转:https://blog.csdn.net/zeuseign/article/details/72773342
github地址:https://github.com/tensorflow/models/tree/master/tutorials/image/cifar10
1. CIFAR-10
Cifar-10 是由 Hinton 的两个大弟子 Alex Krizhevsky、Ilya Sutskever 收集的一个用于普适物体识别的数据集。Cifar 是加拿大政府牵头投资的一个先进科学项目研究所。Hinton、Bengio和他的学生在2004年拿到了 Cifar 投资的少量资金,建立了神经计算和自适应感知项目。这个项目结集了不少计算机科学家、生物学家、电气工程师、神经科学家、物理学家、心理学家,加速推动了 Deep Learning 的进程。从这个阵容来看,DL 已经和 ML 系的数据挖掘分的很远了。Deep Learning 强调的是自适应感知和人工智能,是计算机与神经科学交叉;Data Mining 强调的是高速、大数据、统计数学分析,是计算机和数学的交叉。
Cifar-10 由60000张32*32的 RGB 彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类(姊妹数据集Cifar-100达到100类,ILSVRC比赛则是1000类)。

可以看到,同已经成熟的人脸识别相比,普适物体识别挑战巨大,数据中含有大量特征、噪声,识别物体比例不一。因而,Cifar-10 相对于传统图像识别数据集,是相当有挑战的。想了解更多信息请参考CIFAR-10 page,以及 Alex Krizhevsky 的技术报告。
2. 模型
在前面的博文中,我们已经利用 TensorFlow 建立起一个简单的手写数字识别的 MNIST 模型,主要参考 Yann LeCun 在 1998 年发表的论文 Gradient-Based Learning Applied to Document Recognition 中所提出的经典的 LeNet5网络:
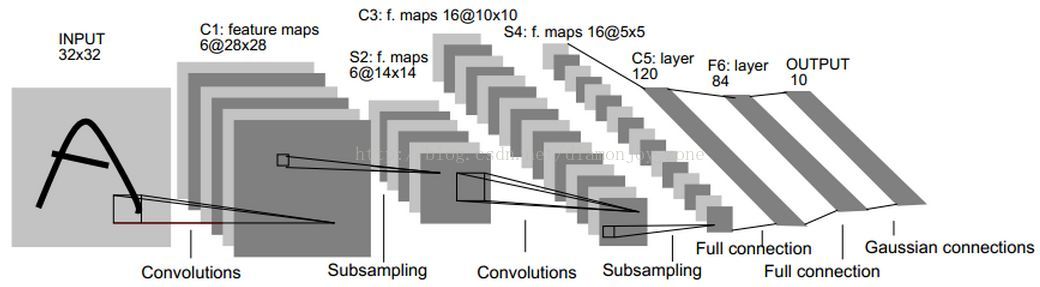
这个网络由卷积层、池化层、全连接层组成,通过梯度下降法对参数进行训练。但是面对复杂的普适物体分类问题,网络结构已经远远不能满足需求。
本篇博文将解析上篇 AlexNet 网络的针对普适物体分类问题采用的改良技术,防止模型过拟合和增强了范化能力:
- 对图片进行了翻转、随机剪切等数据增广(Data Augmentation);
- 在卷积-最大池化层后面使用局部响应归一化 (LRN);
- 采用修正线性激活 (ReLu)、Dropout、重叠 Pooling。
以及在 CIFAR-10 上的 TensorFlow 代码实现,加入了为输入数据设计预存取队列,网络行为的可视化,维护参数的滑动均值,设置学习率随着迭代递减,最后在 Losses 中加入对 weight 的 L2 正则训练,提高网络的训练速度和识别率。
本文将使用的代码结果和网络结构:
| 文件 | 说明 |
| cifar10_input.py | 读取本地CIFAR-10的二进制文件格式的内容 |
| cifar10.py | 建立CIFAR-10的模型 |
| cifar10_train.py | 在CPU或GPU上训练CIFAR-10的模型 |
| cifar10_multi_gpu_train.py | 在多GPU上训练CIFAR-10的模型。 |
| cifar10_eval.py | 评估CIFAR-10模型的预测性能 |

参考代码中提供了模型的多GPU版本,但本文只使用 CPU 运行。
3. 网络结构
CIFAR-10 网络模型部分的代码位于 cifar10.py,完整的训练图中包含约765个操作。通过下面的模块来构造训练图可以最大限度的提高代码复用率:
- 模型输入: 包括 inputs()、distorted_inputs() 等一些操作,分别用于读取 CIFAR-10 的图像并进行预处理,做为后续评估和训练的输入;
- 模型预测: 包括 inference() 等一些操作,用于进行统计计算,比如在提供的图像进行分类;
- 模型训练: 包括 loss() and train() 等一些操作,用于计算损失、计算梯度、进行变量更新以及呈现最终结果。
3.1 模型输入
输入模型是通过 cifar10_input.inputs() 和 cifar10_input.distorted_inputs() 函数建立起来的,这2个函数会从 CIFAR-10 二进制文件中读取图片文件,具体实现定义在 cifar10_input.py 中,使用的数据为 CIFAR-10 page 下的162M 的二进制文件,由于每个图片的存储字节数是固定的,因此可以使用 tf.FixedLengthRecordReader 函数。
载入图像数据后,通过以下流程进行数据增广:
- 统一裁剪到24x24像素大小,裁剪中央区域用于评估或随机裁剪用于训练;
- 对图像进行随机的左右翻转;
- 随机变换图像的亮度;
- 随机变换图像的对比度;
- 图片会进行近似的白化处理。
其中,白化(whitening)处理或者叫标准化(standardization)处理,是对图片数据减去均值,除以方差,保证数据零均值,方差为1,如此降低输入图像的冗余性,尽量去除输入特征间的相关性,使得网络对图片的动态范围变化不敏感。和 Caffe 中的均值文件一个原理。
在 Images 页的列表中查看所有可用的变换,对于每个原始图还添加 tf.summary.image,以便于在 TensorBoard中 查看:

从磁盘上加载图像并进行变换需要花费不少的处理时间。为了避免这些操作减慢训练过程,使用16个独立的线程中并行进行这些操作,这16个线程被连续的安排在一个 TensorFlow 队列中,最后返回预处理后封装好的tensor,每次执行都会生成一个 batch_size 数量的样本 [images,labels]。测试数据使用cifar10_input.inputs() 函数生成,测试数据不需要对图片进行翻转或修改亮度、对比度,需要裁剪图片正中间的24*24大小的区块,并进行数据标准化操作。
以上用到主要函数:
- maybe_download_and_extract(): # 下载并解压数据
- distorted_inputs(data_dir, batch_size): # 读入数据并数据增广
- read_cifar10(filename_queue): # 读取二进制数据
- tf.random_crop(); # 随机裁剪,旧版为tf.image.random_crop
- tf.image.random_flip_left_right(); # 左右翻转
- tf.image.random_brightness(); # 变换图像的亮度
- tf.image.random_contrast(); # 变换图像的对比度
- tf.image.per_image_standardization(); # 对图像进行标准化,旧版为 tf.image.per_image_whitening
- _generate_image_and_label_batch(); # 使用 tf.train.shuffle_batch() 创建多个线程从 tensor 队列中构建 batch
3.2 模型预测
模型的预测流程由 inference() 构造,输入为 images,输出为最后一层的 logits。
在建立模型之前,我们构造 weight 的构造函数 _variable_with_weight_decay(name, shape, stddev, wd),其中 wd 用于向 losses 添加L2正则化,可以防止过拟合,提高泛化能力:
- def _variable_with_weight_decay(name, shape, stddev, wd):
- var = _variable_on_cpu(name, shape,
- tf.truncated_normal_initializer(stddev=stddev))
- if wd:
- weight_decay = tf.multiply(tf.nn.l2_loss(var), wd, name='weight_loss')
- tf.add_to_collection('losses', weight_decay)
- return var
- # conv1
- with tf.variable_scope('conv1') as scope:
- kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],
- stddev=1e-4, wd=0.0)
- conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
- biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
- bias = tf.nn.bias_add(conv, biases)
- conv1 = tf.nn.relu(bias, name=scope.name)
- _activation_summary(conv1)
- # pool1
- pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
- padding='SAME', name='pool1')
- # norm1
- norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
- name='norm1')
第二层卷积层与第一层,除了输入参数的改变之外,将 biases 值全部初始化为0.1,调换最大池化和 LRN 层的顺序,先进行LRN,再使用最大池化层。
- # conv2
- with tf.variable_scope('conv2') as scope:
- kernel = _variable_with_weight_decay('weights', shape=[5, 5, 64, 64],
- stddev=1e-4, wd=0.0)
- conv = tf.nn.conv2d(norm1, kernel, [1, 1, 1, 1], padding='SAME')
- biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1))
- bias = tf.nn.bias_add(conv, biases)
- conv2 = tf.nn.relu(bias, name=scope.name)
- _activation_summary(conv2)
- # norm2
- norm2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
- name='norm2')
- # pool2
- pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1],
- strides=[1, 2, 2, 1], padding='SAME', name='pool2')
- # local3
- with tf.variable_scope('local3') as scope:
- # Move everything into depth so we can perform a single matrix multiply.
