文章目录
摘要
随着成本的降低和传感器技术的普及,工业生产过程越来越多地从运行中的机器中收集数据。通过使用正确的传感器和适当的技术,对机器的当前运行状态产生有价值的信息。这种提取允许检测机器是否在降级状态下运行,然后,如果有必要,在机器进入故障状态之前中断其运行。机器异常行为的检测是相关的,因为在正确的时间检测可以减少由于机器故障和生产停机造成的财务成本。本工作提出了一种新的无监督方法来检测工业机器中的异常,并在机器进入故障状态之前中断其运行。该方法接收来自多个传感器的一组时间序列数据作为输入。使用一组统计特征,它计算出一个表征故障严重程度的指标,并在必要时向机器操作员发出警报。该方法在两个已知单变量数据的基准和两个具有多变量数据的专有数据集中进行了评估。进行的实验表明,在训练和评估上花费的计算时间较少。雅虎基准中接收者工作特征曲线下面积(Area Under Receiver Operating Characteristic Curve, AUC)测量的总体结果为89.3%;在Numenta中为70.3%,在评估的两个多变量数据集中为92.4%和91.2%。这些高AUC值显示了该方法在大型豆油生产行业预测性维护中的应用潜力。
关键词 异常检测·离群点检测·时间序列·特征提取·预测性维护·工业4.0
1、介绍
工业4.0革命的发生主要是由于计算能力的提高、传感技术的廉价化、人工智能(AI)方法的发展以及物理世界和数字世界的融合。工业4.0带来了一系列优势,如提高生产率、降低生产成本、增强互操作性、降低维护成本以及更容易实现人机交互等。本研究通过开发一种新的无监督时间序列异常检测方法来降低维护成本,旨在协助预测性维护。
文献中的许多作者没有[6]强调的那样,在异常和异常值之间没有明确区分。 在这项工作的背景下,异常值被认为是突然的变化,在这项工作的背景下与邻居不同,可能来自数据输入中的传感或其他错误的错误。 反过来,异常是一组连续点的变化,可以将机器带到故障或断裂状态。 我们的新方法能够检测异常和异常值。 该方法还可以区分本地和全球异常值。 当它逃避邻居建立的模式时,离群值是本地的。 当避免有关整个数据系列的模式时,离群值是全局的[6]。
如上所述,异常的发生是机器预期行为偏差的表现。反过来,异常检测包括使用在数据序列中发现这些偏差的技术。异常检测的分类方法主要有两种:时间数据检测和空间数据检测。目前的工作重点是检测异常的时间数据(顺序)。异常点是指与其他点完全不同的点,也就是说,远离标准行为。这些不同于其他点的点通常与传感错误或数据输入中的错误有关。我们的新方法可以同时应用于异常检测和离群值检测,只需触发特定于每个上下文的统计特征。
关于预测性维护,文献介绍了这一主题的两个主要部分:诊断和预后。诊断首先检测,确定原因,然后评估机器或系统的健康状态以防止故障。预报员对机器或系统的未来状态进行预测,并预测剩余使用寿命(RUL)。本文提出的方法只关注故障诊断阶段。
维护程序基于四个标准:安全性,经济成本,轻松和准确性[5]。 为了确保这些标准的最佳满足,存在几种类型的维护策略。 如[14,27]中报道,维护策略通常分为纠正性,预防性(系统和有条件)和预测性。 矫正维护(CRM)策略是最简单的,因为它仅在机器停止工作时才发生。 CRM政策在经济上对于简单和简短的干预措施是有利的。 但是,由于停机时间和新组件产生的成本,将CRM政策应用于昂贵的系统或复杂的干预措施时,策略成本很高。 系统的策略是基于时间的维护策略。 条件方法仅基于机器状况,但是条件的控制和测量可以定期进行。 仅当使用适当的频率应用时,预防性维护(PVM)比CRM更好。 PVM的主要缺点是由于对系统的误解而执行的不必要的纠正措施,导致运营成本的增加。 预测维护(PDM)定义为PVM的扩展[13]。 PDM使用预测工具来估算何时需要进行维护操作。 这种维护的策略涉及连续的机器监控,仅在必要时才能执行维护。 如果应用良好,PDM策略将节省财务节省,因为它减少了故障的数量并将生存时间改善到机械组件[25]。 PDM的主要缺点是需要准确的数据和公司信息系统的良好成熟度[22]。
提出的方法称为异常和异常检测(AOD),该方法基于一组统计特征,这些特征定义了支持单变量(仅来自一个传感器)或多变量(来自一个以上传感器)数据的几个变量可接受的限制 。 AOD的目的是指出可能导致机器达到维护需求的异常行为。 这是对行业的内在需求,因为[26]报道,预测性维护可以将投资回报率提高多达10倍,从而将维护成本从25%降低到30%,从而消除了70%的细分,将停机时间从35降低。 至45%,并将产量从20%增加到25%。
由AOD执行的诊断的第一步提供了参考不同机器故障的独特方法。我们的方法可以取代或自动完成故障树或其他故障识别技术,这些技术是任何预测方法的先决条件。此外,AOD还允许识别关键设备状态。临界状态是指设备不是处于故障模式,而是在生产中可以观察到质量缺陷的状态。识别这些状态将提高预测阶段维修干预预测的性能,从而改善生产质量管理。
AOD方法已在文献中已知的单变量数据的两个基准中进行了评估。评估的第一个基准是Yahoo Outlier benchmark (YOB),专门用于检测单变量时间序列[17]中的异常值。第二个数据集是Numenta异常基准(NAB),用于检测单变量时间序列中的异常[1,19]。两个数据集都包含人工异常数据和真实异常数据。实际的异常来自各个应用领域,包括雅虎会员登录数据、数据流、亚马逊网络服务(AWS)服务器指标、推文数量、广告点击指标、流量数据和运行中的机器数据。评估方法是在一个综合生成的多元数据的专有数据集和一个来自植物油生产行业的多元数据的实际案例研究中进行的。
本文的组织结构如下:第二节简要回顾了文献。第3节描述了这个问题。第4节详细介绍了建议的方法。第5节给出了计算结果。最后,第6节以最后的考虑结束本文。
