零、目录

一、背景介绍

深度学习驱动以上应用落地。
1.1 花卉识别手机APP
通过手机摄像头拍照后进行花卉识别。
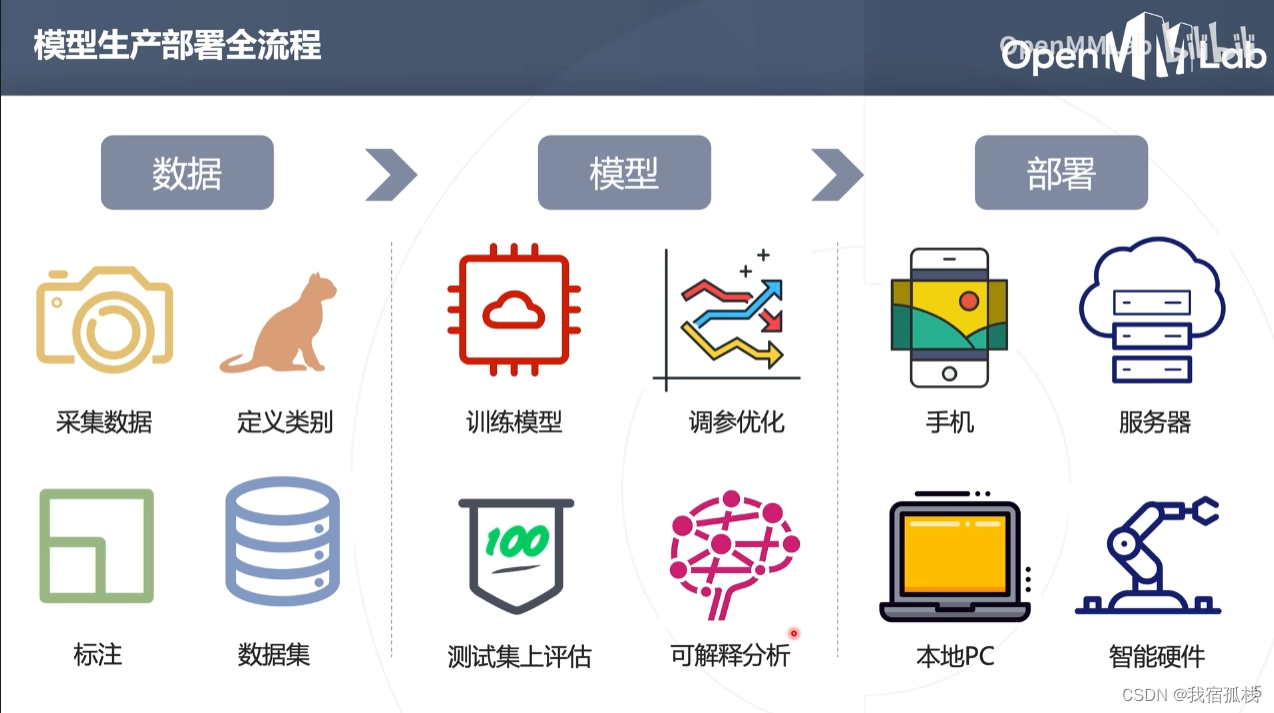
- 第一步:数据收集
- 第二步:训练模型
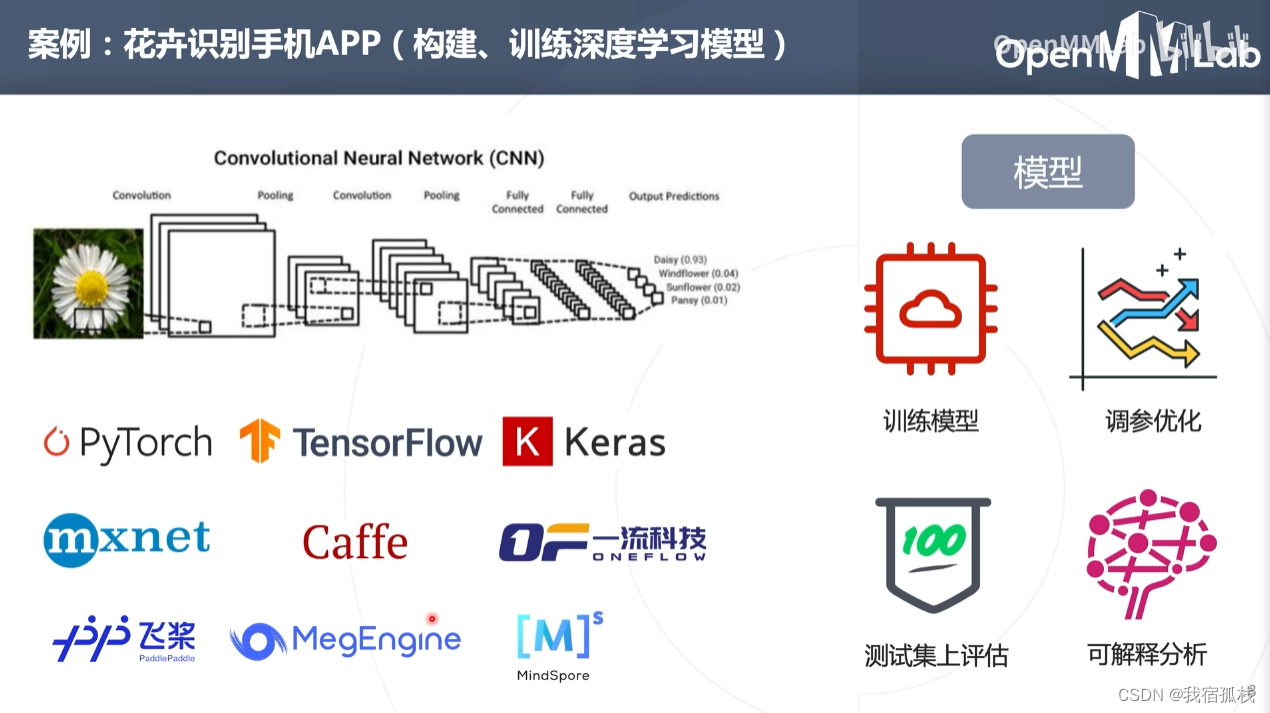
- 第三步:模型部署

1.2 模型部署概念
模型部署核心问题:如何把训练模型高效地运行在软硬件平台下,对输入数据进行推理得到预测结果。
花卉识别案例:把训练好的花卉识别模型移植到手机环境中运行,对输入花卉图像进行推理预测。
实质:把模型计算的前向过程针对硬件特点进行优化、加速通过代码实现,比如矩阵乘法在cpu、gpu和dsp中的实现方式便各不相同。
前向计算过程+模型前处理+模型后处理即可得到一个推理SDK模型,类似OpenCV可以直接调用。
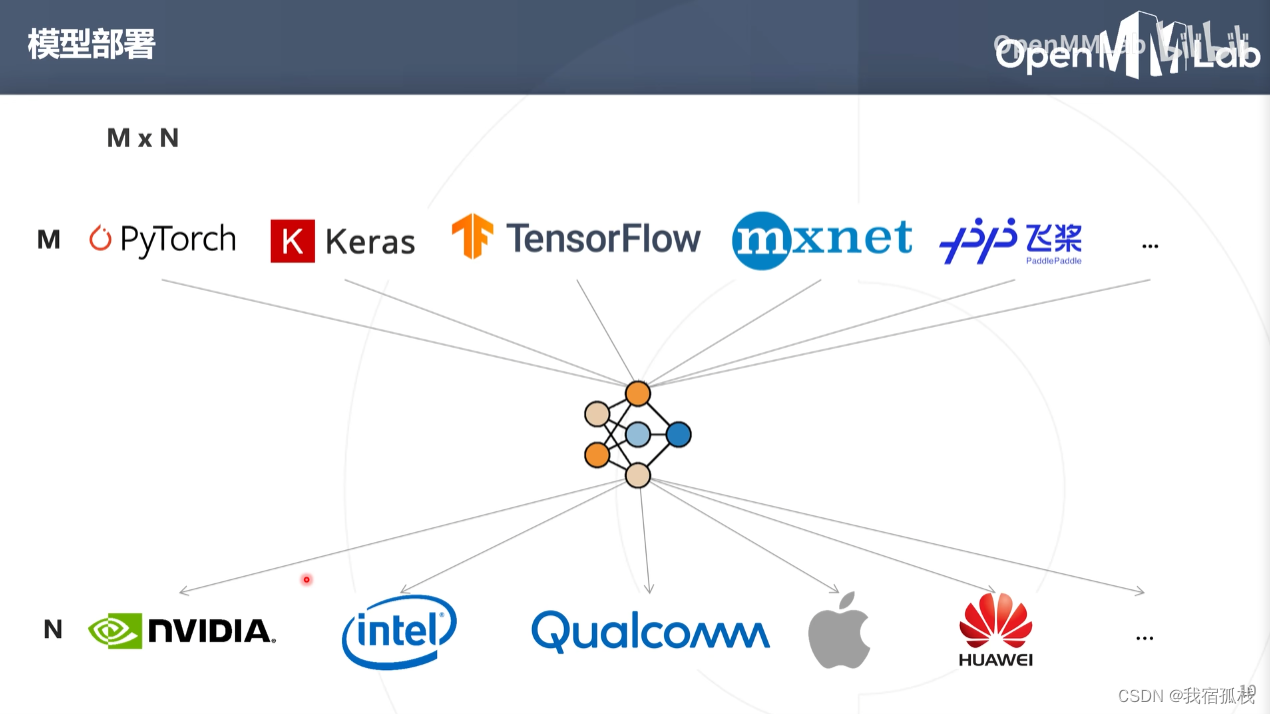
深度学习框架的不一致,导致模型部署复杂度高。
M个深度学习框架部署到N个环境中,需要部署M*N个。


引入统一的网络框架模型格式:ONNX。
模型部署个数即可变为:M+N
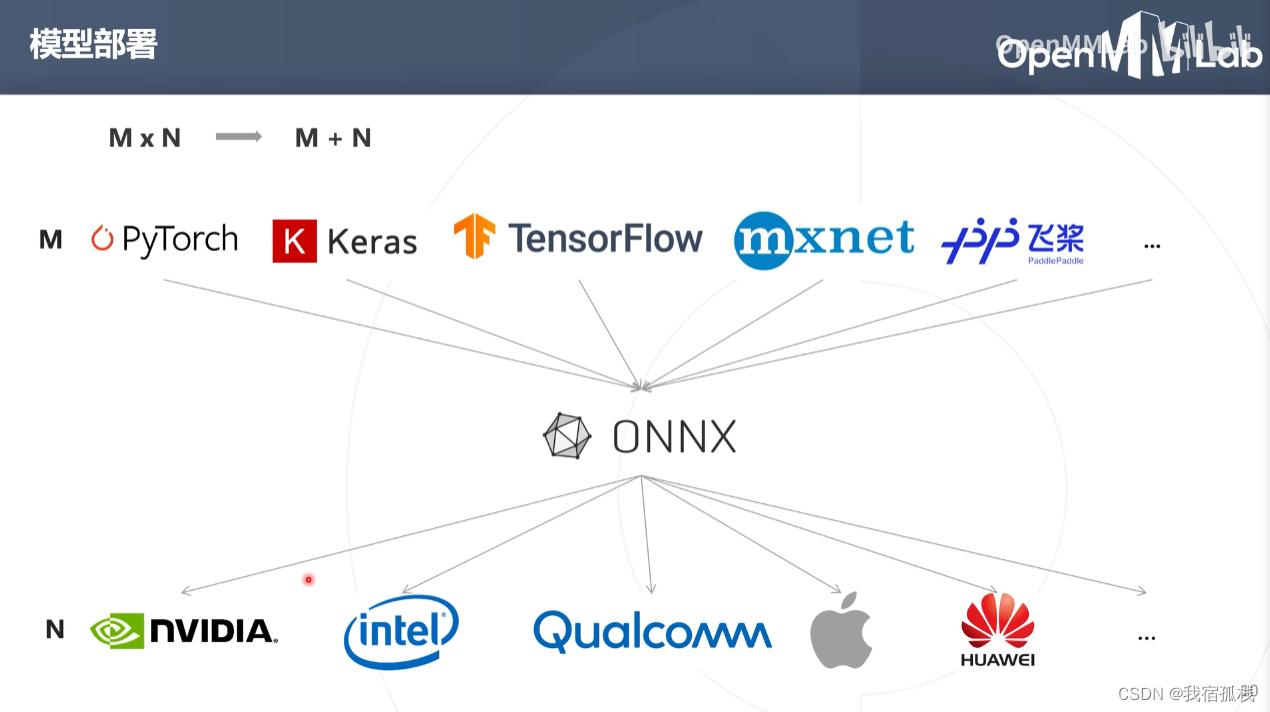
ONNX属于文本而非程序,无法在硬件设备中直接运行,需要软件栈加载ONNX模型使其可以在硬件设备上进行高效地推理。
软件栈即为推理框架(引擎)。
推理框架可分为两类:
厂家自研:比如NVIDIA的tensorRt。这类框架优点在于可充分发挥自家芯片的能力,获得更好的推理性能,缺点在于不具备普适性,无法用到其他芯片中;
