目标检测 DETR:End-to-End Detection with Transformer
detr是facebook提出的引入transformer到目标检测领域的算法,效果很好,做法也很简单,相较于RCNN和YOLO系列算法,避免了Proposal/Anchor+NMS的复杂流程。
1. detr基本架构
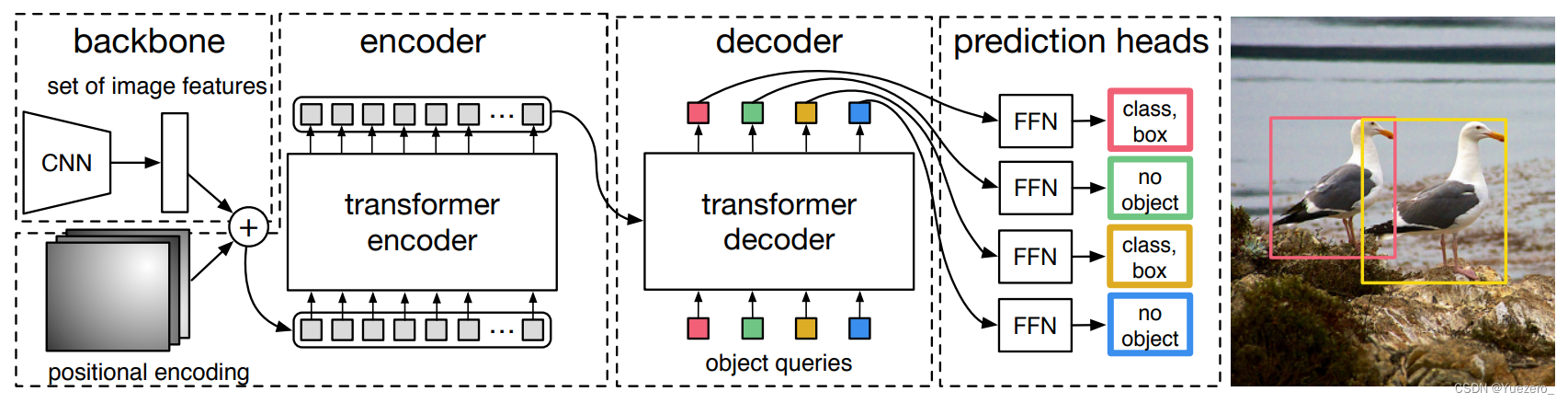
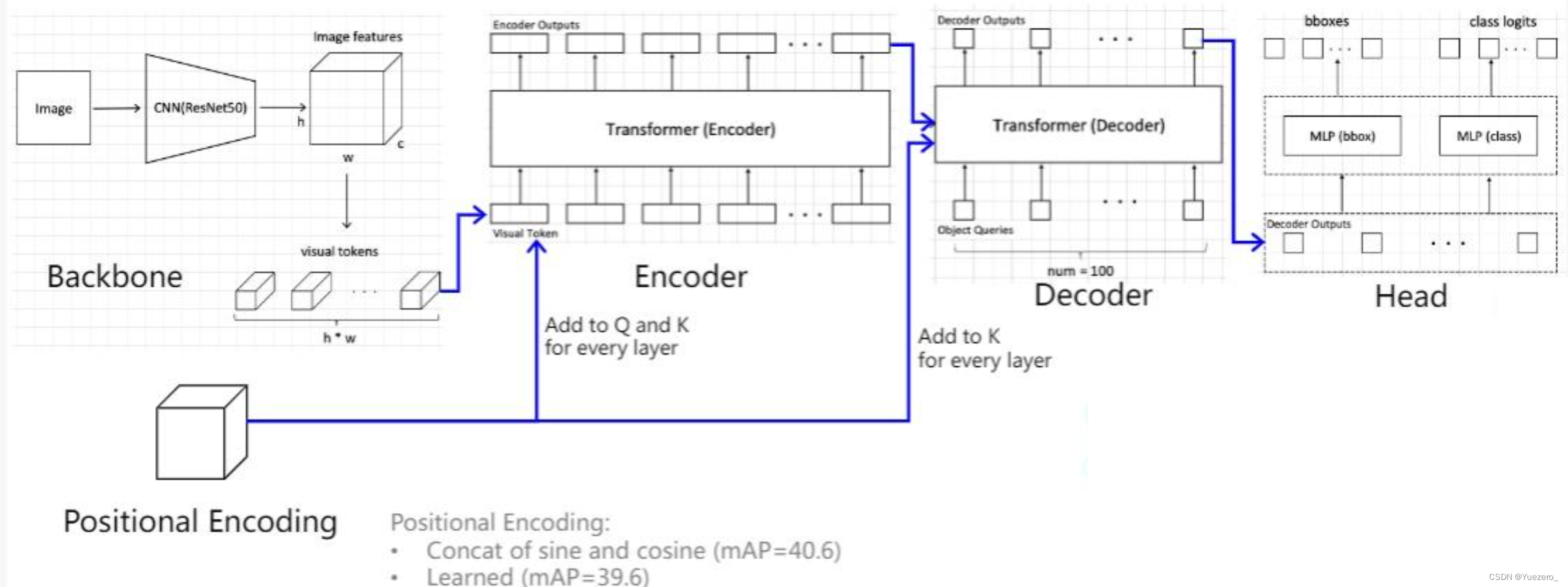
对于目标检测任务,其要求输出给定图片中所有前景物体的类别和bbox坐标,该任务实际上是无序集合预测问题。针对该问题,detr做法非常简单:给定一张图片,经过CNN进行特征提取,然后变成特征序列输入到transformer的编解码器中,直接输出指定长度为N的无序集合,集合中每个元素包含物体类别和坐标。 其中N表示整个数据集中图片上最多物体的数目(默认100),因为整个训练和测试都Batch进行,如果不设置最大输出集合数,无法进行batch训练,如果图片中物体不够N个,那么就采用no object填充,表示该元素是背景。

整个思想看起来非常简单,相比faster rcnn或者yolo算法那就简单太多了,因为其不需要设置先验anchor,超参几乎没有,也不需要nms(因为输出的无序集合没有重复情况),并且在代码程度相比faster rcnn那就不知道简单多少倍了,通过简单修改就可以应用于全景分割任务。
相比faster rcnn等做法,detr最大特点是将目标检测问题转化为无序集合预测问题(所有前景物体集合: 类别+bbox坐标),直接预测N=100个坐标框和类别概率。论文中特意指出faster rcnn这种设置一大堆anchor,然后基于anchor进行分类和回归其实属于代理(anchor作为代理中介),这种做法不是最直接做法,目标检测任务就是输出无序集合,而faster rcnn等算法通过各种操作,并结合复杂后处理最终才得到无序集合属于绕路了,而detr就比较纯粹了。
1.1 Backnone(CNN+PE)
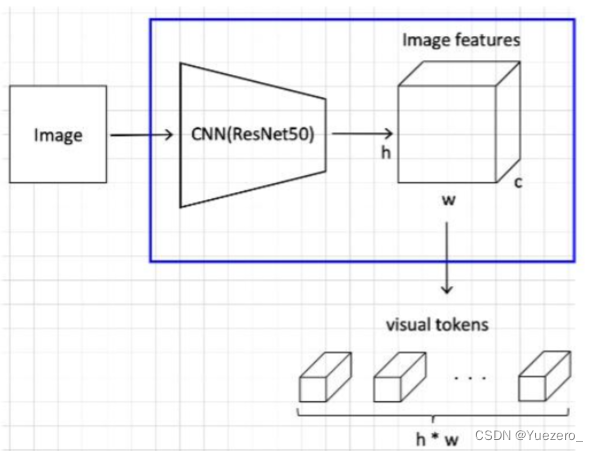
输入图片(b,c,h,w) 经过backbone网络完成特征提取的工作,这里用的是Resnet50,得到最终的feature map维度为(b,2048,h//32,w//32),其中h’=h//32和w’=w//32(类似于将图像划分为32x32的patch,共h'xw'个patch),因为2048比较大,为了节省计算量,先采用1x1卷积降维为256,(b,256,h//32,w//32),然后将最终的feature map进行展开,每个batch_size展开成h'xw'个 token,每个token长度为 c=256 的visual tokens,Encoder的输入shape=(h' x w', b, 256)。
