前言:数据标准化就是使数据分布服从均值为0,方差为1的标准正态分布(高斯分布),是深度神经网络中常用的一种手段,常用在激活函数之前。它的使用可以加快模型训练时的收敛速度,使模型训练过程更加稳定,可以起到缓解梯度消失和梯度爆炸,缓解过拟合等作用。常见的标准化操作有4种:Batch Normalization(BN)、Layer Normalization(LN)、Instance Normalization(IN)、Group Normalization(GN)。下面将详细讲解这4种标准化操作的异同点以及BN的优点。
目录
1、BN原理
BN叫做批标准化或批归一化,BN的使用非常有利于神经网络的训练。下面就是BN的算法流程:

算法流程中的最后一步叫做affine transform,它可以增强模型的容纳能力,使得模型更加灵活。BN算法如果进行到标准化这一步结束,就会导致网络表达能力下降,因为标准化之后会将大部分数据强制转换到这个区间,而一些数据本不需要标准化才能更好地表征某个数据特征,强制标准化之后就会导致网络学不到数据的这部分特征。affine transform这步操作就能很好的解决网络表达能力下降的这个问题,因为当
,
时,affine transform就相当于标准化的逆操作,可以将本不需要而又被强制标准化了的这部分数据还原成原数据
,实际上网络是可以自己学习到
,
这两个参数的,需不需要对数据进行标准化交给网络自己决定,并且此时还原后的
不受权重参数
的影响,这就大大提高了网络的表达能力,让BN在深度学习过程中大放异彩。
然而在测试时无法得到和
,那么怎么解决这个问题呢?实际上,往往是通过用训练实例中获得的所有
和
的加权平均的统计值来代替测试时的
和
,这些问题的解决方案都被封装到了各种深度学习框架中,我们直接调用就行了,使用时不需要思考这个问题,但理论上我们需要大概知道其原理。也就是说BN在模型训练和测试阶段的情况是不一样的,写代码时尤其要注意这个地方,和Dropout一样,在训练阶段的代码之前要使用train()函数,表示模型进入训练阶段,此时除了正常使用BN算法,还要额外统计训练实例中获得的所有
和
的加权平均;在测试阶段的代码之前要使用eval()函数,表示模型进入测试阶段,此时BN算法中的
和
由训练阶段所有训练实例均值和方差的统计值代替。
讲到这里,大家可能还会有疑问,就是和
的获取方式是怎样的,下面以Pytorch中提供的nn.BatchNorm1d、nn.BatchNorm2d、nn.BatchNorm3d这三个批标准化函数进行讲解。
①nn.BatchNorm1d -> input = batchsize * 特征数 * 1d特征(batchsize就是样本数)
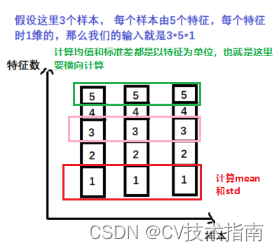
