CycleGAN论文的阅读与翻译,无监督风格迁移

CycleGAN junyanz,作者自己用 lua 在 GitHub 上的实现

CycleGAN tensorflow PyTorch by LynnHo,一个简单的 TensorFlow 实现
0. 摘要:
图像到图像的翻译 (Image-to-Image translation) 是一种视觉上和图像上的问题,它的目标是使用成对的图像作为训练集,(让机器)学习从输入图像到输出图像的映射。然而,在很多任务中,成对的训练数据无法得到。
我们提出一种在缺少成对数据的情况下,(让机器)学习从源数据域 X 到目标数据域 Y 的方法。我们的目标是使用一个对抗损失函数,学习映射 G:X → Y ,使得判别器难以区分图片 G(X) 与 图片 Y。因为这样子的映射受到巨大的限制,所以我们为映射 G 添加了一个相反的映射 F:Y → X,使他们成对,同时加入一个循环一致性损失函数 (cycle consistency loss),以确保 F(G(X)) ≈ X(反之亦然)。
在缺少成对训练数据的情况下,我们比较了风格迁移、物体变形、季节转换、照片增强等任务下的定性结果。经过定性比较,我们的方法表现得比先前的方法更好。
1. 介绍
在 1873 年某个明媚的春日,当莫奈 (Claude Monet) 在 Argenteuil 的塞纳河畔 (the bank of Seine) 放置他的画架时,他究竟看到了什么?如果彩色照片在当时就被发明了,那么这个场景就可以被记录下来——碧蓝的天空倒映在波光粼粼的河面上。莫奈通过他细致的笔触与明亮的色板,将这一场景传达出来。
如果莫奈画画的事情发生在 Cassis 小港口的一个凉爽的夏夜,那么会发生什么?
漫步在挂满莫奈画作的画廊里,我们可以想象他会如何在画作上呈现出这样的场景:也许是淡雅的夜色,加上惊艳的几笔,还有变化平缓的光影范围。
我们可以想象所有的这些东西,尽管从未见过莫奈画作与对应场景的真实照片一对一地放在一起。与此不同的是:我们已经见过许多风景照和莫奈的照片。我们可以推断出这两类图片风格的差异,然后想象出 “翻译” 后的图像。

在这篇文章中,我们提出了一个学习做相同事情的方法:在没有成对图像的情况下,刻画一个图像数据集的特征,并弄清楚如何将这些特征转化为另外一个图像数据集的特征。
这个问题可以被描述成概念更加广泛的图像到图像的翻译 (Image-to-Image translation),从给定的场景 x 完成一张图像到另一个场景 y 的转换。举例:从灰度图片到彩色图片、从图像到语义标签 (semantic labels) 、从轮廓到图片。发展了多年的计算机视觉、图像处理、计算图像图形学 (computational photography, and graphics ?) 学界提出了有力的监督学习翻译系统,它需要成对的数据 { x i , y i } i = 1 N \{x_{i}, y_{i}\}_{i=1}^{N} { xi,yi}i=1N(就像那个 pix2pix 模型一样)。

然而,获取成对的数据比较困难,也耗费资金。例如:只有几个成对的语义分割数据集,并且它们很小。特别是为艺术风格迁移之类的图像任务获取成对的数据就更难了,进行复杂的输出已经很难了,更何况是进行艺术创作。对于许多任务而言,就像物体变形(例如 斑马 ⇔ \Leftrightarrow ⇔\Leftrightarrow 马),这一类任务的输出更加不容易定义。

