RNN是啥
Recurrent Neural Network(RNN),循环神经网络的优势在于能够处理任意长度的输入(或者说流式(strem)输入,插一嘴,博主非常讨厌这种故作玄虚的称呼,似乎显得提出者高大上,实际只能让后来者在单独学习的时候费尽力气)。简单的来说,一句话**“go to bed instead of go mad”**,可以通过分词将这句话分为:['go', 'to', 'bed', 'instead', 'of', 'go', 'mad']。在这之后,我们可以用一些pretrained的向量对这些单词有一个表示,比如我们可以用GloVe拿到了一个向量的list,里面的向量都是对应位置单词的表示。
在给RNN模型喂的时候,每一个向量都依此送进去跑一下,在这个过程中一些有特殊设计的RNN比如LSTM,GRU这些可能会有一些额外的量被计算出来,但是最终都会拿到一个outputs矩阵,里面储存着每一次计算过程中,对于该次喂进去的单词计算而得的隐层向量。通常而言,我们想要的是最后一个输出的隐层,因为其跑遍了所有的信息,因此我们从某种意义上可以相信其更贴切该句子的表示。
IMDB
这个数据集是国外友人的电影影评,可以理解成是从豆瓣上面爬下来的数据,经过人工看了之后,分为positive 和 negative两种进行标注。这个可以通过torchtext的api来做,但是这个其实挺蛋疼的。
因为如果按照其官方文档开始的展示来用,得到的train_iter = torchtext.datasets.IMDB(split='train'),其并不是一个dataset对象,而是一个奇了八怪的MapperIterDatapipe。尽管花了好几个小时研究这个东西,最后还是通过遍历的方式把数据全部拿出来,再用复写Dataset, DataLoader的形式做了一个自己的数据迭代器。
GloVe
博主最开始在做的时候为了表示单词,直接naive地通过torch.nn.Embedding随机初始化了一个编码层。虽然在做的时候还想过,这些随机初始化的编码不能表示这些词的意思,但是当时脑子一懵,觉得在这个数据量下可以通过训练的方式不断更新这个编码。但是事实表示年轻了,还是太年轻了,人生宝贵的半天就这么耗过去了。
也在这里提一下关于训练时候loss不降的一种观察角度,如果loss并不是严格不动的,换言之你的optimizer在干活,但是模型的表现一直很差,关于分类任务的输出通常和盲猜的结果相同。这个时候是代码层面错误的几率比较小,应该从模型的整体架构来看。另外一方面,如果loss一直不动都是那个数,那么需要查查是不是哪块的计算图被清掉了。
代码
开源是一个伟大的事情,希望自己未来能开源一些更有价值的东西
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext.vocab.vocab as vocab
import torchtext
from torchtext import datasets
from torch.utils.data import DataLoader,Dataset
from collections import Counter, OrderedDict
BATCH_SIZE = 32
EPOCHS = 10
SHUFFLE = True
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
MOST_COMMON_SIZE = 40000
VOCAB_SIZE = MOST_COMMON_SIZE + 2 # unk pad
COMMENT_SIZE = 300
EMBED_SIZE = 50
HIDDEN_SIZE = 32
UNK_TOKEN = '<unk>'
PAD_TOKEN = '<pad>'
imdb_path = 'path_of_dataset'
GloVe = torchtext.vocab.GloVe('6B', 50, cache='/home/haolin_li/code/pretrained_models')
# 这俩就是上面提到的,Datapipe
train_imdb = datasets.IMDB(
root = imdb_path,
split = 'train'
)
test_imdb = datasets.IMDB(
root = imdb_path,
split = 'test'
)
# 把两个Datapipe里面数据全都拿出来
train_source_targets = []
train_source_comments = []
test_source_targets = []
test_source_comments = []
for target, comment in train_imdb:
train_source_targets.append(target)
train_source_comments.append(comment)
for target, comment in test_imdb:
test_source_targets.append(target)
test_source_comments.append(comment)
# 计算词频
word_counter = Counter()
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
for comment in train_source_comments:
for word in tokenizer(comment):
word_counter[word] += 1
# 前十个都是些没啥语义的 of with that 这样的,所以直接去掉
most_common_words = word_counter.most_common(MOST_COMMON_SIZE+10)[10:]
word_ordered_dict = OrderedDict(most_common_words)
# 在torchtext这个版本中可以通过添加specials的方式直接把unk 和 pad加进去,还是挺方便的,默认放在最前面
my_vocab = vocab(word_ordered_dict, specials=[UNK_TOKEN, PAD_TOKEN])
# 当键值的不在keys中时,默认返回是unk
my_vocab.set_default_index(my_vocab[UNK_TOKEN])
#前两个分别代表unk 和 pad的向量表示,后面的按照顺序连上
embedding_weight_matrix = [[0 for i in range(EMBED_SIZE)] for j in range(2)]
# 注意这里最好转成numpy()否则后面整体转tensor的时候也有点烦人
embedding_weight_matrix.extend([GloVe.get_vecs_by_tokens(word[0]).detach().numpy() for word in most_common_words])
class imdb_dataset(Dataset):
def __init__(self, source_targets, source_comments, tokenizer, my_vocab):
self.source_targets = source_targets
# 见下面的函数
self.conver_targets()
self.source_comments = []
# 把str的comment先分词,再转成idx的形式
for comment in source_comments:
split = tokenizer(comment)
if len(split) > COMMENT_SIZE:
self.source_comments.append([my_vocab[word] for word in split[:COMMENT_SIZE]])
else:
split.extend([PAD_TOKEN for i in range(COMMENT_SIZE - len(split))])
self.source_comments.append([my_vocab[word] for word in split[:COMMENT_SIZE]])
self.length = len(source_targets)
def __len__(self):
return self.length
def __getitem__(self,idx):
return self.source_targets[idx], self.source_comments[idx]
def conver_targets(self):
for i, target in enumerate(self.source_targets):
self.source_targets[i] = 0 if target == 'neg' else 1
train_dataset = imdb_dataset(train_source_targets, train_source_comments, tokenizer, my_vocab)
test_dataset = imdb_dataset(test_source_targets, test_source_comments, tokenizer, my_vocab)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=SHUFFLE)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=SHUFFLE)
# 无attention的模型
class sentimental_rnn(nn.Module):
def __init__(self, vocab_size:int, embed_size:int, hidden_size:int, dropout:float, pad_idx:int, embedding_weight_matrix):
super(sentimental_rnn, self).__init__()
self.embedding = nn.Embedding.from_pretrained(torch.Tensor(embedding_weight_matrix), freeze=True)
self.dropout = nn.Dropout(dropout)
self.rnn = nn.GRU(embed_size, hidden_size, batch_first=False) # 比较奇怪的一点,从Loader里面出来就是Seq_first的状态
self.classifier = nn.Sequential(
nn.Linear(hidden_size, 128),
nn.ReLU(),
nn.Linear(128, 2),
# nn.Softmax()
)
def forward(self, x):
# x: seq, batch
x = self.embedding(x)
# x = self.dropout(x)
# x: seq, batch, embed_size
output, h_n = self.rnn(x)
# output: seq, batch, hidden
output = output[-1, :, :]
# batch, hidden
pred = self.classifier(output)
# batch, 2
return pred
# attention版模型
class sentimental_rnn_attention(nn.Module):
def __init__(self, embed_size:int, hidden_size:int, dropout:float, n_layers:int, embedding_weight_matrix):
super(sentimental_rnn_attention, self).__init__()
self.embedding = nn.Embedding.from_pretrained(torch.Tensor(embedding_weight_matrix), freeze=True)
self.dropout = nn.Dropout(dropout)
self.rnn = nn.GRU(embed_size, hidden_size, num_layers=n_layers, batch_first=False) # 比较奇怪的一点,从Loader里面出来就是Seq_first的状态
