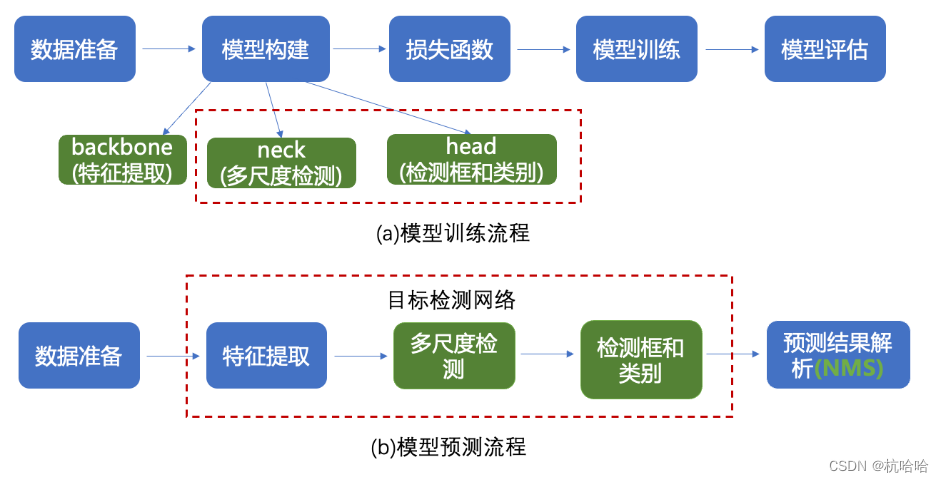
通用的视觉任务研发全流程:
1.数据处理
数据集结构:

insects包含train、val和test三个文件夹。train/annotations/xmls目录下存放着图片的标注。每个xml文件是对一张图片的说明,包括图片尺寸、包含的昆虫名称、在图片上出现的位置等信息。
常见的目标检测数据集如Pascal VOC采用的[x1,y1,x2,y2] 表示物体的bounding box, COCO采用的[x1,y1,w,h] 表示物体的bounding box。

1.1数据集预处理
(1)通过records描述读取图片及标注
# 数据读取
import cv2
def get_bbox(gt_bbox, gt_class):
# 对于一般的检测任务来说,一张图片上往往会有多个目标物体
# 设置参数MAX_NUM = 50, 即一张图片最多取50个真实框;如果真实
# 框的数目少于50个,则将不足部分的gt_bbox, gt_class和gt_score的各项数值全设置为0
MAX_NUM = 50
gt_bbox2 = np.zeros((MAX_NUM, 4))
gt_class2 = np.zeros((MAX_NUM,))
for i in range(len(gt_bbox)):
gt_bbox2[i, :] = gt_bbox[i, :]
gt_class2[i] = gt_class[i]
if i >= MAX_NUM:
break
return gt_bbox2, gt_class2
def get_img_data_from_file(record):
"""
record is a dict as following,
record = {
'im_file': img_file,
'im_id': im_id,
'h': im_h,
'w': im_w,
'is_crowd': is_crowd,
'gt_class': gt_class,
'gt_bbox': gt_bbox,
'gt_poly': [],
'difficult': difficult
}
"""
im_file = record['im_file']
h = record['h']
w = record['w']
is_crowd = record['is_crowd']
gt_class = record['gt_class']
gt_bbox = record['gt_bbox']
difficult = record['difficult']
img = cv2.imread(im_file)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# check if h and w in record equals that read from img
assert img.shape[0] == int(h), \
"image height of {} inconsistent in record({}) and img file({})".format(
im_file, h, img.shape[0])
assert img.shape[1] == int(w), \
"image width of {} inconsistent in record({}) and img file({})".format(
im_file, w, img.shape[1])
gt_boxes, gt_labels = get_bbox(gt_bbox, gt_class)
(2)数据增强
进行如下增强方法:
随机改变亮暗、对比度和颜色
随机填充
随机缩放
随机翻转
随机打乱真实框排列顺序
# 图像增广方法汇总
def image_augment(img, gtboxes, gtlabels, size, means=None):
# 随机改变亮暗、对比度和颜色等
img = random_distort(img)
# 随机填充
img, gtboxes = random_expand(img, gtboxes, fill=means)
# 随机缩放
img = random_interp(img, size)
# 随机翻转
img, gtboxes = random_flip(img, gtboxes)
# 随机打乱真实框排列顺序
gtboxes, gtlabels = shuffle_gtbox(gtboxes, gtlabels)
return img.astype('float32'), gtboxes.astype('float32'), gtlabels.astype('int32')
img_enhance, img_box, img_label = image_augment(srcimg, srcimg_gtbox, srcimg_label, size=320)
visualize(srcimg, img_enhance)
(3)dataset部分
import paddle
# 定义数据读取类,继承Paddle.io.Dataset
class TrainDataset(paddle.io.Dataset):
def __init__(self, datadir, mode='train'):
self.datadir = datadir
cname2cid = get_insect_names()
self.records = get_annotations(cname2cid, datadir)
self.img_size = 640 #get_img_size(mode)
def __getitem__(self, idx):
record = self.records[idx]
# print("print: ", record)
img, gt_bbox, gt_labels, im_shape = get_img_data(record, size=self.img_size)
return img, gt_bbox, gt_labels, np.array(im_shape)