因此我们寻找一种算法可以学习如何在没有成对数据的情况下,在两个场景之间进行转换。我们假设在两个数据域直接存在某种联系——例如:每中场景中的每幅图片在另一个场景中都有它对应的图像,(我们让机器)去学习这个转换关系。尽管缺乏成对的监督学习样本,我们仍然可以在集合层面使用监督学习:我们在数据域 X 中给出一组图像,在数据域 Y 中给出另外一组图像。我们可以训练一种映射 G : X → Y 使得 输出 y ^ = G ( x ) , x ∈ X \hat{y} = G(x), x\in X y^=G(x),x∈X ,判别器的功能是将生成样本 y ^ \hat{y} y^\hat{y} 和真实样本 y y y 区分开,我们的实验正是要让 y y y 和 y ^ = G ( x ) \hat{y} = G(x) y^=G(x) 无法被判别器区分开。理论上,这一项将包括符合 p d a t a ( y ) p_{data}(y) pdata(y) 经验分布的 y ^ \hat{y} y^ 的输出分布(通常这要求映射 G 是随机的)。
从而存在一个最佳的映射 G G GG 将数据域 X X XX 翻译为数据域 Y ^ \hat{Y} Y^ , 使得 数据域 Y ^ ∼ Y \hat{Y} \sim Y Y^∼Y(有相同的分布)。然而,这样的翻译不能保证独立分布的输入 x x x 和输出 y y y 是有意义的一对——因为有无限多种映射 G G G 可以由输入的 x x x 导出相同的 y y y。此外,在实际中我们发现很难单独地优化判别器:当输出图图片从输入映射到输出的时候,标准的程序经常因为一些众所周知的问题而导致奔溃,使得优化无法继续。
为了解决这些问题,我们需要往我们的模型中添加其他结构。因此我们利用 翻译应该具有 “循环稳定性”(translation should be “cycle consistent”) 的这个性质,某种意义上,我们将一个句子从英语翻译到法语,再从法语翻译回英语,那么我们将会得到一相同的句子。从数学上讲,如果我们有一个翻译器 G : X → Y 与另一个翻译器 F : Y → X ,那么 G 与 F 彼此是相反的,这一对映射是双射 (bijections) 。
于是我们将这个结构应用到 映射 G 和 F 的同步训练中,并且加入一个 循环稳定损失函数 (cycle consistency loss) 以确保到达 F ( G ( X ) ) ≈ x F(G(X)) \approx x F(G(X))≈x与 G ( F ( y ) ) ≈ y G(F(y)) \approx y G(F(y))≈y 。将这个损失函数与判别器在数据域 X 与数据域 Y 的对抗损失函数结合起来,就可以得到非成对图像到图像的目标转换。
我们将这个方法应用广泛的领域上,包括风格迁移、物体变形、季节转换、照片增强。与以前的方法比较,以前的方法依既赖过多的人工定义与调节,又依赖于共享的内部参数,在比较中也表明我们的方法要优于这些(合格?)基准线 (out method outperforms these baselines)。我们提供了这个模型在 PyTorch 和 Torch 上的实现代码,点击这个网址进行访问。
2. 相关工作
对抗生成网络 Generative Adversarial Networks (GANs) 在图像生成、图像编辑、表征学习 (representation learning) 等领域以及取得了令人瞩目的成就。在最近,条件图像的生成的方法也采用了相同的思路,例如 从文本到图像 (text2image)、图像修复 (image inpainting)、视频预测 (future prediction),与其他领域(视频和三维数据)。
对抗生成网络成功的关键是:通过对抗损失(adversarial loss)促使生成器生成的图像在原则上无法与真实图像区分开来。图像生成正是许多计算机图像生成任务的优化目标,这种损失对在这类任务上特别有用。我们采用对抗损失来学习映射,使得翻译得到的图片难以与目标域的图像区分开。
Image-to-Image Translation 图像到图像的翻译
这个想法可以追溯到 Hertzmann 的 图像类比 (Image Analogies),这个模型在一对输入输出的训练图像上采用了无参数的纹理模型。最近 (2017) 的更多方法使用 输入 - 输出样例数据集训练卷积神经网络。我们的研究建立在 Isola 的 pix2pix 框架上,这个框架使用了条件对抗生成网络去学习从输入到输出的映射。相似的想法也已经应用在多个不同的任务上,例如:从轮廓、图像属性、布局语义 (semantic layouts) 生成图片。然而,与就如先前的工作不同,我们可以从不成对的训练图片中,学习到这种映射。
Unpaired Image-to-Image Translation 不成对的图像到图像的翻译
其他的几个不同的旨在关联两个数据域 X 和 Y 的方法,也解决了不成对数据的问题。
最近,Rosales 提出了一个贝叶斯框架,通过对原图像以及从多风格图像中得到的似然项 (likelihood term) 进行计算,得到一个基于区块 (patch-based)、基于先验信息的马尔可夫随机场;更近一点的研究,有 CoGAN 和 跨模态场景网络 (corss-modal scene networks) 使用了权重共享策略 去学习跨领域 (across domains) 的共同表示;同时期的研究,有 刘洺堉 用变分自编码器与对抗生成网络结合起来,拓展了原先的网络框架。同时期另一个方向的研究,有 尝试 (encourages) 共享有特定 “内容 (content) ” 的特征,即便输入和输出的信息有不同的“风格 (style) ”。这些方法也使用了对抗网络,并添加了一些项目,促使输出的内容在预先定义的度量空间内,更加接近于输入,就像 标签分类空间 (class label space) ,图片像素空间 (image pixel space), 以及图片特征空间 (image feature space) 。
不同于其他方法,我们的设计不依赖于 特定任务 以及 预定义输入输出似然函数,我们也不需要要求输入和输出数据处于一个相同的低纬度嵌入空间 (low-dimensional embedding space) 。因此我们的模型是适用于各种图像任务的通用解决方案。我们直接把本文的方案与先前的、现在的几种方案在第五节进行对比。
Cycle Consitency 循环一致性
把 可传递性 (transitivity) 作为结构数据正则化的手段由来已久。近十年来,在视觉追踪 (visual tracking) 任务里,确保 简单的前后向传播一致 (simple forward-backward consistency) 已经成为一个标准。在语言处理领域,通过 “反向翻译与核对(back translation and reconcilation) ” 验证并提高人工翻译的质量,机器翻译也是如此。更近一些的研究,使用到使用高阶循环一致性的有:动作检测、三维目标匹配,协同分割(co-segmentation) ,稠密语义分割校准(desnse semantic alignment),景物深度估计(depth estimation) 。
下面两篇文章的与我的工作比较相似,他们也使用了循环一致性损失体现传递性,从而监督卷积网络的训练:
基于左右眼一致性的单眼景物深度估计 (Unsupervised monocular depth estimation with left-right consistency) —— Godard
通过三维引导的循环一致性学习稠密的对应关系 (Learning dense correspondence via 3d-guided cycle consistency) —— T. Zhou.
我们引入了相似的损失使得 两个生成器 G 与 F 保持彼此一致。同时期的研究,Z. Yi. 受到机器翻译对偶学习的启发,独立地使用了一个与我们类型的结构,用于不成对的图像到图像的翻译——Dualgan: Unsupervised dual learning for image-to-image translation.
神经网络风格迁移 Neural Style Transfer
神经网络风格迁移是优化 图像到图像翻译 的另外一种方法,通过比较不同风格的两种图像(一张是普通图片,另一张是另外一种风格的图片 (一般来讲是绘画作品))并将一幅图像的内容和另一幅的风格组合起来,基于预训练期间对伽马矩阵进行统计从而得到深层次的特征,再对这些特征进行匹配,最终创造新的图像。
另一方面,我们主要关注的是:通过刻画更高层级外观结构之间的对应关系,学习两个图像集之间的映射,而不仅是两张特定图片之间的映射。因此,我们的方法可以应用在其他任务上,例如从 绘画 → 图片,物体变形 (object transfiguration),等那些单样品转换方法表现不好的地方。我们在 5.2 节 比较了这两种方法。
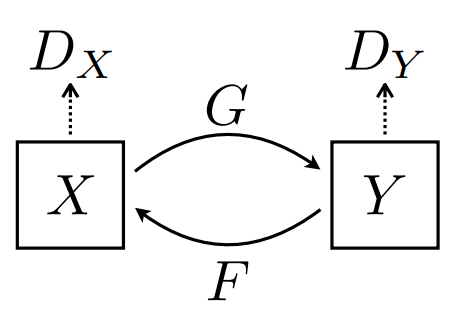
3. 公式推导
我们的目标是学习两个数据域 X 与 Y 之间的映射函数,定义数据集合与数据分布,与模型的两个映射,其中: { x i } i = 1 N x i ∈ X , x ∼ p d a t a ( x ) { y i } i = 1 M y i ∈ Y , y ∼ p d a t a ( y ) G : X → Y F : Y → X \{ x_{i} \} ^N _{i=1} \quad x_i \in X ,\quad x\sim p_{data}(x)\\ \{ y_{i} \} ^M _{i=1} \quad y_i \in Y ,\quad y\sim p_{data}(y) \\ \ \\ G: X \rightarrow Y \\ F: Y \rightarrow X { xi}i=1Nxi∈X,x∼pdata(x){ yi}i=1Myi∈Y,y∼pdata(y) G:X→YF:Y→X
另外,我们引入了两个判别函数:
- 用于区分 {x} 与 {F(y)} 的 D X D_X DXD_X
- 用于区分 {y} 与 {G(x)} 的 D Y D_Y DYD_Y 。
我们的构建的模型包含两类组件 (Our objective contains two types of terms):
- 对抗损失 (adversarial losses),使生成的图片在分布上更接近于目标图片;
- 循环一致性损失 (cycle consistency losses),防止学习到的映射 G 与 F 相互矛盾。
3.1 对抗损失 (adversarial losses)
我们为两个映射函数都设置了对抗损失。对于映射函数 G 和它的判别器 D Y D_Y DYD_Y ,我们有如下的表达式:
L G A N ( G , D Y , X , Y ) = E y ∼ p data ( y ) [ log ( D Y ( Y ) ) ] + E x ∼ p data ( x ) [ log ( 1 − D Y ( G ( x ) ) ) ] \begin{aligned} \mathcal{L}_{G A N}\left(G, D_Y, X, Y\right) & =\mathbb{E}_{y \sim p_{\text {data }}(y)}\left[\log \left(D_Y(Y)\right)\right] \\ & +\mathbb{E}_{x \sim p_{\text {data }}(x)}\left[\log \left(1-D_Y(G(x))\right)\right]\end{aligned} LGAN(G,DY,X,Y)=Ey∼pdata (y)[log(DY(Y))]+Ex∼pdata (x)[log(1−DY(G(x)))]
当映射 G 试图生成与数据域 Y 相似的图片 G(x) 的时候,判别器也在试着将生成的图片从原图中区分出来。映射 G 希望通过优化减小的项目与 映射 F 希望优化增大的项目 相对抗,另一个映射 F 也是如此。这两个相互对称的结构用公式表达就是: m i n G m a x D Y L G A N ( G , D Y , X , Y ) m i n F m a x D X L G A N ( F , D X , Y , X ) min_G \ max_{D_Y} \ \mathcal{L}_{GAN} (G,D_Y,X,Y) \\ min_F \ max_{D_X} \ \mathcal{L}_{GAN} (F,D_X,Y, X) minG maxDY LGAN(G,DY,X,Y)minF maxDX LGAN(F,DX,Y,X)

