- 2023.2.7
- google research\
- Eugene Kharitonov
文章目录
abstract
- 用两种离散的特征表示,将TTS分解成两个seq2seq任务:(1)文本到semantic tokens,类似于reading,需要audio-text平行数据(2)semantic tokens到acoustic tokens,类似于speaking,只需要纯音频,因此最终生成音频的质量和多样性和可获得的平行数据无关了。因为常规处理方法下,TTS需要平行数据(text-audio pair),这就导致数据来源受限。通过这样两阶段的改进,就可以利用到网上的海量的纯音频数据。
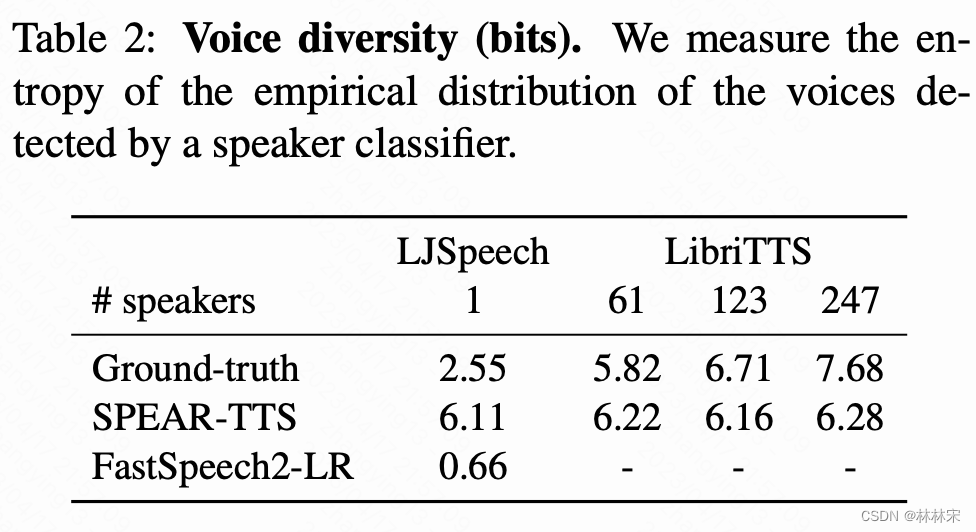
- 效果:对于单人TTS,只需要15min的audio-text数据在multi-speaker上finetune即可。对于新音色克隆,只需要3s的注册音频。
intro
- 音频离散化:使用有限的离散特征字典对音频进行离散化;audioLM将音频离散成两部分,semantic tokens和acoustic tokens。
- 本文的两阶段过程类似于机器翻译,使用BART/T5这样的预训练,辅助backtranslation技巧,大大减少SPEAR-TTS对于平行数据训练的依赖。
- 音色prompt:使用clip audio,作为example prompting,类似语言模型的训练技巧。这样在只有单说话人平行数据时,简化多说话人系统构建的可控性。
- 随机采样增加多样性:提出基于objective quality metric的采样方法,提升合成语音的质量。
- 实验:LibriTTS(551h)的数据用于预训练&backtranslation,15min(LJSpeech)的数据用于单人建设。合成语音高音准,CER 1.92% on LibriSpeech test-clean ;合成各种音色的语音;3s unseen speaker的音频完成音色复刻;高的生成质量,MOS 4.96 vs 4.92。
Discrete Speech Representations
