目录
1 迁移学习的直观理解
人类容易在类似的任务上利用先前的经验,比如学过自行车就很容易学会摩托车,学会打羽毛球也能帮助学习打网球,学过小提琴也会对学习二胡有帮助。也就是把一个领域上学习的知识迁移到另一个领域上,目的也是让计算机有举一反三的能力(大概是实现AGI的一个重要的坎),或者是去尝试充分利用已经训练过的某个领域的知识来解决当前的任务(这样可以解决数据少的问题)。
在迁移学习中要强调源域(Source Domain)、源任务(Source Task)、目标域(Target Domain)和目标任务(Target Domain) 的概念。在普通机器学习方法里,源域和目标域是一样的,就是训练的是什么数据测试的也是这个领域的数据(比如“摄像头捕捉的行人图片”);源任务和目标任务也是一样的,即希望模型能做什么事情,训练的就是做这件事(比如“分类猫和狗”)。而在迁移学习中源域和目标域可能是不一样的,源任务和目标任务也可能是不一样的(甚至可能一个是分类一个是回归),我的理解是源域-目标域、源任务-目标任务至少有一对不一样才能称为迁移学习。
2 迁移学习的种类
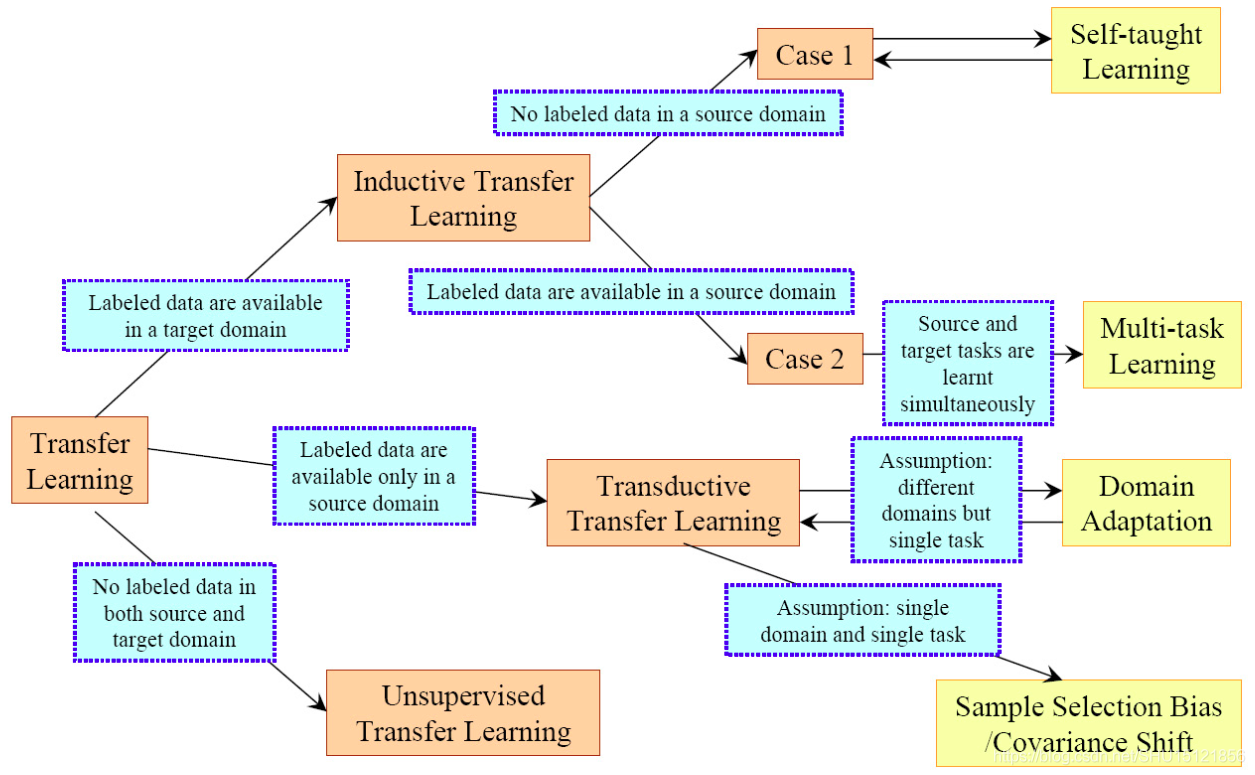