3.2 循环一致性损失 (cycle consistency loss)
理论上对抗训练可以学习到 映射 G 与 F,并生成与目标域 Y 与 X 相似的分布的输出(严格地讲,这要求映射 G 与 F 应该是一个随机函数。然而,当一个网络拥有足够大的容量,那么输入任何随机排列的图片,它都可以映射到与目标图片相匹配的输出分布。因此,不能保证单独依靠对抗损失而学习到的映射可以将每个单独输入的 x i x_i xix_i 映射到期望得到的 y i y_i yiy_i 。
为了进一步减少函数映射可能的得到的空间大小,我们认为学习的的得到的函数应该具有循环一致性 (cycle-consistent): 如图 3(b) 所示,数据域 X 中的每一张图片 x 在循环翻译中,应该可以让 x 回到翻译的原点,反之亦然,即 前向、后向循环一致,换言之: x → G ( x ) → F ( G ( x ) ) ≈ x y → F ( y ) → G ( F ( y ) ) ≈ y x \rightarrow G(x) \rightarrow F(G(x)) \approx x \\ y \rightarrow F(y) \rightarrow G(F(y)) \approx y x→G(x)→F(G(x))≈xy→F(y)→G(F(y))≈y
我们使用循环一致性损失作为激励,于是有:
L c y c ( G , F ) = E x ∼ p data ( x ) [ ∥ F ( G ( x ) ) − x ∥ 1 ] + E y ∼ p date ( y ) [ ∥ G ( F ( y ) ) − y ∥ 1 ] \begin{aligned} \mathcal{L}_{c y c}(G, F) & =\mathbb{E}_{x \sim p_{\text {data }}(x)}\left[\|F(G(x))-x\|_1\right] \\ & +\mathbb{E}_{y \sim p_{\text {date }}(y)}\left[\|G(F(y))-y\|_1\right]\end{aligned} Lcyc(G,F)=Ex∼pdata (x)[∥F(G(x))−x∥1]+Ey∼pdate (y)[∥G(F(y))−y∥1]
初步实验中,我们也尝试用 F(G(x)) 与 x 之间、G(F(Y)) 与 y 之间的对抗损失替代上面的 L1 范数,但是没有观察到更好的性能。
如图 4 所示,加入循环一致性损失最终使得模型重构的图像 F(G(x)) 与输入的图像 x 十分匹配。