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
# 输出是(b,256,h//32,w//32)
src=self.input_proj(src)
# 变成序列模式,(h'xw',b,256),256是每个词的编码长度
src = src.flatten(2).permute(2, 0, 1)
1.2 Transformer 编码器
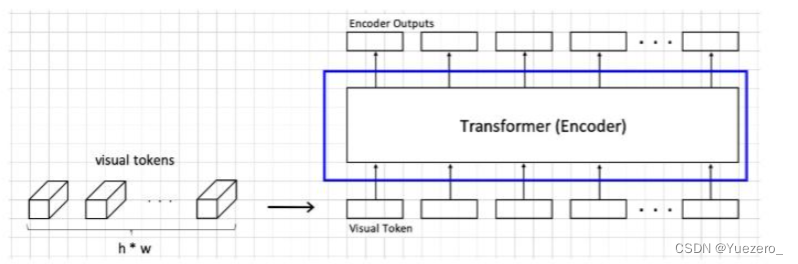
encoder就是类似于之前VIT的结构,它的输入和输出tokens的维度和数量不变,内部transformer的结构大同小异,就知道它是综合输入各个tokens之间关系的结构就行了。
注意:在DETR的encoder中,只给K、Q加了spatial positional encoding,而且这里的spatial positional encoding在encoder的每一层都有加,之前只是在encoder的第一层加上,这里可以理解为,目标检测任务是一个特别看重位置的任务,每一层都加的话会不断强化patches的位置关系。
a) 位置编码需要考虑2d空间
由于图像特征是2d特征,故位置嵌入向量也需要考虑xy方向。前面说过编码方式可以采用sincos,也可以设置为可学习,本文采用的依然是sincos模式,和前面说的一样,但是需要考虑xy两个方向(前面说的序列只有x方向)。
#输入是b,c,h,w
#tensor_list的类型是NestedTensor,内部自动附加了mask,
#用于表示动态shape,是pytorch中tensor新特性https://github.com/pytorch/nestedtensor
x = tensor_list.tensors # 原始tensor数据
# 附加的mask,shape是b,h,w 全是false
mask = tensor_list.mask
not_mask = ~mask
# 因为图像是2d的,所以位置编码也分为x,y方向
# 1 1 1 1 .. 2 2 2 2... 3 3 3...
y_embed = not_mask.cumsum(1, dtype=torch.float32)
# 1 2 3 4 ... 1 2 3 4...
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
# 0~127 self.num_pos_feats=128,因为前面输入向量是256,编码是一半sin,一半cos
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
# 归一化
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