通用框架:比如ONNX RUNTIME,其主要特点具备普适性,可运行在不同的软硬件平台下。对用户最大的好处是可降低开发难度提升开发效率,因为不用关心底层硬件差异只需关注框架本身的应用接口即可。

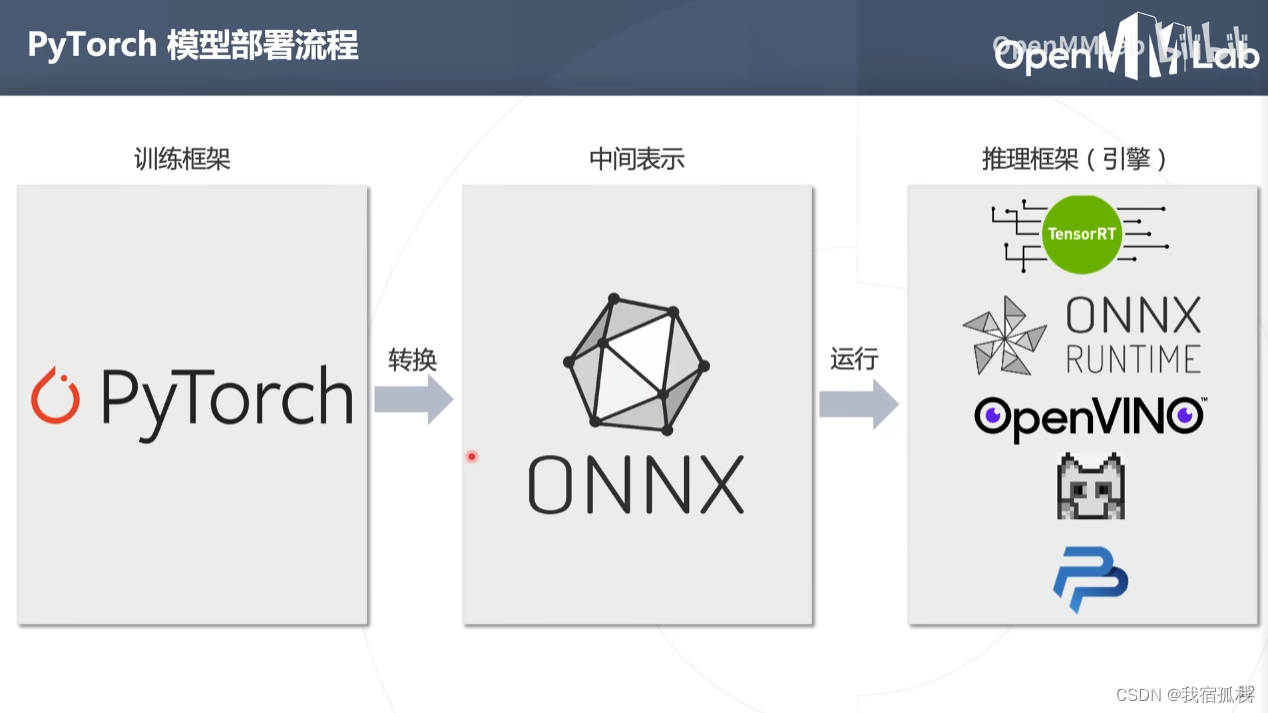
综上可得pytorch模型部署流程。
二、ONNX模型格式

2.1 LeNet例子
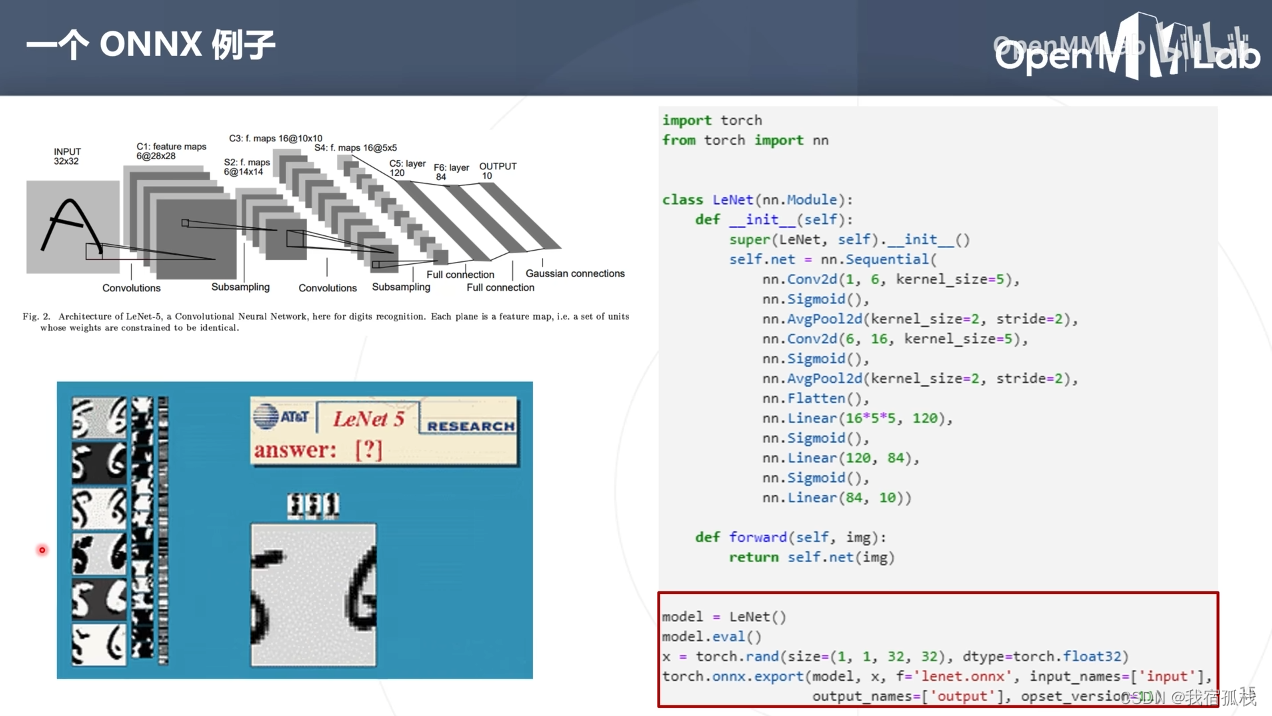
-
step1:根据网络结构构建LeNet;

-
step2:转换为onnx格式。
首先生成一个LeNet模型对象model,调用eval()函数,随机生成一个torch.tensor,最后调用torch.onnx.export()将model转换为lenet.onnx。
2.2 查看onnx结构
浏览器打开netron.app,再将生成的onnx文件拖至此处即可查看。
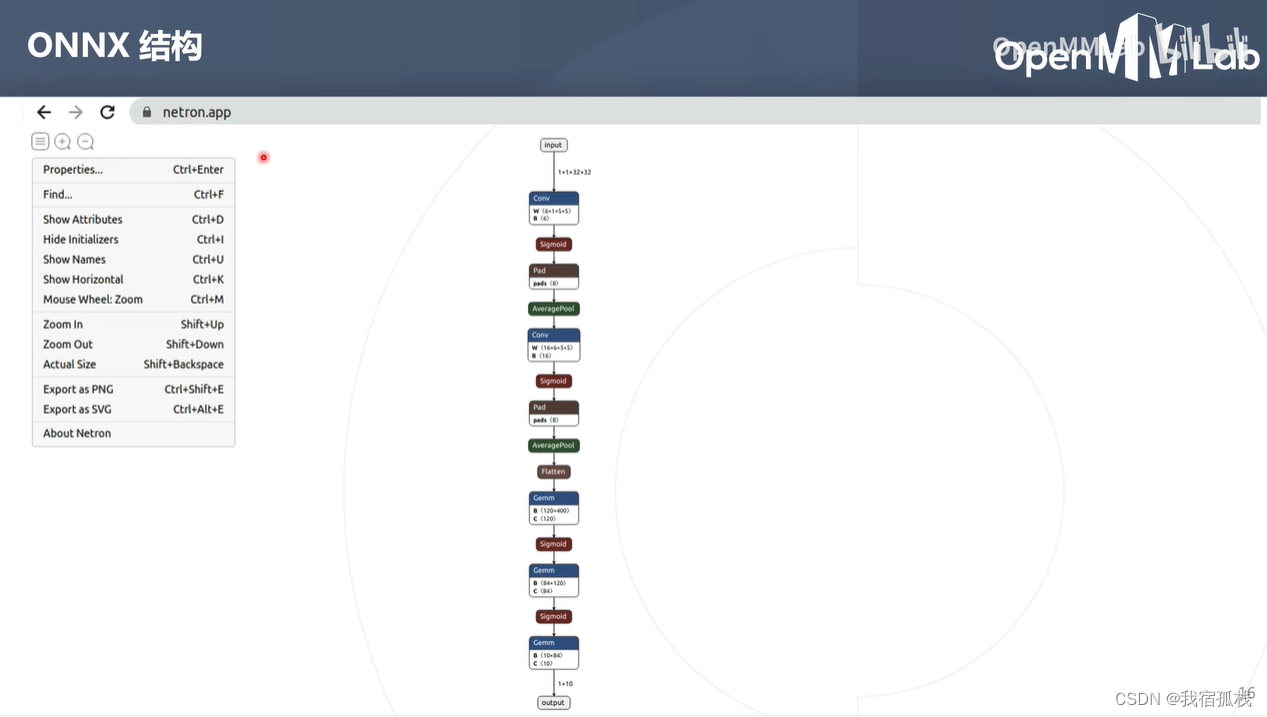
onnx模型:有向的无环图。
- 图中节点称为算子,描述的是计算(比如conv、sigmoid都是具体的算子)。所有的算子集合称为一个算子集。
- 图中边表示节点的计算顺序,以及数据流向。
- 对比pytorch模型:除了在average pooling节点多了一个pads,其余均可一一对应。
查看onnx属性信息:
点集properties:
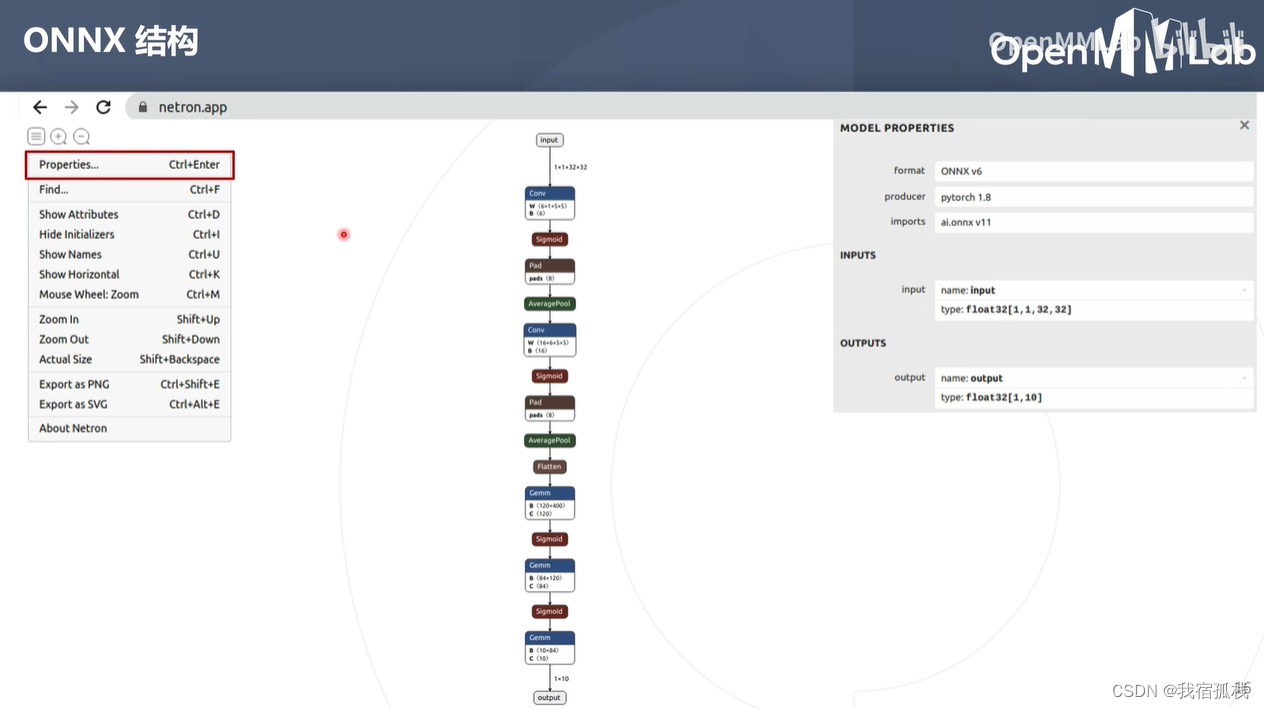
format:onnx遵循版本。(此处为v6)