3.3 完整的模型对象 (Full Objective)
我们完整的模型对象如下,其中,λ 控制两个对象的相对重要性。
L ( G , F , D X , D Y ) = L G A N ( G , D Y , X , Y ) + L G A N ( F , D X , Y , X ) + λ L c y c ( G , F ) \begin{aligned} \mathcal{L}\left(G, F, D_X, D_Y\right) & =\mathcal{L}_{G A N}\left(G, D_Y, X, Y\right) \\ & +\mathcal{L}_{G A N}\left(F, D_X, Y, X\right) \\ & +\lambda \mathcal{L}_{c y c}(G, F)\end{aligned} L(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
我们希望解决映射的学习问题:
G ∗ , F ∗ = arg min G , F max D X , D Y L ( G , F , D X , D Y ) G^*, \ F^* = \arg \min_{G, F} \max_{D_X, D_Y} \ \mathcal{L}(G, F, D_X, D_Y) G∗, F∗=argminG,FmaxDX,DY L(G,F,DX,DY)
请注意,我们的模型可以视为训练了两个自动编码器 (auto-encoder):
F ∘ G : X → X G ∘ F : Y → Y F \circ G: X \rightarrow X \\ G \circ F: Y \rightarrow Y F∘G:X→XG∘F:Y→Y
然而,每一个自动编码器都有它特殊的内部结构:它们通过中间介质将图片映射到自身,并且这个中间介质属于另一个数据域。这样的一种配置可以视为是使用了对抗损失训练瓶颈层 (bottle-neck layer) 去匹配任意目标分布的 “对抗性自动编码器”(advesarial auto-encoders)。在我们的例子中,目标分布是中间介质 Yi 分布于数据域 Y 的自动编码器 X i → Y i → X i X_i \rightarrow Y_i \rightarrow X_i Xi→Yi→Xi
在 5.1.4 节,我们将我们的方法与消去了 完整对象的模型 (ablations of the full objective) 进行比较,包括只包含对抗损失 L G A N \mathcal{L}_{GAN} LGAN 、只包含循环一致性损失 L c y c \mathcal{L}_{cyc} Lcyc,根据我们的经验,在模型中加入这两个对象,对获得高质量的结果而言十分重要。我们也对单向的循环损失模型进行评估,它的结果表明:单向的循环对这个问题的约束不够充分,因而不足以使训练获得足够的正则化。(a single cycle is not sufficient to regularize teh training for this under-constrained problem)
4. 实现 (Implementation)
网络结构
我们采用了 J. Johnson 文章中的生成网络架构。这个网络包含两个步长为 2 的卷积层,几个残差模块,两个步长为 1/2 的转置卷积层 (transposed concolution; 原文是 fractionally-strided convolutions)。我们使用了 6 个模块去处理 128x128 的图片,以及 9 个模块去处理 256x256 的高分辨率训练图片。与 Johnson 的方法类似,我们对每个实例使用了正则化 (instance normalization)。我们使用了 70x70 的 PatchGANs 作为我的判别器网络,这个网络用来判断图片覆盖的 70x70 补丁是否来自于原图。比起全图的鉴别器,这样的补丁层级的鉴别器有更少的参数,并且可以以完全卷积的方式处理任意尺寸的图像。
J. Johnson 文章:指的是李飞飞他们的那篇文章:感知损失在 实时风格迁移 与 超分辨率 上的应用 (Perceptual losses for real-time style transfer and super-resolution)
分数步长卷积 (fractionally-strided convolution):也就是 转置卷积层 Transposed Convolution,也有人叫 反卷积、逆卷积 (deconvolution),不过这个过程不是卷积的逆过程,所以我建议用 转置卷积层称呼它。
PatchGANs:使用条件 GAN 实现图片到图片的翻译 Image-to-Image Translation with Conditional Adversarial Networks ——本文作者是这篇文章的第二作者
训练细节
我们把学界近期的两个技术拿来用做我们的模型里,用于稳定模型的训练。
第一,对于 L G A N \mathcal{L}_{GAN} LGAN\mathcal{L}_{GAN} ,我们使用最小二乘损失 (least squares loss) 取代 原来的负对数似然损失 (就是 LeCun 的那个)。在训练时,这个损失函数有更好的稳定性,并且可以生成更高质量的结果。实际上,对于 GAN 的损失函数,我们为两个映射 G(X) 与 D(X) 各自训练了一个损失函数。
L G A N ( G , D , X , Y ) G . m i n i m i z e ( E x ∼ p d a t a ( x ) [ ∣ ∣ G ( F ( y ) ) − y ∣ ∣ 1 ] ) D . m i n i m i z e ( E y ∼ p d a t a ( y ) [ ∣ ∣ F ( G ( x ) ) − x ∣ ∣ 1 ] ) \mathcal{L}_{GAN}(G,D,X,Y) \\ G.minimize \big( \mathbb{E}_{x \sim p_{data}(x)}[ || G(F(y)) - y ||_1] \big) \\ D.minimize \big( \mathbb{E}_{y \sim p_{data}(y)}[ || F(G(x)) - x ||_1] \big) LGAN(G,D,X,Y)G.minimize(Ex∼pdata(x)[∣∣G(F(y))−y∣∣1])D.minimize(Ey∼pdata(y)[∣∣F(G(x))−x∣∣1])
第二,为了减小模型训练时候的震荡 (oscillation),我们遵循 Shrivastava 的策略——在更新判别器的时候,使用生成的图片历史,而不是生成器最新一次生成的图片。我们把最近 50 次生成的图片保存为缓存。
在每一次实验中,在计算损失函数的时候,我们都把下面公式内的 λ \lambda λ\lambda 设置为 10,我们使用 Adam 进行批次大小为 1 的更新。所有的网络都是把学习率设置为 0.0002 后,从头开始训练的。在前 100 次训练中,我们保持相同的学习率,并且在 100 次训练后,我们保持学习率向 0 的方向线性减少。第七节(附录 7)记录了关于数据集、模型结构、训练程序的更多细节
L G A N ( G , F , D X , D Y ) = L G A N ( G , D Y , X , Y ) + L G A N ( F , D X , Y , X ) + L G A N ( G , F ) ⋅ λ \begin{aligned} \mathcal{L}_{G A N}\left(G, F, D_X, D_Y\right) & =\mathcal{L}_{G A N}\left(G, D_Y, X, Y\right) \\ & +\mathcal{L}_{G A N}\left(F, D_X, Y, X\right) \\ & +\mathcal{L}_{G A N}(G, F) \cdot \lambda\end{aligned} LGAN(G,F,DX,DY)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+LGAN(G,F)⋅λ
最小二乘损失:来自于——LSGANs, Least squares generative adversarial networks
5. 结果
首先,我们将我们的方法与最近的 训练图片不成对的图片翻译 方法对比,并且使用的是成对的数据集,评估的时候使用的是 标记正确的成对图片。然后我们将我们的方案与方案的几种变体一同比较,研究了 对抗损失 与 循环一致性损失 的重要性。最后,在只有不成对图片存在的情况下,我们在更大的范围内,展示了我们算法的泛化性能。
为了简洁起见,我们把这个模型称为 CycleGAN。在我们的网站上,你可以找到所有的研究成果,包括 PyTorch 和 Torch 的实现代码。
5.1 评估
我们使用与 pix2pix 相同的评估数据集,与现行的几个基线 (baseline) 进行了定量与定性的比较。这些任务包括了 在城市景观数据集 (Cityscapes dataset) 上的 语义标签↔照片,在谷歌地图上获取的 地图↔卫星图片。我们在整个损失函数上进行了模型简化测试 (ablation study 模型消融研究 )。