# 输出shape=b,h,w,128
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# 每个特征图的xy位置都编码成256的向量,其中前128是y方向编码,而128是x方向编码
return pos # b,n=256,h,w
可以看出对于h//32,w//32的2d图像特征,不是类似vision transoformer做法简单的将其拉伸为h//32 x w//32,然后从0-n进行长度为256的位置编码,而是考虑了xy方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特定。
b) QKV处理逻辑不同
作者设置编码器一共6个,并且位置编码向量仅仅加到QK中,V中没有加入位置信息,这个和原始做法不一样,原始做法是QKV都加上了位置编码,论文中也没有写为啥要如此修改。
其余地方就完全相同了,故代码就没必要贴了。总结下和原始transformer编码器不同的地方:
- 输入编码器的位置编码需要考虑2d空间位置
- 位置编码向量需要加入到每个编码器中(在每层的Attention之前+PE)
- 在编码器内部位置编码仅仅和QK相加,V不做任何处理
- 经过6个编码器forward后,输出shape为(h//32xw//32,b,256)。
# 6个编码器整体forward流程如下:
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
# 编码器copy6份
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 内部包括6个编码器,顺序运行
# src是图像特征输入,shape=hxw,b,256
output = src
for layer in self.layers:
# 每个编码器都需要加入pos位置编码
# 第一个编码器输入来自图像特征,后面的编码器输入来自前一个编码器输出
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
return output
# 每个Encoder编码器内部运行流程如下:
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 和标准做法有点不一样,src加上位置编码得到q和k,但是v依然还是src,
# 也就是v和qk不一样
q = k = src+pos # PE
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0] # Attentfion
src = src + self.dropout1(src2) # 残差
src = self.norm1(src) # LN
src2 = self.linear2(self.dropout(self.activation(self.linear1(src)))) # FFN
