本机环境:Windows10
虚拟机:centos7
所需软件、安装包:JDK、hadoop、winscp(可选)
1.Linux虚拟机的安装及网络配置
1.1.虚拟机安装教程
1.2.网络配置
网络配置_CentOS要求: 宿主机与多个虚拟机之间联网
1.2.1.虚拟机网卡设置
选择网卡模式为:
-
桥接:网卡地址会与主机地址在同一个网段,虚拟机–>主机、虚拟机–>虚拟机能连通(机房环境中可能造成IP地址不够用)
-
Host-Only:虚拟机会与宿主机的虚拟网卡组成一个局域网,局域网中可使用单独的静态内部IP,只需要将网关设置为虚拟网卡的地址即可,这样,虚拟机之间可通过局域网互联,虚拟机通过网关与宿主机连接
-
NAT:NAT配置教程(我选择的方式)
1.2.2.虚拟机IP配置
- 设置固定IP:
修改IP地址要在这里修改,使用ifconfig命令不能永久修改
命令:vi /etc/sysconfig/network-scripts/ifcfg-网卡名
网卡名进入/etc/sysconfig/network-scripts/目录查看即可,CentOS7以后不再默认为eth0
需求修改和新增的配置:
Node1
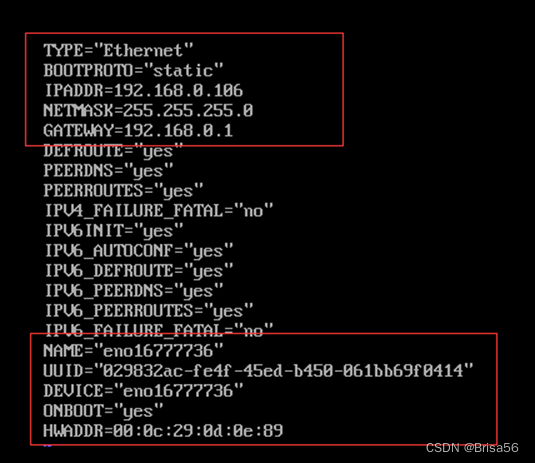
Node2
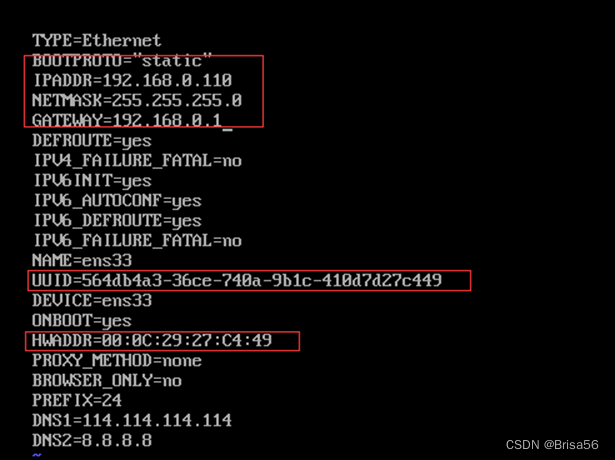
Node3
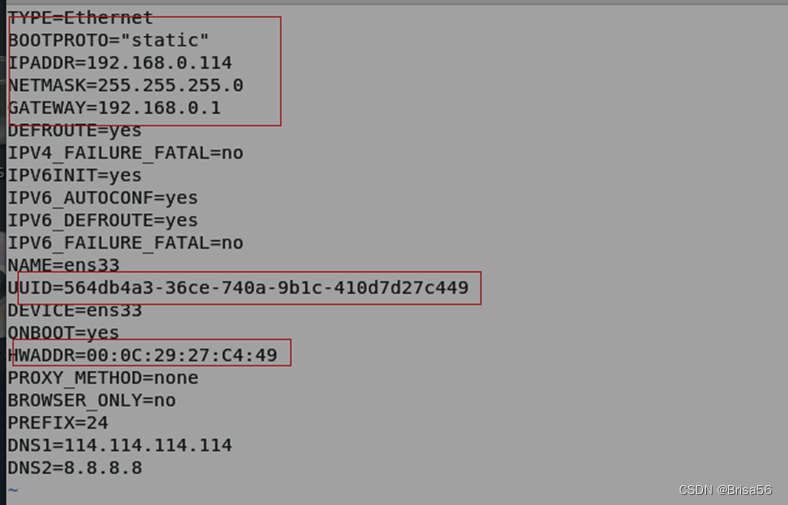
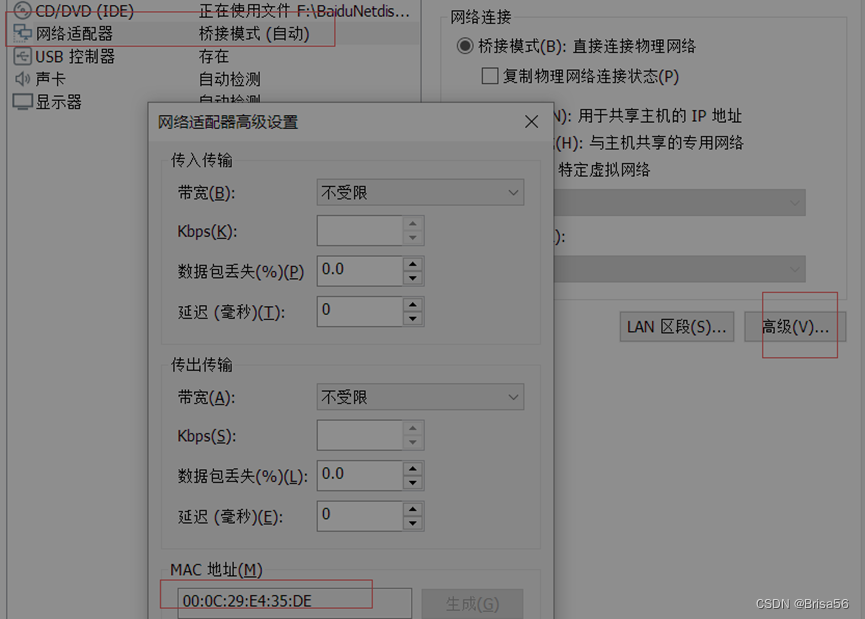
说明:
我是选择克隆的虚拟机1,克隆过后需要修改UUID,HWADDR。
UUID可在虚拟机对应的文件下里找到文件命名为一长串数字+子母组成的字符串,这就是UUID。
HWADDR在虚拟机的此处可找到
- 修改DNS
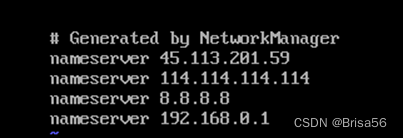
vi /etc/resolv.conf
增加配置:
nameserver 114.114.114.114
或183.221.253.100、61.139.2.69