2、相关工作
在文献中有几种方法来检测时间序列中的异常和异常值。在这项工作的上下文中,我们对无监督技术感兴趣,因为数据标签并不总是可用于实际应用中的训练。因此,本文只考虑机器学习(ML)和统计方法。
b[7]的作者介绍了机器学习技术在预测性维护(PdM)中的应用的文献综述。这项工作表明,在PdM中使用的主要方法包括深度学习、贪婪方法和贝叶斯方法。这项工作还指出,这些技术可以应用于许多类型的设备,如涡轮机、发动机、压缩机、泵和风扇。该工作提出的另一个方面涉及方法使用的数据,其中优先使用振动数据、声学信号、设备温度、电信号和维护历史。
[21]的工作提出了DeepAnT方法,该方法使用使用卷积神经网络(CNN)的序列预测模块和检测异常的模块,负责将数据标记为正常或异常。这种无监督方法学习数据的分布,并利用这些信息来预测时间序列中未来点的行为,可以用于单变量或多变量时间序列。
在预测未来点以验证查询点是否属于预期分布的策略中,作者在[18]中提出了EGADS方法,即可扩展通用异常检测系统的缩写。EGADS执行异常值检测,并检测单变量时间序列中的变化点,并且由于其设计方式,允许在每个模块中添加新的方法。该方法有三个主要部分:时间序列建模模块、异常检测模块和警报发布模块。这项工作已经在雅虎数据上进行了验证,其中包括该公司成员的登录数据。
在[12]中,作者提出了S-H-ESD方法,即季节性混合极端学生偏差的首字母缩略词,该方法可以检测单变量时间序列中的异常。S-H-ESD是一种基于假设检验和将时间序列分解为季节性、趋势和噪声的统计方法。这项工作已经在Twitter数据上得到了验证,比如每秒的tweet数和CPU利用率。
这项工作与[12,18,21]的方法不同,因为它基于当前分析窗口而不是每个数据点来检测异常和异常值。然而,[12,18]的工作是针对单变量时间序列的具体方法。
在这种情况下,可以引用更多作品。 在[3]的工作中,有一个多元控制图来检测潜在的环境和生态影响。 [8]中的作者提出了一种用于检测时间序列中异常的方法,该方法使用小波分解与数据的HAAR变换。 [31]的工作开发了一种基于自回旋综合运动平均线(ARIMA)的技术,以检测对计算机网络的潜在攻击。 [32]的工作提出了一种基于自适应统计过程控制的单变量时间序列中检测异常的策略。 [29]中的作者开发了一种基于分层时间内存(HTM)的方法,用于时间序列中的异常检测。 [10]中的作者开发了一种基于长短期内存网络(LSTM)和高斯混合模型(GMM)的技术。
[30]的作者开发了一种用于提取旋转机械故障特征的谱回归技术。这些故障特征表明机器在运行中的当前状态,并可用于检测异常。这项工作使用加速度计传感器来捕获旋转机器的轴承振动数据,因为轴承行为分析是检测这种机器类型故障的最关键因素。作者还提取了加速度计信号在时域、频域和频时域的特征。表1总结了本研究综述的论文的主要技术特征。因此,首先比较的技术特征是检测的对象:异常,异常值或两者兼有,然后是使用的时间序列数量(单变量或多变量)和使用的学习类型(监督或无监督),最后是作者使用的计算策略类型。
另一方面,一些文献已经在故障和异常检测技术的发展中使用了一些统计特征。[30]的工作利用统计特征均方根(RMS)、幅值平方根(SRA)、峰峰值(PPV)、偏度值(SV)、峰度值(KV)、波峰因子(CF)、脉冲因子(IF)、裕度因子(MF)、形状因子(SF)和峰度因子(KF)构建了加速度计数据故障分类的回归模型。作者在[24]中使用了特征算术平均值(AMean), RMS, SRA,标准差(STD),方差(VAR), PPV,最大值(MaxV),最小值(MinV), SV, KV, CF, IF, MF, SF和KF来开发检测轴承故障的方法。[11]的工作利用了AMean、RMS、SRA、Mean Absolute Value (MVA)、VAR、MaxV、SV、KV、CF和SF等特征提取感应电机在不同功率条件下的特征,用于断条检测。在[9]的工作中,将AMean、STD、VAR、SV和KV特征用于感应电机断条检测的特征提取。[28]的工作是利用RMS、PPV、KV和CF建立一种应用于齿轮箱的诊断检测方法。[4]的工作还突出了RMS、PPV、CF和KV的统计特征,在发动机故障分析中取得了良好的效果
这些工作[4,9,11,24,28,30]有一个共同的事实,即它们只使用非鲁棒统计估计量。这类估计器对异常数据和异常值敏感。因此,这项工作还旨在评估在异常检测技术中鲁棒估计器的使用。统计特征,如中位数,四分位数平均值,中位数绝对偏差(MAD),四分位数范围,偏度值的四分位数(SVBQ),峰度值的八分位数(KVBO),也已经实现和评估。在[16]的基础上实现了不对称估计(SVBQ)和峰度估计(KVBO)的鲁棒估计。在[12]的工作中,也探讨了使用稳健估计量作为中值和MAD而不是非粗糙均值和标准差估计量的想法,但采用了非常不同的实现。表2组织了上述论文使用的不同统计特征。统计特征分为三组,即集中趋势测量、离散度测量和其他测量。本表中使用的一些缩写词在第4节中有详细说明。
在文献中没有发现用于单变量和多变量数据的时间序列的无监督方法,该方法使用滑动窗口检测异常和异常值,该滑动窗口接近实时运行。在工业应用中,我们对无监督方法感兴趣,因为在大多数情况下我们没有工业数据的标签。该方法必须实时运行,以确保在当前数据窗口中检测到异常。同样,不需要知道哪些点是异常的,只需要知道哪些窗口是异常的。开发的方法也可以很容易地复制到不同的工业应用中,在这些应用中,我们有时间序列数据来监控机器的运行状态。
3、问题描述
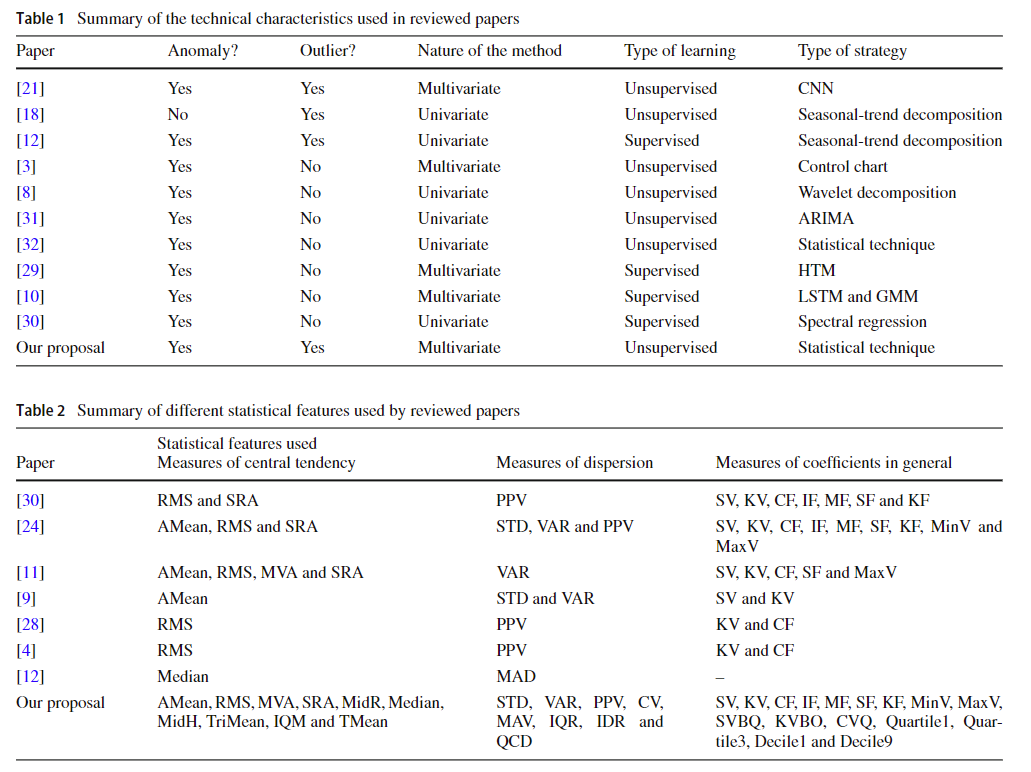