src = src + self.dropout2(src2) # 残差
src = self.norm2(src) # LN
return src
1.3 Transformer 解码器
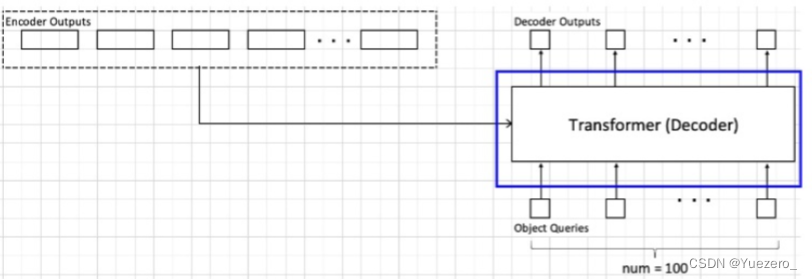
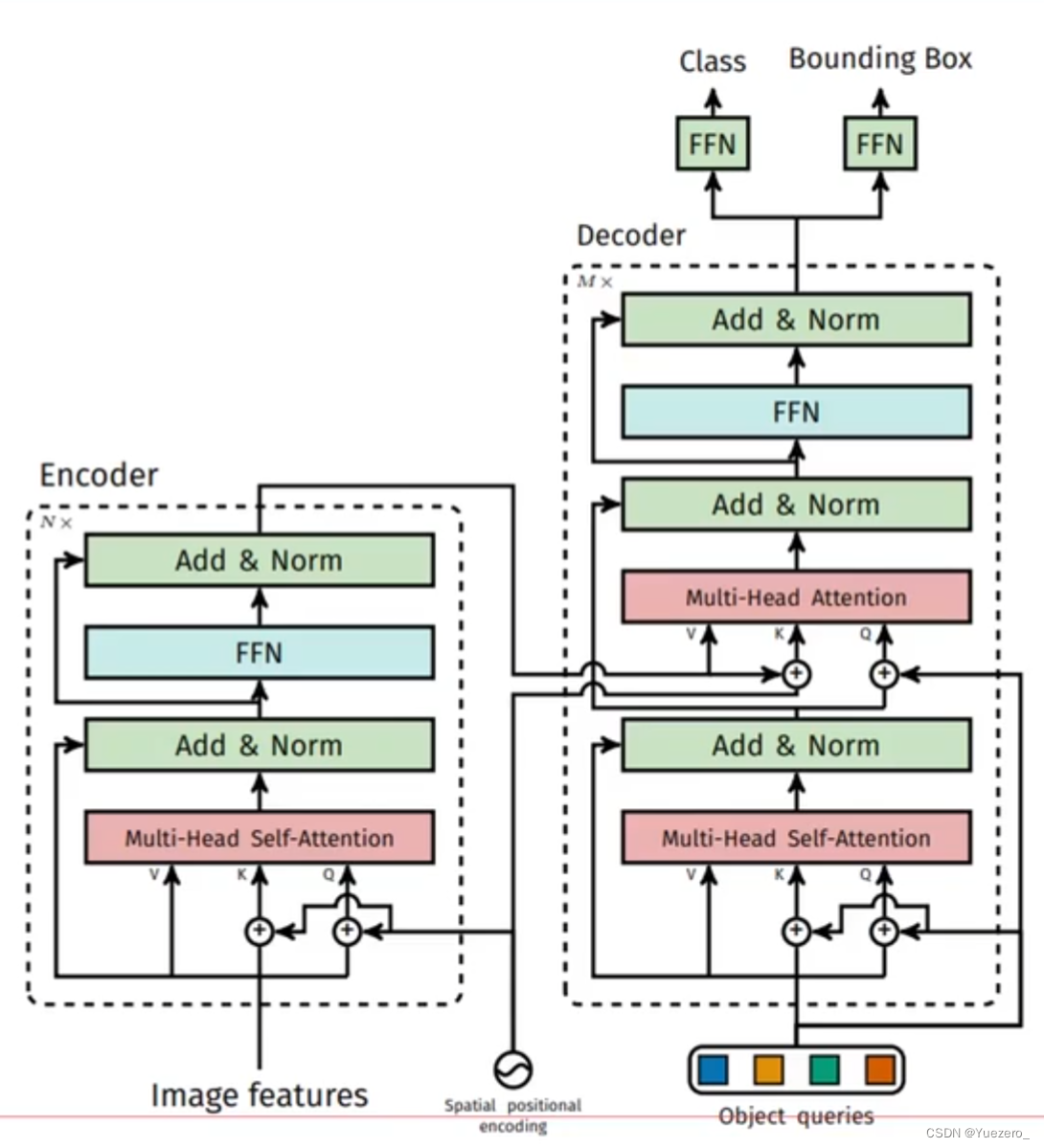
解码器是cross attention结构,K和V是由encoder提供的,Q是重新定义了一个object queries(每个object对应一个query token),在DETR中设定这个object queries为100(认为一张图片中的物体不会超过100个),object queries这个东西类似于之前的MAE中mask tokens,是可以学习的;另一部分是来自之前encoder的输出,具体如何连接请看下图:
a) 新引入Object queries
object queries(shape是(100,256))可以简单认为是随机初始化的, 其作用主要是在学习过程中提供目标对象和全局图像之间的关系,相当于全局注意力,必不可少非常关键。代码形式上是可学习位置编码矩阵。和编码器一样,该可学习位置编码向量也会输入到每一个解码器中。我们可以尝试通俗理解:object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出。
# num_queries=100,hidden_dim=256
self.query_embed = nn.Embedding(num_queries, hidden_dim) # 100个256维token
论文中指出object queries作用非常类似faster rcnn中的anchor,只不过这里是可学习的,不是提前设置好的。
补充一个object queries通俗理解:假设其维度是(100,256),在训练过程中每个格子(共N个)的向量都会包括整个训练集相关的位置和类别信息,例如第0个格子里面存储的一定是某个空间位置的大象类别的嵌入向量,注意该大象类别嵌入向量和某一张图片的大象特征无关,而是通过训练考虑了所有图片的某个位置附近的大象编码特征,属于和位置有关的全局大象统计信息。训练完成后每个格子里面都会压缩入所有类别的图片位置相关的统计信息。现在开始测试:假设图片中有大象、狗和猫三种物体,该图片会输入到编码器中进行特征编码,假设特征没有丢失,该编码器输出的编码向量就是KV,而object queries是Q,现在通过注意力模块将Q和K计算,然后加权V得到解码器输出。对于第0个格子的q会和K中的所有向量进行计算,目的是查找某个位置附近有没有大象,如果有那么该特征就会加权输出,整个过程计算完成后就可以把编码向量中的大象、狗和猫的编码嵌入信息提取出来,然后后面接fc进行分类和回归就比较容易,因为特征已经对齐了。