说明:
之前存在ping不通外网,参考解决教程:linux 解决ping未知的名称或服务
然后重启网络服务:service network restartcm

-
网络连接测试和故障排查
三个结点分别ping外网、掩码、主机和另外两个结点 -
修改主机名
使用hostname命令不能永久修改
命令:vi /etc/hostname
直接将主机名写入即可:
node1
再执行命令:hostname检查是否生效
若未生效,再执行命令:hostname node1临时修改一下

还要修改host映射文件
命令:vi /etc/hosts
配置文件如下(IP地址和主机名以实际的为准):
127.0.0.1 localhost
192.168.0.2 node1
192.168.0.3 node2
192.168.0.4 node3
说明:三台虚拟机都需如此配置
1.3.安装ifconfig
先搜索命令ifconfig命令的名称是什么
命令:yum search ifconfig
然后再安装
命令:yum intstall net-tools

1.4.尝试ssh登录
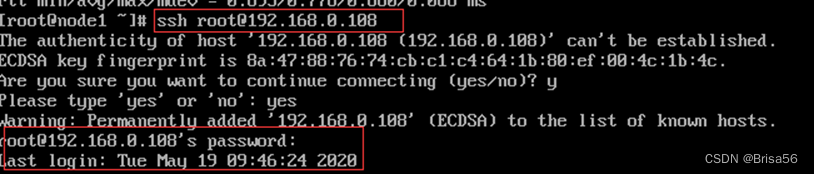
命令:ssh [email protected](这里的@IP,可以将IP变为主机名,前提是1.2.中的网络配置已完成,且实现了三台主机名的更改和相应的文件更改) 远程登录另一个虚拟机
命令:exit 退出ssh


