今天给大家解读一篇NeurlPS 2022中哈佛大学在时间序列无监督预训练的工作。这篇工作我认为非常有价值,为时间序列表示学习找到了一个很强的先验假设,是时间序列预测表示学习方向的一个突破性进展。
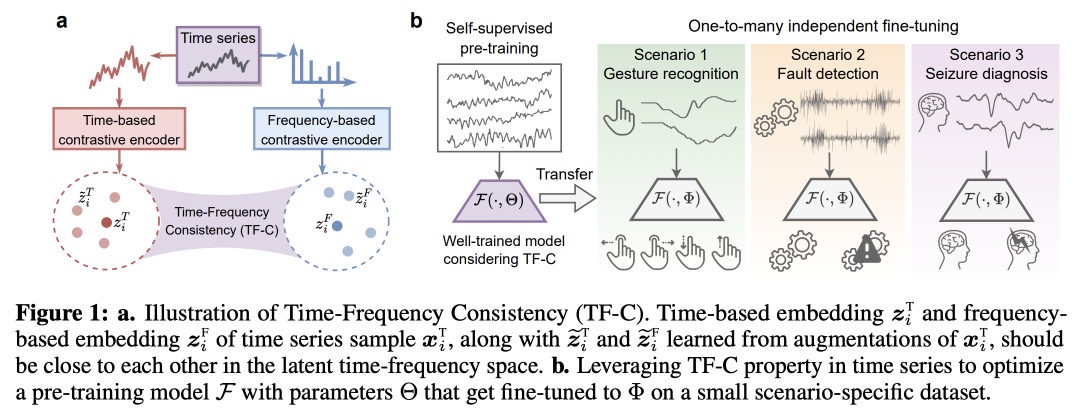
本文的核心思路为:无监督预训练的核心是将先验引入模型学习强泛化性的参数,本文引入的先验是同一个时间序列在频域的表示和在时域的表示应该相近,以此为目标利用对比学习进行预训练。

论文标题:Self-Supervised Contrastive Pre-Training For Time Series via Time-Frequency Consistency
下载地址:https://arxiv.org/pdf/2206.08496.pdf
1
Motivation
无监督预训练在时间序列中的应用越来越多,但是和NLP、CV等领域不同的是,时间序列中的预训练没有一个特别合适的,在所有数据上都一致的先验假设。例如在NLP中,一个先验假设是不管是什么领域的文本,或者什么语种的文本,都遵循相同的语法规律。但是在时间序列中,不同数据集的频率、周期性、平稳性差异都很大。以往的预训练方法现在一些数据集pretrain再在目标数据集finetune。如果预训练的数据集和finetune数据集的时间序列相关特征差异很大,就会出现迁移效果不好的问题。