5.1.1 评估指标 (Evalution Metrics)
AMT 感知研究 (AMT perceptual studies) 在 地图↔卫星图片的任务中,我们在亚马逊 真 · 人工 智能平台 (Amazon Mechanical Turk) 上,建立了 “图片真伪判别” 的任务,来评估我们的输出的图片的真实性。我们遵循 Isola 等人相同的感知研究方法,不同的是:我每个算法收集了 25 个实验参与者 (participant) 的结果 。会有一系列成对的真伪图片 展示给实验参与者观看,参与者需要点击选择他认为是真实图片的那一张,(另外一张伪造的图片是由我们的算法生成的,或者是其他基线算法(baselines) 生成的)。每一轮的前 10 个试验用来练习,并将他们答案的正误 反馈给试验参与者。每一轮只会测试一种算法,每一个试验参与者只允许参与测试一轮。

请注意,我们报告中的数字,不能直接与其他文章中报告的数字进行比较,因为我们的正确标定图片与他们有轻微的不同,并且实验的参与人员也有可能不同(由于实验室在不同的时间进行的)。因此,我们报告中的数字,用来在这篇文章内部进行比较。
FCN score (全卷积网络得分 full-convolutional network score) 虽然感知研究可能是评估图像真实性的黄金准则,但是我们也在寻求不需要人类经验的 自动质量检测方法。为此,我们采用 Isola 的 “FCN score” 来进行 城市景观标签↔照片 转换任务的评估。全卷积网络的根据现成的语义分割模型 来测量评估图片的可解释性。全卷积从一幅图片 预测出整张图片的语义标签地图,然后使用标准的语义分割模型,各自生成图片与输入图片 的标签地图,然后使用它们用来描述的标准语义进行比较。直觉上,我们从标签地图得到 “路上的车” 的生成图片,然后把生成的图片输入全卷积网络,如果可以从全卷积网络上也得到 “路上的车” 的标签地图,那么就是我们恢复成功了。

语义分割指标 (Semantic segmentation metrics) 为了评估 图片→标签 的性能,我们使用了城市景观的标准指标 (standard metrics from the CItyscapes benchmark),包括了每一个像素的准确率,每个等级的准确率,类别交并比 (Class IoU, class Intersection-Over-Union) 平均值。
AMT:亚马逊的 真 · 人工 智能平台 (Amazon Mechanical Turk),这个平台就是 Amazon 在网站上发布任务,由系统分发任务给人类领取,然后按照自己内部的算法支付酬劳,是真的 人工的 智能平台。其实应该叫 人力手动 智能平台。 AMT perceptual studies AMT 感知研究,指的就是把自己的结果让人力手动地 去评估。
Isola 等人的研究:用条件对抗网络进行图像到图像的翻译 Imageto-image translation with conditional adversarial networks. In CVPR, 2017. 包括了用 FCN score 对图片进行评估。
5.1.2 基线模型 (baselines)
CoGAN(Coupled GAN) 这个模型训练一个对抗生成网络,两个生成网络分别生成数据域 X 与 数据域 Y,前几层都进行权重绑定,并共享对数据潜在的表达。从 X 到 Y 的翻译可以通过寻找相同的潜在表达 来生成图片 X,然后把这个潜在的表达翻译成风格 Y 。
SimGAN 与我们的方法类似,用对抗损失训练了一个从 X 到 Y 的翻译,正则项 ∣ ∣ x − G ( x ) ∣ ∣ 1 ||x-G(x)||_1 ∣∣x−G(x)∣∣1用来惩罚图片在像素层级上过大的改动。
Feature loss + GAN 我们还测试了 SimGAN 的变体——使用的预训练网络 (VGG-16, relu4_2) 在图像深度特征 (deep image features) 上计算 L1 损失,而不是在 RGB 值上计算。像这样在深度特征空间上计算距离,有时候也被称为是使用 “感知损失 (perceptual loss )”。
BiGAN/ ALI 无条件约束 GAN 训练了生成器 G: Z→X ,将一个随机噪声映射为图片 x 。BiGAN 和 ALI 也建议学习逆向的映射 F: X→Z 。虽然它们一开始的设计是 学习将潜在的向量 z 映射为图片 x ,我们实现了相同的组件,将原始图片 x 映射到 目标图片 y 。
pix2pix 我们也比较了在成对数据上训练的 pix2pix 模型,想看看在不使用成对训练数据的情况下,我们能够如何接近这个天花板。
为了公平起见,我们使用了与我们的方法 相同的架构和细节实现了这些基线模型,除了 CoGAN,CoGAN 建立在共享 潜在表达 而输出图片的生成器上。因此我们使用了 CoGAN 实现的公共版本。
BiGAN V. Dumoulin. Adversarially learned inference. In ICLR, 2017.
ALI ?? J. Donahue. Adversarial feature learning. In ICLR, 2017
pix2pix P.Isola Imageto-image translation with conditional adversarial networks. In CVPR, 2017.