2.hadoop的安装
2.1.SSH免密登录
- Hadoop集群通过Linux的SSH相互之间通信,故需配置SSH免密登录,否则节点间通信将被Linux拒绝
- 免密登录原理:即事先将RSA非对称加密的公钥由主节点拷贝到到其他节点,只需实现主节点至其他节点的免密即可
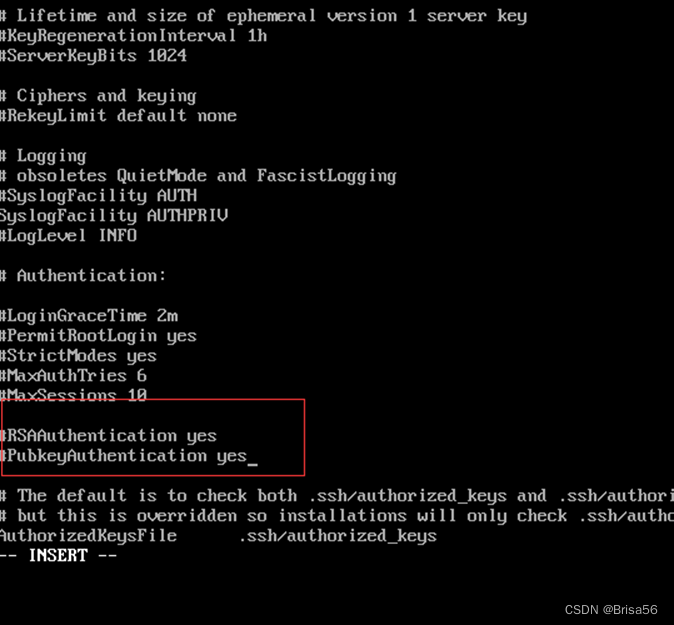
1、去掉/etc/ssh/sshd_config的两行注释,打开RSA非对称密钥验证,所有节点都须操作
命令:vi /etc/ssh/sshd_config
2、生成密钥对
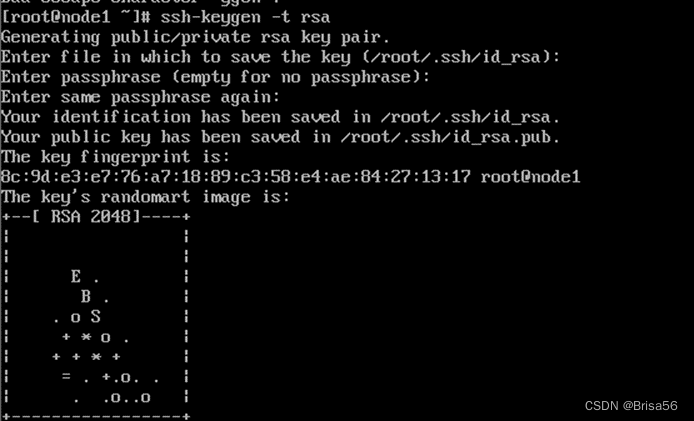
(1)所有节点执行
命令:ssh-keygen -t rsa 生成key,不用输入密码,一直回车,生成密钥对放在 ~/.ssh 目录(ls -al可查看)

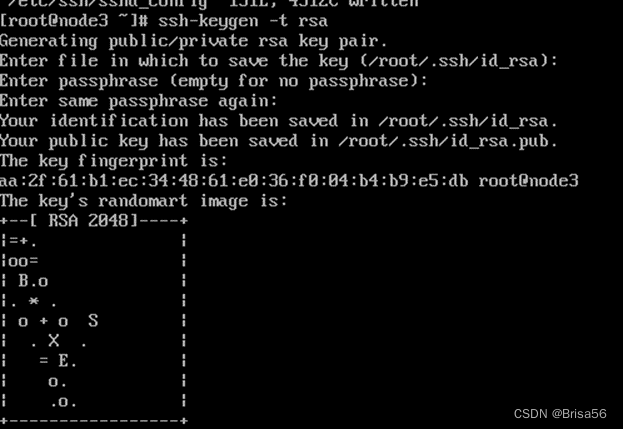
(2)主节点执行
id_rsa.pub是公钥文件,将公钥文件内容复制到authorized_keys文件,并复制到其他节点的~/.ssh目录
命令:cd ~/.ssh 进入到.ssh目录
命令:cat id_rsa.pub>> authorized_keys
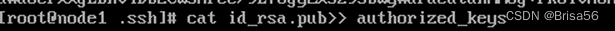
命令:scp -r authorized_keys root@node2:~/.ssh/authorized_keys 将公钥文件复制到其他节点,节点名以实际的名称为准


命令:scp -r authorized_keys root@node3:~/.ssh/authorized_keys
(3)检查ssh
命令:ssh node2
命令:ssh node3
执行ssh将不再需要密码,若还需要密码,则重复前面的配置过程


2.2.下载安装JDK
1、下载JDK
最新的Hadoop需要下载JDK8
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
注意:同时下载jdk-8u211-linux-x64.tar.gz和jdk-8u211-windows-x64.exe,虚拟机和宿主机要安装相同版本的JDK,以便后续实验的进行
下载后,在Windows用运行winSCP,将jdk传至Linux

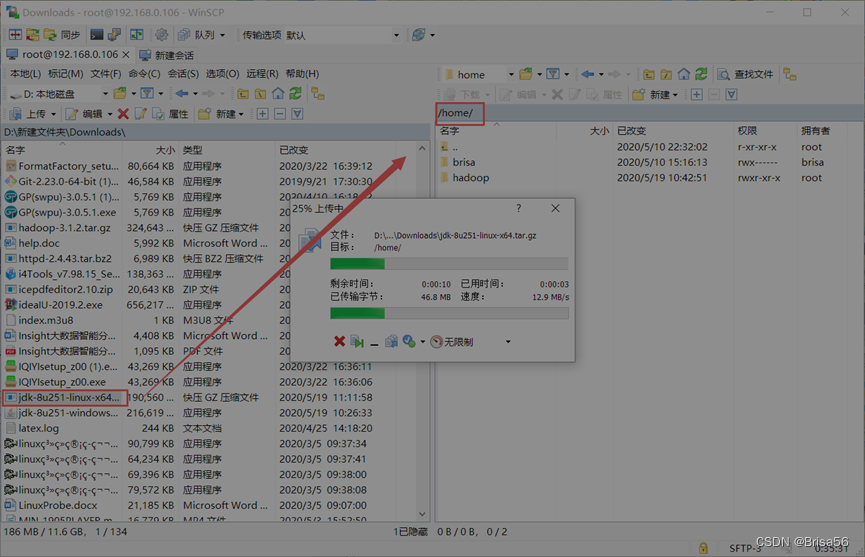
2、安装配置JDK
(1)进入~/目录中找到传上来的jdk文件
命令:cd ~/…

(2)解压文件
命令:tar zxvf jdk-8u211-linux-x64.tar.gz

命令:mv jdk1.8.0_211 /home/ 将解压后的目录移动至指定目录

(3)
配置环境变量
命令:vi /etc/profile
在profile文件下面追加写入下面信息:
export JAVA_HOME=/home/jdk1.8.0_211 JDK实际的安装目录
export JRE_HOME=\$JAVA_HOME/
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

命令:source /etc/profile 使配置文件生效
命令:java -version 若能显示版本则JDK安装配置完成,否则检查前面的步骤是否正确

2.3.下载安装Hadoop
2.3.1.Hadoop下载
最新版3.1.2,2019年2月6日发布
下载页面:https://hadoop.apache.org/releases.html
文件地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
(1)可用wget下载:
mkdir /home/hadoop
wget -P /home/hadoop https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
(2)也可在宿主Windows中下载了,通过winscp上传到Linux
Windows里面下载

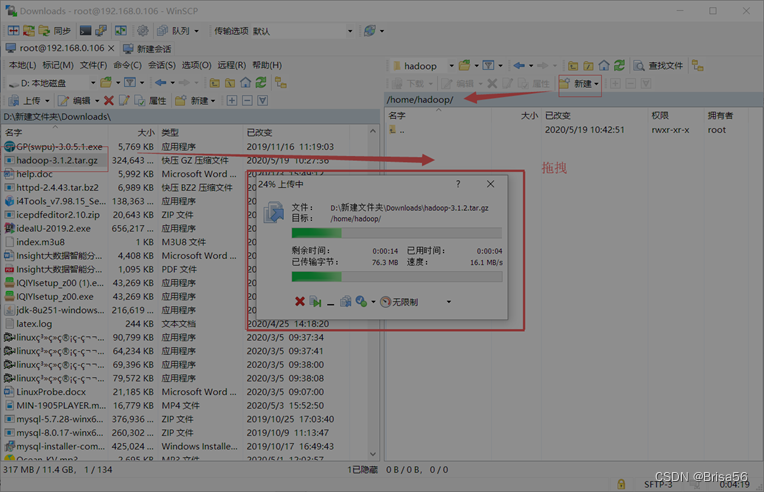
说明:这里是宿主机内下载,用的winSCP进行的文件传输
2.3.2.文件解压
(1)命令:tar zxvf hadoop-3.1.2.tar.gz
然后再将解压后的目录移动至想要放置的位置,如:

(2)在/home/hadoop目录下创建数据存放的文件夹,tmp、dfs、dfs/data、dfs/name
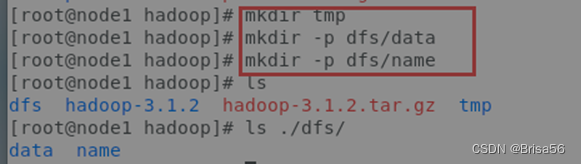
2.3.3.配置hadoop-env.sh
用vi编辑器打开目录**/home/hadoop/hadoop-3.1.2/etc/hadoop/下的hadoop-env.sh配置文件
找到 # export JAVA_HOME= **,大概在54行的位置,去掉该行注释并添加JDK位置


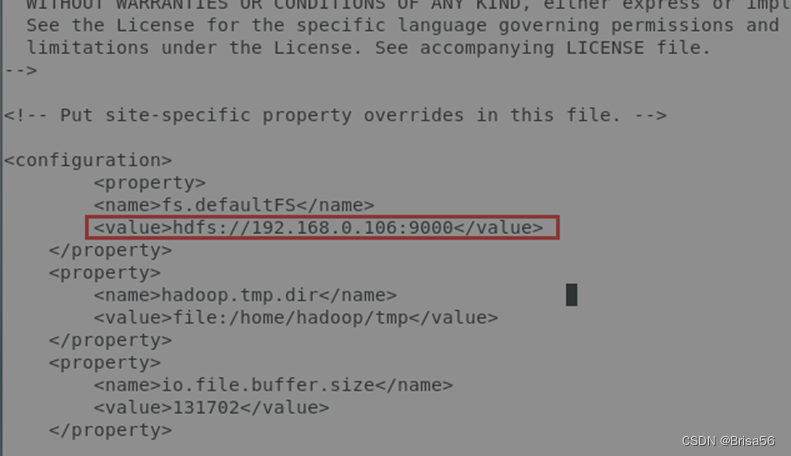
2.3.4.配置core-site.xml
用vi编辑器打开目录/home/hadoop/hadoop-3.1.2/etc/hadoop/下的core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.2:9000</value> <!--以实际的主节点地址为准-->
</property>
<property>
<name>hadoop.tmp.dir</name> <!--原数据的目录位置-->
<value>file:/home/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
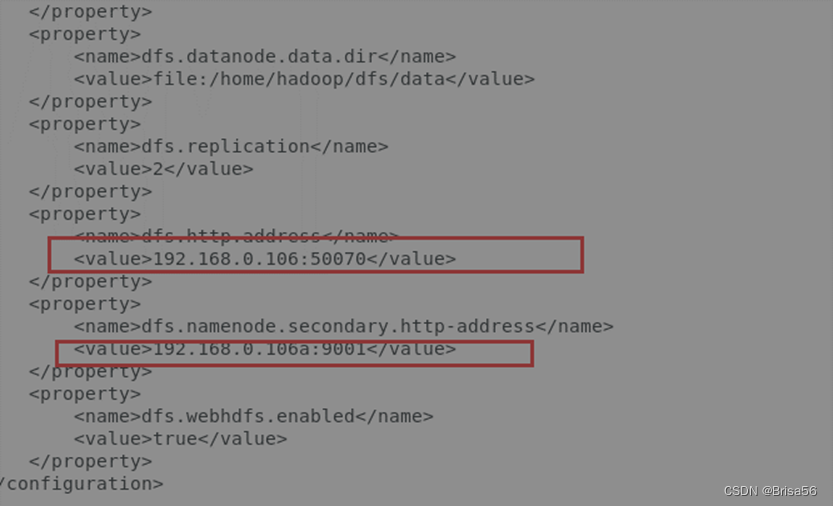
2.3.5.配置hdfs-site.xml
用vi编辑器打开目录/home/hadoop/hadoop-3.1.2/etc/hadoop/下的hdfs-site.xml配置文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.http.address</name>
<value>192.168.0.2:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.0.2:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
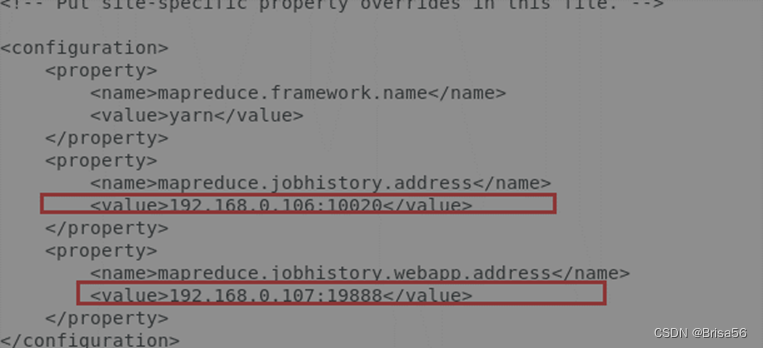
2.3.6.配置mapred-site.xml
配置/home/hadoop/hadoop-3.1.2/etc/hadoop目录下的mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.2:19888</value>
</property>
</configuration>
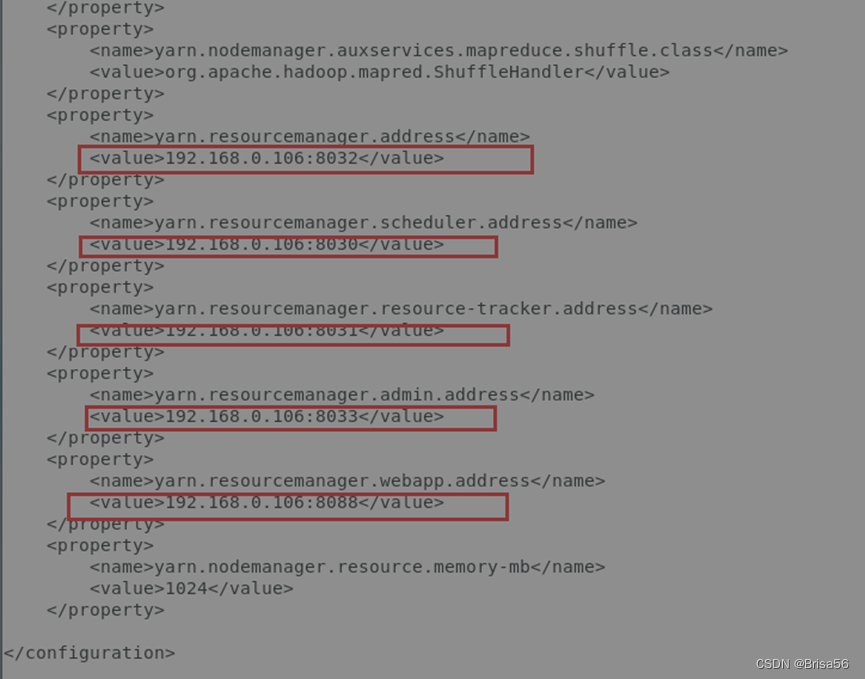
2.3.7.配置yarn-site.xml
配置/home/hadoop/hadoop-3.1.2/etc/hadoop目录下的yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.2:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
</configuration>
2.3.8.配置hadoop-env.sh、yarn-env.sh的JAVA_HOME
配置/home/hadoop/hadoop-3.1.2/etc/hadoop目录下hadoop-env.sh、yarn-env.sh的JAVA_HOME,不设置的话,启动不了,
export JAVA_HOME=/home/jdk1.8.0_211 # 以实际地址为准

2.3.9.配置Hadoop命令环境变量
命令:vi /etc/profile
在profile文件下面追加写入下面信息:
export HADOOP_HOME=/home/hadoop/hadoop-3.1.2
export PATH=$PATH:$HADOOP_HOME/bin
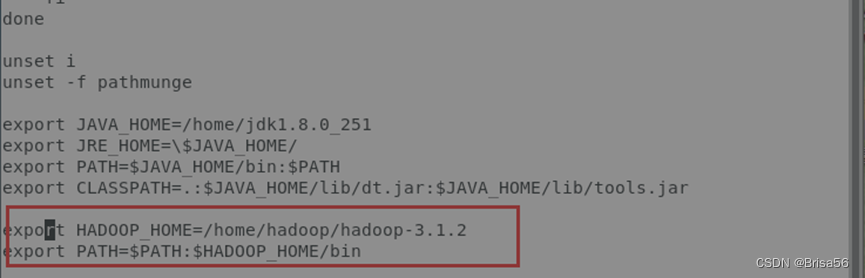
执行命令:source /etc/profile 环境变量即生效

2.3.10.配置workers
配置/home/hadoop/hadoop-3.1.2/etc/hadoop目录下的workers,删除默认的localhost,增加2个从节点
IP地址以实际的为准
192.168.0.3
192.168.0.4
命令:vim /home/hadoop/hadoop-3.1.2/etc/hadoop/workers

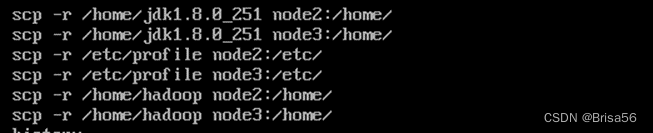
2.3.11.复制
将JDK、profile和Hadoop复制到各个节点对应位置上,通过scp传送,
scp -r /home/jdk1.8.0_211 192.168.0.3:/home/
scp -r /home/jdk1.8.0_211 192.168.0.4:/home/
scp -r /etc/profile 192.168.0.3:/etc/
scp -r /etc/profile 192.168.0.4:/etc/
scp -r /home/hadoop 192.168.0.3:/home/
scp -r /home/hadoop 192.168.0.4:/home/
2.3.12.启动hadoop
在主节点上启动hadoop,从节点会自动启动,进入/home/hadoop/hadoop-3.1.2目录
(1)初始化,输入命令:bin/hdfs namenode -format
(2)全部启动sbin/start-all.sh,也可以分开sbin/start-dfs.sh、sbin/start-yarn.sh
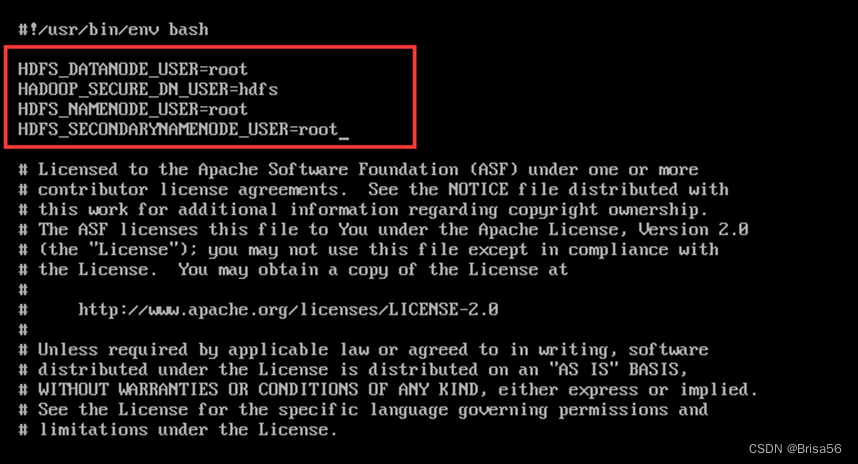
如果提示:there is no HDFS_NAMENODE_USER defined,则添加用户
$ vi sbin/start-dfs.sh
$ vi sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
如果提示:ERROR: there is no YARN_RESOURCEMANAGER_USER defined.,则添加用户
$ vi sbin/start-yarn.sh
$ vi sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
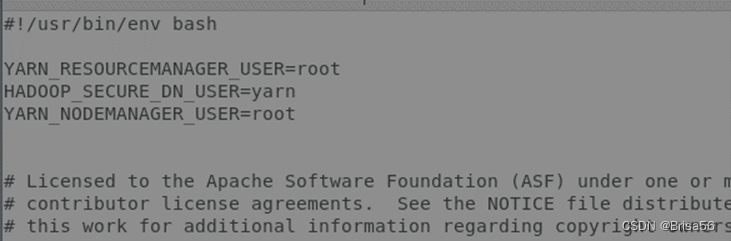
再次进行sbin/start-all.sh
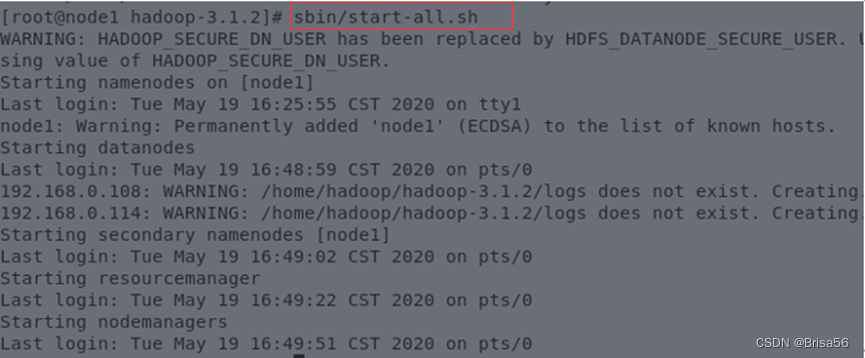
(3)输入命令:jps,可以看到相应的守护进程
主节点:NameNode、SecondaryNameNode
从节点:DataNode
主节点也可同时运行NameNode和DataNode,只需要在workers文件中配置即可
若守护进程不全,则进入/home/hadoop/hadoop-3.1.2/logs,查看日志以找到出错之处

(4)测试HDFS是否正常
执行HDFS Shell命令,尝试往HDFS上传一个文件
查看Hadoop里的文件

将本地文件/home/brisa/test提交到HDFS的 /

再次查看Hadoop里的文件

(5)停止服务,输入命令,sbin/stop-all.sh
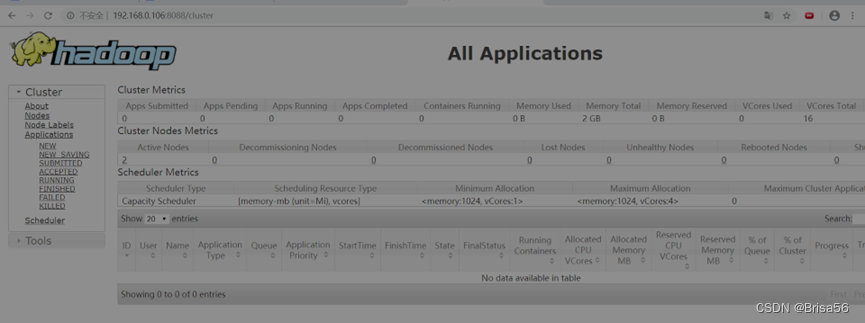
2.3.13.Web访问
(1)若有防火墙,需要先开放端口或者直接关闭防火墙
命令:systemctl stop firewalld.service 停止firewall
命令:systemctl disable firewalld.service 禁止firewall开机启动
chkconfig iptables off
service iptables stop
(2)在宿主机上的浏览器访问URL
http://192.168.0.2:8088/
http://192.168.0.2:50070/
(这里需要在12步(5)sbin/stop-all.sh前进行)
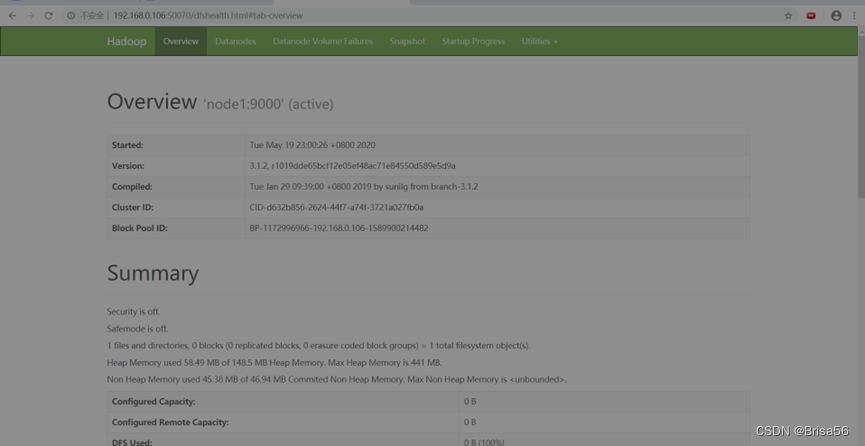
14、安装完成。这只是大数据应用的入门