- reshape = tf.reshape(pool2, [FLAGS.batch_size, -1])
- dim = reshape.get_shape()[1].value
- weights = _variable_with_weight_decay('weights', shape=[dim, 384],
- stddev=0.04, wd=0.004)
- biases = _variable_on_cpu('biases', [384], tf.constant_initializer(0.1))
- local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)
- _activation_summary(local3)
- # softmax, i.e. softmax(WX + b)
- with tf.variable_scope('softmax_linear') as scope:
- weights = _variable_with_weight_decay('weights', [192, NUM_CLASSES],
- stddev=1/192.0, wd=0.0)
- biases = _variable_on_cpu('biases', [NUM_CLASSES],
- tf.constant_initializer(0.0))
- softmax_linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name)
- _activation_summary(softmax_linear)
- return softmax_linear
至此,整个网络的 inference 构建完毕,用 TensorBoard 可查看此结构:

3.3 损失函数
我们回忆之前利用交叉熵(cross entropy)计算 loss 的方法:
- y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2) + b_fc2)
- cross_entropy = tf.reduce_sum(-y_*tf.log(y_conv))
此处 y_conv 是通过 tf.nn.softmax 后的 logits 值(属于每个类别的概率值),shape 为 [batch_size, num_classes],每个样本的 logit 向量元素和为1;y_ 是 onehot encoding 后的 labels 值,shape 为 [batch_size, num_classes],每个样本的 label 元素中只有一个为1,其余为0。TensorFlow 在后面的版本中,提供了更加便捷的 API,合并了 softmax 和 cross entropy 的计算:
- cross_entropy_loss = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv)
- cross_entropy_loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels, name='cross_entropy_pre_example')
- tf.add_to_collection(name='losses', value=cross_entropy_loss)
- return tf.add_n(inputs=tf.get_collection(key='losses'), name='total_loss')
在定义 loss 之后,我们需要定义接受 loss 并返回 train op 的 train()。
首先定义学习率(learning rate),并设置随迭代次数衰减,并进行 summary:
- lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE, global_step, decay_steps, LEARNING_RATE_DECAY_FACTOR, staircase=True)
- tf.summary.scalar('learning_rate', lr)
- _add_loss_summaries(total_loss):
- # 创建一个新的指数滑动均值对象
- loss_averages = tf.train.ExponentialMovingAverage(0.9, name='avg')
- # 从字典集合中返回关键字'losses'对应的所有变量,包括交叉熵损失和正则项损失
- losses = tf.get_collection('losses')
- # 创建'shadow variables'并添加维护滑动均值的操作
- loss_averages_op = loss_averages.apply(losses + [total_loss])
- # Attach a scalar summary to all individual losses and the total loss; do the
- # same for the averaged version of the losses.
- for l in losses + [total_loss]:
- # Name each loss as '(raw)' and name the moving average version of the loss
- # as the original loss name.
- tf.summary.scalar(l.op.name +' (raw)', l)
- tf.summary.scalar(l.op.name, loss_averages.average(l))
- return loss_averages_op
然后,我们定义训练方法与目标,tf.control_dependencies 是一个 context manager,控制节点执行顺序,先执行[ ]中的操作,再执行 context 中的操作:
- loss_averages_op = _add_loss_summaries(total_loss) # 损失变量的更新操作
- with tf.control_dependencies([loss_averages_op]):
- opt = tf.train.GradientDescentOptimizer(lr)
- grads = opt.compute_gradients(total_loss) # 返回计算出的(gradient, variable) pairs
- # 返回一步梯度更新操作
- apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
- variable_averages = tf.train.ExponentialMovingAverage(
- MOVING_AVERAGE_DECAY, global_step)
- variables_averages_op = variable_averages.apply(tf.trainable_variables())
- with tf.control_dependencies([apply_gradient_op, variables_averages_op]):
- train_op = tf.no_op(name='train')
- return train_op
4. 训练过程
上述步骤完成了数据的输入,模型预测,损失和训练的定义,接下来依次调用,建立训练和汇总过程:
- def train():
- """Train CIFAR-10 for a number of steps."""
- # 指定当前图为默认graph
- with tf.Graph().as_default():
- # 设置trainable=False,是因为防止训练过程中对global_step变量也进行滑动更新操作
- global_step = tf.Variable(0, trainable=False)
- # Get images and labels for CIFAR-10.