在整个分析过程中可以总结下:object queries在训练过程中对于N个格子会压缩入对应的和位置和类别相关的统计信息,在测试阶段就可以利用该Q去和编码特征KV计算加权计算,从而提出想要的对齐的特征,最后进行分类和回归。所以前面才会说object queries作用非常类似faster rcnn中的anchor,这个anchor是可学习的,由于维度比较高,故可以表征的东西丰富,当然维度越高,训练时长就会越长。
b) 位置编码也需要
编码器环节采用的sincos位置编码向量也可以考虑引入,且该位置编码向量输入到每个解码器的第二个Multi-Head Attention中,后面有是否需要该位置编码的对比实验。
c) QKV处理逻辑不同
解码器一共包括6个,和编码器中QKV一样,V不会加入位置编码。
d) 一次解码输出全部无序集合
和原始transformer顺序解码操作不同的是,detr一次就把N个无序框并行输出了(因为任务是无序集合,做成顺序推理有序输出没有很大必要)。为了说明如何实现该功能,我们需要先回忆下原始transformer的顺序解码过程:输入BOS_WORD,解码器输出i;输入前面已经解码的BOS_WORD和i,解码器输出am…,输入已经解码的BOS_WORD、i、am、a和student,解码器输出解码结束标志位EOS_WORD,每次解码都会利用前面已经解码输出的所有单词嵌入信息。现在就是一次解码,故只需要初始化时候输入一个全0的查询向量A,类似于BOS_WORD作用,然后第一个解码器接受该输入A,解码输出向量作为下一个解码器输入,不断推理即可,最后一层解码输出即为我们需要的输出,不需要在第二个解码器输入时候考虑BOS_WORD和第一个解码器输出。
总结下和原始transformer解码器不同的地方:
- 额外引入可学习的Object queries,相当于可学习anchor,提供全局注意力
- 编码器采用的sincos位置编码向量也需要输入解码器中,并且每个解码器都输入
- QKV处理逻辑不同
- 不需要顺序解码,一次即可输出N个无序集合
- 相较于Transformer不使用Mask
整体架构:
- 先让object queries做1次self attention;
- 再让object queries作为Q,encoder输出作为K,V,做M次cross attention;
- 最后进行FFN输出Decoder
n个解码器整体流程如下:
class TransformerDecoder(nn.Module):
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# 首先query_pos是query_embed,可学习输出位置向量shape=100,b,256
# tgt = torch.zeros_like(query_embed),用于进行一次性解码输出
output = tgt