5.1.3 与基线模型相比较
5.1.4 对损失函数的分析
5.1.5 图片重构质量
5.1.6 成对数据集的其他结果
5.2 应用 (Applications)
我们演示了 成对的训练数据不存在时 cycleGAN 的几种应用方法。可以看第七节 附录,以获取更多关于数据集的细节。我们观察到训练集上的翻译 比测试上的更有吸引力,应用的所有训练与测试的数据都可以在我们项目的网站上看到。
风格迁移 (Collection style transfer) 我们用 Flickr 和 WikiArt 上下载的风景图片,训练了一个模型。注意,与最近的 “神经网络风格迁移 (neural style transfer)” 不同,我们的方法学习的是 对整个艺术作品数据集的仿造。因此,我们可以学习 以梵高的风格生成图片,而不仅是学习 星夜 (Starry Night) 这一幅画的风格。我们对 塞尚 (Cezanne),莫奈 (Monet),梵高 (Van Gogh) 以及日本浮世绘 这每个艺术风格 都构建了一个数据集,他们的数量大小分别是 526,1073,400,563 张。
物件变形 (Object transfiguration) 训练这个模型用来将 ImageNet 上的一个类别的物件 转化为另外一个类型的物物件(每个类型包含了约 1000 张的训练图片)。Turmukhambetov 提出了一个子空间的模型将一类物件转变为同一类别的另外一个物件。而我们的方法侧重于两个(来自于不同类别)而视觉上相似的的物件之间的变形。
季节转换 (Season transfer) 这个模型在 从 Flickr 上下载的 Yosemite 风景照上训练,其中包括 854 张冬季(冰雪) 和 1273 张 夏季的图片。
从画作中生成照片 (Photo generation from paintings) 为了建立映射 画作→照片,我们发现:添加一个鼓励颜色成分保留的损失 对映射的学习有帮助。特别是采用了 Taigman 的技术后,当提供目标域的真实样本 作为生成器的输入时,对生成器进行正则化以接近恒等映射 (identity mapping)
L G A N ( G , F ) = E y ∼ p dota [ ∥ G ( y ) − y ∥ 1 ] + E x ∼ p data [ ∥ F ( x ) − x ∥ 1 ] \begin{aligned} \mathcal{L}_{G A N}(G, F) & =\mathbb{E}_{y \sim p_{\text {dota }}}\left[\|G(y)-y\|_1\right] \\ & +\mathbb{E}_{x \sim p_{\text {data }}}\left[\|F(x)-x\|_1\right]\end{aligned} LGAN(G,F)=Ey∼pdota [∥G(y)−y∥1]+Ex∼pdata [∥F(x)−x∥1]
在不使用 L i d e n t i t y \mathcal{L}_{identity} Lidentity 时,生成器 G 与 F 可以自由地改变输入图像的色调,而这是不必要的。例如,当学习莫奈的画作和 Flicker 的照片时,生成器经常将白天的画作映射到 黄昏时拍的照片,因为这样的映射可能在 对抗损失和循环一致性损失 的启用下同样有效。这种恒等映射在图 9 中可以看到。

神经网络风格迁移 neural style transfer L. A. Gatys. Image style transfer using convolutional neural networks. CVPR, 2016
使用 条件纹理成分分析 为物体的外观建模 D. Turmukhambetov. Modeling object appearance using context-conditioned component analysis. In CVPR, 2015.
图 12 中,展示的是将莫奈的画作翻译成照片,图 12 与 图 9 显示的是 包含了训练集的结果,而本文中的其他实验,我们仅显示测试集的结果。因为训练集不包含成对的图片,所以为测试集提供合理的翻译结果是一项非凡的任务(也许可以复活莫奈让他对着相同的景色画一张?——括号内的话是我自己加的)确实,自从莫奈再也不能创作新的绘画作品后,泛化无法看到原画作的测试集并不是一个迫切的问题。(Indeed, since Monet is no longer able to create new paintings, generalization to unseen, “test set”, paintings is not a pressing problem 感谢
@LIEBE
在评论区给出的翻译)
图片增强 (Photo enhancement) 图 14 中,我们的方法可以用在生成景深较浅的照片上。我们从 Flickr 下载花朵的照片,用来训练模型。数据源由智能手机拍摄的花朵图片组成,因为光圈小,所以通常具有较浅的景深。目标域包含了由 拥有更大光圈的单反相机拍摄的图片。我们的模型 用智能手机拍摄的浅光圈图片,成功地生成有大光圈拍摄效果的图片。

与神经风格迁移相比 (Comparison with Neural style transfer) 我们与神经风格迁移在照片风格化任务上相比,我们的图片可以产生出 具备整个数据集风格 的图片。为了在整个风格数据集上,把我们的方法与神经风格迁移相比较,我们在目标域上。计算了平均 Gram 矩阵,并且使用这个矩阵转移 神经风格迁移的 “平均风格”。
图 16 演示了在其他转移任务上 相似的比较,我们发现 神经风格迁移需要寻找一个尽可能与所需输出 相贴近的目标风格图像,但是依然无法产生足够真实的照片,而我们的方法成功地生成与目标域相似,并且比较自然的结果。


6. 局限与讨论
虽然我们的方法在多种案例下,取得了令人信服的结果,但是这些结果并不都是一直那么好。图 17 就展示了几个典型的失败案例。在包括了涉及颜色和纹理变形的任务上,与上面的许多报告提及的一样,我们的方法经常是成功的。我们还探索了需要几何变换的任务,但是收效甚微 (limit success)。举例说明:狗→猫 转换的任务,对翻译的学习 退化为对输入的图片进行最小限度的转换。这可能是由于我们对生成器结构的选择造成的,我们生成器的架构是为了在外观更改上的任务上拥有更好的性能而量身定制的。处理更多和更加极端的变化,尤其是几何变换,是未来工作的重点问题。
训练集的分布特征也会造成一些案例的失败。例如,我们的方法在转换 马→斑马 的时候发生了错乱,因为我们的模型只在 ImageNet 上训练了 野马和斑马 这两个类别,而没有包括人类骑马的图片。所以普京骑马的那一张,把普京变成斑马人了。