②nn.BatchNorm2d -> input = batchsize * 特征数 * 2d特征 (此时特征数可以理解为通道数,一个通道相当于一个特征)
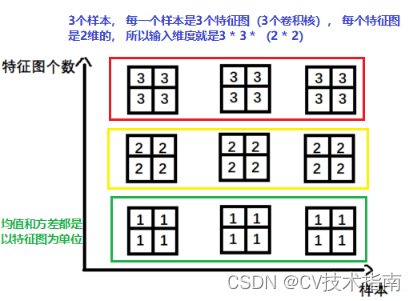
③nn.BatchNorm3d -> input = batchsize* 特征数 * 3d特征
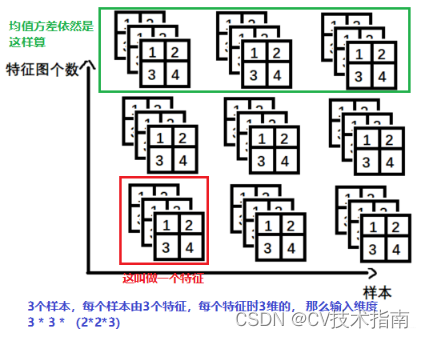
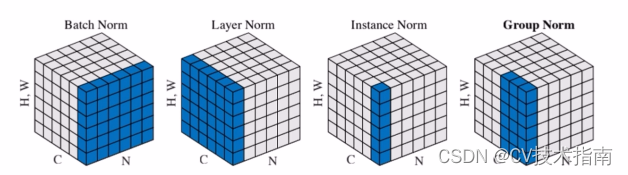
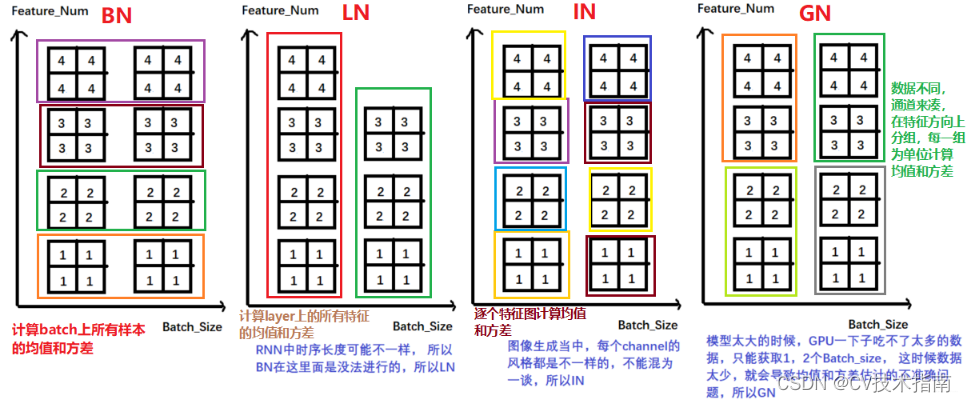
2、BN、LN、IN、GN的异同点
这4种标准化操作在算法流程上是类似的,区别就是它们在 和
的获取方式上不同,BN上面已经具体讲了,下面讲讲其它三种。
①Layer Normalization
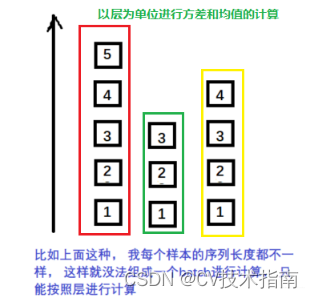
BN不适用于变长的网络,如RNN, 所以提出了逐层计算均值和方差的思路。LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差。
②Instance Normalization

BN在图像生成中不适用, 所以就提出了逐个Instance(channel)计算均值和方差。比如在图像风格迁移中,每一个样本的风格是不一样的,所以我们不能像BN那样从多个样本里面去计算平均值和方差了。
③Group Normalization
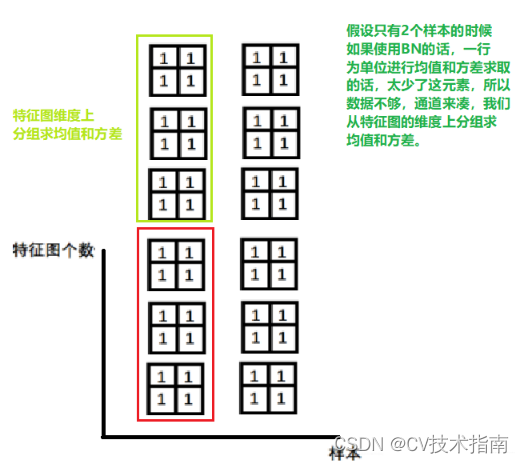
小batch样本中, BN估计的值不准, GN这种Normalization的思路就是数据不够, 通道来凑, 一样用于大模型(小batch size)的任务 。GN有点LN的感觉,只不过相当于对LN进行了分组。
总结:BN, LN, IN和GN都是为了克服内部协变量偏移(Internal Covariate Shift(ICS))提出来的,它们的计算公式差不多,只不过计算均值和方差的时候采用的方式不同。
3、BN的作用
3.1 加快网络收敛速度
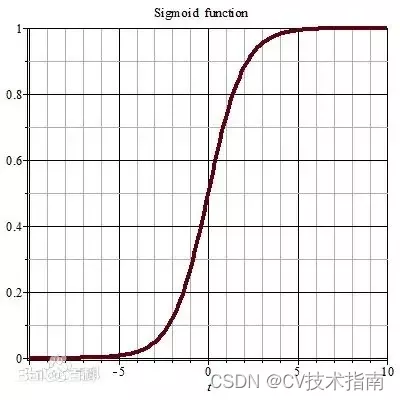
之所以训练时网络收敛速度越来越慢,是因为深层神经网络在做非线性变换前的值(网络中间层(即隐藏层)各神经元的值)随着网络深度加深或者在训练过程中,其分布逐渐往非线性函数取值区间的上下限两端偏移或者变动,对于大部分非线性函数来说(比如Sigmoid函数,它的两端梯度较小,靠近0附近的梯度较大),其两端的梯度较小,这将导致网络参数在更新前后几乎没有什么变化,使得网络的收敛速度越来越慢。