def __len__(self):
return len(self.records)
# 创建数据读取类
train_dataset = TrainDataset(TRAINDIR, mode='train')
# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数
train_loader = paddle.io.DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=2, drop_last=True)
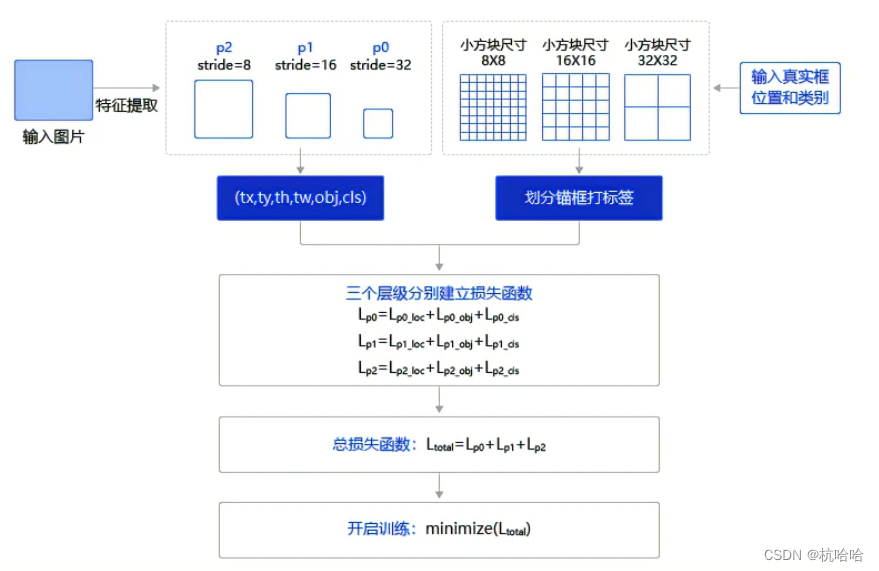
2.损失函数
def get_loss(num_classes, outputs, gtbox, gtlabel, gtscore=None,
anchors = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326],
anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
ignore_thresh=0.7,
use_label_smooth=False):
"""
使用paddle.vision.ops.yolo_loss
"""
losses = []
downsample = 32
for i, out in enumerate(outputs): # 对三个层级分别求损失函数
anchor_mask_i = anchor_masks[i]
loss = paddle.vision.ops.yolo_loss(
x=out, # out是P0, P1, P2中的一个
gt_box=gtbox, # 真实框坐标
gt_label=gtlabel, # 真实框类别
gt_score=gtscore, # 真实框得分,使用mixup训练技巧时需要,不使用该技巧时直接设置为1,形状与gtlabel相同
anchors=anchors, # 锚框尺寸,包含[w0, h0, w1, h1, ..., w8, h8]共9个锚框的尺寸
anchor_mask=anchor_mask_i, # 筛选锚框的mask,例如anchor_mask_i=[3, 4, 5],将anchors中第3、4、5个锚框挑选出来给该层级使用
class_num=num_classes, # 分类类别数
ignore_thresh=ignore_thresh, # 当预测框与真实框IoU > ignore_thresh,标注objectness = -1
downsample_ratio=downsample, # 特征图相对于原图缩小的倍数,例如P0是32, P1是16,P2是8
use_label_smooth=False) # 使用label_smooth训练技巧时会用到,这里没用此技巧,直接设置为False
losses.append(paddle.mean(loss)) #mean对每张图片求和
downsample = downsample // 2 # 下一级特征图的缩放倍数会减半
return sum(losses) # 对每个层级求和
也可以使用飞桨已经封装好的lossAPI
1.x: 输出特征图。
2.gt_box: 真实框。
3.gt_label: 真实框标签。
4.ignore_thresh,预测框与真实框IoU阈值超过ignore_thresh时,不作为负样本,YOLOv3模型里设置为0.7。
5.downsample_ratio,特征图P0的下采样比例,使用Darknet53骨干网络时为32。
6.gt_score,真实框的置信度,在使用了mixup技巧时用到。
7.use_label_smooth,一种训练技巧,如不使用,设置为False。
8.name,该层的名字,比如’yolov3_loss’,默认值为None,一般无需设置。
paddle.vision.ops.yolo_loss(x, gt_box, gt_label, anchors, anchor_mask, class_num, ignore_thresh, downsample_ratio, gt_score=None, use_label_smooth=True, name=None, scale_x_y=1.0)
3.模型训练
############# 这段代码在本地机器上运行请慎重,容易造成死机,我们可以使用较小的MAX_EPOCH运行#######################
import time
import os
import paddle
def get_lr(base_lr = 0.0001, lr_decay = 0.1):
bd = [10000, 20000]
lr = [base_lr, base_lr * lr_decay, base_lr * lr_decay * lr_decay]
learning_rate = paddle.optimizer.lr.PiecewiseDecay(boundaries=bd, values=lr)
return learning_rate
# MAX_EPOCH = 200
MAX_EPOCH = 1
ANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
IGNORE_THRESH = .7
NUM_CLASSES = 7
TRAINDIR = '/home/aistudio/work/insects/train'
TESTDIR = '/home/aistudio/work/insects/test'
VALIDDIR = '/home/aistudio/work/insects/val'
paddle.set_device("gpu:0")
# 创建数据读取类
train_dataset = TrainDataset(TRAINDIR, mode='train')
valid_dataset = TrainDataset(VALIDDIR, mode='valid')
