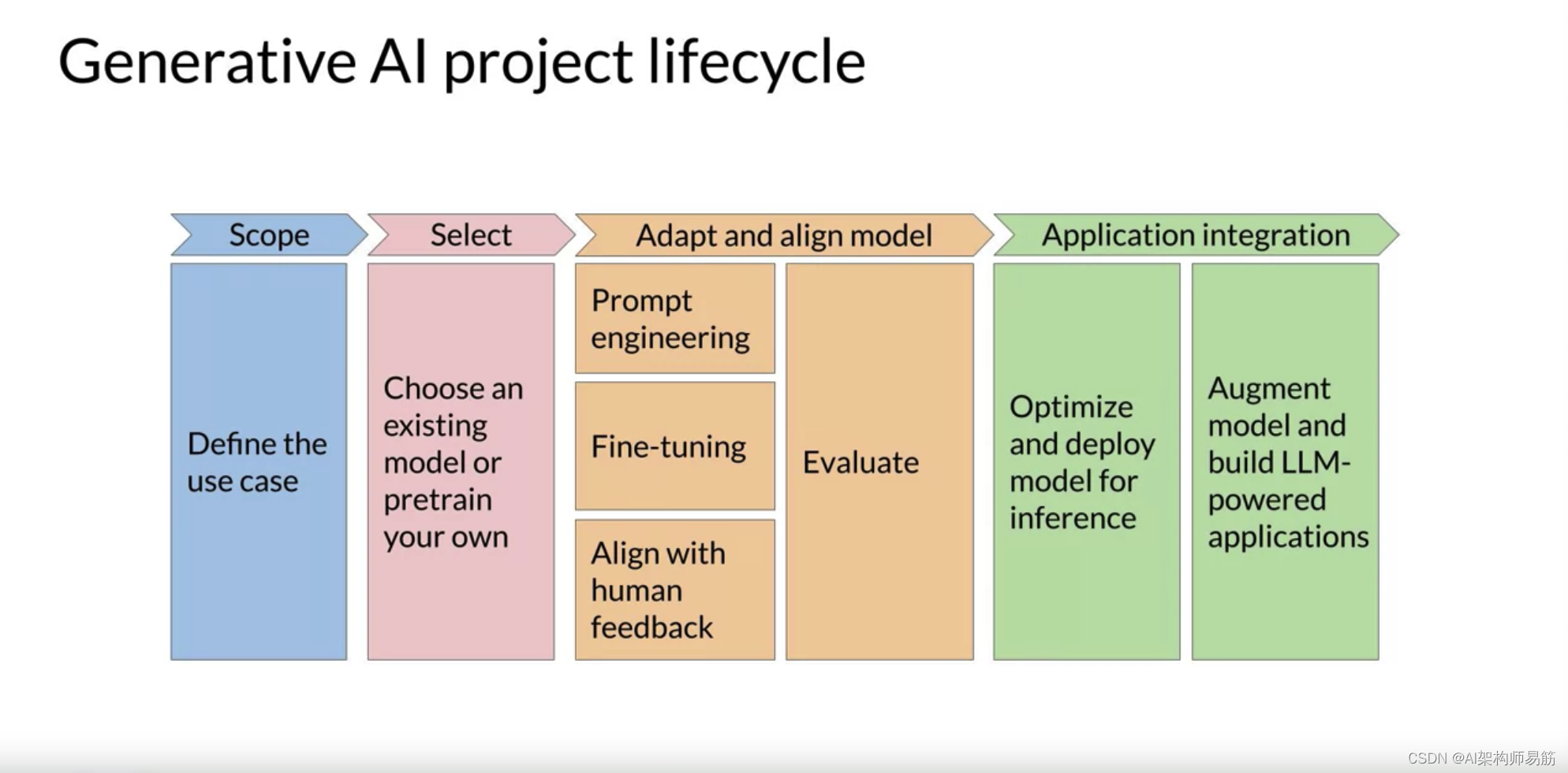
他总结了一个您可以用来计划和指导应用程序开发工作的生成性AI项目生命周期。
-
接下来,您看到了模型在一个称为预训练的初始训练阶段如何在大量的文本数据上进行训练。这是模型发展其语言理解的地方。
-
您探讨了训练这些模型的计算挑战,这些挑战是很大的。
-
在实践中,由于GPU内存限制,您几乎总是在训练模型时使用某种形式的量化。
-
您本周结束时讨论了LLM的缩放法则以及如何使用它们设计计算最佳模型。
如果您想阅读更多的细节,请务必查看本周的阅读练习。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/BMxlN/pre-training-for-domain-adaptation