主要参考AudioLM的设计
- Semantic tokens :需要从音频中提取出语义明显的信息,其余的副语言信息比如说话人身份和升学细节可以不包含。基于w2v-BERT训练自监督模型,特定层的输出使用k-means聚类,然后只取索引的kmeans结果作为离散特征。
- Acoustic tokens :用于重建高精度的音频,使用SoundStream作为特征提取工具。残差多级量化。
SPEAR-TTS Overview
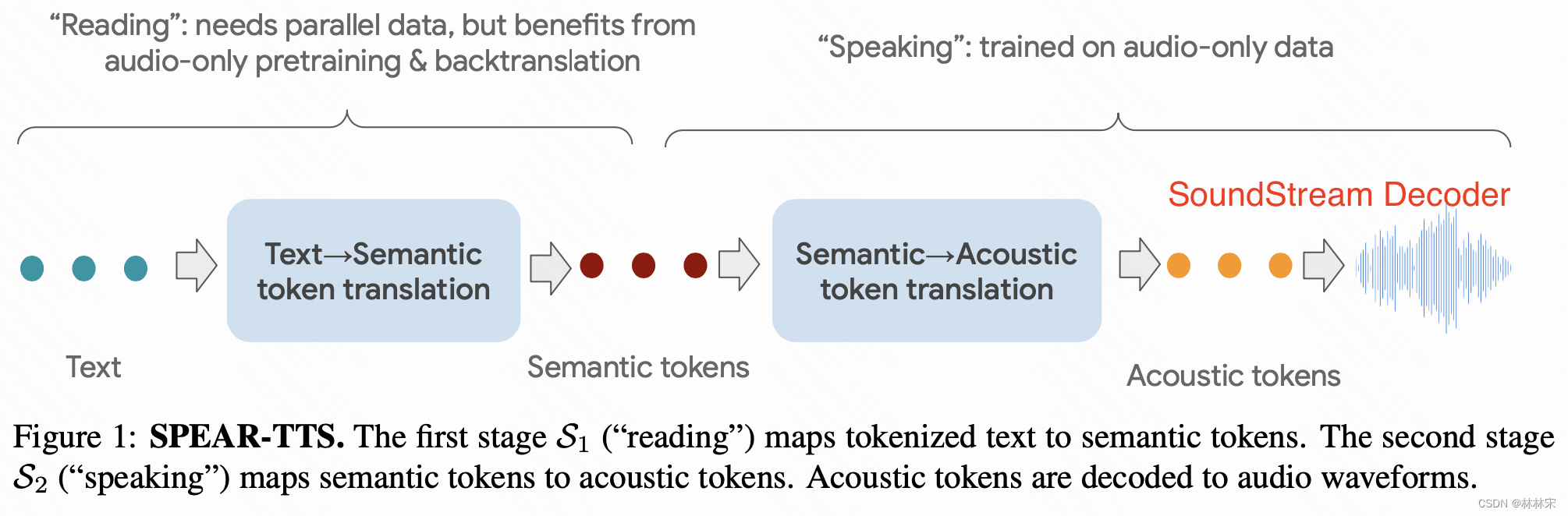
stage1:Improving Supervision Efficiency
- 从文本映射到semantic tokens,semantic tokens主要是text相关的信息,也会有prosody & speaker info,相比于直接预测acoustic tokens的难度要低,相比于文本,也为acoustic tokens的预测提供了更多信息。
- 基于audio-text数据训练,从audio中提取semantic tokens,可以通过transformer-based encoder-decoder结构或者decoder-only的结构完成。
- transformer的训练需要很多数据,但是有的语言没有那么多可获得的audio-text数据;因此可以通过预训练+backtranslation来解决平行数据资源缺乏的问题。
pretraining
- 类似于BART/T5,基于denoiseing pretext task任务进行预训练,对tokens进行损坏(也包括其他的损坏操作,替换,删除等,作者发现删除更有效果),然后让模型预测无损的token seq。
- 预训练之后,freeze encoder-upper + decoder+ 之间的attention layer参数,基于平行数据对encoder lower layers进行更新。
- 首先,纯音频数据通过预训练的模型,生成转录信息(类似semantic tokens),然后用生成的数据继续训练stage1的模型;最后,在text-audio的数据上finetune模型。