# 存储每个解码器输出,后面中继监督需要
intermediate = []
# 编码每个解码器
for layer in self.layers:
# 每个解码器都需要输入query_pos和pos
# memory是最后一个编码器输出
# 每个解码器都接受output作为输入,然后输出新的output
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.return_intermediate:
return torch.stack(intermediate) # 6个输出都返回
return output.unsqueeze(0)
内部每个解码器运行流程为:
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# query_pos首先是可学习的,其作用主要是在学习过程中提供目标对象和全局图像之间的关系
# 这个相当于全局注意力输入,是非常关键的
# query_pos是解码器特有
q = k = tgt+query_pos
# 第一个自注意力模块
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# memory是最后一个编码器输出,pos是和编码器输入中完全相同的sincos位置嵌入向量
# 输入参数是最核心细节,query是tgt+query_pos,而key是memory+pos
# v直接用memory
tgt2 = self.multihead_attn(query=tgt+query_pos,
key=memory+pos,
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
解码器最终输出shape是(6,b,100,256),6是指6个解码器的输出。
1.4 Head与loss
加上检测头才能完成检测任务。
DETR的输出:
- logits_class:
(batch_size, num_queries, num_classes+1) - pred_boxes:
(batch_size, num_queries, 4)
预测框有100个,然而真实框可能只有10个,因此我们需要找到一种匹配方式,为这10个真实框找到各自的预测框,剩余的预测框按照背景处理。DETR中采用pair-wise matching cost来度量预测框和真实框之间的相似度。注意这里不是计算损失,而是计算匹配度。它与两部分有关,一部分是与分类有关,一部分与回归有关,与回归有关这部分是由giou和L1损失计算得到,与类别有关的部分满足条件是为-1不满足时为0。
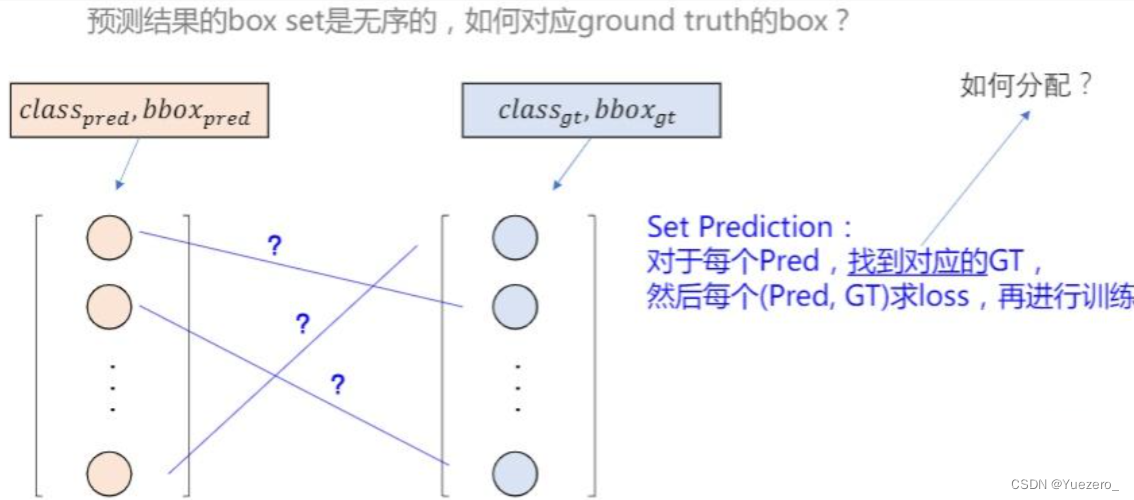
注意生成的Cost矩阵的维度是n_queries*n_targets,比如100*10也就是说,得到了预测框和真实框两两之间的关系度量(匹配度)。然后使用匈牙利算法找到与真实框对应的预测框,其他框都是背景框,实际是调用了scipy中的API,在这里就知道这一步的目的是完成分配就行了,就是以一种科学的方式完成预测框和真实框的对应就好了。

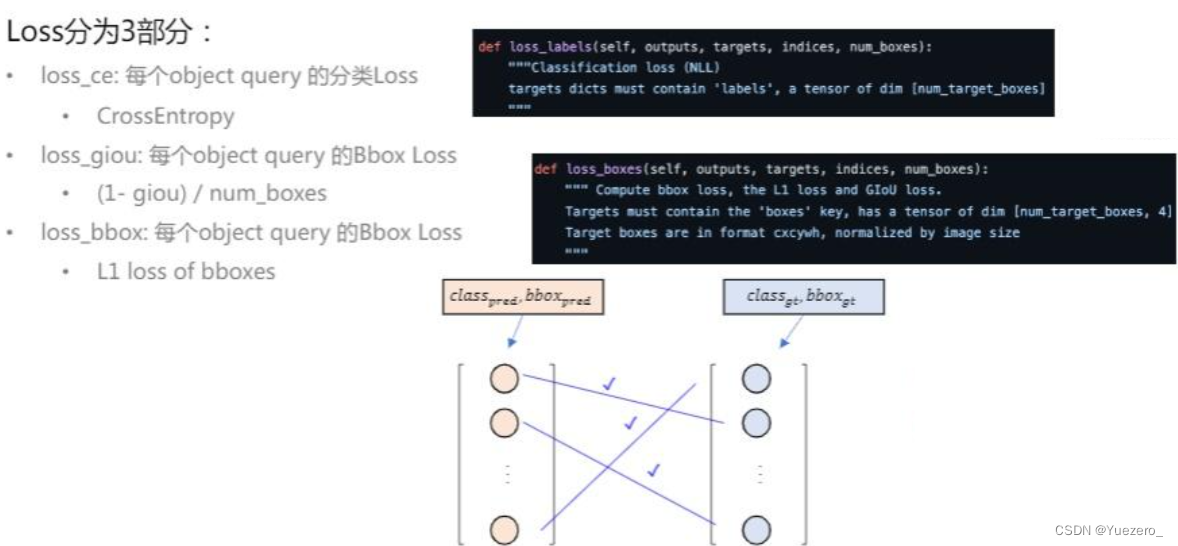
对应上之后,就可以计算损失了,再梳理一下,我们的目的是计算损失才能根据损失进行backward修正网络完成训练,但是因为transformer的机制,在计算loss之前,不得不找到哪些框和哪个真实框对应,在以往的目标检测算法中,比如anchor-base的方法,其实根据置信度筛选完,再计算iou之后,留下的框其实是有和真实框之间的对应的,比如一个真实框对应了几个比较好的回归框。这里loss分为三部分,CE Loss计算分类损失,GIOU Loss计算回归损失,还有一个L1Loss计算回归损失。
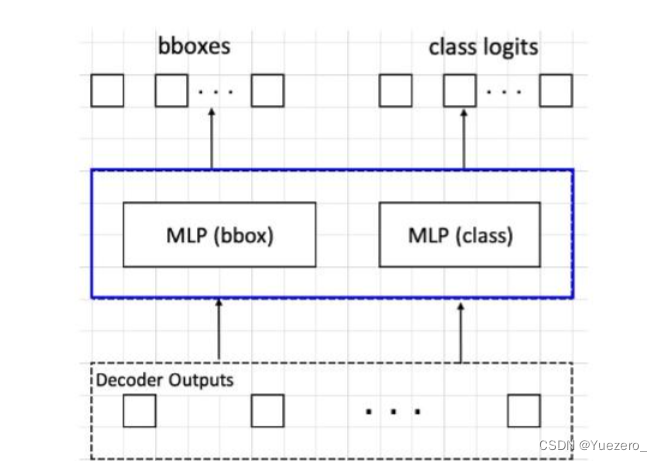
在解码器输出基础上构建分类和bbox回归head即可输出检测结果,比较简单:
self.class_embed = nn.Linear(256, 92)
self.bbox_embed = MLP(256, 256, 4, 3)
# hs是(6,b,100,256),outputs_class输出(6,b,100,92),表示6个分类分支
outputs_class = self.class_embed(hs)
# 输出(6,b,100,4),表示6个bbox坐标回归分支
outputs_coord = self.bbox_embed(hs).sigmoid()
# 取最后一个解码器输出即可,分类输出(b,100,92),bbox回归输出(b,100,4)
out = {
'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
# 除了最后一个输出外,其余编码器输出都算辅助loss
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
作者实验发现,如果对M个解码器的 每个decoder输出 都计算辅助的分类和回归loss,可以提升性能,故作者除了对最后一个编码层的输出进行Loss监督外,还对其余5个编码器采用了同样的loss监督,只不过权重设置低一点而已。
1.5 模型全流程

当然上面是简化代码,和实际代码不一样。具体流程是:
将(b,3,800,1200)图片输入到resnet50中进行特征提取,输出shape=(b,1024,25,38)
通过1x1卷积降维,变成(b,256,25,38)
利用sincos函数计算位置编码
将图像特征和位置编码向量相加,作为编码器输入,输出编码后的向量,shape不变
初始化全0的(100,b,256)的输出嵌入向量,结合位置编码向量和query_embed,进行解码输出,解码器输出shape为(6,b,100,256),后面的解码器接受该输出,然后再次结合置编码向量和query_embed进行输出,不断前向
将最后一个解码器输出输入到分类和回归head中,得到100个无序集合
对100个无序集合进行后处理,主要是提取前景类别和对应的bbox坐标,乘上(800,1200)即可得到最终坐标,后处理代码如下:
prob = F.softmax(out_logits, -1)
scores, labels = prob[..., :-1].max(-1)
# convert to [x0, y0, x1, y1] format
boxes = box_ops.box_cxcywh_to_xyxy(out_bbox)
# and from relative [0, 1] to absolute [0, height] coordinates
img_h, img_w = target_sizes.unbind(1)
scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
boxes = boxes * scale_fct[:, None, :]
results = [{
'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
既然训练时候对6个解码器输出都进行了loss监督,那么在测试时候也可以考虑将6个解码器的分类和回归分支输出结果进行nms合并,稍微有点性能提升。
2.实验分析
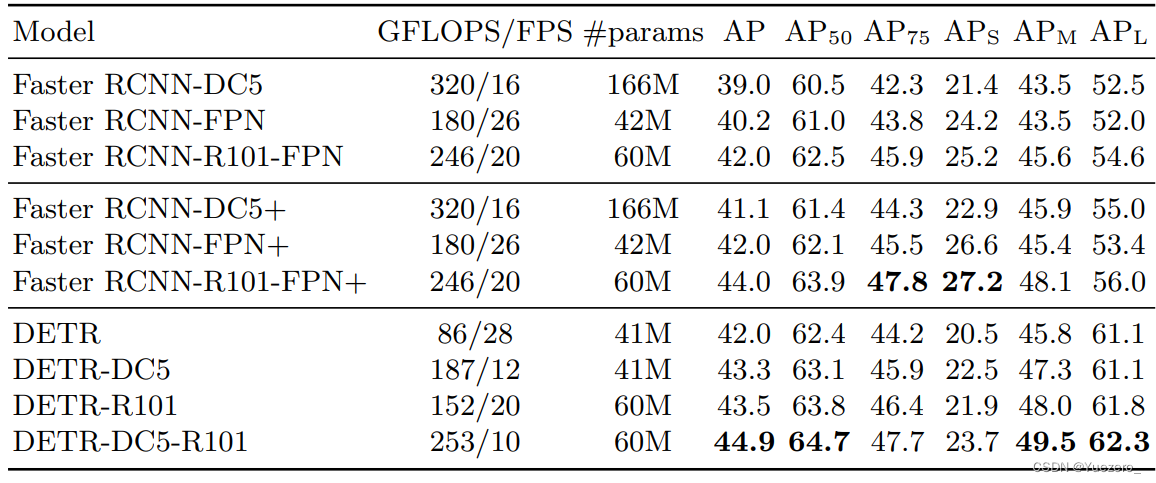
Faster RCNN-DC5是指的resnet的最后一个stage采用空洞率=stride设置代替stride,目的是在不进行下采样基础上扩大感受野,输出特征图分辨率保持不变。+号代表采用了额外的技巧提升性能例如giou、多尺度训练和9xepoch训练策略。可以发现detr效果稍微好于faster rcnn各种版本,证明了视觉transformer的潜力。但是可以发现其小物体检测能力远远低于faster rcnn,这是一个比较大的弊端。
detr整体做法非常简单,基本上没有改动原始transformer结构,其显著优点是:不需要设置啥先验,超参也比较少,训练和部署代码相比faster rcnn算法简单很多,理解上也比较简单。但是其缺点是:改了编解码器的输入,在论文中也没有解释为啥要如此设计,而且很多操作都是实验对比才确定的,比较迷。算法层面训练epoch次数远远大于faster rcnn(300epoch),在同等epoch下明显性能不如faster rcnn,而且训练占用内存也大于faster rcnn。
整体而言,虽然效果不错,但是整个做法还是显得比较原始,很多地方感觉是尝试后得到的做法,没有很好的解释性,而且最大问题是训练epoch非常大和内存占用比较多,对应的就是收敛慢,期待后续作品。