在2012年的SJ Pan的综述里将迁移学习按照有标记的样本的情况分为下面三大类,可以解决不同的问题。
3 领域自适应简述
Domain Adaptation是一种源任务和目标任务一样,但是源域和目标域的数据分布不一样,并且源域有大量的标记好的样本,目标域则没有(或者只有非常少的)有标记的样本的迁移学习方法。这样就是怎么把源域上从大量的有标记样本中学习的知识迁移到目标域上,来解决相同的问题,而目标域上能利用的大多只有没有标记的样本。
这里要解释一下“数据分布不一样”是什么意思,就比如下图中(a)组是不同来源的自行车和笔记本电脑的照片,有从购物网站下载的,也有数码相机拍的生活照,也有网络上获取的照片等,它们虽然都表达自行车和笔记本电脑,但是数据分布是不同的。

比如用(b)组的门牌号数据集SVHN去训练模型,去提取SVNH和MNIST的特征,然后将其可视化到一个平面内,是下图左边的样子,蓝色点是源域(SVNH)的样本,红色的点是目标域(MNIST)的样本,也就是说直接在源域上训练得到的分类器的分类边界无法很好的区分目标域的样本。而领域自适应这种迁移学习方法想达到的效果就是下图右边这样,让源域和目标域中的样本能对齐,这样模型就能在目标域上很好的使用了。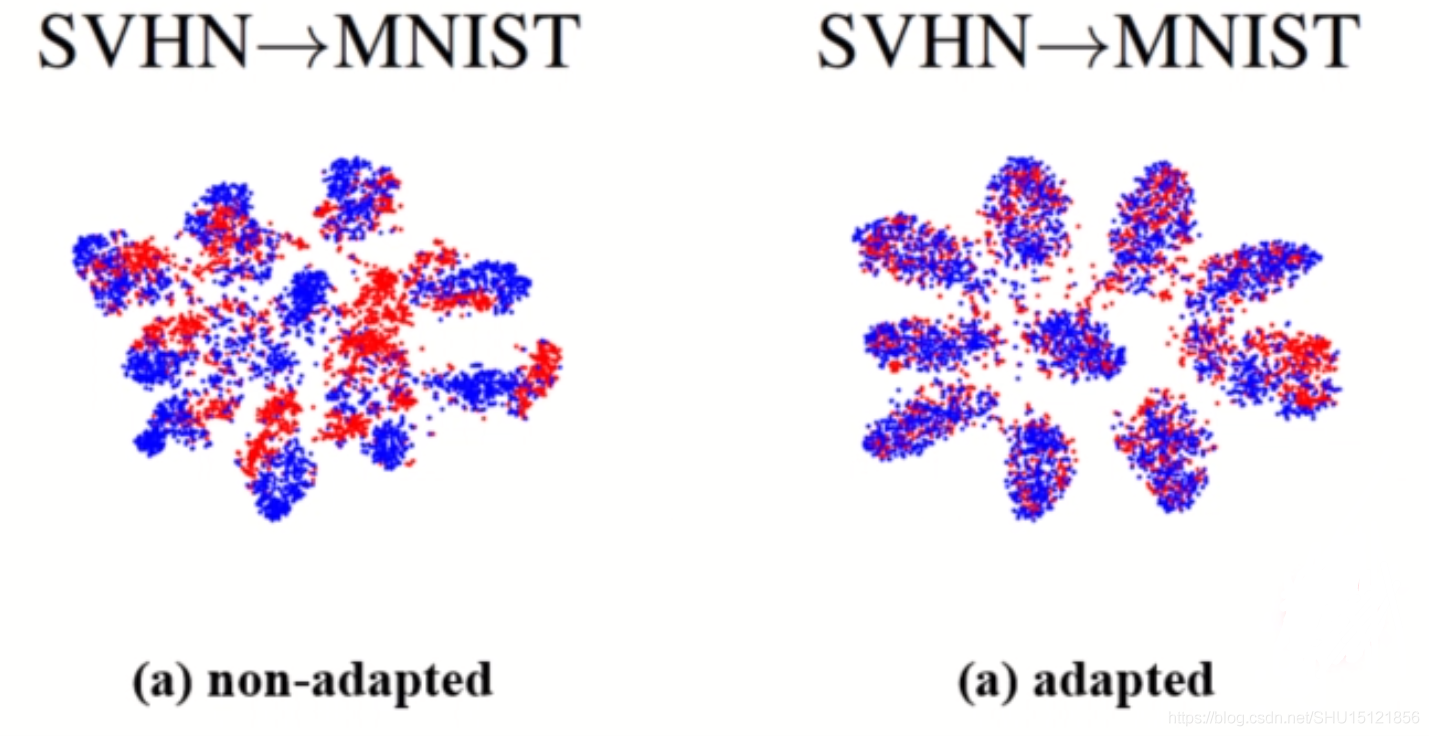