考虑一个由几台机器组成的工业生产系统,这些机器可能会或可能不一样。 我们将调用要监视 m 1 m_{1} m1的第一台机器,第二台要监视 m 2 m_{2} m2的机器,依此类推,直到最后一台机器 m Q m_{Q} mQ。 这些机器必须安装了用于人工智能技术的传感器。 因此,考虑到 S 1 1 S^1_{1} S11代表机器M1上安装的第一个传感器,该S1 2代表安装在计算机M1上的第二个传感器,依此类推,直到S1F1代表机器M1上安装的最后一个传感器。 同样,传感器S2 1,S2 2到S2F2代表机器M2上安装的传感器。 最后,传感器Q1,S Q2到S Q F Q表示Machinem Q中安装的传感器。 图1示意了工业生产系统的一部分,其中植物机器和安装在这些机器上的每台机器上的传感器都被突出显示。
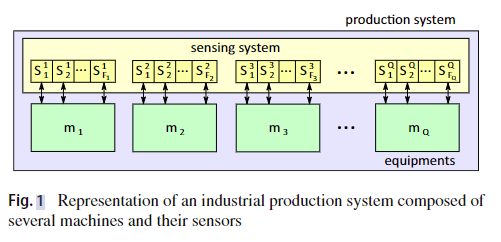
感测机器感兴趣的输出是时间空间数据,表征时间序列。因此,这个序列s被定义为一个变量在不同时间点的测量序列,并在公式(1)中进行数学描述。
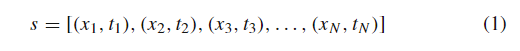
该级数由有序对(x r, tr)的集合组成,其中x r表示该级数在时刻tr的值。在这个系列中,N表示数据的总量,因此r∈{1,2,3,…, n}。时间序列的特征之一是tr值是严格递增的,即如果r1 < r2,则tr1 < tr2。绝大多数时间序列模型都认为t = tr−tr−1为常数,即任意两个样本之间的时间间隔总是相同的。本文提出的方法也考虑了t常数,因此,同样的时间序列可以写成s = [x1, x2, x3,…]。, x N]。这项工作将处理多个时间序列,每个时间序列来自不同的传感器,因此有必要区分传感器的数据序列,如Eq.(2)所示。
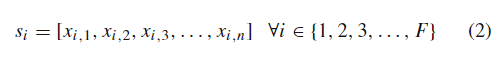
仍然,关于Eq.(2),在给定的机器中总共有F个传感器。大多数情况下,不同传感器的采集频率不同,即t值不同。所有传感器的数据都经过预处理,以保证所有传感器的t值相同。这样的过程通常会减少数据集的大小,但会带来更连贯的分析。然而,尽管执行了同步方法,但在特定的基准测试中没有实现或不需要同步方法。
尽管图1展示了几台可以使用该方法进行异常检测和预测性维护辅助的机器,但通过将该技术的一个实例单独应用于每台机器,可以大大简化问题。使用这种技术的一个实例是可以做到的,因为大多数工业机器的缺陷是相互独立发生的。例如,如果两台机器具有独立的功能,没有共同的支撑机制,那么故障的概率也是独立的[5]。这种建模方式简化了模型和问题描述。例如,Eq.(2)不需要索引来识别哪个机器属于时间序列。
让我们考虑图2中的示例,以说明时间序列中可能导致机器故障的异常情况。图2a显示了一个假设的时间序列,表示任何机器在8小时的运行期间的发动机温度。该系列呈现一些波动,温度在30°C和60°C之间振荡。对于所讨论的机器来说,这些波动被认为是正常的。图2b显示了同样的例子,但是从5小时开始,发动机温度开始上升,直到大约6小时12分钟,机器过热到甚至崩溃(可能发动机停止运行)。在此事件发生后,机器停止运行,温度近似线性下降。
AOD方法的主要思想是利用时间序列数据,检测数据中的异常。经常发生的情况是运转中的机器不会突然坏掉。休息前几分钟,传感器的数据就已经显示出一些异常情况。例如,查看图2b中以虚线划分的窗口。算法会注意到机器由于在断点之前的高温而出现异常行为。
图2c显示了假设数据的离群值检测过程。在这个例子中,在不同的窗口中有两个异常值检测。由于异常值通常反映的是不正确的传感器读数,甚至是一些数据采集失败,因此异常值检测不会导致相关机器的损坏。由于异常值的突发性,很难预测,但相对容易检测,因为它往往对局部数据造成很大的干扰。由于这种特性,异常值对预测性维护的影响很小。
图2D显示了一个时间序列,该时间序列具有行为变更点,其中建立了新的概念(方案)。 信号的变化发生是由于监视机器中安装了新的风扇,该风扇将机器的平均温度大大降低了约18℃。 因此,现在温度为30至60℃的机器现在的温度在12℃和42℃的范围内。 如[18]报道,这样的概念变化需要连续重新学习人工智能技术。 如果在一个概念中建立了培训并评估了另一个概念,那么误报和假否定因素的数量可能会大大增加。
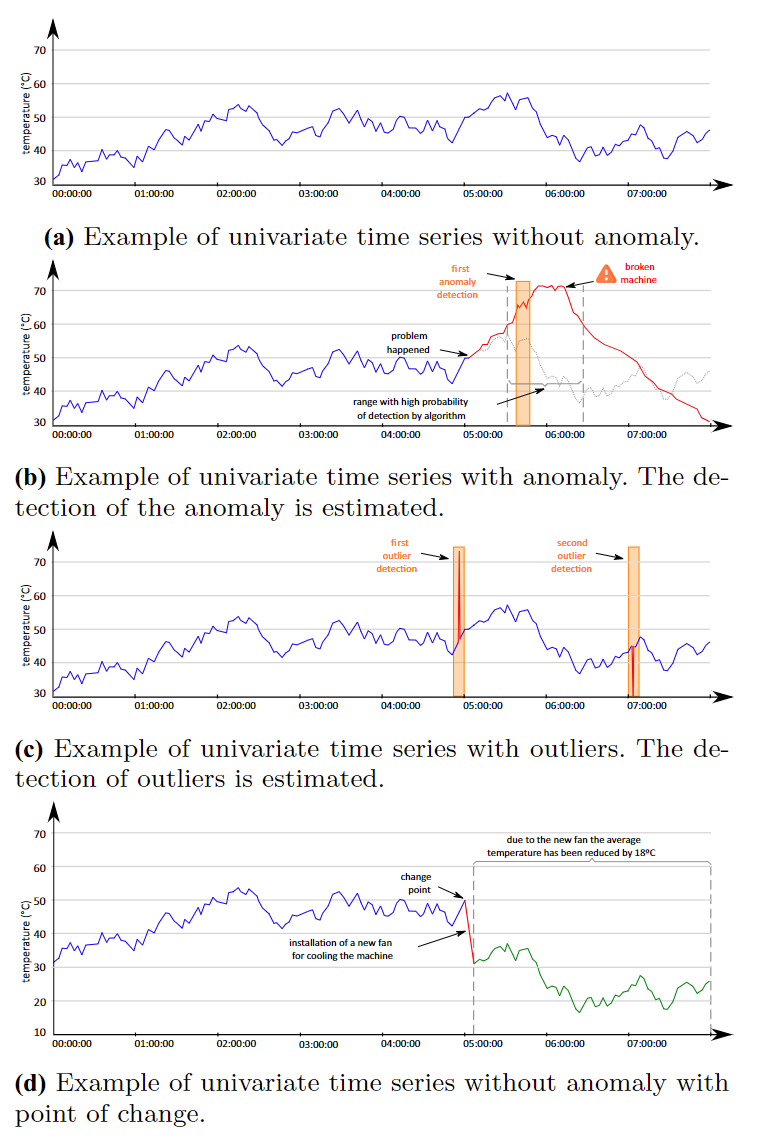
图2表示假设机器无异常和有异常的温度行为的时间序列示例
4、方法
该方法使用一组统计功能来合成输入信号的变化极限。 基于深度学习的特征提取,例如一维卷积神经网络还有其他可能性。 首先考虑了这种解决数据功能的方法,但是大量数据以及更新模型的频繁需求会使计划内处理不可行。 因此,通过统计变量直接证明这是深度学习的积极且合理的替代方案。 这些统计特征可以分为组,代表中心趋势度量,分散,系数及其衍生物。 这些组与表2中提到的相同。其中一些特征具有与输入数据相同的测量单元,而其他一些功能则没有测量单元,而另一些则具有与输入不同的单位。 考虑以下术语:

还要考虑方程中使用的下列函数:

4.1 统计特征
集中趋势度量是一个值,它代表了数据集中的中心值。该方法共支持10个可选择或不选择的集中趋势特征:算术平均值(AMean)、均方根(RMS)、绝对均值(MVA)、幅值平方根(SRA)、中程(MidR)、中位数(Median)、中间hinge (MidH)、TriMean、四分位数间均值(IQM)和截断均值(TMean)。