# 这个attention只综合了output
self.W = nn.Parameter(torch.Tensor(hidden_size, hidden_size))
self.K = nn.Parameter(torch.Tensor(hidden_size, 1))
self.softmax = nn.Softmax(dim=1)
self.fc = nn.Linear(hidden_size, 2)
nn.init.uniform_(self.W, -0.1, 0.1)
nn.init.uniform_(self.K, -0.1, 0.1)
def forward(self, x):
# x: seq, batch
x = self.embedding(x)
x = self.dropout(x)
# x: seq, batch, embed_size
output, h_n = self.rnn(x)
# output: seq, batch, hidden
# h_n: n_layers, batch, hidden
output = output.permute(1,0,2)
# batch, seq, hidden
weights = torch.tanh(output.matmul(self.W))
# batch, seq, hidden
weights = weights.matmul(self.K)
# print(weights.shape)
# batch, seq, 1
weights = self.softmax(weights)
# print(weights.shape)
# batch, seq, 1
output = output * weights
# batch, seq, hidden
output = torch.sum(output, dim=1)
pred = self.fc(output)
# batch, 2
return pred
def evaluate(model, test_loader, loss_fn):
total_count = 0
correct_count = 0
total_loss = 0
with torch.no_grad():
for i, (targets, comments) in enumerate(test_loader):
targets = torch.LongTensor(targets).to(DEVICE)
comments = torch.LongTensor([ts.cpu().detach().numpy() for ts in comments]).to(DEVICE)
predictions = model(comments)
loss = loss_fn(predictions, targets)
total_loss += loss.detach().cpu().numpy() * BATCH_SIZE
predictions = predictions.argmax(dim=1)
total_count += BATCH_SIZE
correct_count += torch.sum(targets == predictions)
return correct_count / total_count, total_loss / total_count
def train(model, train_loader, test_loader, loss_fn):
for epoch in range(EPOCHS):
for i, (targets, comments) in enumerate(train_loader):
optimizer.zero_grad()
targets = torch.LongTensor(targets).to(DEVICE)
comments = torch.LongTensor([ts.cpu().detach().numpy() for ts in comments]).to(DEVICE)
predictions = model(comments)
loss = loss_fn(predictions, targets)
loss.backward()
optimizer.step()
if i % 50 == 0 and i != 0:
print("epoch:{} crnt_train_loss:{}".format(epoch, loss.cpu().detach().numpy()))
acc, avg_loss = evaluate(model, test_loader, loss_fn)
print("test performance accuracy:{} avg_loss:{}".format(acc, avg_loss))
model = sentimental_rnn(VOCAB_SIZE, EMBED_SIZE, HIDDEN_SIZE, 0.2, my_vocab[PAD_TOKEN], embedding_weight_matrix).to(DEVICE)
optimizer = optim.Adam(model.parameters())
loss_fn = nn.CrossEntropyLoss()
train(model, train_loader, test_loader, loss_fn)
写的时候不觉得,这么一复制过来感觉还是tensorflow写得省事儿,PyTorch洋洋洒洒这么一大堆。不过就跟拼乐高一样,块小虽然耗精力,但是拼的东西种类更多,创新的时候比较省心。
有时候这种东西真的要靠兴趣驱动,这个训练好之后特别好玩儿。
你随便说一句话"This movie is horrible",他告诉你这个是骂人的

然后改一个词,他又能知道夸他呢
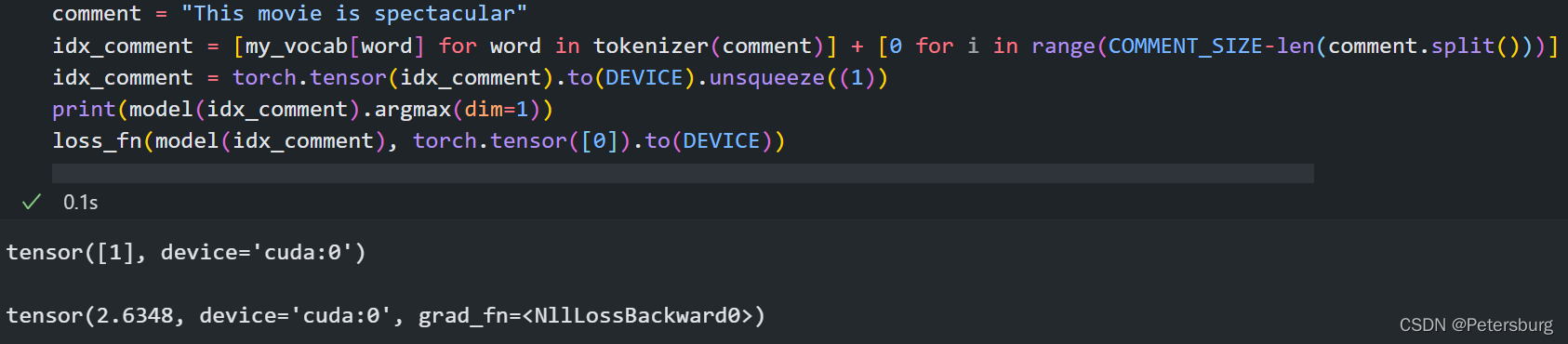
最后,还有一个比较有意思的点,当然,也有可能是我训练的程度不够,当一句话有转折,并且前后语句长度参半的时候,很难进行识别,换言之,其对结构性的标志词不敏感。

必须要多加一句话,加强语义上的分量,才能得到正确的结果

P.S. 我贼喜欢成龙,只不过现在太晚了,弄了一天代码脑子转不起来想不起来其他人了,与其写个奶油小生给自己找事儿,不如把这活儿交给我信得过的广大成龙粉丝群众。\doge