大语言模型的持续预训练
收录于合集#论文速递258个
概述
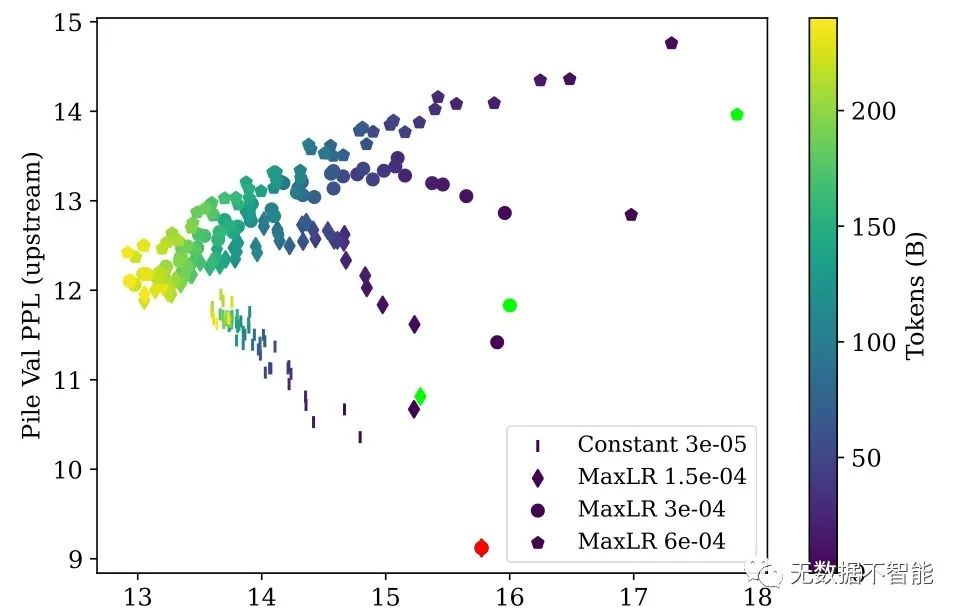
本文的研究背景是大型语言模型的预训练过程通常需要从头开始,耗时耗力。作者试图探索如何使这些模型能够持续预训练,即在新数据到来时更新预训练模型,而不是重新训练。 过去的方法要么是从头开始训练,要么是使用低成本的超参数优化,并未解决预训练模型的持续更新问题。本文的方法是通过逐步递增学习率的方式进行模型重新启动,以提高计算效率。这种方法具有可行性和动机性。 本文提出了一种基于线性启动和余弦衰减的预训练模型的重新启动方式,并在预训练的模型上持续预训练,同时尝试了不同的预训练检查点、学习率和启动长度。 本文在Pythia 410M语言模型架构上进行了实验,通过验证的困惑度评估性能。结果表明,虽然模型的重新启动初始时会增加上游和下游数据的损失,但长期来看可以提高下游任务的性能,并且在大规模下游数据集上超越从头训练的模型。

重要问题探讨
1. 为什么在预训练模型中加入新数据会导致在旧数据上的性能下降?
答:在预训练模型中加入新数据会引起数据分布的变化,因此新数据带来的分布偏移会导致模型在旧数据上的性能下降。这是因为模型在预训练过程中学习到的特征和表示不适应新数据的分布。
2. 为什么在训练新数据时需要重新增加学习率? 答:在训练新数据时,重新增加学习率可以提高计算效率。由于新数据具有与旧数据不同的分布,通过增加学习率可以加快模型对新数据的适应能力,从而降低整体训练时间和成本。
3. 为什么在长期训练中重新增加学习率可以提高下游任务表现?
答:重新增加学习率在初始阶段可能会导致在上游和下游数据上的损失增加,但在长期训练中可以提高下游任务的表现。这是因为随着训练的进行,模型能够逐渐适应新数据的分布,并学习到更好的表示和特征,从而提高在下游任务上的性能。
4. 新数据的规模对于重新增加学习率的效果有何影响?
答:新数据的规模会对重新增加学习率的效果产生影响。较大规模的新数据可能需要更长的重新增加学习率的阶段,以便模型能够充分适应新的数据分布。较小规模的新数据可能不需要重新增加学习率的过程,因为模型可以很快地适应新数据。
5. 与从零开始训练相比,将预训练模型与新数据结合进行训练能带来哪些优势?
答:与从零开始训练相比,将预训练模型与新数据结合进行训练可以带来更高的性能。经过预训练的模型已经学习到了大量的语言知识和特征,能够提供更好的初始表示,因此可以在较少的训练步骤后就达到较好的性能。这样可以显著降低训练的时间和计算成本,并且在大规模数据上表现更好。
论文链接:https://arxiv.org/abs/2308.04014.pdf