离散度的度量是一个值,它表示数据集的分布有多长或多窄。共有8个特征可以选择:标准差(Standard Deviation, STD)、方差(Variance, VAR)、峰值值(Peak-Peak Value, PPV)、变异系数(Coefficient of Variation, CV)、绝对偏差中位数(Median Absolute Deviation, MAD)、四分位间距(intertile Range, IQR)、十分位间距(interile Range, IDR)和四分位间距系数(Quartile Coefficient of dispersion, QCD)。
一般来说,系数度量是一种形式度量,一个指数,甚至是一个数据集的极值度量。所开发的方法共支持16个可选择的系数特征,分别是:偏度值(SV)、峰度值(KV)、峰顶因子(CF)、脉冲因子(IF)、边际因子(MF)、形状因子(SF)、峰度因子(KF)、最小值(MinV)、最大值(MaxV)、基于偏度值的四分位数(SVBQ)、基于峰度值的八分位数(KVBO)、四分位数变异系数(CVQ)、第一四分位数(quartile1)、第三四分位数(quartile3)、第一十分位数(decile1)和第九十分位数(decile9)。
最后,导数域中的一个测度是应用离散导数后在级数上计算出的上述特征之一。所开发的方法在导数域中支持34个特征。一些支持的度量是算术平均值的导数(DAMean)、STD的导数(DSTD)、SV的导数(DSV)、KV的导数(DKV)、中位数的导数(DMedian)、IQR的导数(DIQR)、SVBQ的导数(DSVBQ)和KVBO的导数(DKVBO)。
4.2提取特征总结
表3总结了前面提到的特性,并显示了它们的计算时间复杂度。可以看出,存在一些线性复杂度为O(n)的特征,其中n为输入观测值的总数。例如,算术平均值的线性复杂度为n。这样,就可以用常数乘以输入数据的n次运行来计算这个度量。还有一些指标具有对数线性复杂性或O(n log(n))。例如,中位数是一个具有对数线性复杂性的度量,这可以通过以下事实来解释:必须对数据进行排序,然后返回到中位数。
您感兴趣的功能的选择仅取决于应用程序。 如果我们希望将此方法应用于离群检测问题,则应选择非重构估计器以更有效地突出这些点。 另一方面,如果利息是忽略异常值并仅检测异常,则应选择强大的估计器。 如果时间序列是静止的,则应选择中央趋势指标以显示序列逃脱平稳性建立模式时可能的异常情况。 同样,如果时间序列是非平稳的,则不应使用中央趋势指标,因为该序列不会在常规间隔周围振荡。 通常,在衍生域中采用的指标强调了标准信号中未突出显示的特征,例如通过分散度量测量的信号的粗糙度。 最后,衍生域指标维护信号的时间性方面,这在使用标准信号计算的指标中不会发生。
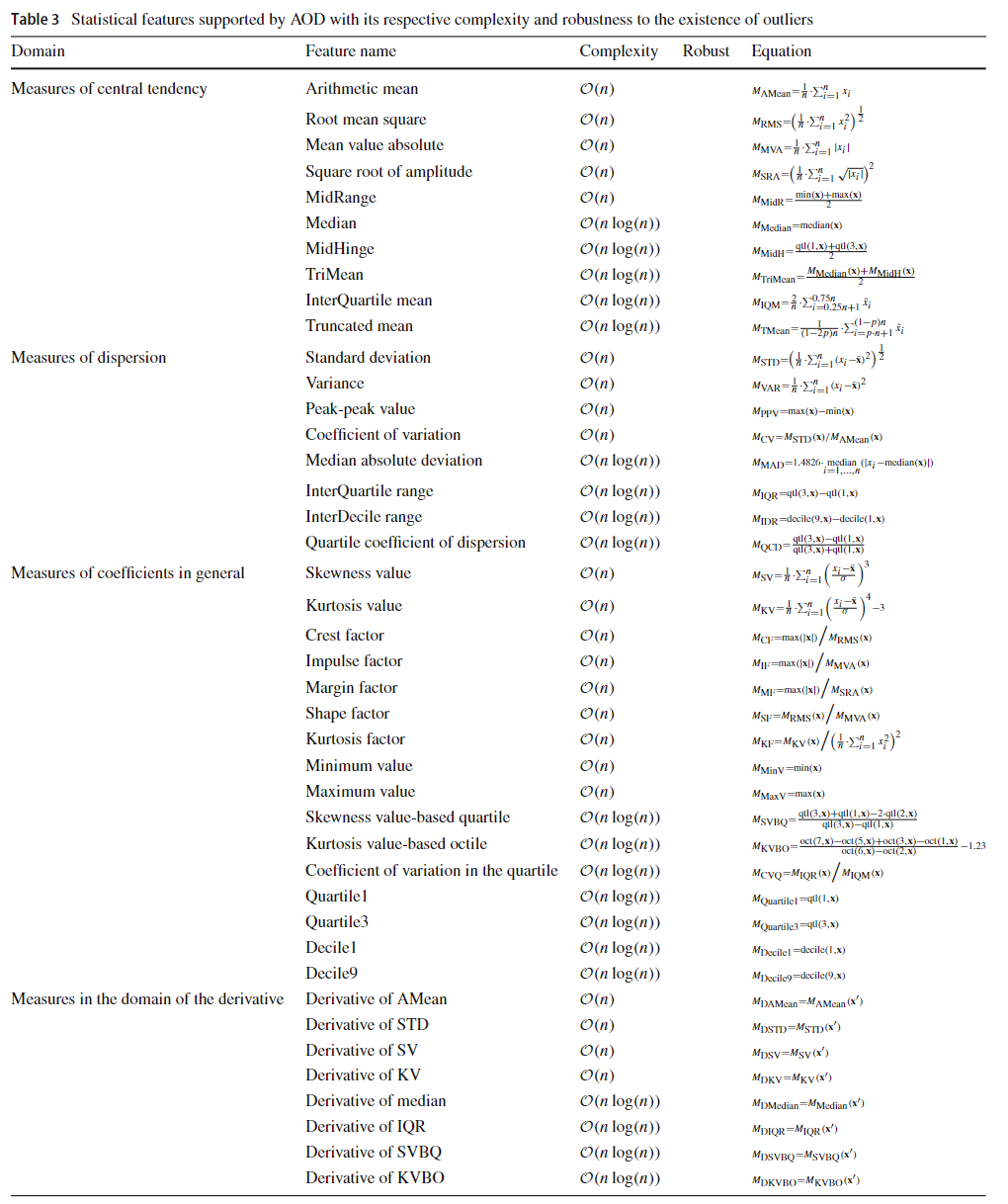
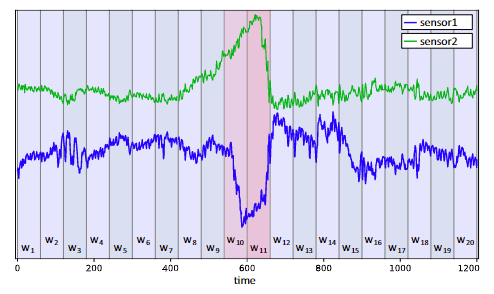
图3连接到同一台机器的两个传感器的假设数据
4.3 学习阶段算法
AOD,像许多人工智能技术一样,有两个阶段,训练和测试。由于所提出的方法是无监督的,因此不需要有观察标签。训练期间的唯一要求是数据序列来自正常运行条件下的机器。如果存在代表异常或异常值的数据,则必须删除这些数据,使算法只学习机器的常规操作。由于不可能保证训练的输入数据与正常操作条件有关,因此还开发了一种从训练集中删除任何异常的策略。在观测数方面,训练集中的数据量越大越好。然而,即使训练集中的数据很少,结果也被认为是高质量的。在测试过程中,使用滑动窗口来定义特征提取区域和后续分析。使用数据滑动窗口的理由是,该窗口允许计算一组需要多个数据的特征。此外,窗口比一次只考虑一个数据点的技术更好地揭示了信号特性。因此,检测到的异常值和异常与一个或多个窗口相关联,这些窗口由时间序列中任意数量的点组成。
在提出训练算法之前,让我们考虑图3,这说明了一些与两个不同传感器系列相关的培训的假设数据,但从同一机器中获取数据。 在此图中,每个时间序列都分为20个子窗口,每个窗口分别为60点,称为W1,W2至W20。 这些窗口中的每一个都带有某些信息,但大多数窗口通常显示机器的正常操作行为。 但是,在W10和W11窗口中,该机器呈现出异常,使我们有必要从训练中删除这些窗口,正如我们稍后将看到的那样。 在培训期间,在每个子窗口中,计算了表3中列出的统计特征。 为每个选定的特征和每个传感器所获得的最大和最小的值都存储。 这些值代表训练有素的学习模型。
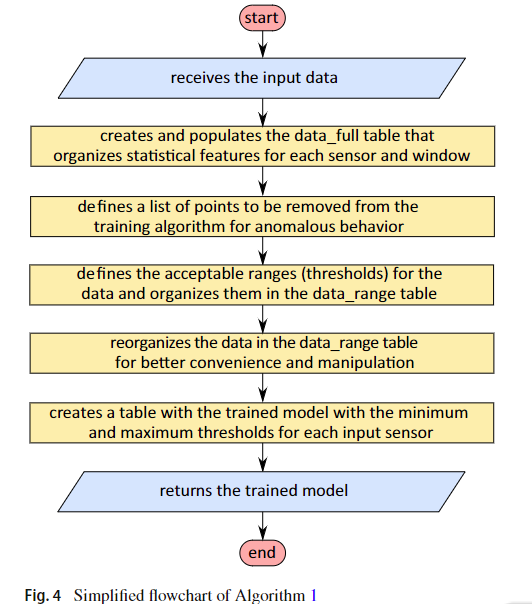
基本的流程图在图4中显示,训练算法中执行的主要步骤。 图4合成了算法1的内容,该算法1还包括算法2作为流程图的第二个块(要删除的点列表的定义)。 算法1提出了从表3中获取功能限制的主要步骤。在此算法中,DF_TRAIN表包含长时间内传感器收集的数据。 来自培训阶段的DF_Trainare的数据。 Data_full表组织为每个传感器和每个培训窗口计算的统计功能。 Data_range表包含从每个传感器和每个功能提取的所有统计特征的最小值和最大值。 最后,data_to_df表存储学习模型,并包括数据表的重组。 训练阶段中使用的算法1如下所述。

算法2介绍了删除具有潜在训练异常的窗户的方法。 此方法返回必须从培训集中删除的所有窗口索引的列表。 用于删除窗口的标准是基于每个窗口和数据质心之间计算的距离的度量。 远离数据质心的窗口往往是机器出现问题的窗口,因此应将其删除。 例如,如果您在图3的数据上使用Cut_Factor在图3的数据上运行窗口删除算法,则总共将删除两个窗口的20个窗口。 卸下的窗口将是W10和W11,这是两个窗口与已建立的操作模式最偏差的窗口。 点(lpoints)的列表总计k点,每个点属于实际坐标空间rd = rf·j。 标准点列表的列表也发生了同样的情况。 质心是实际坐标空间RD中的一个点,它存储了每个数据窗口传感器的指标的平均行为。 因此,从训练组中删除了最远的质心点。

