Pytorch使用LSTM实现Movie Review数据集情感分析
入门Pytorch一周时间,周六试着手写情感分类代码。学过Tensorflow的都知道,其需先生成计算图,还得通过placeholder喂入数据,十分的麻烦,也不容易调试,而pytorch真心是简单上手,最开心的就是Tensorflow不能随时打印中间结果,而Pytorch完美实现了~~啰嗦两句,很建议大家先学习tensorflow,再去学习pytorch,就好比编程入门语言是C++,仔细了解了程序的机理后,学习其他语言都得心应手。
下面是一个简单的NLP任务——情感分类。给定数据集MR,是一个电影评论数据集,只有两类(positive和negative),小试阶段仅使用单层双向LSTM以及一个注意力机制进行文本分类(模型可参阅博文https://blog.csdn.net/qq_36426650/article/details/88207917)。带注释的全部程序如下所示。
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
import random as rd
# 加载数据集目录
data_dir = 'E:\\数据集\\NLP文本分类\\Movie Review\\rt-polaritydata\\'
pos = data_dir + 'rt-polarity.pos'
neg = data_dir + 'rt-polarity.neg'
# 超参数
max_len = 65 #句子最大长度
embedding_size = 50
hidden_size = 100
batch_size = 20
epoch = 100
label_num = 2
eval_time = 100 # 每训练100个batch后对测试集或验证集进行测试
# 预处理数据集,划分训练集和测试集,遍历所有单词生成词表
def processData():
pos_train = []
neg_train = []
pos_test = []
neg_test = []
#读取数据
with open(pos, 'r', encoding='utf-8') as fr:
sens = fr.readlines()
sens_ = []
for i in sens:
sens_.append([i,1])
rd.shuffle(sens_)
split = int(len(sens_)*0.8)
pos_train = sens_[:split]
pos_test = sens_[split:]
#读取数据
with open(neg, 'r', encoding='utf-8') as fr:
sens = fr.readlines()
sens_ = []
for i in sens:
sens_.append([i,0])
rd.shuffle(sens_)
split = int(len(sens_)*0.8)
neg_train = sens_[:split]
neg_test = sens_[split:]
train = pos_train + neg_train
test = pos_test + neg_test
rd.shuffle(train)
rd.shuffle(test)
# 获取所有词以及句子数值化
vocab = dict()
vocab['None'] = 0 # 未知词
train_ = []
test_ = []
for i,label in train:
sentences = i.replace('\n', '').replace('\'', '').replace('"', '').split(' ')
sent_ = [ 0 for i in range(max_len)]
for ei, i in enumerate(sentences):
if i not in vocab.keys():
vocab[i] = len(vocab)
sent_[ei] = vocab[i]
else:
sent_[ei] = vocab[i]
train_.append([sent_, label])
for i,label in test:
sentences = i.replace('\n', '').replace('\'', '').replace('"', '').split(' ')
sent_ = [ 0 for i in range(max_len)]
for ei, i in enumerate(sentences):
if i not in vocab.keys():
vocab[i] = len(vocab)
sent_[ei] = vocab[i]
else:
sent_[ei] = vocab[i]
test_.append([sent_, label])
return train_, test_, vocab
# 批处理
def batch(dataset, kind):
if kind == 'train':
rd.shuffle(dataset)
batch_num = int(len(dataset)/batch_size)
# 最后一个size不足是时batch舍弃
for i in range(batch_num):
batch = dataset[i*batch_size:(i+1)*batch_size]
sen_batch = []
label_batch = []
for j in batch:
sen_batch.append(j[0])
label = [ 0 for t in range(label_num)]
label[j[1]] = 1
label_batch.append(label)
# batch:[batch_size,max_len]
yield sen_batch, label_batch
else:
sen_batch = []
label_batch = []
for j in dataset:
sen_batch.append(j[0])
label = [ 0 for t in range(label_num)]
label[j[1]] = 1
label_batch.append(label)
# batch:[batch_size,max_len]
yield sen_batch, label_batch
class Classify(nn.Module):
def __init__(self,vocab_len, embedding_table):
super(Classify, self).__init__()
self.max_len = max_len
self.batch_size = batch_size