- # 输入图像的预处理,包括亮度、对比度、图像翻转等操作
- images, labels = cifar10.distorted_inputs()
- # Build a Graph that computes the logits predictions from the
- # inference model.
- logits = cifar10.inference(images)
- # Calculate loss.
- loss = cifar10.loss(logits, labels)
- # Build a Graph that trains the model with one batch of examples and
- # updates the model parameters.
- train_op = cifar10.train(loss, global_step)
- # 创建一个saver对象,用于保存参数到文件中
- saver = tf.train.Saver(tf.global_variables())
- # 返回所有summary对象先merge再serialize后的的字符串类型tensor
- summary_op = tf.summary.merge_all()
- # log_device_placement参数可以记录每一个操作使用的设备,这里的操作比较多,故设置为False
- sess = tf.Session(config=tf.ConfigProto(
- log_device_placement=FLAGS.log_device_placement))
- # 变量初始化
- init = tf.global_variables_initializer()
- sess.run(init)
- ckpt = tf.train.get_checkpoint_state(FLAGS.train_dir)
- if ckpt and ckpt.model_checkpoint_path:
- # Restores from checkpoint
- saver.restore(sess, ckpt.model_checkpoint_path)
- print ("restore from file")
- else:
- print('No checkpoint file found')
- # 启动所有的queuerunners
- tf.train.start_queue_runners(sess=sess)
- summary_writer = tf.summary.FileWriter(FLAGS.train_dir,
- graph=sess.graph)
- for step in xrange(FLAGS.max_steps):
- start_time = time.time()
- _, loss_value = sess.run([train_op, loss])
- duration = time.time() - start_time
- # 用于验证当前迭代计算出的loss_value是否合理
- assert not np.isnan(loss_value), 'Model diverged with loss = NaN'
- if step % 10 == 0:
- num_examples_per_step = FLAGS.batch_size
- examples_per_sec = num_examples_per_step / duration
- sec_per_batch = float(duration)
- format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
- 'sec/batch)')
- print (format_str % (datetime.now(), step, loss_value,
- examples_per_sec, sec_per_batch))
- if step % 100 == 0:
- summary_str = sess.run(summary_op)
- summary_writer.add_summary(summary_str, step)
- # Save the model checkpoint periodically.
- if step % 1000 == 0 or (step + 1) == FLAGS.max_steps:
- checkpoint_path = os.path.join(FLAGS.train_dir, 'model.ckpt')
- saver.save(sess, checkpoint_path, global_step=step)
需要注意的是,一定要运行 start_queue_runners 启动前面提到的图片数据增广的线程,这里一共使用来16个线程来进行加速。
在每一 step 的训练过程中,需要先使用 session 的 run 方法执行对 images、labels 组成的 batch 传入 train_op 和 loss 的计算,记录每一个 step 花费的时间,每隔10个 step 会计算并展示当前的 loss,每秒钟训练的样本数量,以及训练一个 batch 数据所花费的时间,这样就可以比较方便地监控整个训练过程。
通过执行脚本 Python cifar10_train.py 启动训练过程,第一次在 CIFAR-10 上启动任何任务时,会自动下载 CIFAR-10 数据集,该数据集大约有160M大小,随后输出:
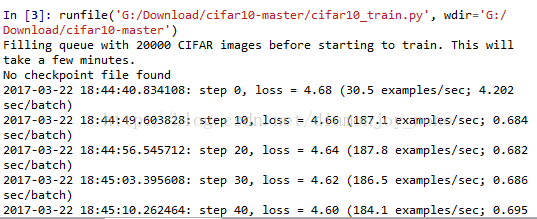
5. 模型评价
cifar10_train.py 会周期性的在检查点文件中保存模型中的所有参数,但是不会对模型进行评估。cifar10_eval.py 会使用该检查点文件在另一部分数据集上测试预测性能。利用 inference() 函数重构模型,并使用了在评估数据集所有10,000张 CIFAR-10 图片进行测试。最终计算出的精度为 1 : N,N = 预测值中置信度最高的一项与图片真实 label 匹配的频次。为了监控模型在训练过程中的改进情况,评估用的脚本文件会周期性的在最新的检查点文件上运行,这些检查点文件是由上述的 cifar10_train.py 产生。
运行 cifar10_eval.py 文件后我们可以得到类似这样的输出:
- 2017-03-22 19:00:00.223784: precision @ 1 = 0.099
我们在训练脚本会为所有学习变量计算其滑动均值(Moving Average),评估脚本则直接将所有学习到的模型参数替换成对应的滑动均值,这一替代方式可以在评估过程中提升模型的性能。