算法的训练阶段的时间复杂性由O(k·f·j·n·log(n))给出。 因此,我们可以看到训练是关于窗口数(k)的数量,传感器数(F)和指标数(J)的线性线性。 培训是关于每个窗口(n)数据点数的日志线性。 这种复杂性几乎与输入参数有关,这使得训练阶段非常快速,适合大数据应用程序。
4.4测试阶段算法
这一阶段发生在该方法应用于可能包含异常值和离群值的新数据集提取参数之后。图5显示了寻找可能异常的评估方法的流程图。
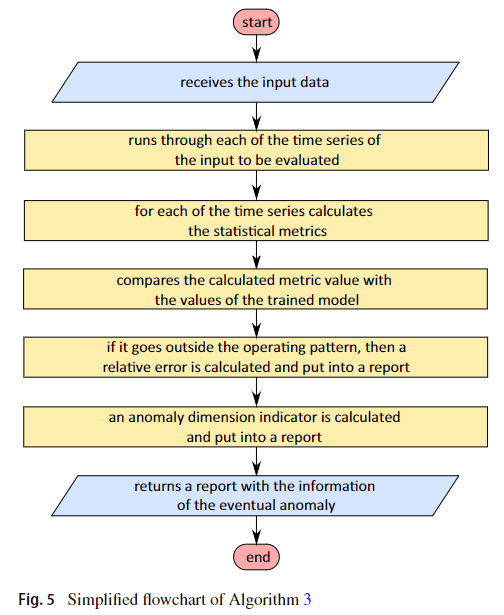
算法3显示了评估方法背后的思想,以识别输入数据中可能的异常或离群值。与异常检测相关的一个重要方面是降低数据中的噪声。为此,不仅需要选择健壮的特征,还需要使用滑动窗口。然后对有问题的窗口执行异常或离群值检测,而不是对构成该窗口的数据的每个点执行异常或离群值检测。例如,当指向包含异常值的特定窗口时,该方法不会突出显示异常值位于窗口的哪个点,而是向整个窗口发出信号。

算法评估阶段的时间复杂度为O(F·J·N·log(N))。因此,除了缺少窗口数因子(K)之外,评估的复杂性与训练的复杂性相似。这一点是合理的,因为计算只针对当前窗口进行。事实上,训练和评估的复杂性几乎是线性的,这意味着该方法可以非常快速地执行训练和评估。AOD参数K、F、J、N的典型值为:K[10,10000]、F[1,20]、J[4,20]、N[5,500]。
5、结果
在两个单变量的公共基准和两个专有的多元数据集中对AOD进行了评估。 第一个评估的数据集Yahoo Outlier基准(YOB)用于检测单变量时间序列中的异常值。 第二个评估的基准Numenta异常基准(NAB)用于单变量时间序列中的异常和异常值检测。 第三是具有使用AGOTS工具合成生成的多元数据的数据集。 第四个数据集由来自植物石油生产行业的案例研究的多元数据组成。 YOB和NAB基准都在不同的应用领域都具有合成和真实数据。 根据评估的基准:YOB,NAB,合成数据集和案例研究,将本节的结果分开。
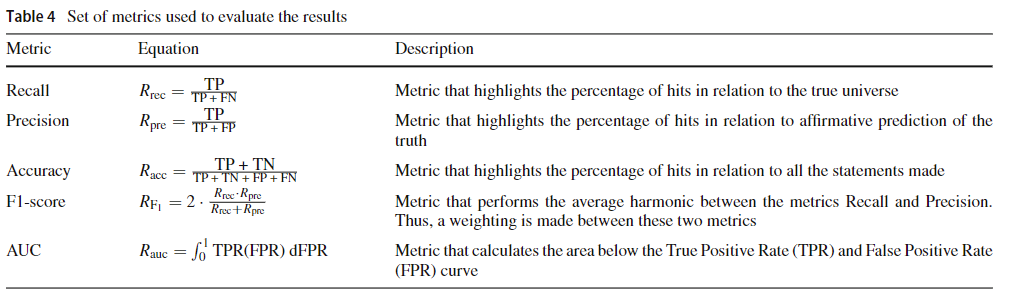
用于评估结果的指标是:召回(也称为灵敏度),精度,准确性,F1得分和接收器操作特征曲线(AUC)下的面积。 这些指标通常用于在异常检测和异常检测的背景下报告算法的效率[2,18,21,27]。 表4列出了这些指标的方程式和简短描述,其中TP,FP,FN和TN是真正正面,假阳性,假阴性和真实负面的首字母缩写。
5.1 YOB评价:单变量
此处描述了在Yahoo Outier基准(YOB)上获得的计算结果。 1此数据集包含带有标记离群值的367个单变量时间序列,并将其细分为四个子基准测试,称为A1,A2,A3和A4。 A1子基准包括具有实际数据的67个时间序列。 A2,A3和A4子基准测试包含300个时间序列,其中包含合成数据,每个子基础基准总计100个时间序列。 A2和A3子基准测试只有离群值,而A4子基准测试既包含异常值和变更点。
标签信息仅用于评估该方法的性能,这是由于AOD无监督的性质。 表4中显示了用于此类评估的所有方程式,在评估此基准测试时,我们只对异常检测感兴趣,因为该基准没有异常。 因此,使用的统计指标为:MSTD,MPPV,MDSTD,MDPPV。 因此,我们有j = 4,算法1和3的指标列表变为list_metrics = [MSTD,MPPV,MDSTD,MDSTD,MDPPV]。 这些指标是从初步研究中选择的,并基于教派报告的信息。 5.5。 所选的所有统计指标都是有助于检测异常值的非重构统计指标。 由于YOB具有非平稳时间序列,因此没有使用中心趋势指标。 由于该基准是单变量的,因此传感器列表仅包含一个时间序列(F = 1)。
在这些实验中,在下一个实验中,每个实例中有40%用于培训,60%用于测试。 NSliding窗口的大小为10(n = 10)。 根据数据集的内部特征选择此值。 由于实例具有不同量的数据,用于训练的Windows K的量在57至67之间变化(K∈[57,67])。 用于从训练中去除潜在异常窗口的截止因子为10%(cut_factor = 0.10)。 由于子基准A4的时间序列具有概念变化点,因此有必要不断重做学习阶段以重新学习时间序列格式的新趋势。 如果未放置这种恒定的重新学习,则自信率较低。 图6说明了每种子基准A1至A4中使用的AOD方法获得的结果。 在此图和下一个图中,时间序列以蓝色突出显示,垂直绿色柱在基准中标记为离群值。 橙色底部的矩形是AOD检测到的离群值的列; 红色矩形是该方法未检测到的异常值; 黄色矩形是从训练中取出的柱; 粉红色的矩形突出了时间序列中概念的开始变化。
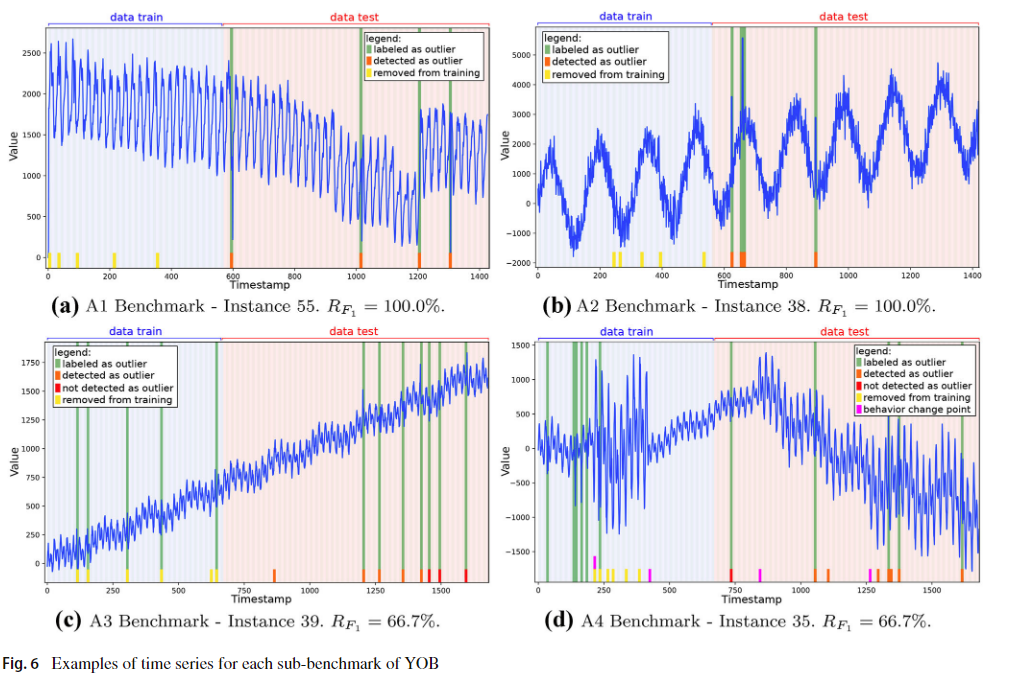
表5给出了AOD方法在几种评估形式中测量得到的结果。该表按子基准对结果进行分组,并给出混淆矩阵。由于离群值和非离群值类别之间存在很大的不平衡,因此准确性不够,因为每次命中都给予相同的权重。通常需要的是方法的高召回率和高准确性。当应用于工业机器中的异常检测问题时,召回因子比精度因子更重要,因为即使没有发生异常(FP),也比不检测异常(FN)更可取。F1-score和AUC更适合验证该方法的平衡性能。一旦平均表现良好,就会寻求高回忆率。A1子基准的异常值很难被发现,f1得分为48.6%。这种困难可以归因于具有复杂行为的真实数据,其中没有趋势效应和季节性。次级基准A4也出现了这种困难,f1得分为58.1%,但这来自于该系列的概念变化。在A2和A3子基准中,异常值的检测相对容易,f1得分超过90%。最后,在子基准A1到A4中获得的AUC值超过80%。
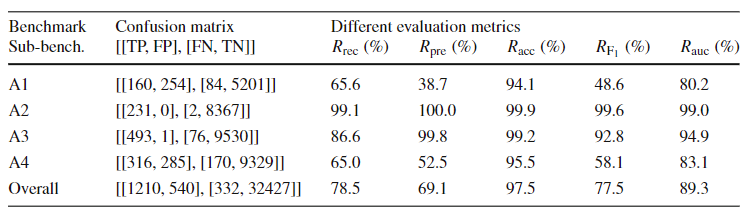 表5应用于YOB的AOD方法的不同度量的评价