test_dataset = TrainDataset(VALIDDIR, mode='valid')
# 使用paddle.io.DataLoader创建数据读取器,并设置batchsize,进程数量num_workers等参数
train_loader = paddle.io.DataLoader(train_dataset, batch_size=10, shuffle=True, num_workers=0, drop_last=True, use_shared_memory=False)
valid_loader = paddle.io.DataLoader(valid_dataset, batch_size=10, shuffle=False, num_workers=0, drop_last=False, use_shared_memory=False)
model = YOLOv3(num_classes = NUM_CLASSES) #创建模型
learning_rate = get_lr()
opt = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=0.9,
weight_decay=paddle.regularizer.L2Decay(0.0005),
parameters=model.parameters()) #创建优化器
# opt = paddle.optimizer.Adam(learning_rate=learning_rate, weight_decay=paddle.regularizer.L2Decay(0.0005), parameters=model.parameters())
if __name__ == '__main__':
for epoch in range(MAX_EPOCH):
for i, data in enumerate(train_loader()):
img, gt_boxes, gt_labels, img_scale = data
gt_scores = np.ones(gt_labels.shape).astype('float32')
gt_scores = paddle.to_tensor(gt_scores)
img = paddle.to_tensor(img)
gt_boxes = paddle.to_tensor(gt_boxes)
gt_labels = paddle.to_tensor(gt_labels)
outputs = model(img) #前向传播,输出[P0, P1, P2]
loss = get_loss(NUM_CLASSES, outputs, gt_boxes, gt_labels, gtscore=gt_scores,
anchors = ANCHORS,
anchor_masks = ANCHOR_MASKS,
ignore_thresh=IGNORE_THRESH,
use_label_smooth=False) # 计算损失函数
loss.backward() # 反向传播计算梯度
opt.step() # 更新参数
opt.clear_grad()
if i % 10 == 0:
timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time()))
print('{}[TRAIN]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy()))
# save params of model
if (epoch % 5 == 0) or (epoch == MAX_EPOCH -1):
paddle.save(model.state_dict(), 'yolo_epoch{}'.format(epoch))
# 每个epoch结束之后在验证集上进行测试
model.eval()
for i, data in enumerate(valid_loader()):
img, gt_boxes, gt_labels, img_scale = data
gt_scores = np.ones(gt_labels.shape).astype('float32')
gt_scores = paddle.to_tensor(gt_scores)
img = paddle.to_tensor(img)
gt_boxes = paddle.to_tensor(gt_boxes)
gt_labels = paddle.to_tensor(gt_labels)
outputs = model(img)
loss = get_loss(NUM_CLASSES,outputs, gt_boxes, gt_labels, gtscore=gt_scores,
anchors = ANCHORS,
anchor_masks = ANCHOR_MASKS,
ignore_thresh=IGNORE_THRESH,
use_label_smooth=False)
if i % 1 == 0:
timestring = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(time.time()))
print('{}[VALID]epoch {}, iter {}, output loss: {}'.format(timestring, epoch, i, loss.numpy()))
4.模型评估
当数据集中含有多个类别的物体时,需要做多分类非极大值抑制,实现代码如下面的multiclass_nms所示。
# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
# 非极大值抑制
def nms(bboxes, scores, score_thresh, nms_thresh, pre_nms_topk, i=0, c=0):
"""
nms
"""
inds = np.argsort(scores)
inds = inds[::-1]
keep_inds = []