为了解决这个问题,本文找到了一种不论在什么样的时间序列数据集中都存在的规律,那就是一个时间序列的频域表示和时域表示应该相似。在时间序列中,时域和频域就是同一个时间序列的两种表示,因此如果存在一个时域频域共享的隐空间,二者的表示应该是相同的,在任何时间序列数据中都应该有相同的规律。
基于上述思考,本文提出了Time-Frequency Consistency (TF-C)的核心架构,以对比学习为基础,让时域和频域的序列表示尽可能接近。
2
基础模型结构
基于上述思路,本文构建的整体模型结构如下图。首先利用多种时间序列数据增强手段,生成每个时间序列的不同增强版本。然后将时间序列输入到Time Encoder和Frequency Encoder,分别得到时间序列在时域和频域的表示。损失函数包括时域对比学习loss、频域对比学习loss、时域和频域的表式对齐loss。
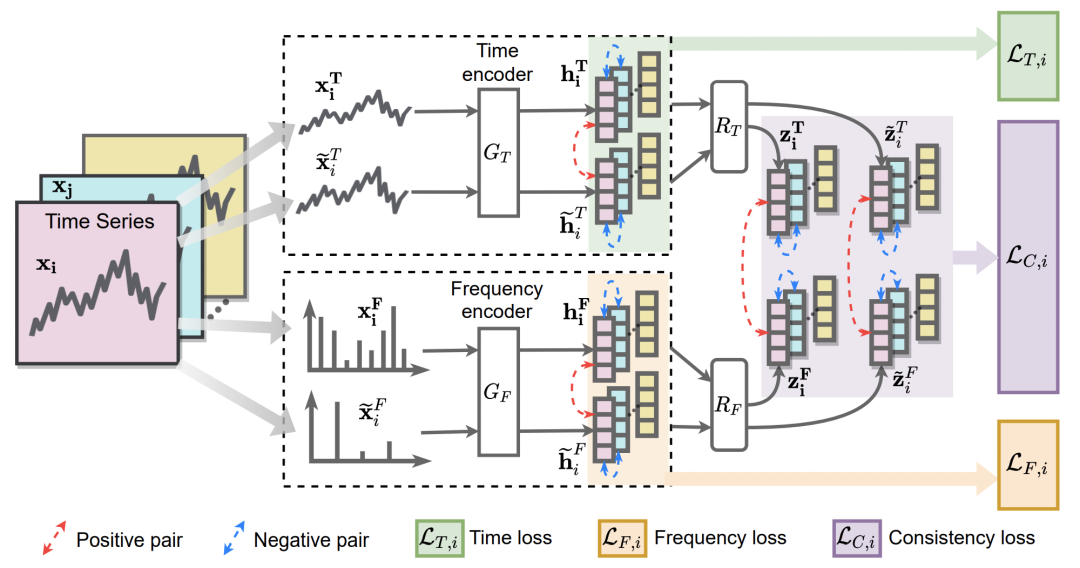
在时域上,使用的数据增强手段包括jittering、scaling、time-shifts、neighborhood segments等时间序列对比学习中的经典操作(对于时间序列数据增强,后续会出一个单独的文章系统性介绍)。经过Time Encoder后,让一个时间序列和其增强的结果表示相近,和其他时间序列远离:
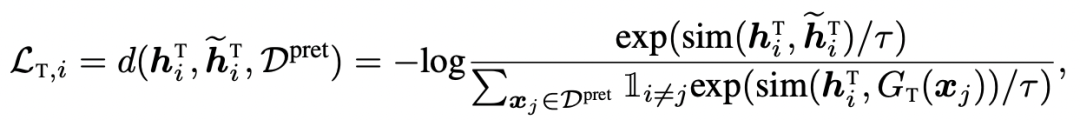
在频域上,本文是首次研究了如何进行频域中的时间序列数据增强。文中通过随机抹除或增加frequency components实现频域上的数据增强。同时为了避免频域的绕道对原始序列噪声大的变化,导致增强后的序列和原始序列不相似,会对增删的components和增删幅度做限制。对于删除操作,会随机选择不超过E个频率进行删除;对于增加操作,会选择那些振幅小于一定阈值的频率,并提升其振幅。得到频域数据增强的结果后,使用Frequency Encoder得到频域表示,并利用和时域类似的对比学习进行学习。
3
时域频域一致性
上述的基础模型结构只是分别在时域和频域内利用对比学习拉近表示,还没有引入时域和频域表示的对齐。为了实现时域和频域的一致性,本文设计了一种一致性loss拉近同一个样本在时域和频域的表示。
具体的损失函数如下,主要借鉴了triplet loss的思想。其中STF是同一个时间序列经过时域Encoder和频域Encoder生成表示的距离,其他带波浪线上标的,表示使用该样本的某种增强样本得到的序列。这里的假设是,一个样本的时域编码和频域编码应该更接近,离其增强后样本的时域编码或频域编码更远。
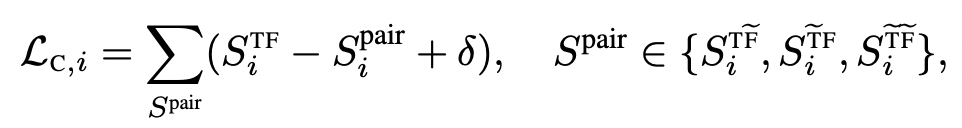