producer:生成onnx的框架。(此处为pytorch1.8)
imports:onnx用到的算子记忆。
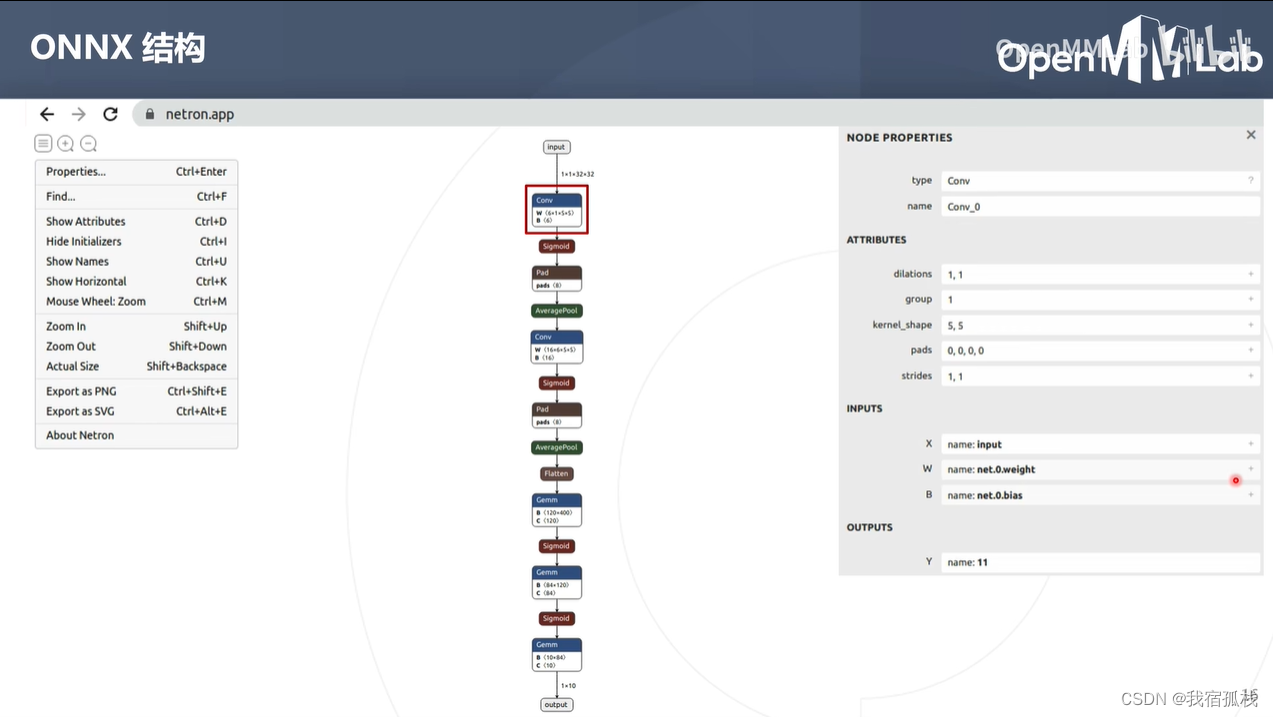
点击某个节点:查看节点详细信息
conv节点
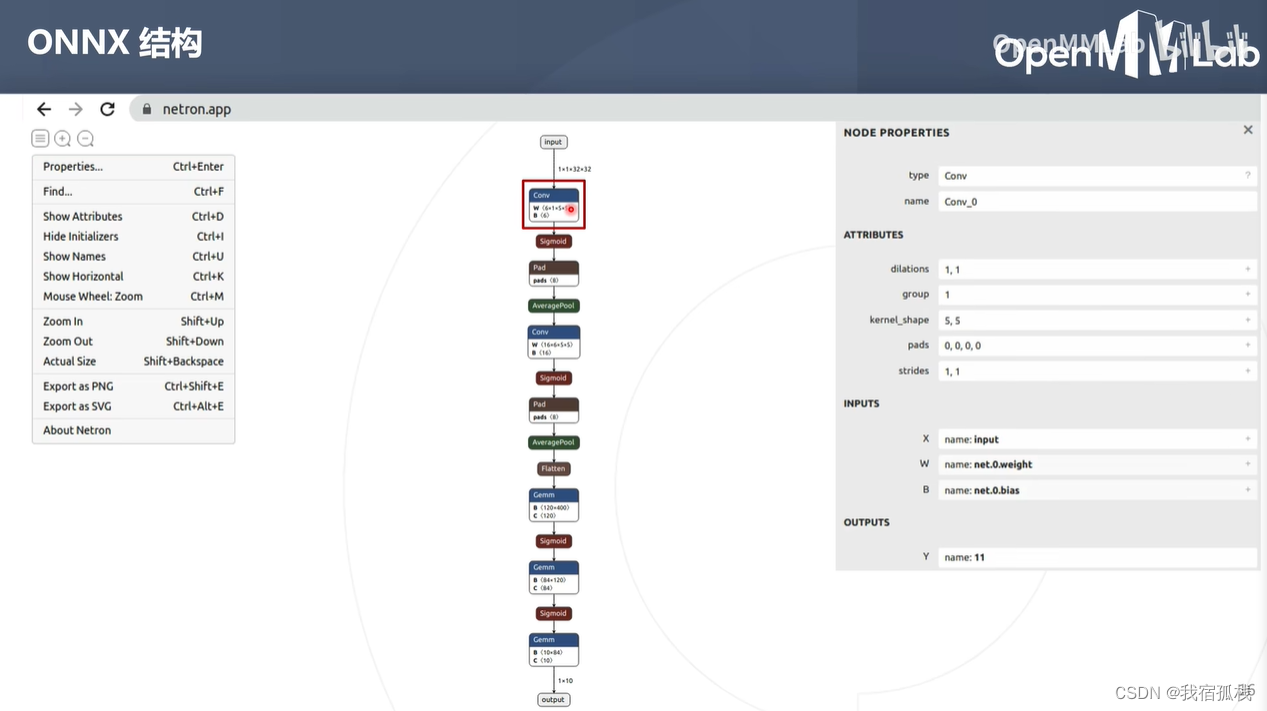
节点信息主要包括两个部分:属性信息+图结构信息
属性信息:记录超参数,比如卷积核大小(5,5)、卷积步长(1,1)
图结构信息:算子的类型(conv)、名称(conv_0),输入(3个输入tensor:网络输入input、自身权重、偏差),输出。
点击右侧+号可查看tensor的具体值。对于构建模型时没有给初值的权重,这里的显示便为随机值。
sigmoid节点:
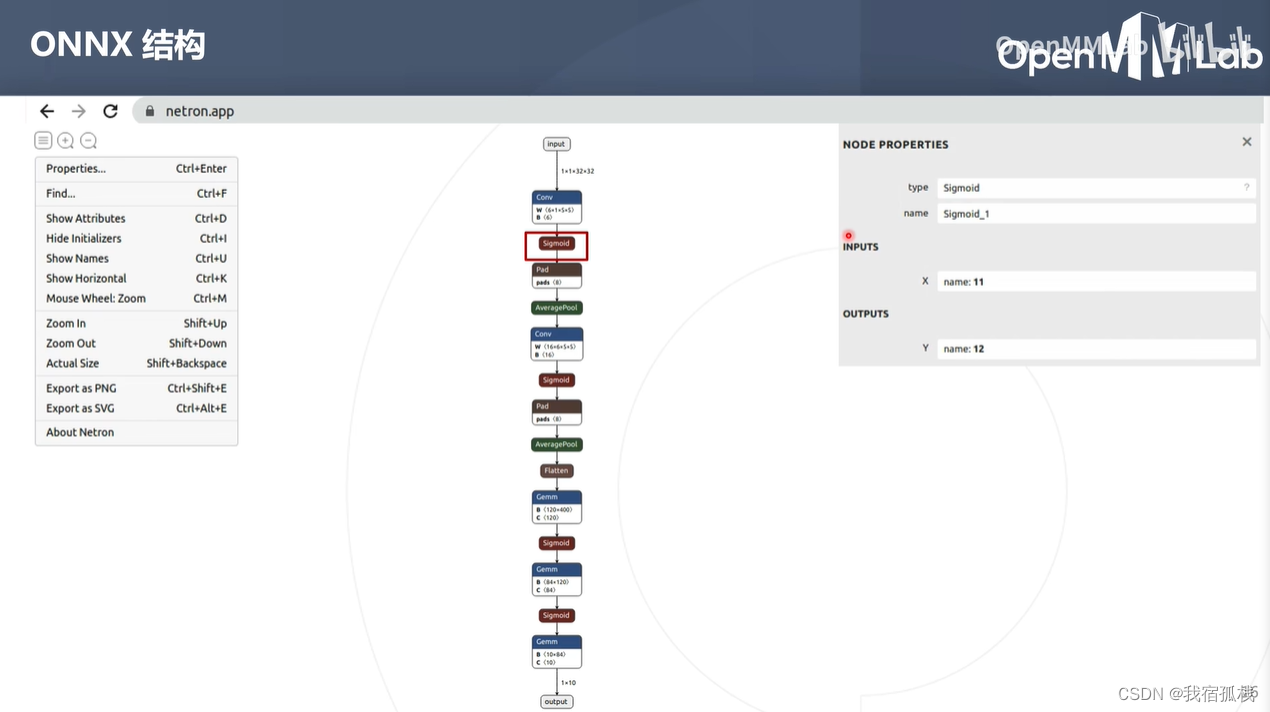
sigmoid节点没有属性信息,因为sigmoid并没有超参数。
2.3 onnx算子
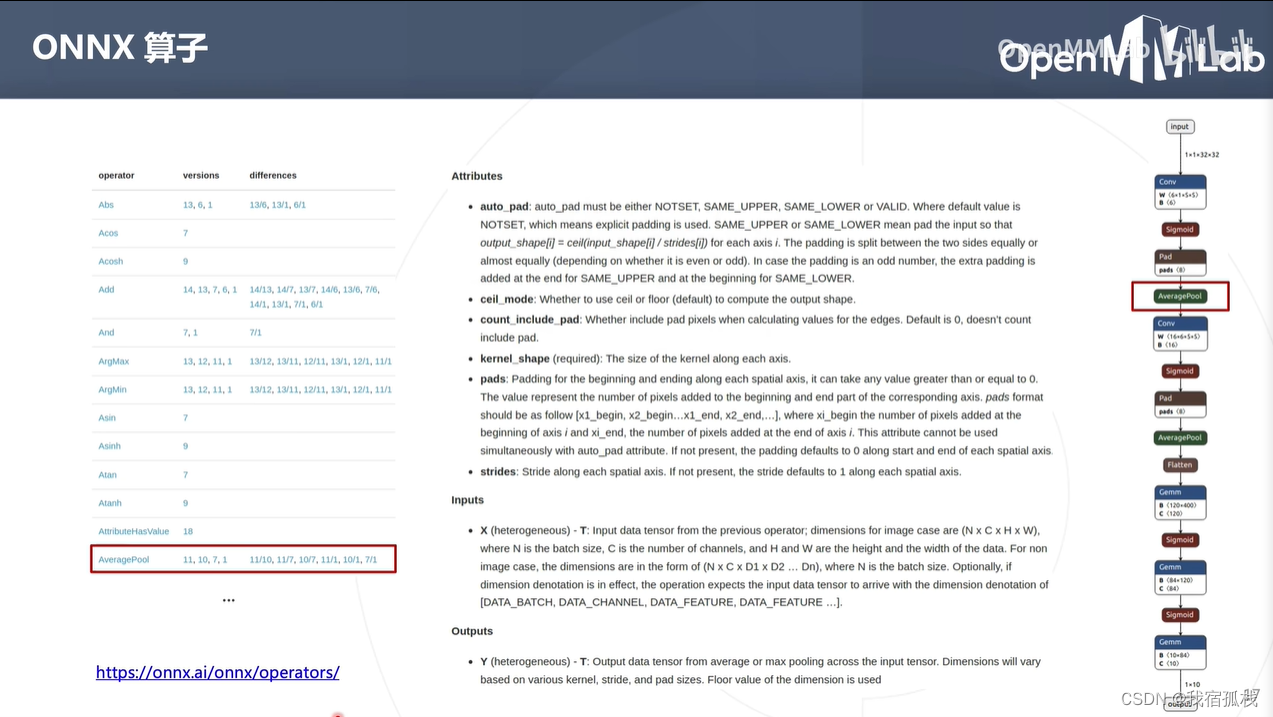
访问左下角链接可查看所有算子定义。
例如AveragePool:onnx中pads是一个list结构,pytorch中padding是一个正数而非list,所以torch在到处onnx模型时都会在AveragePool前增加一个pads节点。
2.4、重点总结梳理:
- torch.onnx.export()得到onnx模型;
- netron.app查看onnx结构(onnx整体结构、算子属性信息和输入输出信息);
- 了解算子集(http://onnx.ai/onnx/operators/)