表5应用于YOB的AOD方法的不同度量的评价
YOB中假阳性(FP)的总数为540,假阴性(FN)的总数为332(见表5)。这些数字表明,算法指控FP的几率比FN高62%。考虑到在预测性维护中对FP的容忍度高于FN,这些值是可以接受的结果。FP指的是在实际故障发生之前计划进行干预,而FN指的是机器发生故障。
AOD方法不能直接与其他异常点检测方法(如DeepAnT、Yahoo EGADS和Twitter S-H-ESD)进行比较,因为方法不同。例如,DeepAnT、雅虎EGADS和Twitter S-HESD对每个点进行返回,无论它是否是异常值。相反,AOD方法返回所分析的滑动数据窗口是否包含异常值。
任何方法都必须至少比朴素估计执行得更好。表6显示了在YOB上应用虚拟方法获得的结果。评估的虚拟策略是积极的,消极的,均匀的,分层的。正策略表示每个点都是离群值,负策略表示所有点都不是离群值。统一策略将该点标记为离群点和常规点的机会均等(50%)。最后,分层策略有5%的机会回答它是一个离群值,95%的机会回答它不是一个离群值,其中5%的值是从这样一个事实中提取出来的,即平均而言,A1到A4基准有5%的窗口与离群值。由于均匀法和分层法的随机性质,分别执行10次,然后报告共同海损。如表6所示,在对召回率和f1得分指标进行分析时,Positive方法具有更好的性能。当使用精度和精度指标进行分析时,Negative策略具有更好的性能。最后,在对AUC指标进行分析时,所有虚拟方法都具有相同的性能。

表6虚拟方法对YOB不同指标的评价
图7显示了具有不同形式的重新学习过程在YOB上获得的结果。 在该图的第一个块中,有分析仅在时间序列的第一部分进行学习,并且随着时间的推移没有重新学习过程。 在第二个块中,对每个新的数据窗口进行了重新学习步骤,例如,训练块会滑动并添加新窗口,同时它会忘记一开始就忘记了相同数量的窗口。 在这种方法中,培训的百分比始终是观察结果的40%。 在第三个块中,我们分析了随着新数据的处理,训练窗口的生长位置。 在这种类型的分析中,该方法不会忘记初始数据,并且添加了所有新观察结果。
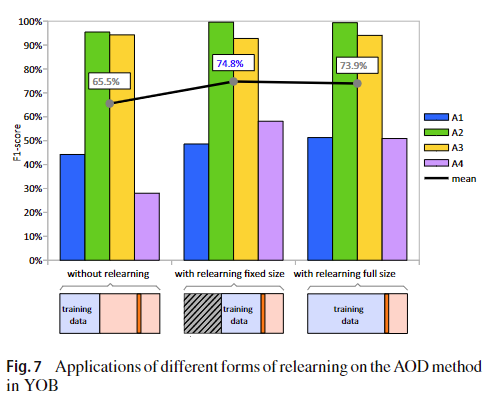
未再学习的结果不佳,多发生在有观念改变点的情况下。这种行为的发生是因为模型是用特定条件下的数据训练的,当观察中出现新概念时,它不能理解。如果没有模型的重新学习,这样的变化会导致一系列的假阳性或假阴性。通过引入固定大小的再学习,子集A4的f1得分提高了30.1%。最后,AOD方法训练每个实例所需的平均时间为27.3 ms。评估每个测试窗口所需的平均时间为8.4 ms。在采用Intel酷睿i5第8代处理器、内存为8gb的计算机上进行计算实验。
5.2 NAB评价:单变量
数据集Numenta异常基准(NAB)2包含58个单变量时间序列数据,其中带有单独文件中标记的异常点。 它被细分为七个子基准:人造毒液(Artnoano),人造withanomaly(Artwiano),realloadecause(realknca),realadexchange(realadex),realawscloudwatch(realaws),realaws(realaws),realtraffic and traffaffic and Realtweets。 人造词组分子基准包含五个时间序列,该序列具有人工数据,没有异常。 人造词组子基准包含六个时间序列的人工数据,并带有一些异常。 真正的众所周知子基准包含具有异常点的七个时间序列的真实数据,其中一些异常也是异常值。 子基准测试Realadexchange,RealawsCloudWatch,RealTraffic和Realtweets还包含具有异常点和/或异常值的几个时间序列。 RealawsCloudWatch子基准测试除了异常和异常值外,概念在时间序列中更改点。
对于这个基准,异常和异常值都是有趣的。 因此,使用的功能是:MAMEAN,MRMS,MMEDIAN,MIQM,MSTD,MPPV,MMAD,MIQR,MIQR,MSV,MKV,MSVBQ,MKVBO,MKVBO,MDMAD,MDMAD,MDIQR,MDIQR,MDSVBQ和MDKVBO。 选定的统计指标中有十个是稳健的统计指标(用于异常检测),而其他六个选定的统计指标是不重做的(用于离群值检测)。 有关这些选择的更多信息。 5.5。
在实验中,数据窗口大小N在40 ~ 240之间变化(N∈[40,240])。这个N值是根据每个子基准的内部特征选择的。由于实例的数据量不同,用于训练的K个窗口的数量从6到151不等(K∈[6,151])。训练中使用的截止因子为10% (cut_factor = 0.10)。图8展示了将AOD方法应用于每个子基准的实例所获得的结果。
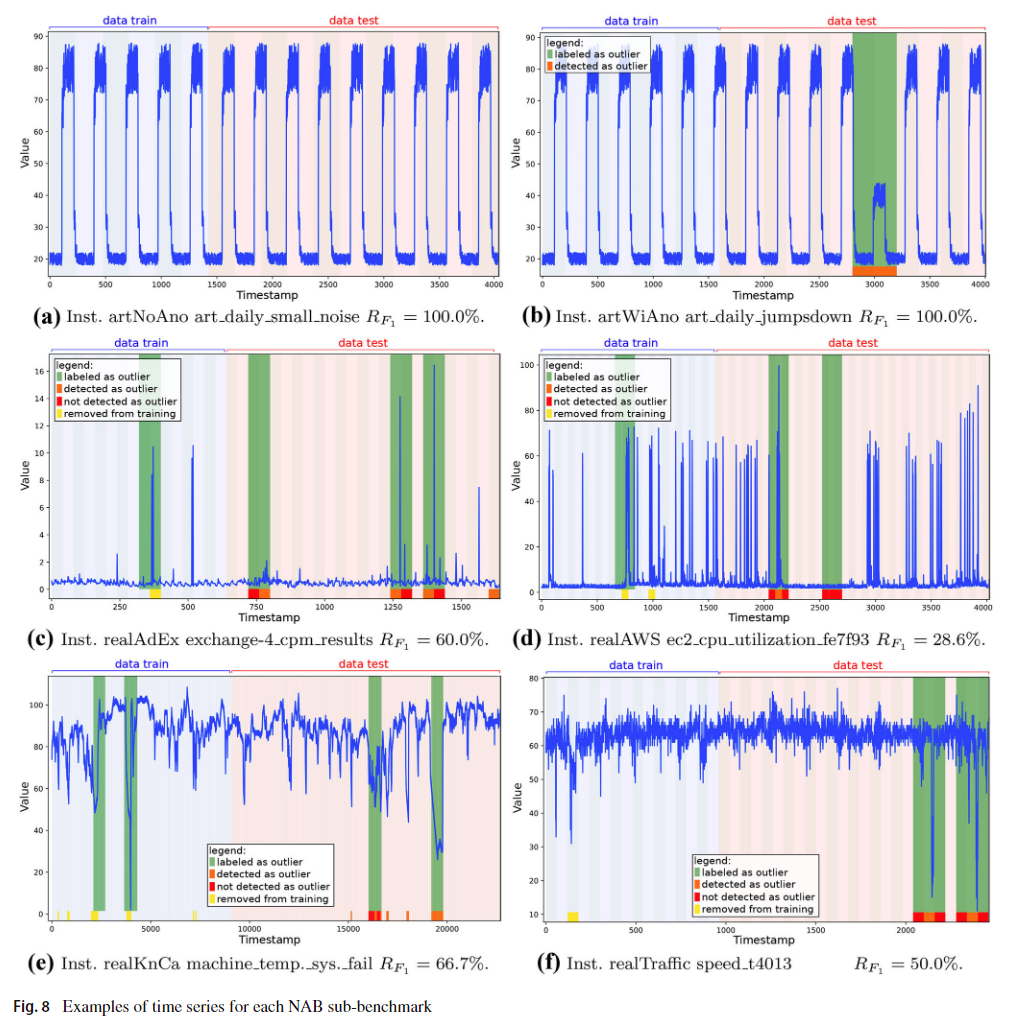
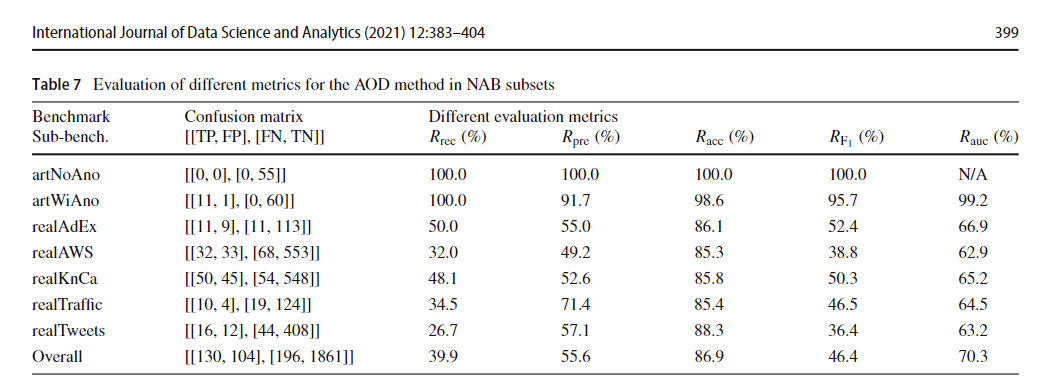
表7列出了通过AOD方法在NAB上获得的结果,该结果通过子基准分组,并在几个指标上进行了测量。 在没有异常或异常的人工基础基准人造词中,可以看作是简单的,F1得分为100%。 在人工子基础基准的人造植物分析中,也很简单,检测到异常相对容易,在该异常中,达到95.7%的F1得分。 请注意,此子基准中的召回率为100%,例如,正确检测到所有异常,但准确性为91.7%,表明误报。 在子基准的真实因素中,检测达到50.3%的F1分数。 在分析的所有子基准测试中,我们获得的最糟糕的性能是磨台,F1得分为36.4%。 RealawsCloudWatch子基准测试的性能也相对较低,F1得分为38.8%,因为它是一个复杂的数据集,具有异常点,离群值和概念更改点。 在所有分析的子基准测试中,从AUC获得的速率高于62%。