while(len(inds) > 0):
cur_ind = inds[0]
cur_score = scores[cur_ind]
# if score of the box is less than score_thresh, just drop it
if cur_score < score_thresh:
break
keep = True
for ind in keep_inds:
current_box = bboxes[cur_ind]
remain_box = bboxes[ind]
iou = box_iou_xyxy(current_box, remain_box)
if iou > nms_thresh:
keep = False
break
if i == 0 and c == 4 and cur_ind == 951:
print('suppressed, ', keep, i, c, cur_ind, ind, iou)
if keep:
keep_inds.append(cur_ind)
inds = inds[1:]
return np.array(keep_inds)
# 多分类非极大值抑制
def multiclass_nms(bboxes, scores, score_thresh=0.01, nms_thresh=0.45, pre_nms_topk=1000, pos_nms_topk=100):
"""
This is for multiclass_nms
"""
batch_size = bboxes.shape[0]
class_num = scores.shape[1]
rets = []
for i in range(batch_size):
bboxes_i = bboxes[i]
scores_i = scores[i]
ret = []
for c in range(class_num):
scores_i_c = scores_i[c]
keep_inds = nms(bboxes_i, scores_i_c, score_thresh, nms_thresh, pre_nms_topk, i=i, c=c)
if len(keep_inds) < 1:
continue
keep_bboxes = bboxes_i[keep_inds]
keep_scores = scores_i_c[keep_inds]
keep_results = np.zeros([keep_scores.shape[0], 6])
keep_results[:, 0] = c
keep_results[:, 1] = keep_scores[:]
keep_results[:, 2:6] = keep_bboxes[:, :]
ret.append(keep_results)
if len(ret) < 1:
rets.append(ret)
continue
ret_i = np.concatenate(ret, axis=0)
scores_i = ret_i[:, 1]
if len(scores_i) > pos_nms_topk:
inds = np.argsort(scores_i)[::-1]
inds = inds[:pos_nms_topk]
ret_i = ret_i[inds]
rets.append(ret_i)
return rets
import json
import paddle
ANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
VALID_THRESH = 0.01
NMS_TOPK = 400
NMS_POSK = 100
NMS_THRESH = 0.45
NUM_CLASSES = 7
# 在验证集val上评估训练模型
TESTDIR = '/home/aistudio/work/insects/val/images' #请将此目录修改成用户自己保存测试图片的路径
WEIGHT_FILE = '/home/aistudio/yolo_epoch50.pdparams' # 请将此文件名修改成用户自己训练好的权重参数存放路径
# 在测试集test上评估训练模型
# TESTDIR = '/home/aistudio/work/insects/test/images'
# WEIGHT_FILE = '/home/aistudio/yolo_epoch50.pdparams'
if __name__ == '__main__':
model = YOLOv3(num_classes=NUM_CLASSES)
params_file_path = WEIGHT_FILE
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
total_results = []
test_loader = test_data_loader(TESTDIR, batch_size= 1, mode='test')
for i, data in enumerate(test_loader()):
img_name, img_data, img_scale_data = data
img = paddle.to_tensor(img_data)
img_scale = paddle.to_tensor(img_scale_data)
outputs = model.forward(img)
bboxes, scores = model.get_pred(outputs,
im_shape=img_scale,
anchors=ANCHORS,
anchor_masks=ANCHOR_MASKS,
valid_thresh = VALID_THRESH)
bboxes_data = bboxes.numpy()
scores_data = scores.numpy()
result = multiclass_nms(bboxes_data, scores_data,
score_thresh=VALID_THRESH,
nms_thresh=NMS_THRESH,
pre_nms_topk=NMS_TOPK,
pos_nms_topk=NMS_POSK)
for j in range(len(result)):
result_j = result[j]
img_name_j = img_name[j]
total_results.append([img_name_j, result_j.tolist()])
print('processed {} pictures'.format(len(total_results)))
print('')
json.dump(total_results, open('pred_results.json', 'w'))
5.模型预测
预测过程可以分为两步:
(1)通过get_pred函数预测框位置和所属类别的得分。
(2)使用非极大值抑制来消除重叠较大的预测框。

1.首先定义绘制预测框的画图函数:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.image import imread
import math
# 定义画图函数
INSECT_NAMES = ['Boerner', 'Leconte', 'Linnaeus',
'acuminatus', 'armandi', 'coleoptera', 'linnaeus']
# 定义画矩形框的函数
def draw_rectangle(currentAxis, bbox, edgecolor = 'k', facecolor = 'y', fill=False, linestyle='-'):
# currentAxis,坐标轴,通过plt.gca()获取
# bbox,边界框,包含四个数值的list, [x1, y1, x2, y2]
# edgecolor,边框线条颜色
# facecolor,填充颜色
# fill, 是否填充
# linestype,边框线型
# patches.Rectangle需要传入左上角坐标、矩形区域的宽度、高度等参数
rect=patches.Rectangle((bbox[0], bbox[1]), bbox[2]-bbox[0]+1, bbox[3]-bbox[1]+1, linewidth=1,
edgecolor=edgecolor,facecolor=facecolor,fill=fill, linestyle=linestyle)
currentAxis.add_patch(rect)
# 定义绘制预测结果的函数
def draw_results(result, filename, draw_thresh=0.5):
plt.figure(figsize=(10, 10))
im = cv2.imread(filename)
plt.imshow(im)
currentAxis=plt.gca()
colors = ['r', 'g', 'b', 'k', 'y', 'c', 'purple']
for item in result:
box = item[2:6]
label = int(item[0])
name = INSECT_NAMES[label]
if item[1] > draw_thresh:
draw_rectangle(currentAxis, box, edgecolor = colors[label])
plt.text(box[0], box[1], name, fontsize=12, color=colors[label])
2.读取指定的图片,输入网络并计算出预测框和得分,然后使用多分类非极大值抑制消除冗余的框。将最终结果画图展示出来
import json
import paddle
ANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
VALID_THRESH = 0.01
NMS_TOPK = 400
NMS_POSK = 100
NMS_THRESH = 0.45
NUM_CLASSES = 7
if __name__ == '__main__':
image_name = '/home/aistudio/work/insects/test/images/2642.jpeg'
params_file_path = '/home/aistudio/yolo_epoch50.pdparams'
model = YOLOv3(num_classes=NUM_CLASSES)
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
total_results = []
test_loader = test_data_loader(image_name, mode='test')
for i, data in enumerate(test_loader()):
img_name, img_data, img_scale_data = data
img = paddle.to_tensor(img_data)
img_scale = paddle.to_tensor(img_scale_data)
outputs = model.forward(img)
bboxes, scores = model.get_pred(outputs,
im_shape=img_scale,
anchors=ANCHORS,
anchor_masks=ANCHOR_MASKS,
valid_thresh = VALID_THRESH)
bboxes_data = bboxes.numpy()
scores_data = scores.numpy()
results = multiclass_nms(bboxes_data, scores_data,
score_thresh=VALID_THRESH,
nms_thresh=NMS_THRESH,
pre_nms_topk=NMS_TOPK,
pos_nms_topk=NMS_POSK)
result = results[0]
draw_results(result, image_name, draw_thresh=0.4)