三、pytorch模型部署示例
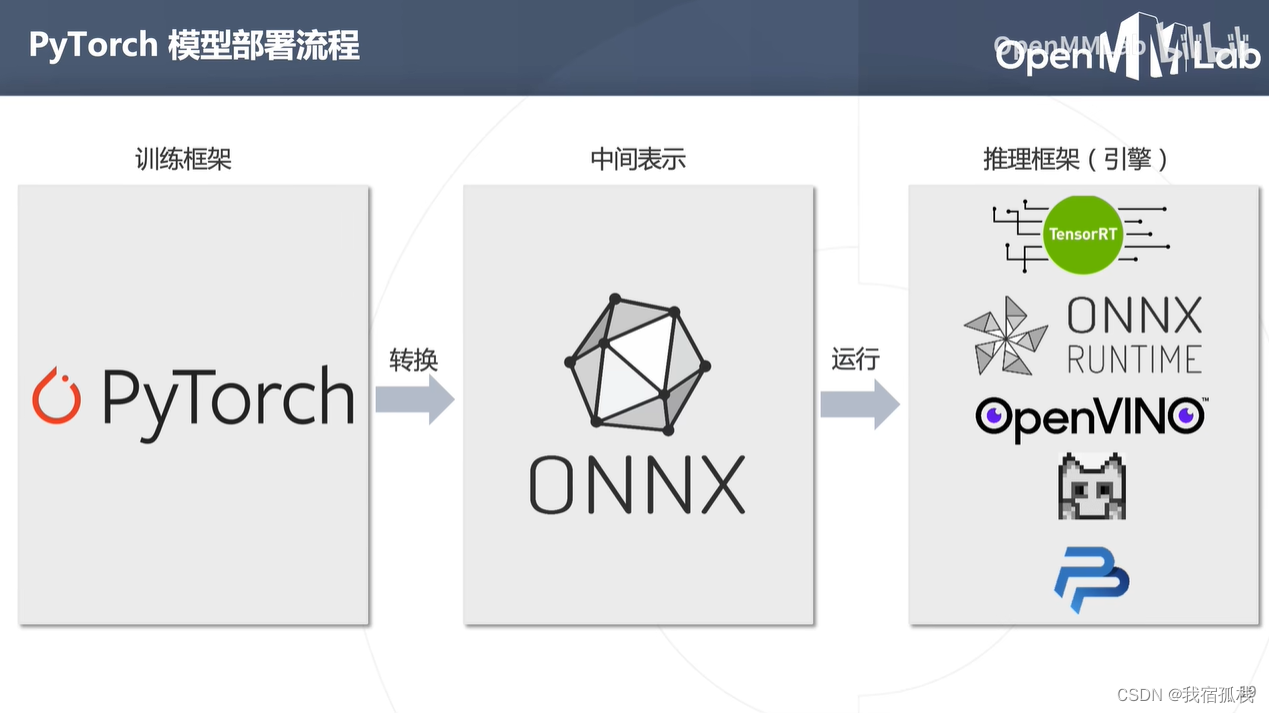
首先将pytorch模型转换为onnx模型,再通过推理框架将onnx运行在特定设备进行高效推理。
3.1、 ResNet部署在NVIDIA显卡
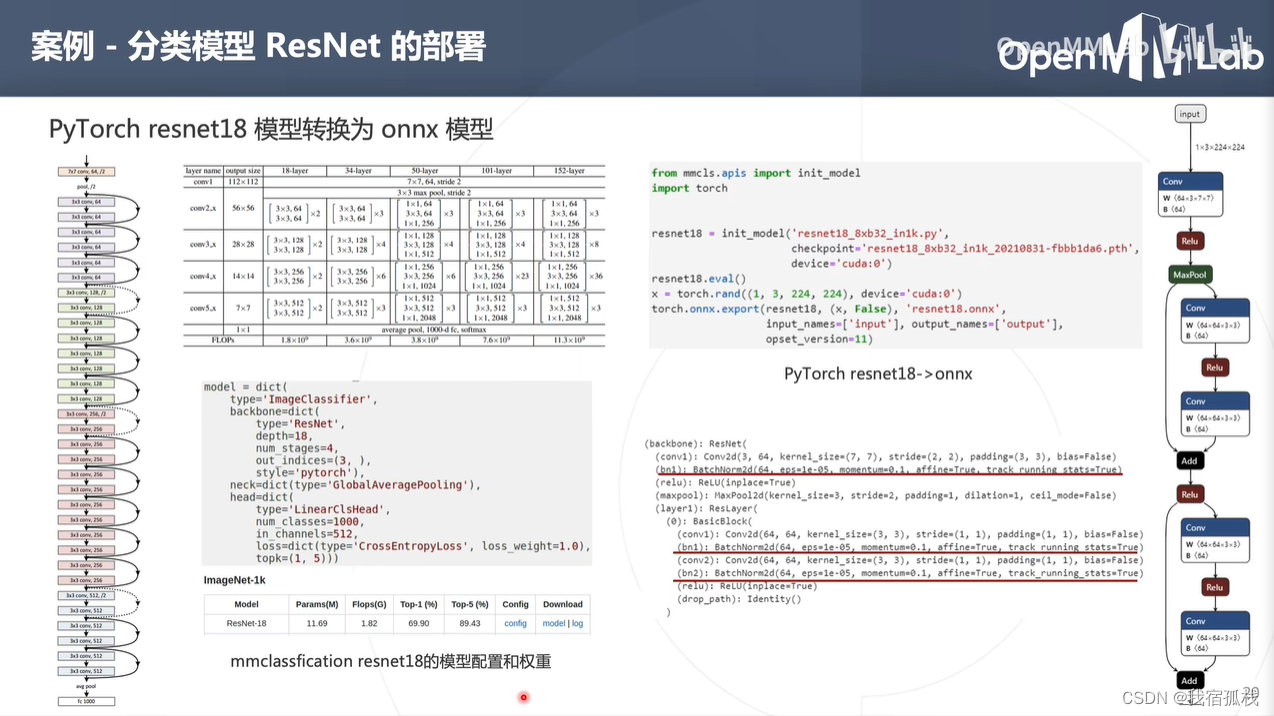
3.1.1 构建onnx模型
step1:构建ResNet模型
调用mmcls.spis中的init_model可直接构建ResNet模型,传参为(模型配置文件、权重、设备标识)
step2:pytorch模型转为onnx模型
调用eval();随机生成一个tensor-x(shape和模型输入大小保持一致即13224*224);调用torch.onnx.export()将ResNet18转换为onnx模型存为resnet18.onnx。
step3:将resnet18.onnx拖拽到netron.app可查看其结构。
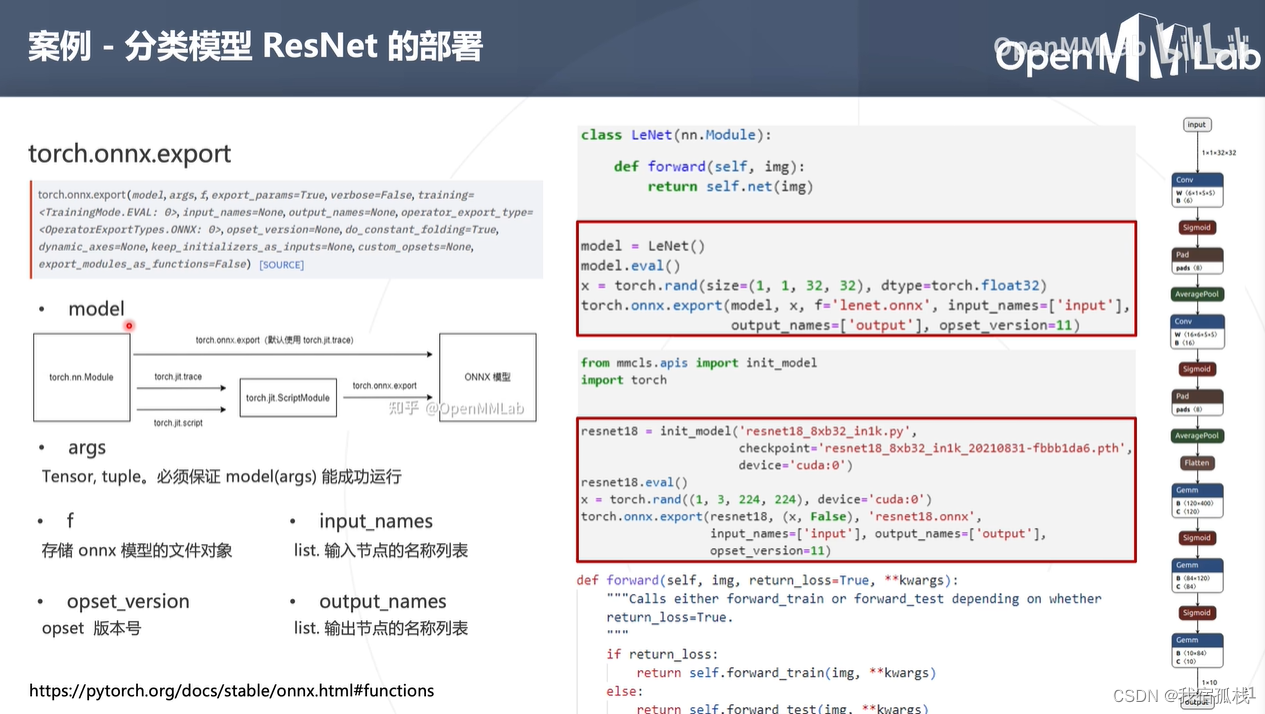
model:pytorch模型,torch.nn.Module对象;
args:模型输入,可以是tensor、tuple,必须和model的forward参数列表保持一致(LeNet中为一个tensor,故args为一个tensor;ResNet中为一个tensor+bool变量,故args为(x, false),此处给FALSE是因为要执行forward_test而非forward_train)
f:存储onnx模型的文件对象;