Backtranslation
- 使用pretrain的模型,freeze encoder,只更新decoder的参数。
stage 2: Controlling the Generation Process
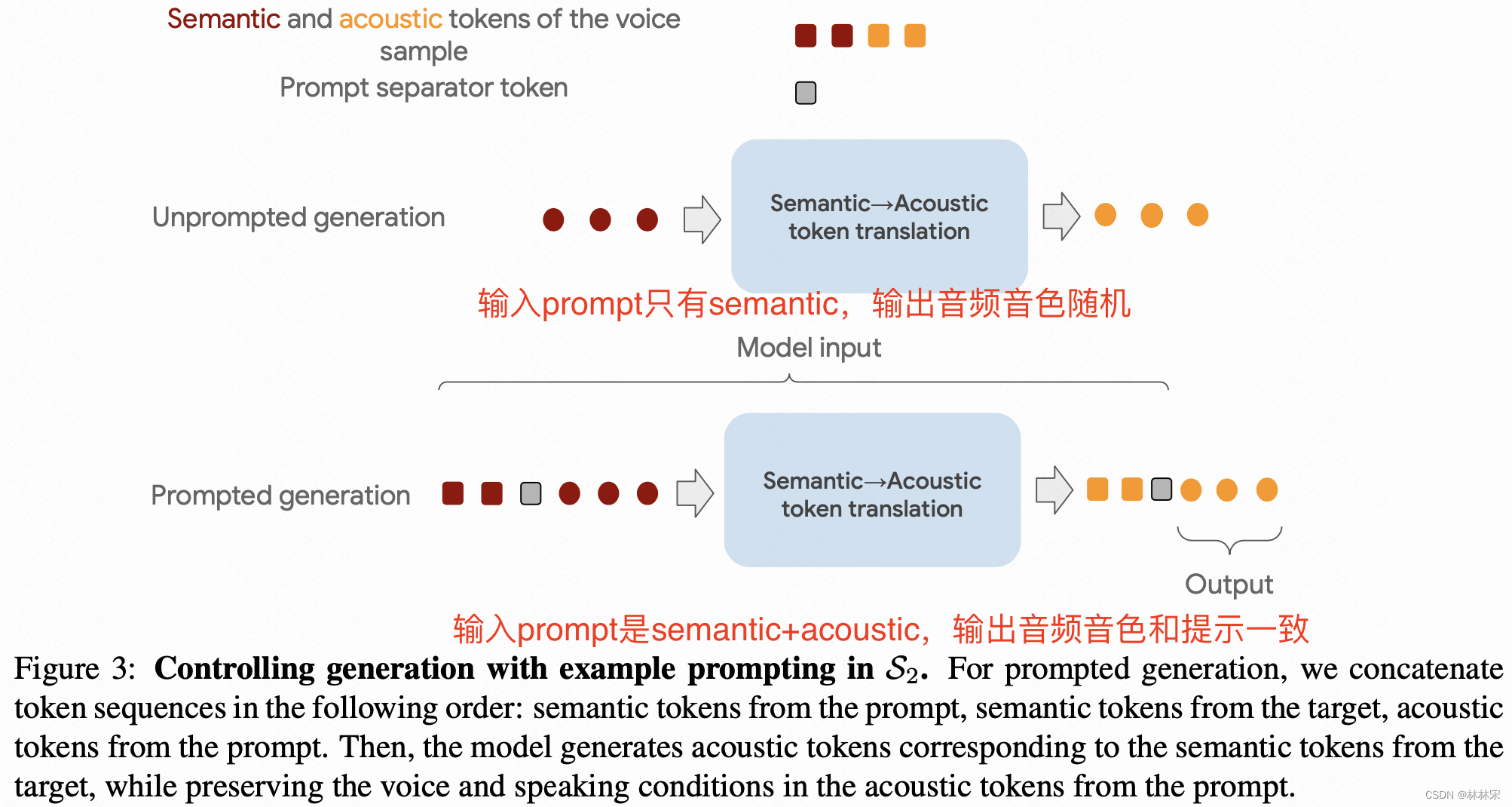
- 因为semantic tokens到acoustic tokens是基于audio-only数据训练的,因此stage1即使只使用了单人数据,也可以生成结果多样的音频(不同的音色/语速等)
- 为了控制合成音色,参考AudioLM的设计,(1)语音前缀只有semantic token时,后续的音频每次会是随机采样一个音色;(2)前缀有semantic token+acoustic tokens时,后续音频的音色参考acoustic token的音色。
- 一段音频中取两段不重叠的部分分别作为prompt和target,训练的时候prompt 可以来自于prompt audio中提取的(a)semantic tokens或(c)acoustic tokens,或者target audio中提取的(b)acoustic tokens,用以预测target acoustic token。infer阶段,target acoustic tokens自回归的生成。
- 边界处加入<seg bound>,以免边界处出错。不再需要prompt对应的的文本转录信息。
- 本阶段的生成音频会包含训练数据集中的噪声,为了降低inference阶段的生成噪声,有两种方法:(1)prompt挑选信噪比高的音频;(2)对于同样的数据,使用随机采样,生成多条音频,然后使用no-reference audio qual- ity metric计算噪声最低的。使用一个类似于DNSMOS的噪声估计器建模。
Experimental Setup
Training and validation data
- Acoustic and semantic tokens:Libri- Light 数据集(6w 小时,7k+说话人)用于训练自监督的SoundStream,w2v- BERT,以及w2v- BERT的kmeans特征。
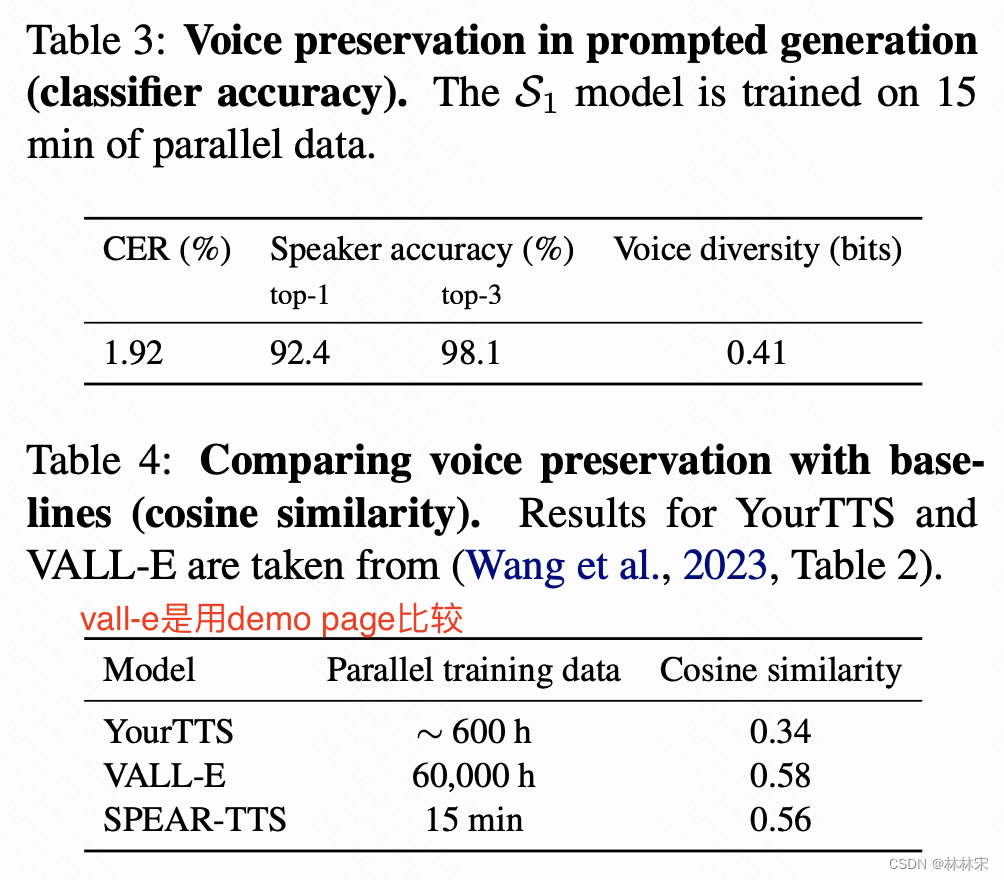
- stage1 训练:使用LJSpeech单人训练(也支持多人),24h数据。同时也划分出12/3/2/1h 以及30/15min的数据作为极限验证。其中15min的数据中包含21k semantic tokens,2k words。
- Pretraining:使用LibriLight的音频数据,提取semantic tokens;
- Backtranslation:使用LibriTTS的音频数据。
- stage2训练:从LibriLight中提取成对的semantic and acoustic token
Evaluation data
- 因为LJSpeech中的音频不超过10s,因此选择LibriSpeech test-clean中不超过10s的音频文本作为测试合成,一共大约3h的数据。
Preprocessing
- ljspeech中的标准缩写展开;使用G2p_en phonemizer,去除词汇中的重音信息,字典中一共有47 tokens(39个来自于CMU DICT)。
- 因为phonemizer在low-supervision scenarios并不是通用的,因此用grapheme做实验。附录G
Metrics
-
测试CER:使用LibriSpeech test-clean进行合成,然后用ASR测试;

-
音色多样性:使用预训练的说话人模型。
-
和prompt的音色一致性
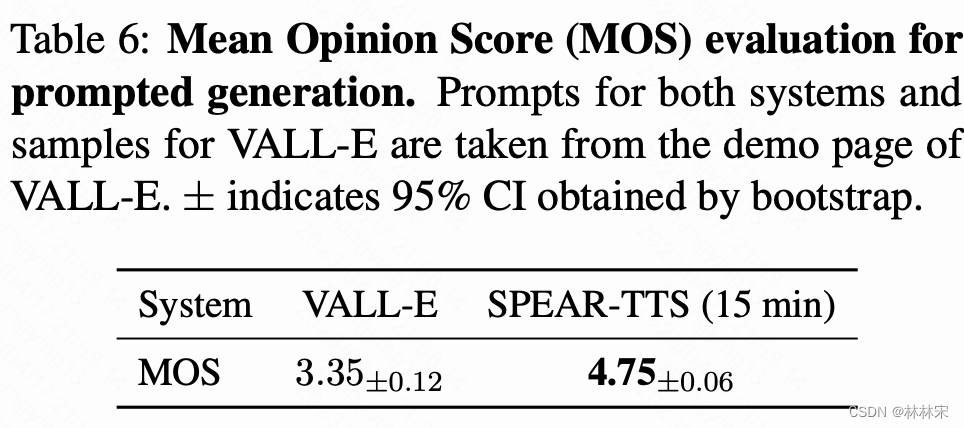
- 主观MOS打分

Hyperparameters & Training details
- semantic tokens:7th layer of w2v-BERT using a codebook of size 512. 1s的音频表示成25512的离散特征,等效于 25log512=225bit/s
- acoustic tokens:使用SoundStream的3个量化器,3*1024;1s的音频表示成50hz *3=150个acoustic tokens,等效于1500bit/s;