解释获得的低f1分值的因素之一是NAB如何执行异常标记。最初,专家识别每个数据实例中的异常中心,并将其标记为异常数据。然后,由于难以确定异常何时开始和何时结束,该异常周围10%的观测也被归类为异常。因此,许多其他观测结果也被归类为异常,即使不是异常。
NAB中FN的总数为196个,FP的总数为104个(见表7)。这些数字表明,算法指控FN的几率比指控FP的几率高88%。这些值可以通过在NAB中如何标记异常来解释,在NAB中,即使基准已经将观察标记为异常,算法也没有足够的信息来预测它是异常。
与YOB一样,由于方法的差异,AOD方法不能直接与NAB中的DeepAnT、Yahoo EGADS和Twitter S-H-ESD方法进行比较。因此,通过使用数据窗口而不是数据点,召回率、精度和f1得分指标比文献方法报告的结果要好得多。事实上,NAB文献技术公布的查全率、准确率和F1-score值都较低。同样,这可以通过NAB中异常标签的制作方式来解释。
表8显示了按照YOB使用相同的策略,通过虚拟方法获得的结果。 唯一的区别是分层策略,现在有10%的机会回答它是一种异常,而90%的机会回答它不是异常。 该值的占10%,因为NAB子基准平均有10%的Windows具有异常。 如表8所示,当分析召回和F1得分指标时,阳性方法具有更好的性能。 分析准确性和精度指标时,负面方法具有更好的性能。 最后,在分析有关AUC指标的分析时,所有虚拟方法都具有等效性能。 重要的是要强调的是,在只有一个数据类别(如人工拨入子基准)中,AUC度量不能应用于(n/a)。
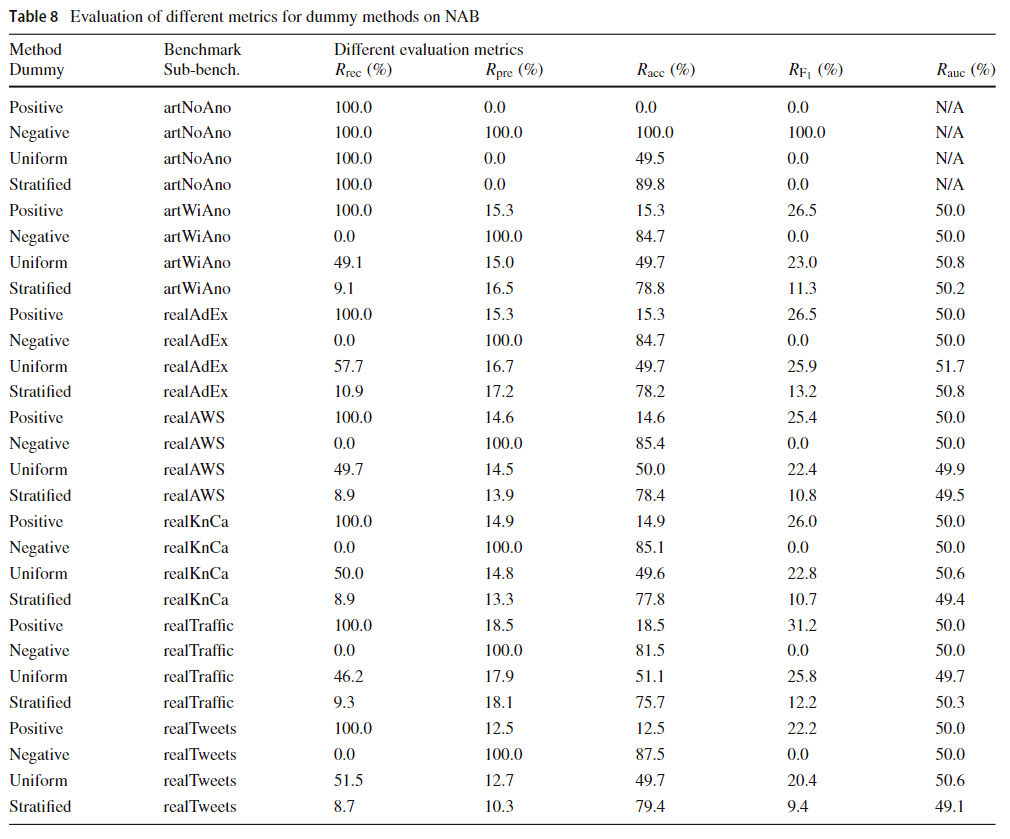
图9显示了在NAB上使用执行重新学习过程的不同方法获得的结果。在这个图的第一个块中,有一些分析,其中学习只在时间序列的开始完成,并且随着时间的推移没有重新学习过程。在第二个块中,我们分析了在每个新数据窗口中重新学习的情况。在第三块中,我们分析了训练窗口随着新数据的处理而增长,并且没有遗忘初始数据。
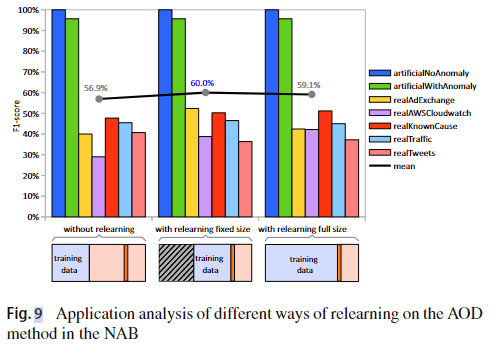
在没有重新学习的情况下获得的结果是不令人满意的,主要是在有概念改变的情况下。通过引入再学习固定大小子基准,realAWSCloudwatch的f1得分提高了9.8%。AOD方法训练每个实例所需的平均时间为75.4 ms,每个窗口的平均时间为26.6 ms。
5.3对合成数据集的评价:多元
本小节给出了AGOTS3工具综合生成的多变量数据的计算结果。用4个时间序列生成5个人工实例。生成的第一个实例(multivariable -1)没有异常。其他四个实例具有异常现象,如移位、方差和趋势。本研究在综合生成的多变量数据上验证了该方法的有效性。该工具的缺陷被标记,并没有用于训练,只是用于评估结果。
大多数缺陷类似于异常,因此所使用的统计指标是:MMedian,MIQM,MMAD,MIQR,MIQR,MDMAD,MDMAD,MDIQR,MDIQR,MDRMS,MDVAR。 因此,选择的指标数为j = 8。重要的是要注意,所选八个统计指标中的六个是有助于异常检测的可靠统计指标。 该数据集是多变量的,由四个时间序列组成(F = 4)。 在实验传导中,数据窗口大小n设置为60(n = 60)。 用于训练的K窗口的数量为16(K = 16)。 训练中使用的截止因子是数据窗口的10%(cut_factor = 0.10)。 图10显示了AOD方法在此多元基准的实例上执行的检测,其中达到了94.1%的F1评分。
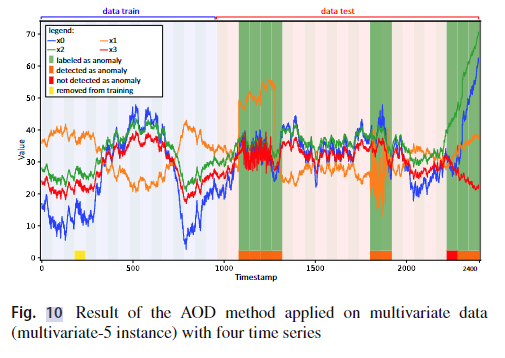
表9给出了AOD方法对AGOTS工具综合生成的5个实例的评价。平均f1评分为91.4%,平均AUC为92.4%,异常检测效果良好。观察混淆矩阵,我们可以看到假阳性数为零,这表明该方法检测到的所有异常实际上都是异常。
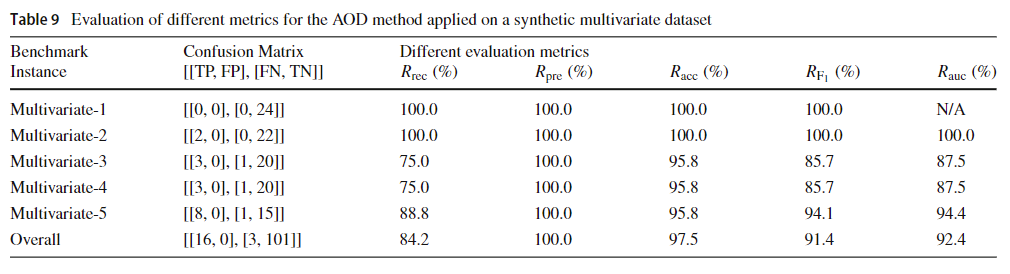
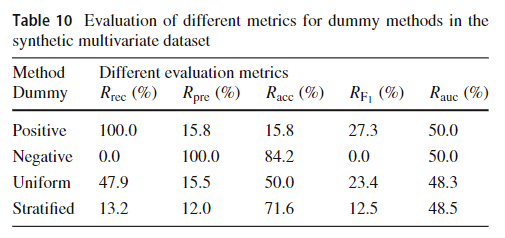
表10显示了应用于合成多变量数据时虚拟策略获得的结果。分层方法独立于输入中读取的任何值,有16%的机会回答它是异常,84%的机会回答它不是异常。之所以选择16%的值,是因为该数据集平均有16%的窗口具有异常值。
AOD方法训练每个实例所需的平均时间为67.6 ms。评估实例的每个测试窗口所需的平均时间为5.55 ms。
5.4案例研究评价:多元评价
该小节介绍了从植物石油生产行业进行的案例研究获得的计算结果。 该机器用于破坏晶粒,由两个电动机组成,它们旋转两对圆柱体,一对圆柱,一个下部。 这项研究考虑了代表两个电机的电流数据的两个时间序列。 这些传感器可以根据机器的性质关联。 从顶部进入机器的谷物需要更多的能量,因此其中一个传感器的值必须更高。 因此,该案例研究验证了多元时间序列中提出的方法。 在这里发生检测称为缺乏负载的故障,这被认为是时间序列方面的离群值。 专家标记了失败,但仅在培训期间使用标签,仅在结果评估期间使用。
由于失败类似于异常值,因此使用的统计指标为:MSTD, MPPV, MDSTD, MDPPV。因此,所选指标的数量为J = 4。所有选择的统计指标都是非稳健的统计指标,有助于检测异常值。由于该基准是二元的,传感器列表包含两个时间序列(F = 2)。
在接下来的实验中,将数据窗口大小N设置为60 (N = 60)。用于训练的K个窗口的数量为6312 (K = 6312),截断因子为数据窗口的10% (cut_factor = 0.10)。图11显示了在该案例研究中使用AOD方法执行的检测,其中f1得分达到了90.3%。