而引入BN层后,可以把网络中间层任意神经元值的分布强行拉回到均值为0方差为1的标准正态分布中,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得进行非线性变换前的值落在非线性函数梯度较大的区域(即0附近),这样这个值即使发生一点点小变化也会导致损失函数发生较大的变化,那么损失反向传播时参数更新前后变化较大,即每更新一次参数,损失都会得到较大程度的减小,从而加快了网络收敛速度。
3.2 缓解梯度爆炸和防止梯度消失
以sigmoid函数为例,sigmoid函数使得输出在[0,1]之间,实际上当输入到了一定大小,即使输入变化很大,经过sigmoid函数后,其输出值变化也很小,如下图所示。
3.2.1 防止梯度消失(效果非常明显)
在深度神经网络中,很容易出现梯度消失现象。如果网络的激活输出(相对于非线性层,它就是输入)很大,其对应的梯度就会很小,导致网络的学习速率就会很慢,假设网络中每层的学习梯度都小于最大值0.25,网络中有n层,因为链式求导的原因,第一层的梯度将会小于0.25的n次方,所以学习速率相对来说会变的很慢,而对于网络的最后一层只需要对自身求导一次,梯度就大,学习速率就会比较快,这就会造成在一个很深的网络中,浅层基本不学习,权值变化小,而后面几层网络一直学习,后面的网络基本可以表征整个网络,这样失去了深度的意义。使用BN层之后,把所有特征层越来越偏的分布强制拉回比较标准的分布,这样使得进行非线性变换前的值落在非线性函数梯度较大的区域(即0附近),这样即使是浅层网络的参数也会有相对较大的梯度,防止了梯度消失,使得浅层网络的参数也得到了学习(即参数得到了更新)。
3.2.2 缓解梯度爆炸(效果不明显)
在深度神经网络中,只要参数初始化合理,发生梯度爆炸的几率较小,但还是有可能发生。第n层损失对参数的梯度=激活层斜率1x后面层权重1x激活层斜率2x后面层权重2……×神经元的值,假如激活层斜率均为最大值0.25,神经元某一时刻的值为100,而随着网络训练的进行,某些神经元的值可能越来越大,从而导致梯度爆炸,当然这不是梯度爆炸的主要原因。而使用BN层后,神经元值的分布会被强行映射到均值为0方差为1的正太分布中,也就是各神经元值的范围是(-1,1),这样就可以轻微降低浅层网络的梯度,较小程度上缓解了梯度爆炸,使得网络的训练能够进行下去。
3.3 防止过拟合
在网络的训练中,BN的使用使得一个batch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取决于跟这个样本同属一个batch的其他样本,而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习,一定程度上避免了过拟合。