训练模型发现loss很大,原因之一是数据未归一化处理?
在深度学习中,归一化(Normalization)和标准化(Standardization)是两种常见的数据预处理技术,用于将输入数据调整到合适的范围,以提高模型的训练效果。虽然它们的目标相似,但归一化和标准化在具体实施和效果上有所区别。
1、归一化(Normalization)通常是指将数据缩放到0和1之间的范围。最常见的归一化方法是将每个样本的特征值减去最小值,然后除以最大值和最小值之间的差值。这样可以确保所有特征值都落在0到1的范围内。归一化可以保留原始数据的分布形状,但可能对异常值比较敏感。它在特征的取值范围未知或差异较大时特别有用。
对于图像来说,归一化后只是从[0,255] 变成 [0,1] 但显示出来是一样的。

def Transform(data):
max = data.max()
min = data.min()
return (data - min) / (max - min)2、标准化(Standardization)是将数据转换为均值为0,标准差为1的分布。标准化通过减去均值,然后除以标准差来实现。标准化后的数据具有零均值和单位方差,使得所有特征具有相似的尺度。标准化通常对异常值比较鲁棒,但会改变原始数据的分布形状。标准化在特征的取值范围已知并且差异不大时常常使用。
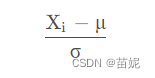
import torchvision.transforms as transforms
transforms.Normalize(mean = (0.485, 0.456, 0.406), std = (0.229, 0.224, 0.225))简而言之,归一化将数据缩放到0和1之间,保留数据分布的形状,对取值范围未知或差异较大的特征适用。标准化将数据转换为均值为0,标准差为1的分布,使得所有特征具有相似的尺度,对取值范围已知且差异不大的特征适用。选择使用哪种方法取决于数据的特点和具体任务的需求。