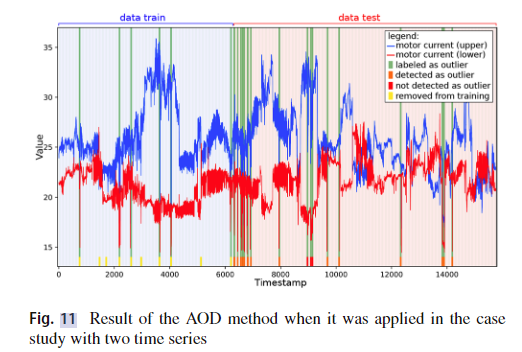
表11给出了AOD方法在案例研究中的评价,f1得分为90.3%,AUC为91.2%。观察混淆矩阵,可以看到假阳性为0,假阴性为3。

表12显示了应用于案例研究时虚拟策略获得的结果。分层方法,无论在输入中读取任何值,都有2%的机会响应为异常,98%的机会响应为非异常。2%的值是从这样一个事实中提取出来的,即平均而言,本案例研究中有2%的窗口具有异常值。
训练每个实例所需的平均时间为76.0 ms,评估每个实例的测试窗口所需的平均时间为10.1 ms。
5.5统计特征的行为研究
本研究是为了衡量表3中每个统计特征在f1得分方面的影响。图12显示了YOB、NAB、合成数据集和案例研究基准测试的性能。在图12a的x轴上,有68个实现的指标。YOB基准的f1分数在y轴上。图12b显示了NAB基准评估,图12c是对合成数据集的评估。最后,在图12d中,我们对案例研究进行了评估。
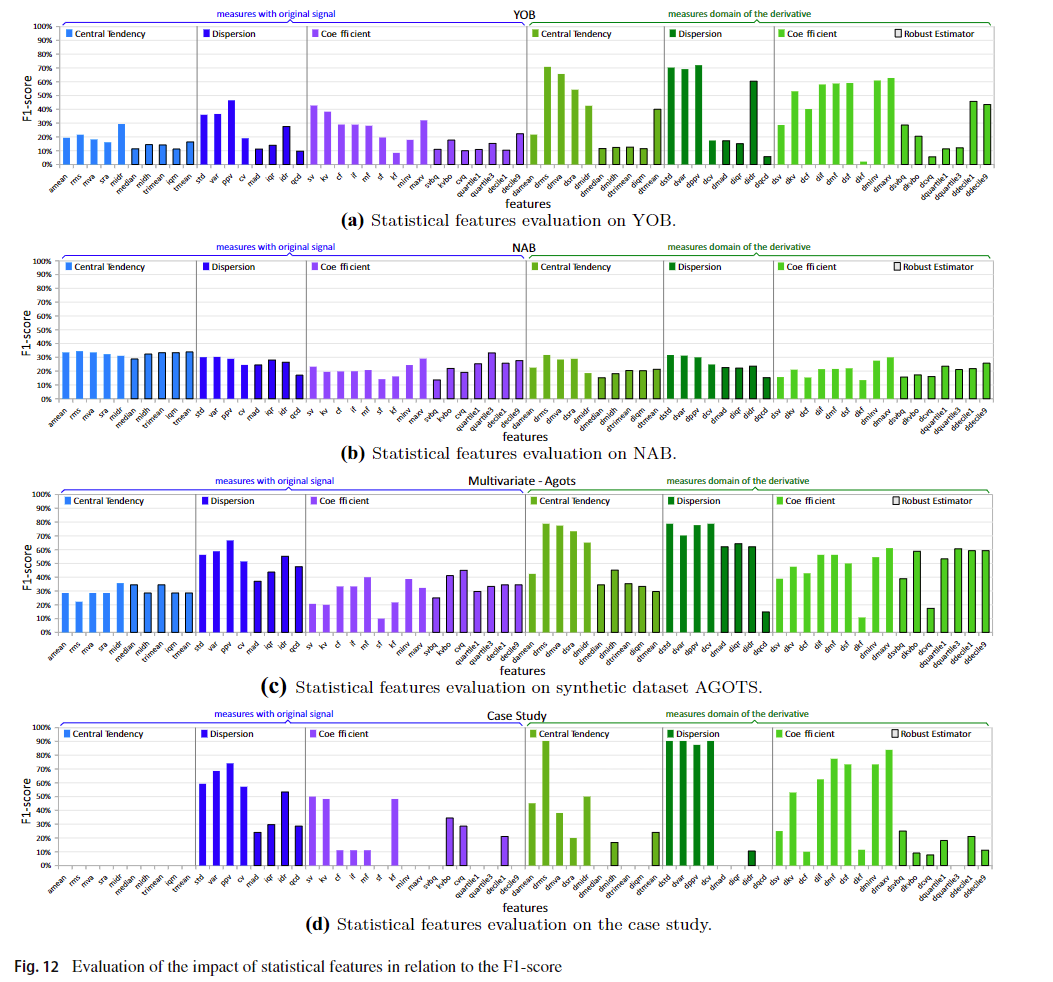
表13给出了按基准组织的可用统计估计器的概述。统计特征按类别分组,表值按F1-score表示。
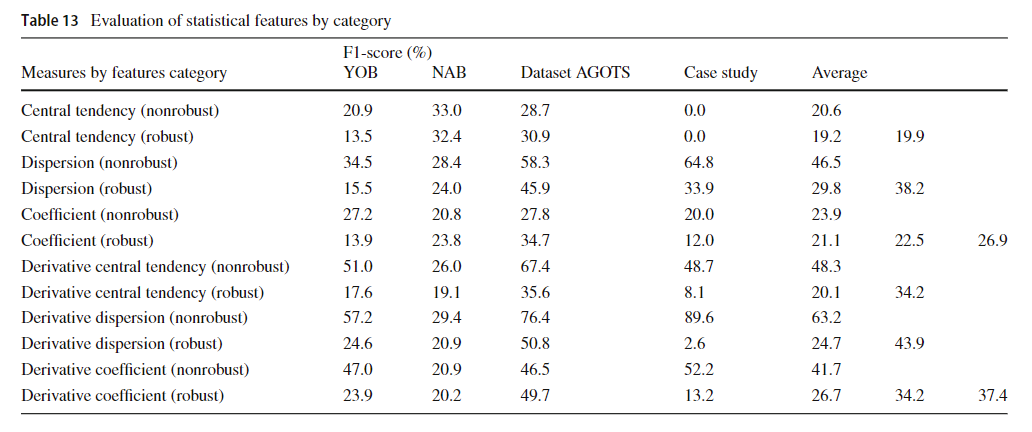
对于YOB而言,获得最佳F1得分的统计功能是无体。 该观察结果可以证明是合理的,因为YOB主要包含离群值,并且非重构估计器对离群值敏感。 尽管如此,关于YOB,获得最佳性能的度量类别是分散性的,因为异常值带来了很大的数据分散。 关于信号起源,当统计特征是衍生域中的统计特征时,性能得到改善。
对于在NAB上得到的结果,鲁棒和非鲁棒统计估计器获得了等效的性能。这个结果是合理的,因为NAB包含异常值和异常值。因此,异常主要由鲁棒估计量发现,而非鲁棒估计量则显示异常值。尽管如此,NAB表现最好的统计特征类别是中心趋势指标。这是因为当异常发生时,数据的中心性会发生重大变化。在信号起源方面,使用原始信号特征,即不应用导数,可以提高性能。
从实例分析的结果来看,非鲁棒统计估计器获得了较好的性能。这一结果是合理的,因为失败与案例研究中异常值的检测有许多相似之处。获得最佳性能的统计特征类别是离散性。在信号来源方面,在导数域使用度量可以提高性能。
第5.1节、5.2节、5.3节和5.4节的结果组合使用了不止一种统计特征。通常,组合特征的使用有助于检测具有不同行为的故障。目前还没有进行任何研究来找到应该用于每个特定基准的最佳特性。因此,研究数据和信号的性质有助于选择在实验中使用的特征。
在github At上找到了一组包含在YOB,NAB,合成数据集和案例研究基准的所有实例中获得的结果的图像。 4这些图像显示了所有分析的时间序列以及检测到异常和异常值的位置。 该存储库还包含人为生成的实例文件。
6、讨论与结论
本文提出了一种新方法,称为异常检测器(AOD),用于检测时间序列中的异常和异常值。 学习方式是无监督的,由于其复杂性低,训练和评估的速度也很快。 该方法旨在实时运行(在线),但也可以离线运行。 它支持单变量或多元数据评估,并使用数据滑动窗口,从中提取和分析了统计特征。 由于方法的开发方式,仅通过更改所使用的统计指标,它就可以轻松地检测异常值或异常值。 该功能至关重要,因为它将提出方法的检测能力扩展到两个略有不同的域。 已经表明,所提出的方法可以通过简单地在收集新数据时重新学习数据历史来处理时间序列数据中的概念更改点。 这种重新学习是必要的,因为以前学习的模型通过将变化纳入时间序列而与新数据不一致。 提出的方法有助于实现预测性维护,重点是诊断部分。
该方法在两个单变量基准中进行了评估:异常值检测(YOB)和异常检测(NAB)。通过综合生成的多元数据和植物油生产行业的实际案例研究,对该方法进行了评价。实验表明,对于离群值检测,滑动窗口的大小应该较小。还发现,需要一个重新学习程序来处理在获得新观测结果时数据中的概念变化。
将AOD与4种虚拟方法进行比较,在f1评分和AUC方面均取得了较好的效果。准确度方面,AOD在YOB时仅输于A1,在NAB时仅输于realAWSCloudwatch,其中dummy Negative策略取得了更优的结果。然而,在这些情况下,虚拟策略带来的f1分数等于0%。训练的平均时间一般小于76 ms,评估的平均时间一般小于27 ms。在导数域中使用信号的统计特征通常比使用原始信号的策略更好。这样的选择导致f1分数的整体提高超过10%。YOB的AUC为89.3%,NAB为70.3%,AGOTS生成的合成数据集的AUC为92.4%,案例研究的AUC为91.2%。这些高AUC值显示了所提出方法的潜力。
由于它是一种灵活的方法,AOD可以复制到与工业机器故障检测的预测性维护相关的不同工业应用中。该方法被用于监控大型豆油生产行业的一组机器。
致谢
本工作的作者感谢SENAI嵌入式系统创新研究所对其研究发展的支持。
利益冲突
作者声明他们没有利益冲突。
参考文献


[1]DA SILVA ARANTES J, DA SILVA ARANTES M, FRÖHLICH H B, 等. A novel unsupervised method for anomaly detection in time series based on statistical features for industrial predictive maintenance[J/OL]. International Journal of Data Science and Analytics, 2021, 12(4): 383-404. http://dx.doi.org/10.1007/s41060-021-00283-z. DOI:10.1007/s41060-021-00283-z.