我们也发现在成对图片训练 和 非成对训练 之间存在无法消弭的差距。在一些案例里面,这个差距似乎特别难以消除,甚至不可能消除。为了消除(模型对数据理解上的)歧义,模型可能需要一些弱语义监督。集成的弱监督或者半监督数据也许能够造就更有力的翻译器,这些数据依然只会占完全监督系统中的一小部分。
尽管如此,在多种情况下,完全使用不成对的数据依然是足够可行的,我们应该使用。这篇论文拓展了 “无监督” 配置可能使用范围。
论文原文中的部分图表,我没有给出
致谢部分,我用的是谷歌翻译 2018-10-25 16:27:43
第七节的附录,我用的是谷歌翻译 2018-10-25 16:27:43
7. 附录 7.1。
训练细节所有网络(边缘除外)均从头开始训练,学习率为 0.0002。在实践中,我们将目标除以 2,同时优化 D,这减慢了 D 学习的速率,相对于 G 的速率。我们保持前 100 个时期的相同学习速率并将速率线性衰减到零。接下来的 100 个时代。权重从高斯分布初始化,均值为 0,标准差为 0.02。
Cityscapes 标签↔Photo2975 训练图像来自 Cityscapes 训练集 [4],图像大小为 128×128。我们使用 Cityscapes val 集进行测试。
Maps↔aerial 照片 1096 个训练图像是从谷歌地图 [22] 中删除的,图像大小为 256×256。图像来自纽约市内及周边地区。然后将数据分成火车并测试采样区域的中位数纬度(添加缓冲区以确保测试集中没有出现训练像素)。建筑立面标签照片来自 CMP Facade 数据库的 400 张训练图像[40]。边缘→鞋子来自 UT Zappos50K 数据集的大约 50,000 个训练图像[60]。该模型经过 5 个时期的训练。
Horse↔Zebra 和 Apple↔Orange 我们使用关键字 “野马”,“斑马”,“苹果” 和“脐橙”从 ImageNet [5]下载图像。图像缩放为 256×256 像素。每个班级的训练集大小为马:939,斑马:1177,苹果:996,橙色:1020.
Summer↔WinterYosemite 使用带有标签 yosemite 和 datetaken 字段的 Flickr API 下载图像。修剪了黑白照片。图像缩放为 256×256 像素。每个班级的培训规模为夏季:1273,冬季:854。照片艺术风格转移艺术图像从 http://Wikiart.org 下载。一些素描或过于淫秽的艺术品都是手工修剪过的。这些照片是使用标签横向和横向摄影的组合从 Flickr 下载的。黑白照片被修剪。图像缩放为 256×256 像素。每个班级的训练集大小为 Monet:1074,Cezanne:584,Van Gogh:401,Ukiyo-e:1433,照片:6853。Monet 数据集被特别修剪为仅包括风景画,而 Van Gogh 仅包括他的后期作品代表了他最知名的艺术风格。
Photo↔Art 风格转移艺术图像从 http://Wikiart.org 下载。一些素描或过于淫秽的艺术品都是手工修剪过的。这些照片是使用标签横向和横向摄影的组合从 Flickr 下载的。黑白照片被修剪。图像缩放为 256×256 像素。每个班级的训练集大小为 Monet:1074,Cezanne:584,Van Gogh:401,Ukiyo-e:1433,照片:6853。
Monet 数据集被特别修剪为仅包括风景画,而 Van Gogh 仅包括他的后期作品代表了他最知名的艺术风格。莫奈的画作→照片为了在保存记忆的同时实现高分辨率,我们使用矩形图像的随机方形作物进行训练。为了生成结果,我们将具有正确宽高比的宽度为 512 像素的图像作为输入传递给生成器网络。身份映射损失的权重为 0.5λ,其中λ是周期一致性损失的权重,我们设置λ= 10.
花卉照片增强智能手机拍摄的花卉图像是通过搜索 Apple iPhone 5 拍摄的照片从 Flickr 下载的,5s 或 6,搜索文本花。具有浅 DoF 的 DSLR 图像也通过搜索标签 flower,dof 从 Flickr 下载。将图像按比例缩放到 360 像素宽。使用重量 0.5λ的同一性映射损失。智能手机和 DSLR 数据集的训练集大小分别为 1813 和 3326。
7.2。网络架构
我们提供 PyTorch 和 Torch 实现。
发电机架构 我们采用 Johnson 等人的架构。[23]。我们使用 6 个块用于 128×128 个训练图像,9 个块用于 256×256 或更高分辨率的训练图像。下面,我们遵循 Johnson 等人的 Github 存储库中使用的命名约定。
令 c7s1-k 表示具有 k 个滤波器和步幅 1 的 7×7Convolution-InstanceNormReLU 层. dk 表示具有 k 个滤波器和步幅 2 的 3×3 卷积 - 实例范数 - ReLU 层。反射填充用于减少伪像。Rk 表示包含两个 3×3 卷积层的残余块,在两个层上具有相同数量的滤波器。uk 表示具有 k 个滤波器和步幅 1 2 的 3×3 分数跨度 - ConvolutionInstanceNorm-ReLU 层。
具有 6 个块的网络包括:c7s1-32,d64,d128,R128,R128,R128,R128,R128,R128,u64,u32,c7s1-3
具有 9 个块的网络包括:c7s1-32,d64,d128,R128,R128,R128,R128,R128,R128,R128,R128,R128,u64 u32,c7s1-3
鉴别器架构 对于鉴别器网络,我们使用 70×70 PatchGAN [22]。设 Ck 表示具有 k 个滤波器和步幅 2 的 4×4 卷积 - 实例范数 - LeakyReLU 层。在最后一层之后,我们应用卷积来产生 1 维输出。我们不将 InstanceNorm 用于第一个 C64 层。我们使用泄漏的 ReLU,斜率为 0.2。鉴别器架构是:C64-C128-C256-C512
QA
- 几个关于翻译的建议
- 如猫狗转换这种一对多的转换,有其他模型能学到吗?有,但是受应用场景限制
- CycleGAN 如何保证不发生交叉映射?在满足双射 (bijections) 的情况下,保持循环一致
这里有几个小小的(关于翻译的)建议,不知道我理解得正不正确:
采用并在正文改正:upper bound:天花板 ×,上限√。作者 写**光圈小,景深深(大)**是正确的,谢谢提醒,我自己弄错了。
1.translation 可以翻成转化?(“图像间的转化” 读起来更直白一点?)我坚持把 translation 直接翻译成「翻译」,理由如下:论文原文有 “a sentence from English to French, and then translate it back from French to English”, CycleGAN 的灵感是从「语言翻译」中来的,英语→法语→英语,图像域 A→图像域 B→图像域 A。而 Pix2Pix - Image-to-Image Translation with Conditional Adversarial Networks - 2018 的论文原文也有 “. Just as a concept may be expressed in either English or French, a scene may be rendered as an RGB image, … …”,因此我没有翻成转化。
- 第 5.1 节 的评估那里是还没翻译完吗?考不考虑手动翻译一遍 7. 附录呢?不打算翻译,我认为这部分内容不看不会影响我们对 CycleGAN 的理解。
cyclegan 的话,更强调循环一致,猫狗转换这种,对于一只猫转换为一只狗,一只狗转换为一只猫,存在很多 1 - 多的关系。因为不存在明显一一对应关系,那么目标就变成学习一个足够真实(和源分布尽可能相似)的分布。对于猫狗转换这种,别的 gan 可以学习学到嘛?
我的回答:有,但是受应用场景限制。例如:
小样本无监督图片翻译 Few-Shot Unsupervised Image-to-Image Translation - 英伟达 2019-05 论文 pdf (从视频上看,做的非常好,但是我还没有机会去复现它)
知乎相关介绍 英伟达最新图像转换器火了!万物皆可换脸,试玩开放 - 新智元