input_names/output_names:输入/输出tensor的名称列表
3.1.2 部署推理引擎
得到onnx模型后,选取可以在NVIDIA显卡上工作的推理框架。
此处选取两个框架:通用的ONNX Runtime以及NVIDIA自研的TensorRT。
ONNX Runtime部署
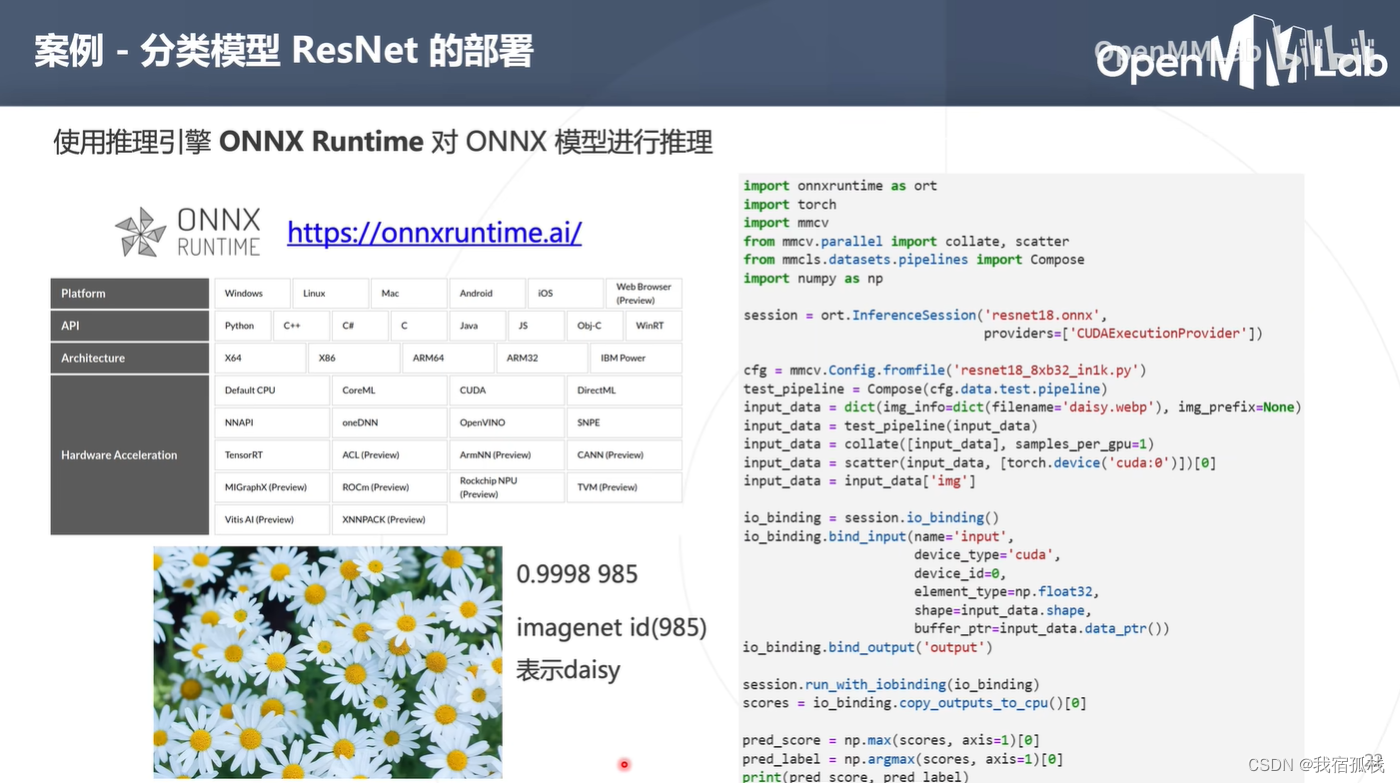
ONNX Runtime:由微软维护的一个跨平台推理引擎,可以直接加载并运行onnx模型。其跨平台性体现在它支持不同的操作系统,cpu架构以及AI加速设备等。
核心工作:调用onnxruntime的api加载resnet18.onnx对输入图像进行推理得到预测结果。
此处给的例子是Python api的使用案例。
- step1:创建session,加载onnx模型。
设备为cuda显卡,此处provider便设置为‘CUDAExecutionProvider’ - step2:输入图像预处理(图像缩放裁剪等)
- step3:绑定模型的输入输出tensor,把step2中预处理好的数据作为模型的输入tensor;
- step4:执行run()函数(即推理过程)
- step5:把run()函数推理结果copy到cpu进行后处理(此处后处理是从推理结果中选取分数最大的及其对应的标签ID)。
上图中小雏菊的图作为输入执行右侧代码输出为:0.9998 985,表示其分数为0.9998,类别ID为985。
TensorRT部署
如果是在NVIDIA中工作,首推为NVIDIA自研的推理引擎TensorRT。
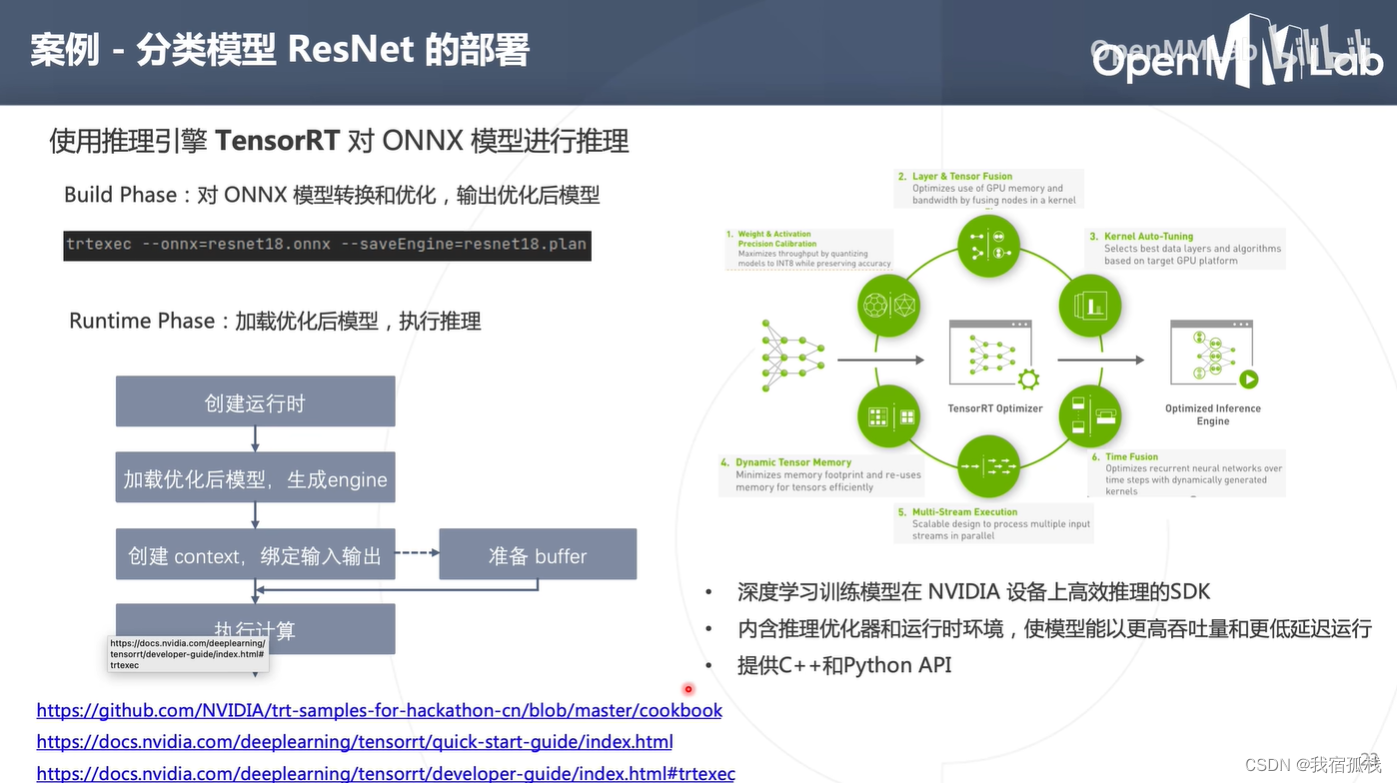
两个阶段:构建阶段(build phase)+运行时阶段(runtime phase)。
- Build Phase:TensorRT解析onnx模型并进行多项优化(包括模型的量化、融合和自动选择最合适的计算kernel等等),最终输出为一个优化后的模型;
TensorRT为build阶段提供了C++和Python的api(此处为方便,选择一个可执行程序trtexec来完成tensorRT的构建工作),左下角连接为TensorRT的相关api文档。
执行trtexec --onnx=resnet18.onnx --saveEngine=resnet18.plan即可将pytorch的resnet18.onnx模型转换为tensorRT模型。(输入onnx模型的路径以及输入tensorRT模型的路径)。
- Runtime Phase:加载转换好的tensorRT模型,对输入数据进行推理。
TensorRT为runtime阶段提供了C++和Python的api(相对onnx runtime,tensorRT的api内容较多且复杂)。
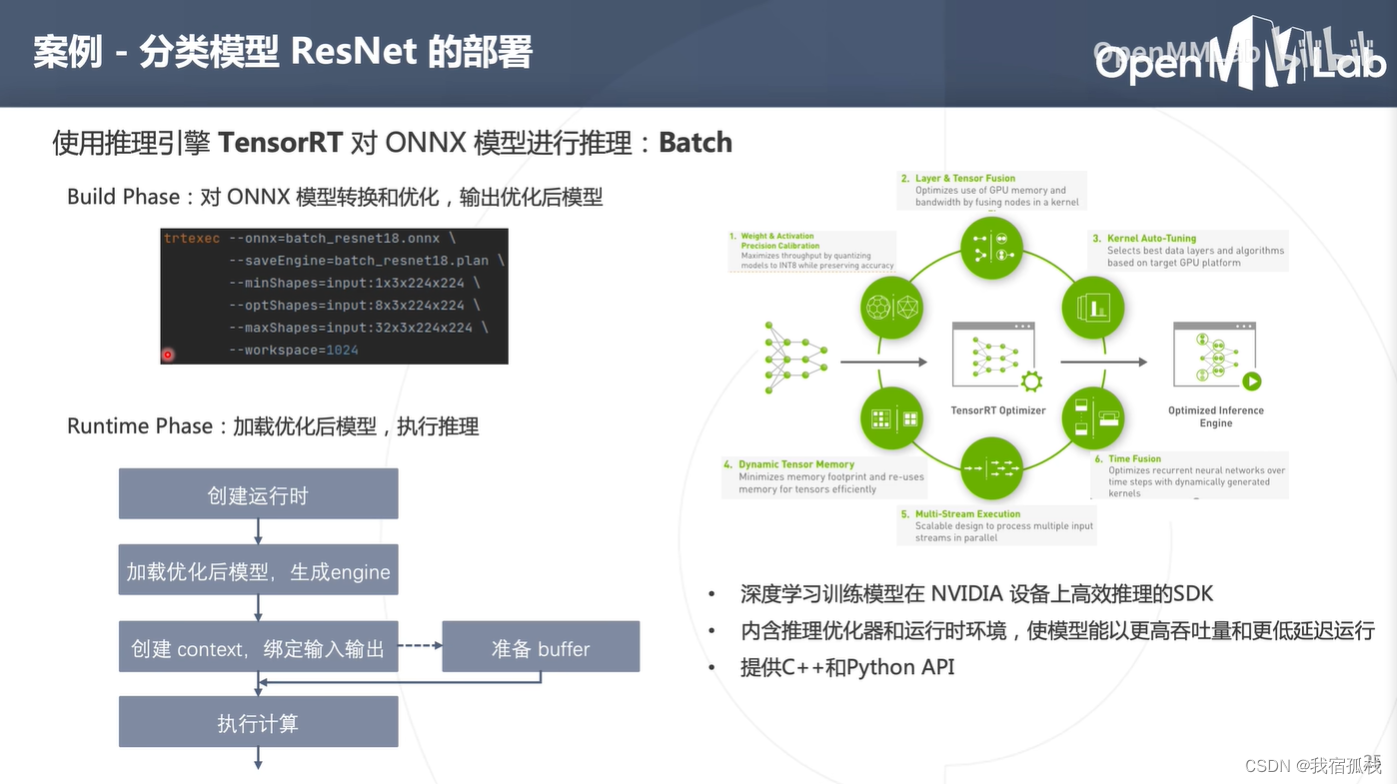
以上演示例子都是对单张图片进行推理,数据类型为浮点数,不能发挥硬件的能力。一般来说,使用批处理以及低精度的模型推理效率可得到较大提升。
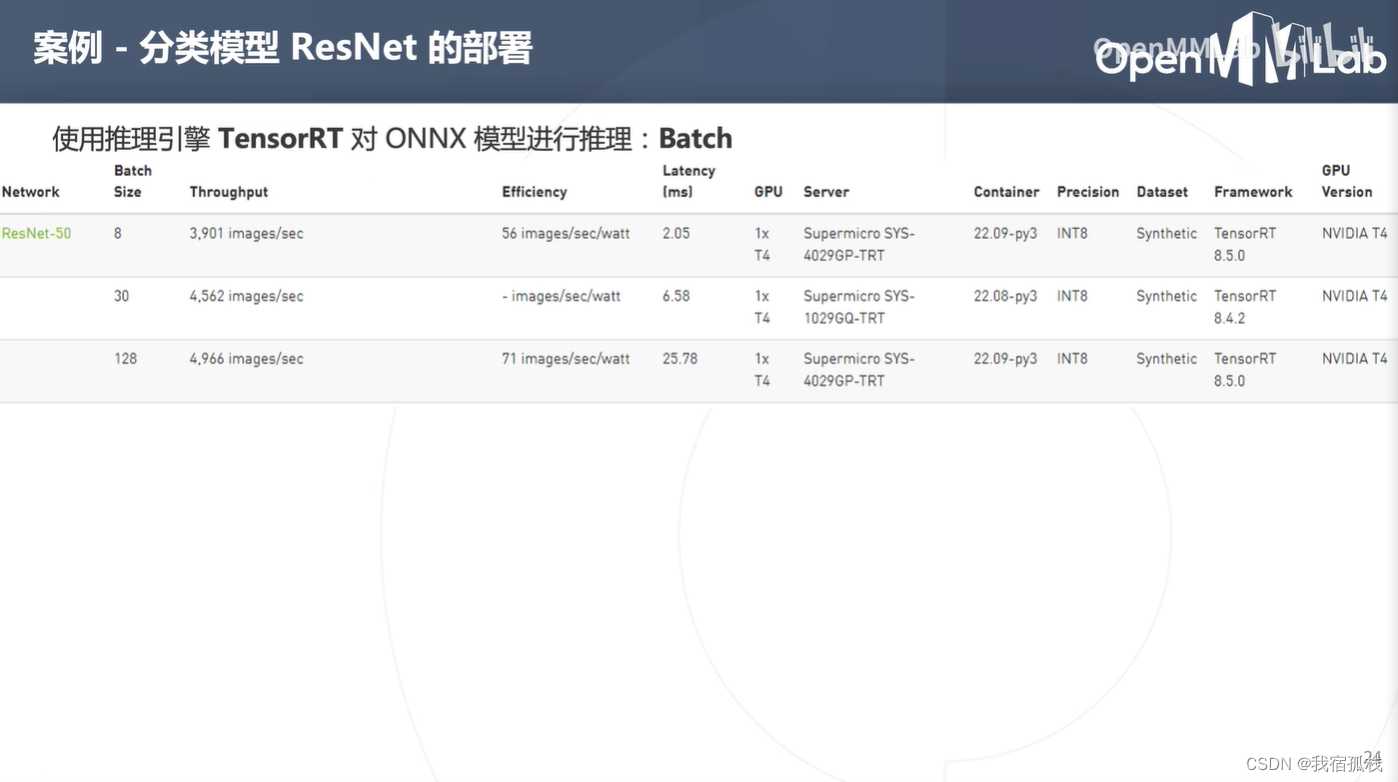
上图中ResNet-50在T4设备中,在相同计算精度下,推理吞吐量会随着batch size的增加而增加。
tensorRT如何进行批处理?
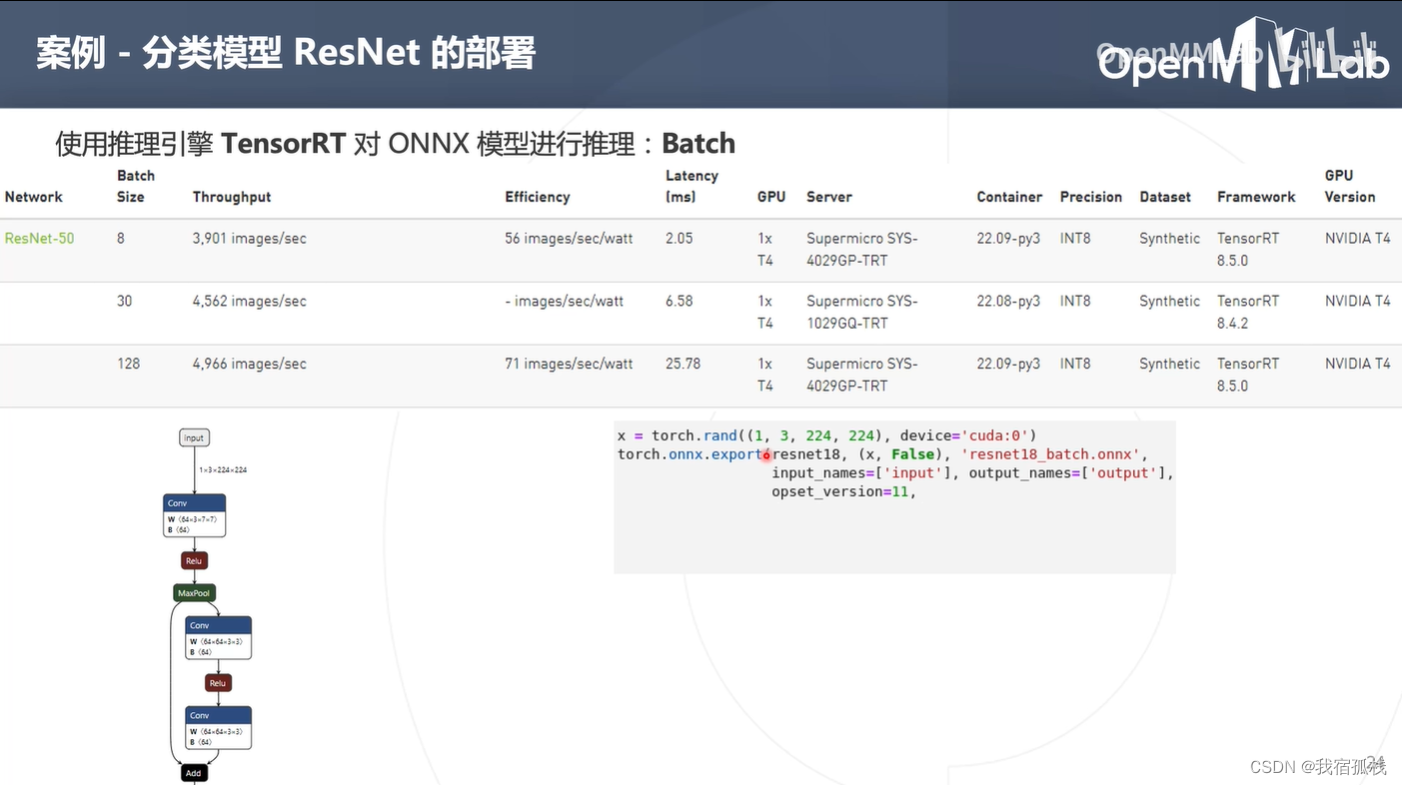
x = torch.rand(1, 3, 224, 224)中的1表示其batch固定为1,代表着onnx模型再推理的时候一次只能处理一张图片。
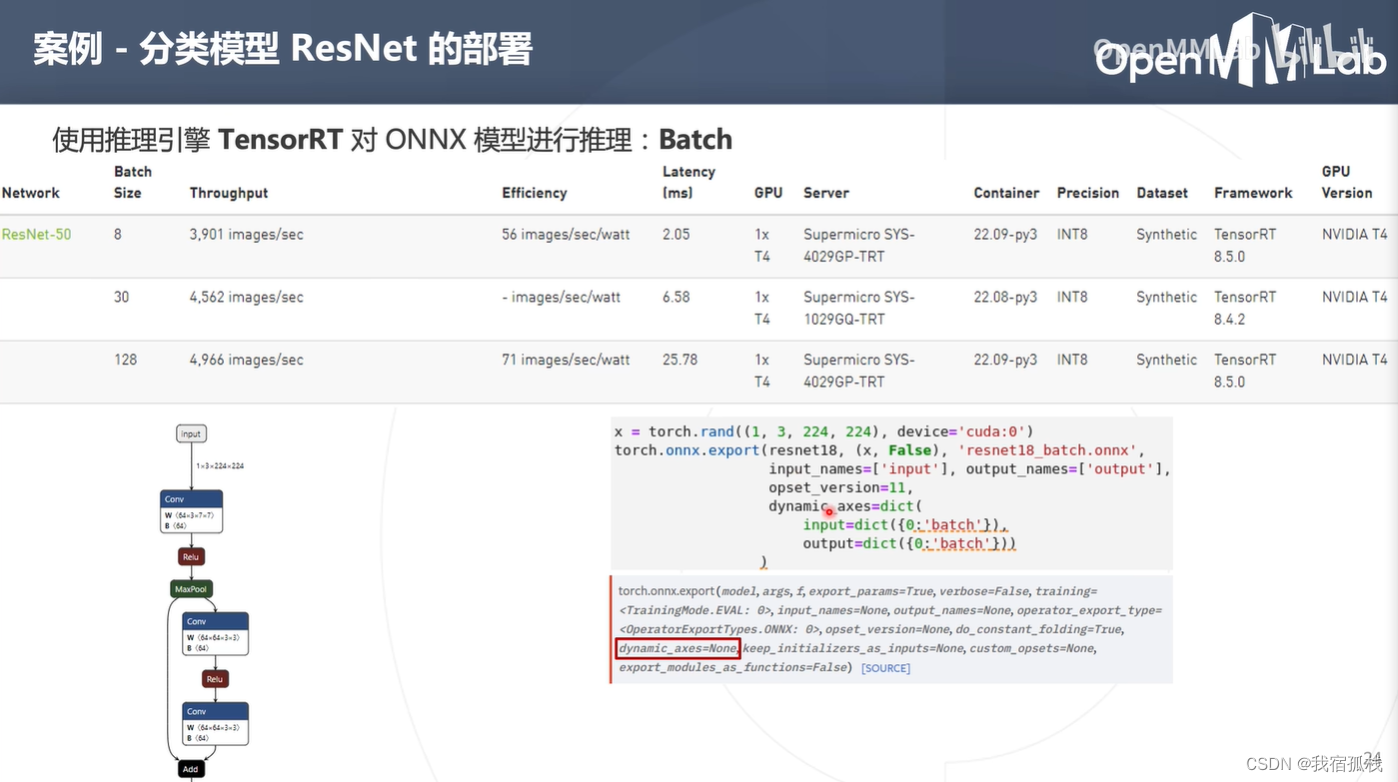
如果想实现批处理,就必须让输入onnx模型的batch维度是可变的(动态的),即在转换onnx模型的时候增加一个参数dynamic_axes(表示模型输入的input第0维是动态的,输出tensor第0维也是动态的)。
修改好执行完毕后即可得到一个支持动态shape的onnx模型,此时在netron.app中查看其结构,input的第0维由原来的1变为了一个动态的参数batch,也就意味着可以在一个batch中批处理多张图片,即图中的8、30、128。
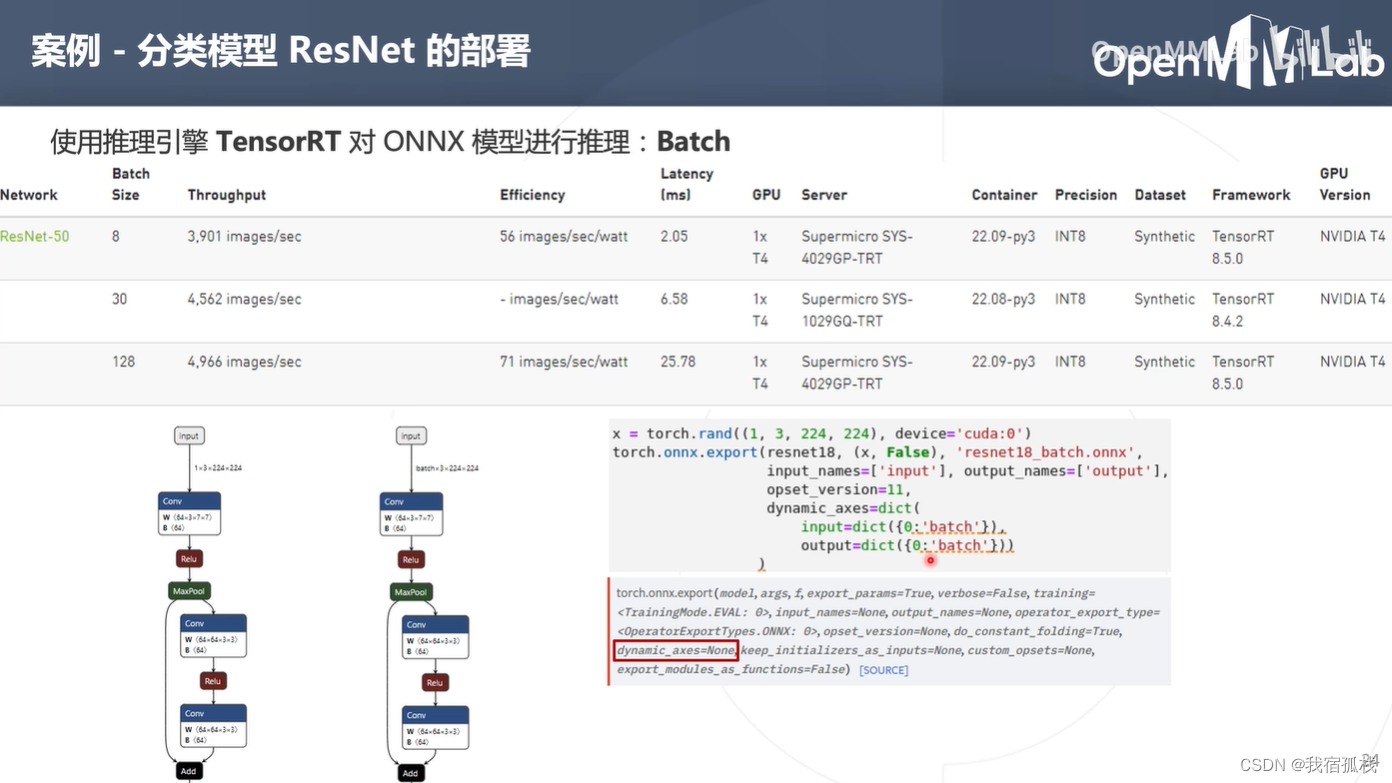
对比静态一次处理一张图片的tensorRT bulid阶段,批处理需要多加几个参数:minShapes(输入tensor的最少shape:1)、optShapes(输入tensor的最优shape:8)、maxShapes(输入tensor的最大shape:32)。一个batch中最多可放32张图;runtime阶段区别在于buffer阶段无须一张一张图片输送,可以batch实现。