# 这里我只是默认初始化词向量,也可以使用torch.from_numpy来加载预训练词向量
self.embedding_table = nn.Embedding(vocab_len, embedding_size)
self.embedding_size = embedding_size
self.hidden_size= hidden_size
self.label_num = label_num
self.lstm = nn.LSTM(input_size=self.embedding_size, hidden_size=self.hidden_size,num_layers=1,dropout=0.8,bidirectional=True)
self.init_w = Variable(torch.Tensor(1, 2*self.hidden_size), requires_grad=True)
self.init_w = nn.Parameter(self.init_w)
self.linear = nn.Linear(2*self.hidden_size, self.label_num)
self.criterion = nn.CrossEntropyLoss()
self.optim = optim.Adam(self.parameters())
def forward(self, input, batch_size):
input = self.embedding_table(input.long()) # input:[batch_size, max_len, embedding_size]
h0 = Variable(torch.zeros(2, batch_size, self.hidden_size))
c0 = Variable(torch.zeros(2, batch_size, self.hidden_size))
lstm_out, _ = self.lstm(input.permute(1,0,2),(h0,c0))
lstm_out = F.tanh(lstm_out) # [max_len, bach_size, hidden_size]
M = torch.matmul(self.init_w, lstm_out.permute(1,2,0))
alpha = F.softmax(M,dim=0) # [batch_size, 1, max_len]
out = torch.matmul(alpha, lstm_out.permute(1,0,2)).squeeze() # out:[batch_size, hidden_size]
predict = F.softmax(self.linear(out)) # out:[batch_size, label_num]
return predict
train_, test_, vocab = processData()
embedding_table = word_embedding(len(vocab), embedding_size)
net = Classify(len(vocab), embedding_table)
print(net.embedding_table)
optim = net.optim
max_acc = 0.0 # 记录最大准确率的值
for i in range(epoch):
batch_it = batch(train_, 'train')
print('training (epoch:',i+1,')')
ej = 0
for x,y in batch_it:
ej += 1
y_hat = net.forward(Variable(torch.Tensor(x)), len(x))
y = torch.max(torch.Tensor(y), 1)[1]
loss = net.criterion(y_hat, y)
if (ej+1)%10 == 0:
print('epoch:', i+1, ' | batch' , ej ,' | loss = ', loss)
net.optim.zero_grad()
loss.backward(retain_graph=True)
net.optim.step()
if ej%eval_time == 0:
# 测试
with torch.no_grad():
print('testing (epoch:',i+1,')')
batch_it = batch(test_, 'test')
num = 0
for x,y in batch_it:
y_hat = net.forward(Variable(torch.Tensor(x)), len(x))
y_hat = np.argmax(y_hat.numpy(),axis=1)
y = np.argmax(y,axis=1)
for ek,k in enumerate(y_hat):
if k == y[ek]:
num += 1
acc = round(100*num/len(test_), 2)
if acc > max_acc:
max_acc = acc
print('epoch:', i+1, ' | accuracy = ', acc, ' | max_acc = ', max_acc)
运行结果:
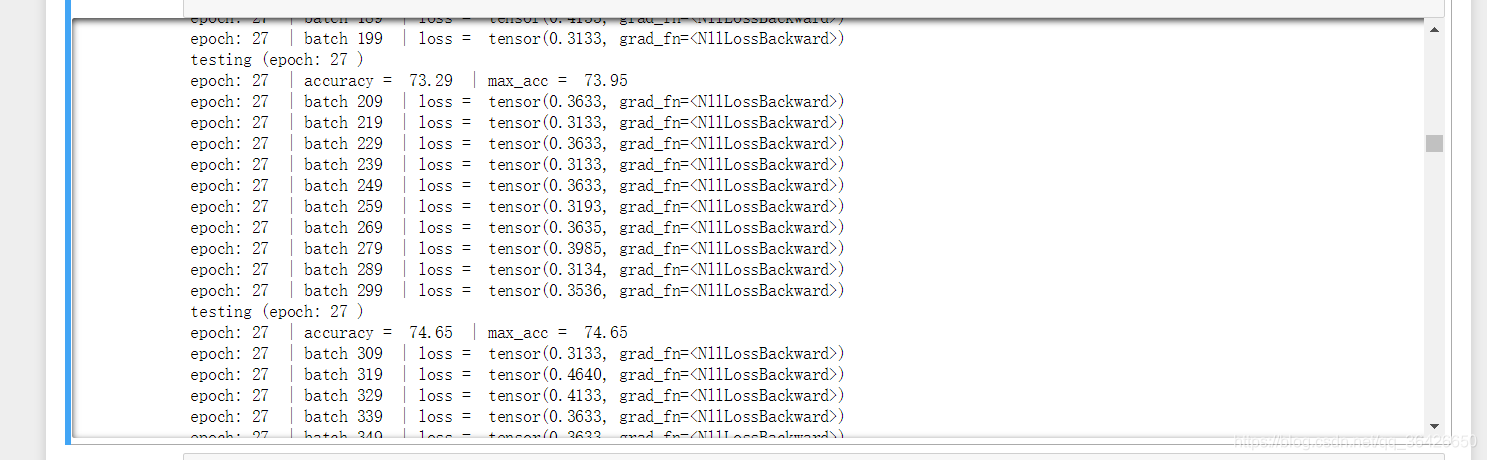
调研过一些论文,绝大多数的准确度其实已经高达80%多,而本次选择的模型很简单,且并没有去调参,最重要的是我没使用预训练词向量,而是随机初始化,结果也达到了74.65%,因此本程序是可以继续使用的,可直接在forward里修改模型即可。另外函数并没有plot画板,也没有写保存模型的代码,同时也没有指定GPU,这一部分可自行加上。
后记:
另外记录pytorch几个坑,就是它的张量计算很古怪,在喂入LSTM的input数据的维度是 【sequence_length, batch_size, embedding_size】,输出的也是 【sequence_length, batch_size, hidden_size】,batch_size这个维度位于中间,而普通的矩阵乘法等带有广播机制的运算是 【batch_size, sequence_length, hidden_size】,也就是说需要手动转置(permute)一下。个人理解是,因为batch_size仅表示样本数量,在实际计算中并不以这个维度为计算,所以转置到中间可以方便一些张量的运算。
pytorch还有一些不同的函数,例如转置运算,pytorch对应的是permute(),而tensorflow对应的是transpose,拼接函数中,pytorch是cat(),而tensorflow是concat()等等