4 DA的研究方向
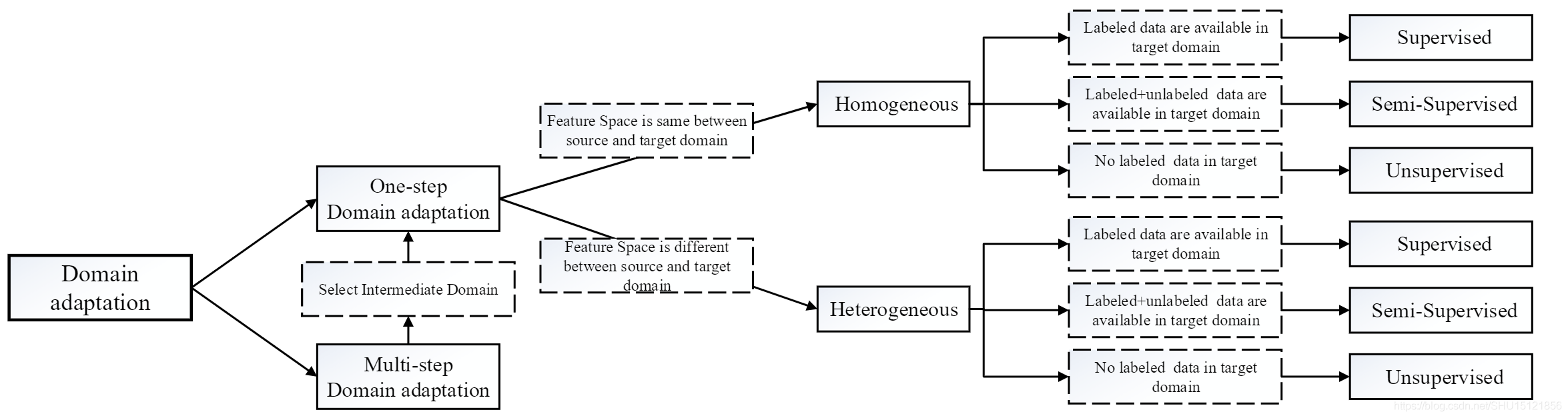
在领域自适应里面也会细分出很多方向。如果源域和目标域距离太大(比如源域是文字,目标域是图像),就可能需要进程多步的迁移,将这个非常大的迁移划分成一步一步的小段迁移,这就是下图中的多步领域自适应(Multi-step DA) 通过选择合适的中间域来转换成一个个单步领域自适应(One-step DA),这样就只要去研究单步迁移怎么做。
然后单步迁移又可以根据源域和目标域数据情况可以分成同质(Homogeneous,即数据空间一样,只是数据分布不一样)和异质(Heterogeneous,数据空间都不同)两种。
接下来,在同质或者异质的DA中又分别可以根据目标域数据的打标签情况分为监督的、半监督的、无监督的DA。学术界研究最多的是无监督的DA,这个比较困难而且价值比较高。
5 DA方法的种类
传统的的ML方法是最小化损失:
基于特征的自适应(Feature Adaption)是将源域样本和目标域样本用一个映射Φ 调整到同一个特征空间,这样在这个特征空间样本能够“对齐”,这也是最常用的方法:
基于实例的自适应(Instance Adaption)是考虑到源域中总有一些样本和目标域样本很相似,那么就将源域的所有样本的Loss在训练时都乘以一个权重(即表示“看重”的程度),和目标域越相似的样本,这个权重就越大:
基于模型参数的自适应(Model Adaption)是找到新的参数θ ′ 通过参数的迁移使得模型能更好的在目标域上工作:
如果目标域数据没有标签,就没法用Fine-Tune把目标域数据扔进去训练,这时候无监督的自适应方法就是基于特征的自适应。因为有很多能衡量源域和目标域数据的距离的数学公式,那么就能把距离计算出来嵌入到网络中作为Loss来训练,这样就能优化让这个距离逐渐变小,最终训练出来的模型就将源域和目标域就被放在一个足够近的特征空间里了。
这些衡量源域和目标域数据距离的数学公式有KL Divergence、MMD、H-divergence和Wasserstein distance等。
6 深度学习中的DA方法
注意,以下三种方法主体都属于5种基于特征的自适应方法。
6.1 基于差异的方法
例如经典的用于无监督DA的DDC方法,它是使用MMD(Maximum Mean Discrepancy) ,即找一个核函数,将源域和目标域都映射到一个再生核的Hilbert空间上,在这个空间上取这个两个域数据分别作均值之后的差,然后将这个差作为距离。用这个方法训练网络的Loss是:
其中第一项就是源域之前的模型的Loss(比如分类任务就是分类Loss),然后第二项是在指定层l ll上的MMD距离之和,乘了个表示重要性的系数λ \lambdaλ。在训练时有两个网络,一边是源域的,一边是目标域的,它们共享参数,然后在较深的某些层去计算MMD距离,然后按上面的公式那样加在一起作为整个模型的Loss。
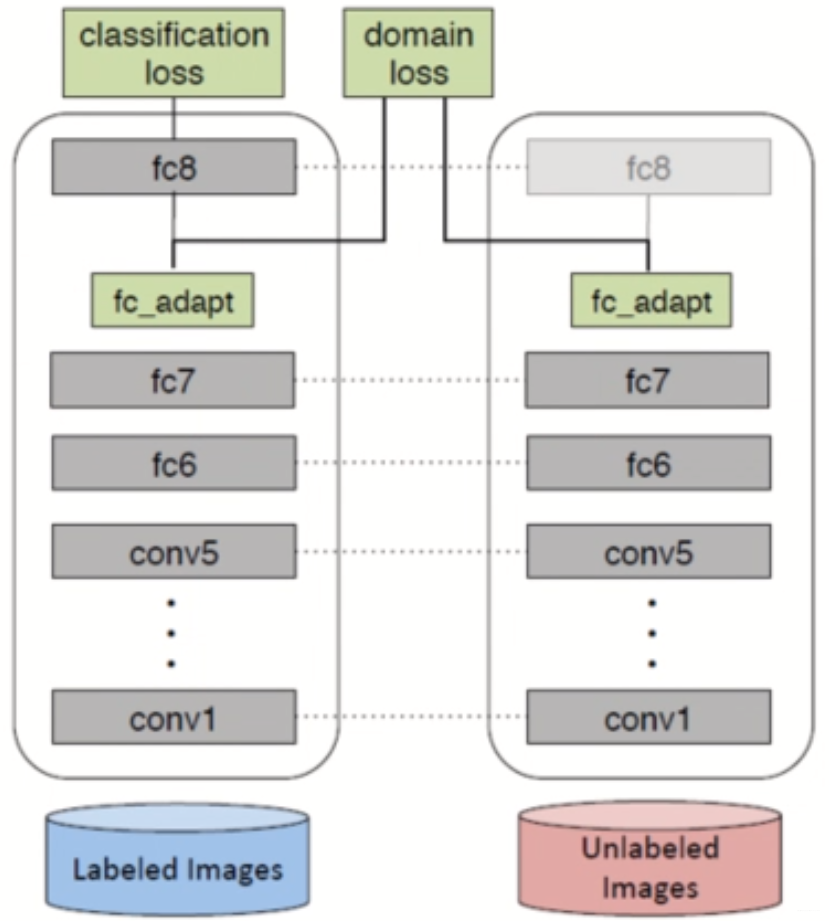
这个DDC方法有很多改进,比如DAN(ICML,2015) 就是用了多个核函数的线性组合,并且在多个层上计算MMD距离
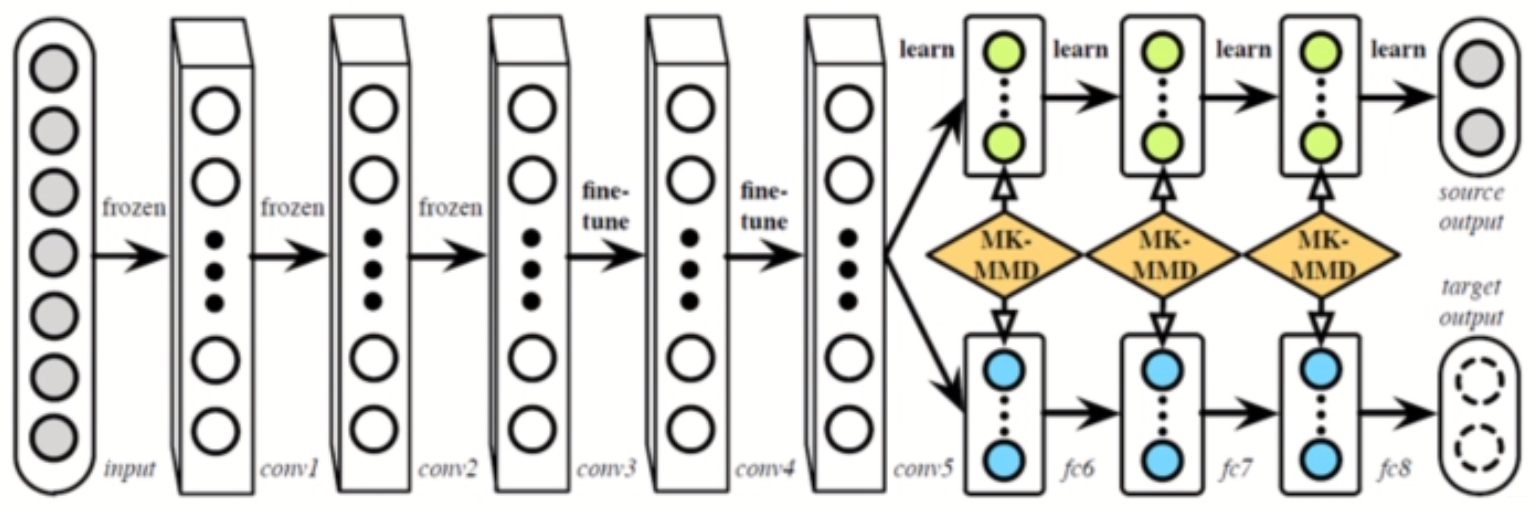
而RTN(NIPS,2016) 前半部分还是DAN,但是光靠DAN特征未必能对齐的那么好,所以在之前直接接源域分类器的地方改成了一个残差结构,用来学习源域和目标域分类器的差异。这种方法就是相当于在DAN上补充了5中基于模型参数的自适应方法。

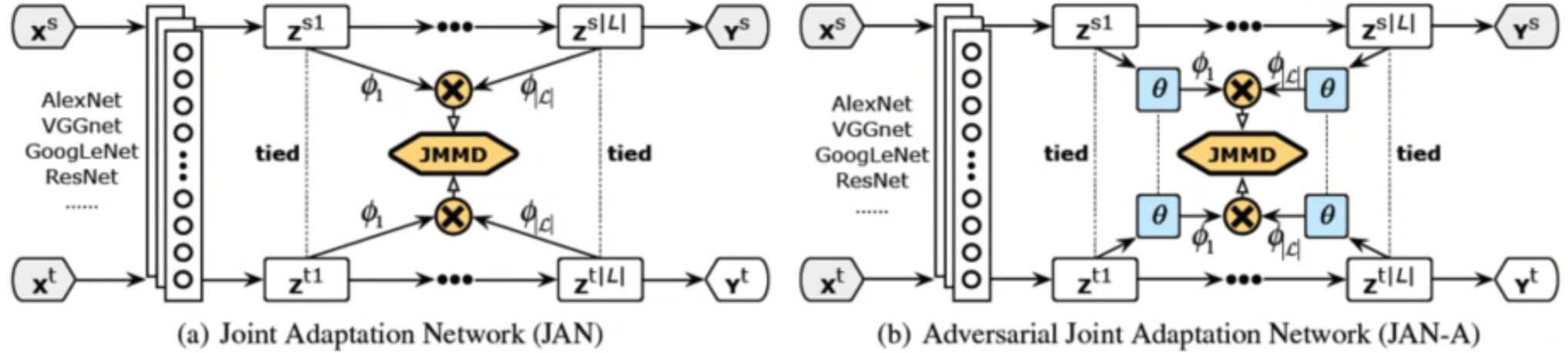
还有JAN(arXiv,2016) 里提出了一个JMMD(联合分布的MMD),通过优化这个JMMD能让源域和目标域特征和标签的联合分布更近,这样效果更好。
6.2 基于对抗的方法
如RevGrad(ICML,2015) 的基本思路就是用GAN去让生成器生成特征,然后让判别器判别它是源域的还是目标域的特征,如果判别不出来就说明在这个特征空间里源域和目标域是一致的。
下图中绿色部分是一个特征提取器,源域和目标域数据都扔进去,它就是用来生成(或者叫提取)特征的,然后紫色部分是对源域数据的特征做分类的分类器,红色部分是对源域数据和目标域数据的特征做判别的判别器,这个判别器要不断增强(能很好的判别是源域的还是目标域的特征),同时生成器也要增强,让生成出来的特征能混淆判别器的判别,这样最后生成(提取)出的特征就是源域和目标域空间里一致的了。
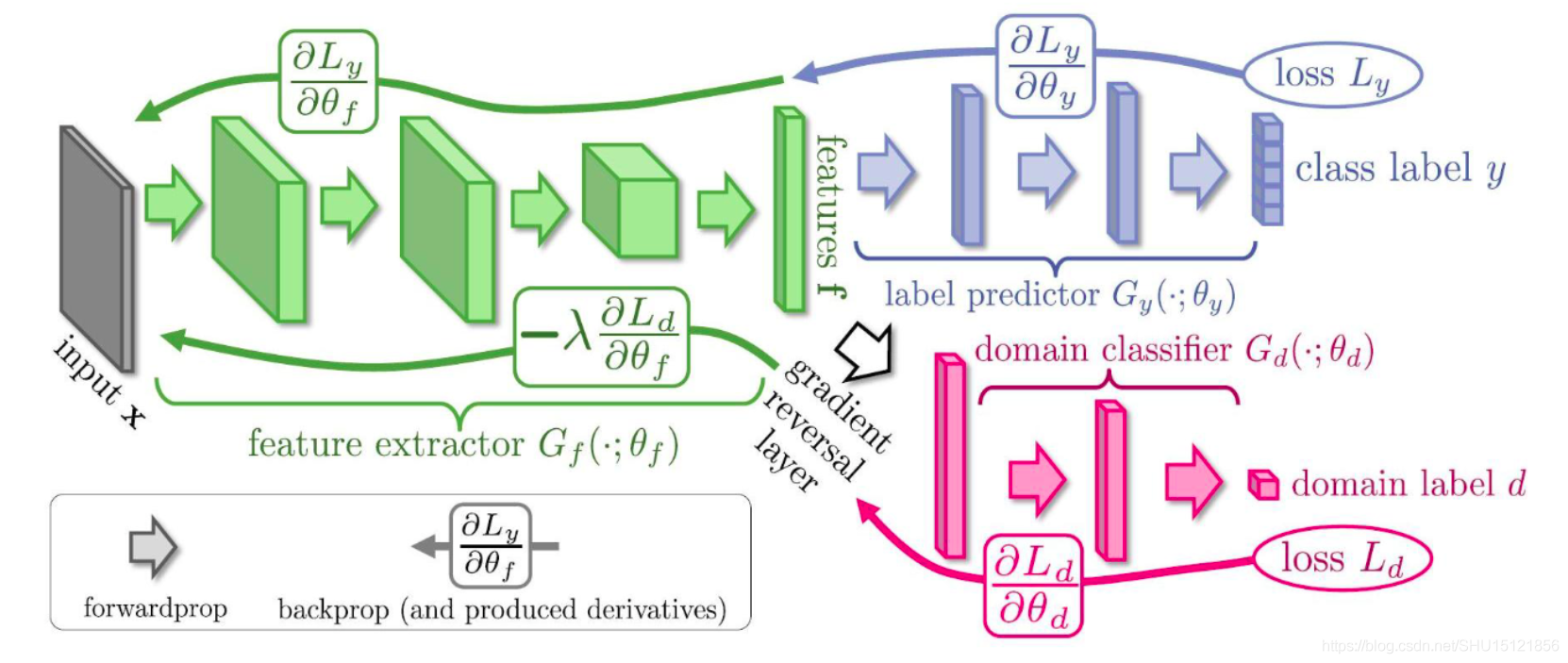
这个可以用GAN的最小化-最大化的思想去训练,也可以用论文中的梯度反转层(Gradient Reversal Layer) 的方法,就是在上图中白色空心箭头的位置加了个梯度反转层,在前向传播的过程中就是正常的网络,即最小化Loss让红色部分的判别器性能更好,再反向传播的过程中把梯度取负,即优化绿色部分的特征提取器,来尽量让红色部分的判别器分不清特征是源域的还是目标域的。这个方法就是一个训练技巧。
对于它的改进有CAN(CVPR,2018),它把深度网络连续的若干层作为一个block,这样划分成几个block,然后对每个block加一个判别器。它提出希望在网络高层的block中的特征和域的信息无关,因为最后要得到的就是不区分源域和目标域数据的网络;而希望在网络的低层的block中的特征和域的信息有关,因为底层在提取边缘信息,希望这些边缘信息能更好提取目标域的特征。
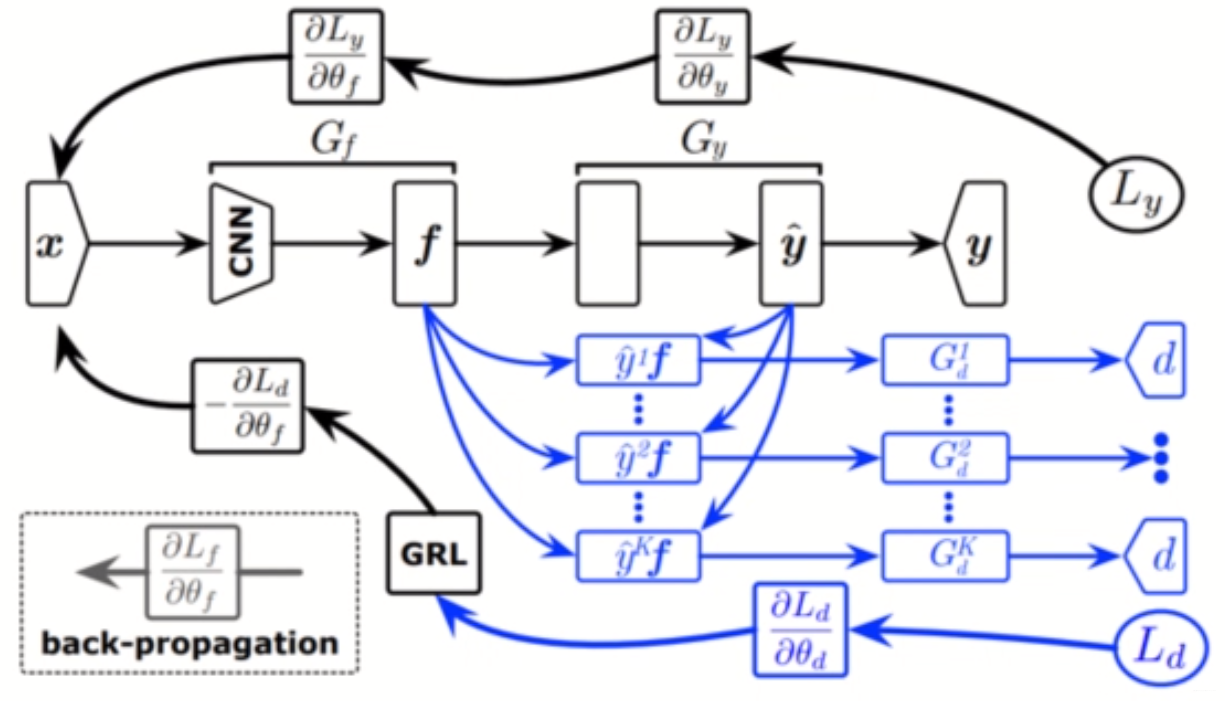
还有MADA(AAAI,2018)。之前的方法都是源域和目标域的类别都是相同的这些,但是有时候源域和目标域类别不一定相同,比如目标域类别可以是源域类别的子集。这个方法就是提出不应该是域到域的对齐,而是应该精细到类别到类别的对齐。这种方式就是只在最后一层用判别器,但是对于每个类别都单独使用一个判别器,这种就是引入语义信息(类别信息)的对齐,能让特征空间对齐的更好。但是因为在无监督的DA里目标域样本没有标签,所以这里要用源域分类器去对目标域样本输出属于每个类的概率,属于哪个类的概率更大就让那个类的判别器发挥更大的作用。这种方法就是相当于在RevGrad上补充了5种基于实例的自适应方法。
6.3 基于重构的方法
DRCN(2016,ECCV) 如下图结构,左侧是一个Encoder,也是将源域和目标域样本都扔进去生成特征用的,然后对于源域特征用一个分类器去分类,这样使得Encoder生成的特征能够很好的区分源域的样本(即是一个比较好的特征),对于目标域特征用一个Decoder去解码,使得能尽量还原目标域的样本。这样下来生成的特征所在的特征空间在源域和目标域样本上比较近。

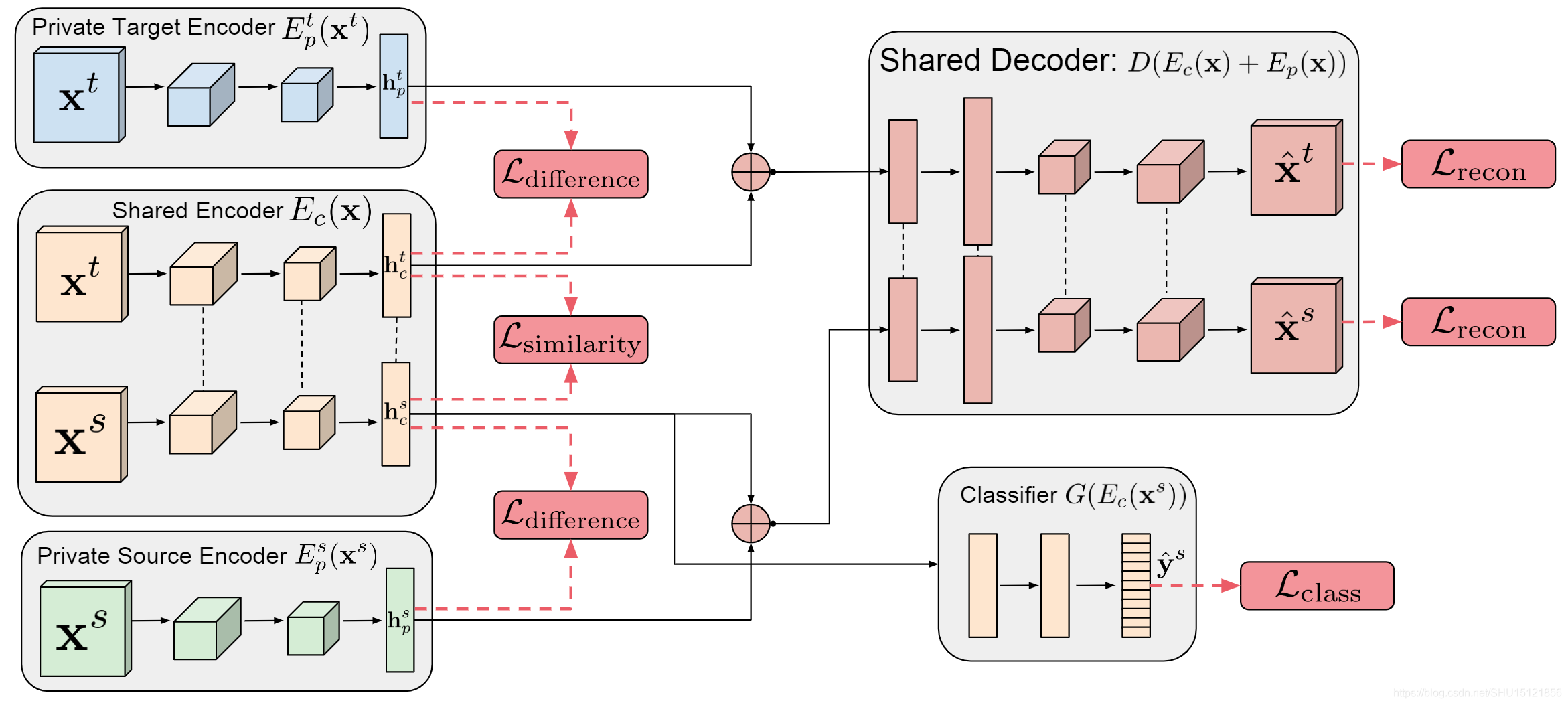
DSN(NIPS,2016) 将源域和目标域的样本分别拆分成两部分,一部分是两个域私有的Encoder,即尝试编码各自域中特定的信息,另一部分是两个域共有的Encoder,显然想到得到的就是这种共有特征。在分类时尽量让私有的特征和共有的特征正交,这样体现出它们更不相关,两个域各有一个损失 。还要保证私有特征和共有特征通过Decoder能尽可能还原出之前的样本,两个域各有一个损失
。还要保证两个域生成的共有特征尽可能相像,对应一个损失
。训练好后,用源域样本(生成的共有特征)训练一个分类器,这个分类器在目标域上也有较好的性能。