最终模型通过上述3个loss联合进行预训练。
4
实验结果
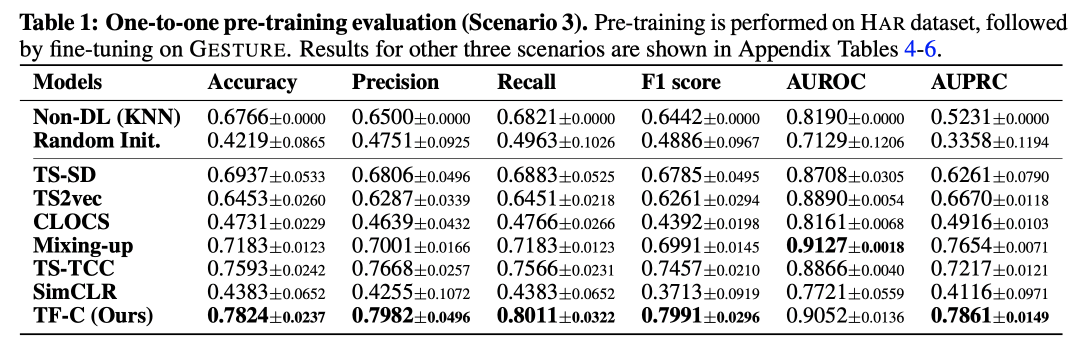
在实验方面,文中主要对比了one-to-one和one-to-many两种迁移效果。在ont-to-one实验中,是在一个数据集上使用不同的方法预训练,对比在另一个数据集上finetune后的效果。可以看到本文提出的TF-C方法效果由于其他的迁移学习方法。
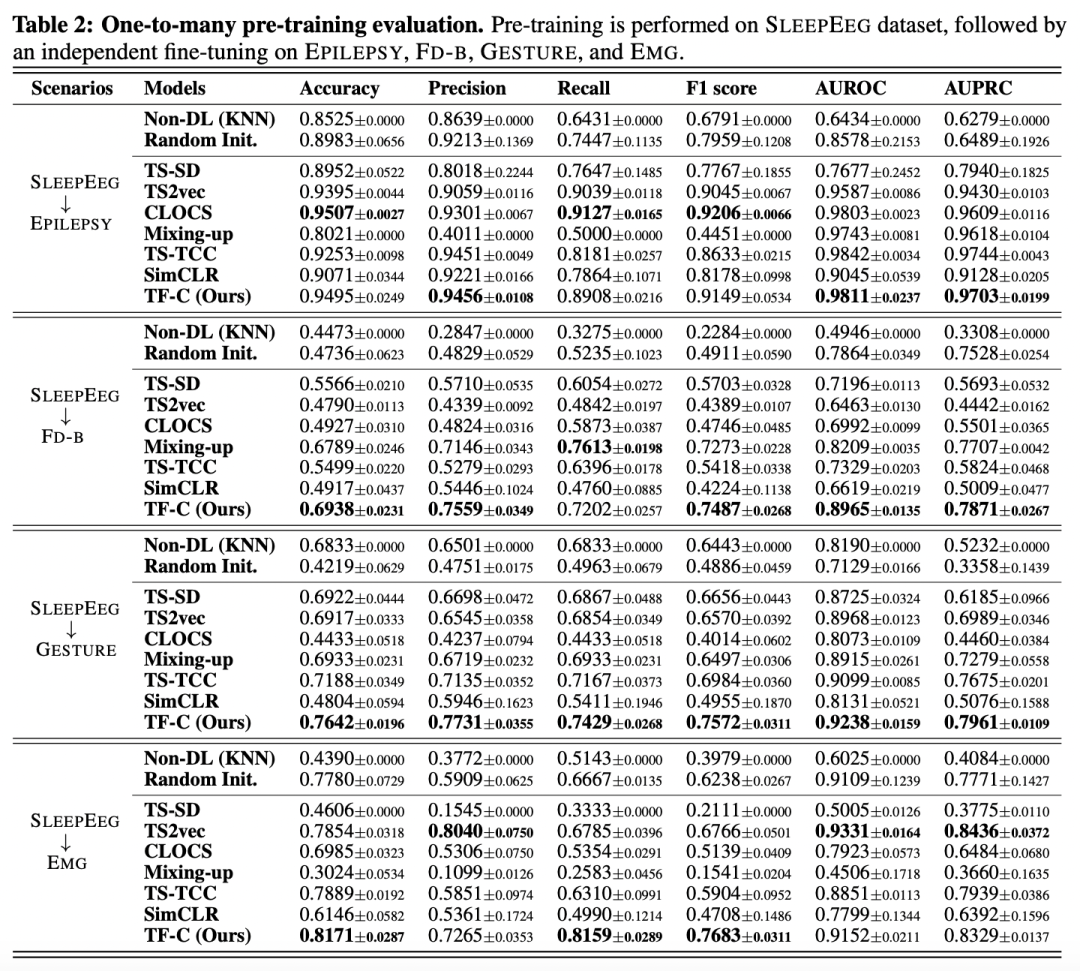
One-to-many验证的是在一个数据集上预训练,在多个数据集上finetune的效果,TF-C效果也非常显著。
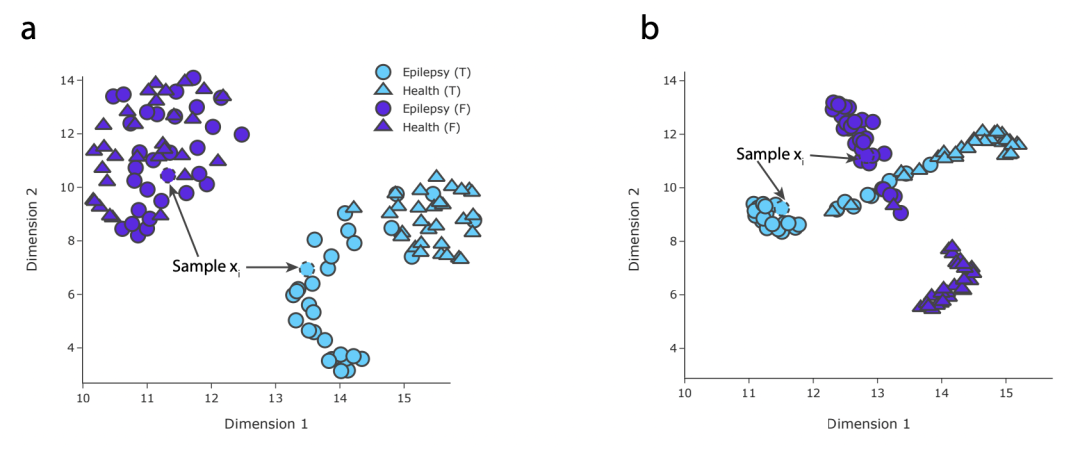
最后文中还可视化了是否加入一致性loss对时域、频域表示学习的影响。不加一致性loss,时域和频域表示被学成两个簇,同一个样本两个表示距离比较远。而引入一致性loss后,拉近了同一个样本时域和频域的表示。
5
总结
本文提出的时间序列预训练方法,解决了一个非常核心的问题:在时间序列中,什么样的规律是所有数据集都遵循的。时域和频域一致性这一先验假设,在不同数据集上都成立,类似于NLP中的语法,让时间序列预训练方法更加合理。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书