另一个,人类的转换,人脸到人脸转换,有 DeepFace 等开源工具可以实现。人脸到其他脸,有它可以实现→ ,论文 Landmark Assisted CycleGAN for Cartoon Face Generation - 香港中文 - 贾佳亚 。
知乎相关介绍: 用于卡通人脸生成的关键点辅助 CycleGAN

极端的例子,假定就是马和斑马的变换,马与斑马都分两种姿态,一类是站着,一类是趴着,那么对于系统设计的代价函数而言,我完全可以把所有站着的马都映射为趴着的斑马,趴着的马变成站着的斑马,然后逆向映射把趴着的斑马映射回站着的马。这个映射的代价函数和正常保持马的姿态的映射是一样的。那么系统是如何保证不发生这种交叉映射的呢
我的回答:在满足双射 (bijections) 的情况下,保持循环一致性。
文章第二节的 Cycle Consitency 循环一致性提到:加入循环一致性损失 (cycle consistency loss),可以保证了映射的正确,在语言处理领域也是如此。
文章第一节的介绍部分,提到:从数学上讲,如果我们有一个翻译器 G : X → Y 与另一个翻译器 F : Y → X ,那么 G 与 F 彼此是相反的,这一对映射是双射 (bijections) 。系统通过 Cycle Consitency 循环一致性,保证不发生趴着的野马,站着的斑马这种交叉映射,从数学上讲,原理是双射 (wikipedia: bijections),即参与映射的两个集合,里面的元素必然是一一对应的。
野马集合 斑马集合
- 站姿 1 的野马 ⇋ 站姿 1 的斑马
- 站姿 2 的野马 ⇋ 站姿 2 的斑马
- …
- 跪姿 1 的野马 ⇋ 跪姿 1 的斑马
- …
↑符合循环一致性的双射
假如在某一次随机重启后,cycleGAN 恰好学到了 站姿⇋跪姿 的转化,我们不期望的交叉映射发生了,有如下:
野马集合 斑马集合
- 站姿 1 的野马 ⇋ 跪姿 1 的斑马
- 站姿 2 的野马 ⇋ 跪姿 2 的斑马
- …
- 跪姿 1 的野马 ⇋ 站姿 1 的斑马
- …
其实经过分析,我们会发现无法证明 对于站姿 n,有稳定的跪姿 n 与其一一对应,所以这种交叉映射是不符合双射的。不符合双射的两个映射,不满足循环一致性。然而,由于野马斑马外形差别不大,导致站姿 n 的野马 到 站姿 n 斑马 总是存在稳定的一一对应的姿态可以相互转换,所以,可以预见到,在执行图片到图片的翻译任务时,当训练到收敛的时候,循环稳定性可以得到正确的结果,避免交叉映射。
根据文章中提到的:使用 cycleGAN 可以进行 野马 ⇋斑马 的转换,但是无法转化形态差异比较大的 猫 ⇋ 狗。 因为从 猫 ⇋ 狗 之间的转化,不能严格满足 双射 的要求,当存在许多差异明显的猫狗时,因为循环一致性并不能指导模型,导致过多的交叉映射破坏循环一致性,从而无法训练得到满意的模型。

所以,我的结论:
- 野马 ⇋ 斑马:满足双射,可以避免交叉映射,符合循环一致性,训练效果好
- 猫 ⇋ 狗:不能严格满足双射,无法完全避免交叉映射,破坏了循环一致性,训练效果不佳
cyclegan 的话,更强调循环一致,猫狗转换这种,对于一只猫转换为一只狗,一只狗转换为一只猫,存在很多 1 - 多的关系。因为不存在明显一一对应关系,那么目标就变成学习一个足够真实(和源分布尽可能相似)的分布。对于猫狗转换这种,别的 gan 可以学习学到嘛?
其他文章: