近年来,大数据技术越来越吃香,也是追求高薪的必备技能之一。
近些日子,打算技术转型,开始研究大数据技术,基于对JAVA、LINUX系统有一定的基础,完成hadoop集群搭建(1个master和1个slave)。
一、准备工具
VMvare、centOS6.3、SSH Secure客户端(具体安装过程这里不做描述)
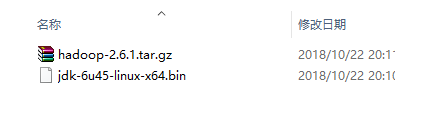
hadoop2.X压缩包与jdk安装包,我这里准备的JDK和Hadoop软件包如下所示。
二、Linux环境下静态IP配置
通过虚拟网络NAT模式进行联网,因为NAT模式是根据本机虚拟出来的网段,在设置IP后,无需更改静态IP;而桥接模式的静态IP需要设置在和本主机相同的网段下,若更换网络,也需要更改静态IP。
输入命令ifconfig,查看自己的网卡,如果查不到,可输入命令ifconfig -a,有可能网卡名称是eth0、eth1、eth2等等,看哪个存在就修改哪个
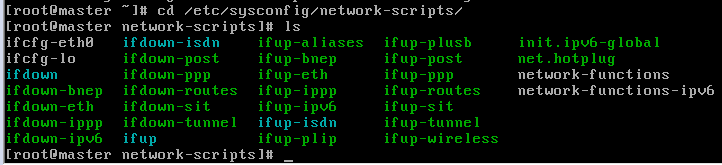
1.进入ip配置界面 命令:cd /etc/sysconfig/network-scripts/文件夹下,输入命令ls,查询文件夹所有文件。
2.输入命令vi ifcfg-eth0修改文件内容
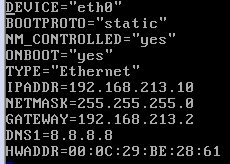
需要注意的是:
DNS改成8.8.8.8,以免换了网络由于DNS不对而连不上网,其中MAC地址也要与之对应,包括DEVICE的名称,也要与之前查到的网卡名对应,BOOTPROTO=“static”,表示静态地址,网关号可在虚拟网络编辑器中的NAT设置中查看。
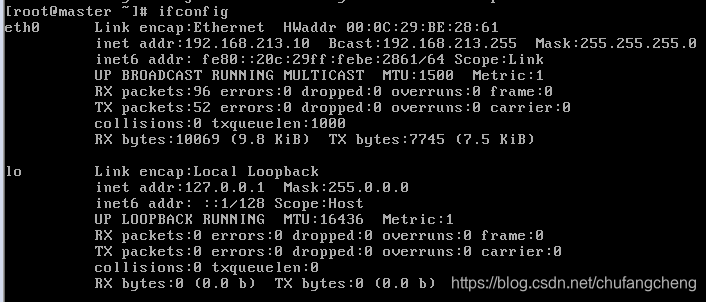
3.IP配置好后,输入命令service network restart,重启网络,再查看下自己的网络是否配置完成
4.通过输入命令curl www.baidu.com或ping 本机IP地址来测试网络连通性。
5.修改主机名,并设置hadoop集群
编辑文件修改主机名 vi /etc/sysconfig/network
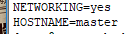
编辑文件设置集群 vi /etc/hosts,设置各主机地址与对应主机名
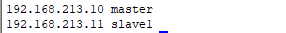
同理配置另一台虚拟机的IP,并设置主机名与hadoop集群,即再执行一次第5步操作
三. JDK安装与环境配置
1.设置共享文件夹
选中第一台虚拟机,启用共享文件夹,共享文件夹中存储的是我的jdk和hadoop软件安装包。

2.输入命令:cd /mnt/hgfs/ ,并查看共享的文件夹,在上图我设置的共享文件夹名称为dev_centos

输入命令:cp * /user/local/src/,拷贝jdk文件夹至/user/local/src/下,并检查是否已拷贝进来。

3.准备设置java环境
解压jdk,输入命令:tar -zxvf ./jdk-6u45-linux-x64.bin
设置环境变量,输入命令:vi /etc/profile ,按“i”进入编辑内容,按“wq”保存并退出
查看文件路径:命令:pwd

编辑配置文件 vi /etc/profile
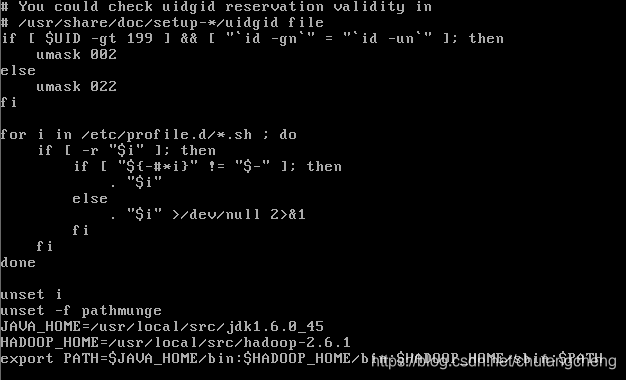
配置JAVA_HOME路径,也可在hadoop安装完成后配置环境
但需注意的是 /etc/profile配置环境文件修改完成后,要输入命令source /etc/profile,更新配置文件
若修改的文件内容有错误,会导致各种linux命令无效,可输入命令/bin/vi /etc/profile,把配置文件改回来。
四. hadoop2.6.1安装与环境配置
进入src文件目录下进行解压,输入命令tar hadoop-2.6.1.tar.gz

注意:解压完成后修改/etc/profile 环境配置文件,即配置JAVA_HOME,HADOOP_HOME,PATH,并更新(命令:source /etc/profile)
随后,在hadoop-2.6.1文件夹下创建临时文件夹tmp,命令mkdir tmp
接下来就是hadoop配置文件的设置,在当前目录下进入 /etc/hadoop/ 文件夹
如果进入不了,就进入全路径 命令cd /usr/local/src/hadoop-2.6.1/etc/hadoop
此时里面有几个配置文件需要修改:masters,slaves, mapred-site.xml, hdfs-site.xml, hadoop-env.sh, core-site.xml, yarn-site.xml,共七个文件。
1.编辑文件vi masters ;
编辑内容master;
2.编辑文件vi slaves ;(本文集群为一主一从)
编辑内容slave1;也可以换行增加
3.编辑文件vi mapred-site.xml,;
编辑内容如下:

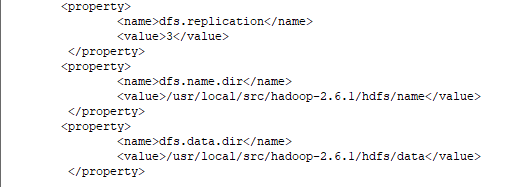
4.编辑文件vi hdfs-site.xml
编辑内容如下:
5.编辑文件vi hadoop-env.sh
编辑内容:
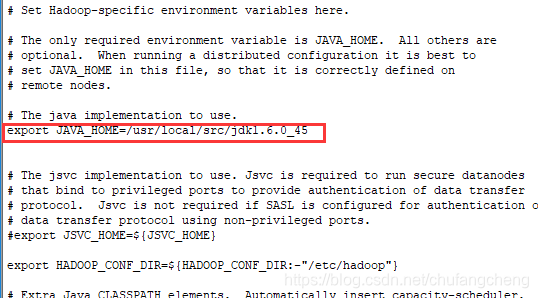
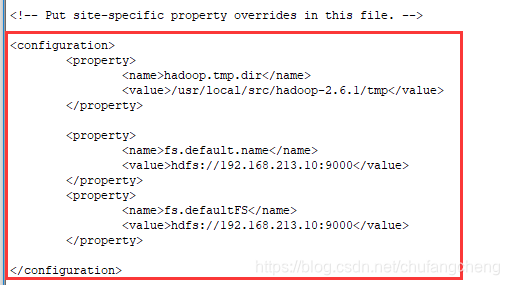
6.编辑文件vi core-site.xml
编辑内容:
7.编辑文件 vi yarn-site.xml
编辑内容:
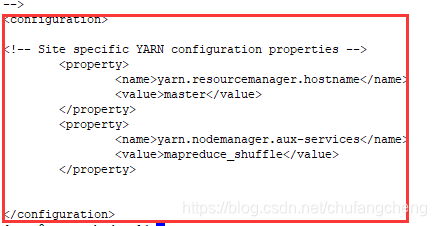
所有文件配置好后,可在/etc/hadoop/文件夹下 输入命令ls -rlt,查看已修改的文件
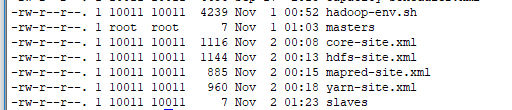
五. 启动Hadoop
1 启动之前要先格式化namenode节点, 执行命令:hadoop namenode -format
2 进入/hadoop-2.6.1/sbin/文件夹
执行命令:./start-all.sh 启动hadoop
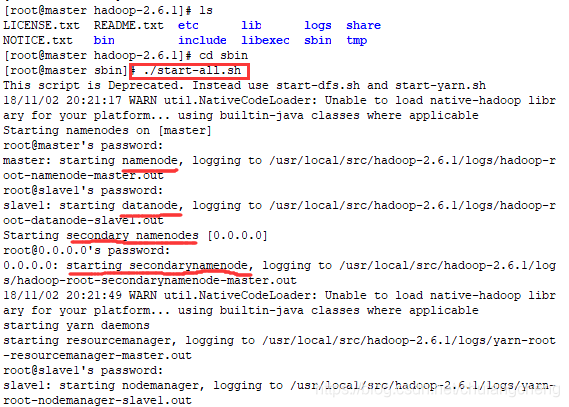
提示: 一般不建议用上述命令启动,可以start-dfs.sh和start-yarn.sh来启动HDFS系统和Yarn计算进程
启动完成后,输入命令jps查看进程是否正常启动

欢迎大家提出问题并指正,继续改善,谢谢。