tensorRT进行加速:量化
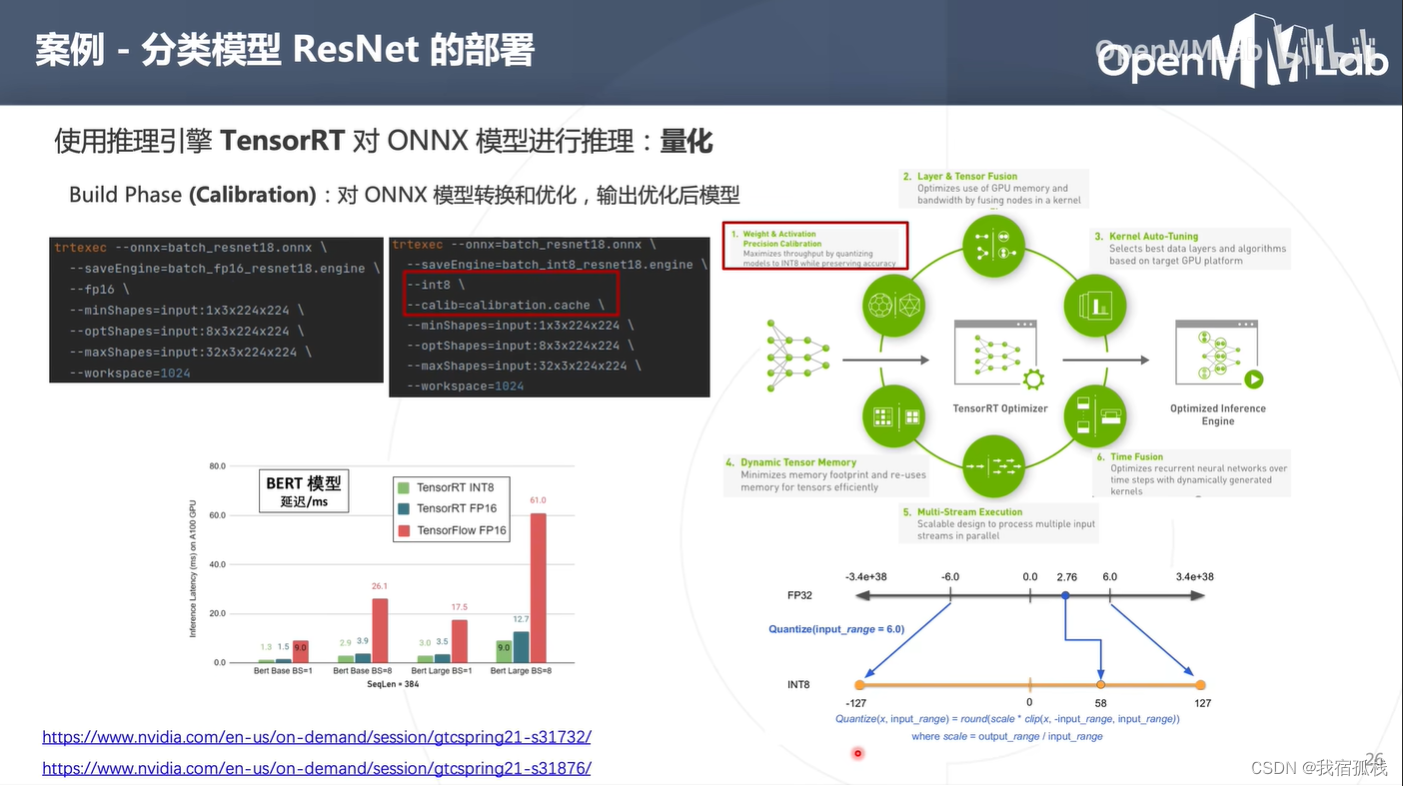
将低精度量化为fp16,int8或者int4时,通常不会有太大精度损失。
直接使用参数‘–fp16’即可将低精度量化为fp16。一般量化的时候都是int8或者更低比特的量化。
量化:把模型的权重以及算子的输入输出tensor由浮点变为int8的定点。
量化的2种方式:训练后量化(post training quantization,pdq)和训练时量化(quantization aware training, qat)。tensorRT均支持。
int8量化:
此处关注训练后量化。训练后量化是拿到onnx模型后再进行量化,上图右下角即为一个量化原理图。
图中为对称量化,取其一个数值区间(-6~6)映射到int8的-127到127,可得到一个缩放系数s,s即为一个量化的系数。
上图中量化系数s=127/6,例如2.76量化即为:2.76*127/6=58。
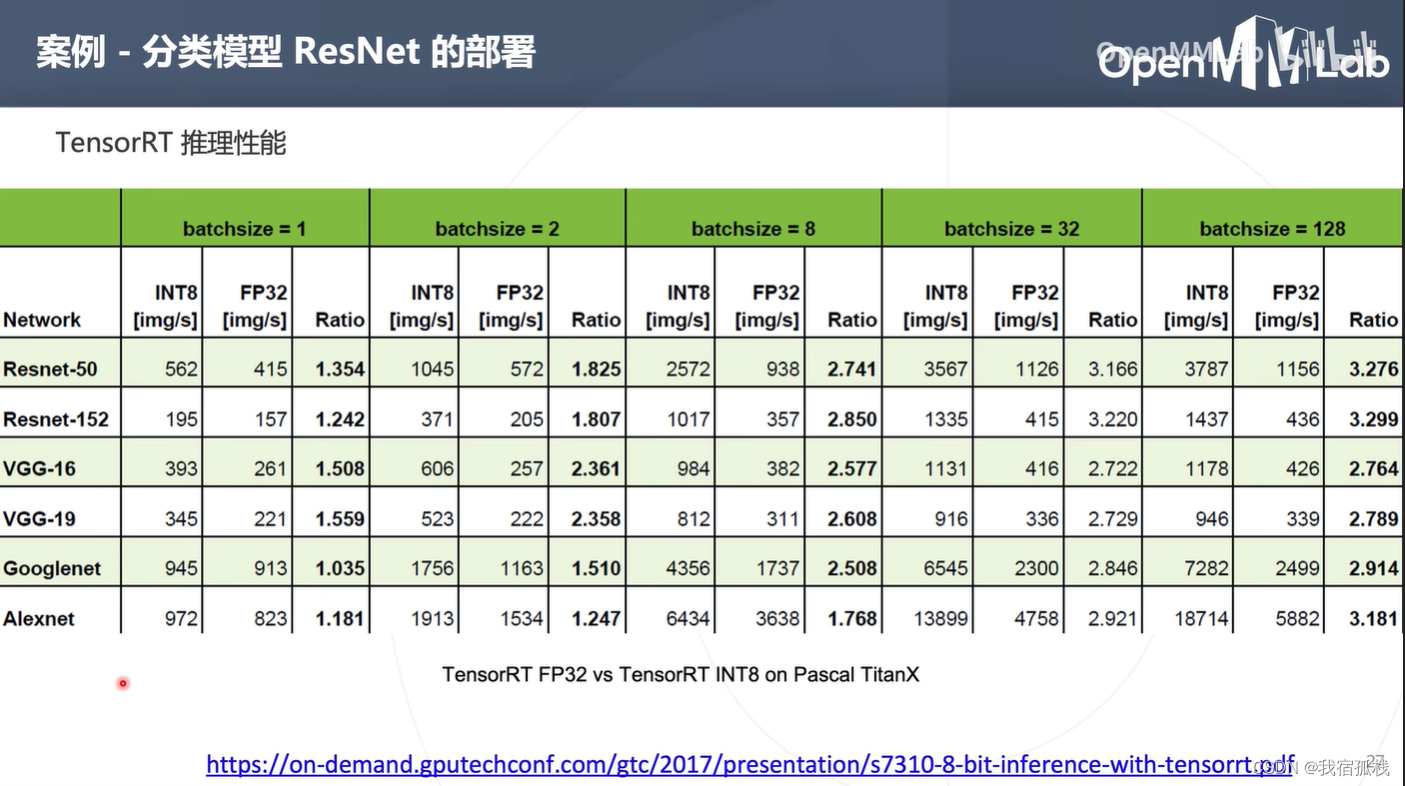
上图可知:相同batchsize下,量化可提升推理性能;而量化+大的batchsize更可成倍提升推理性能。
四、回顾以及常见问题
- pytorch api中onnx.export()用法、传参,dynamic-axes设置;
- 如何通过onnx runtime在显卡下做模型推理;
- 如何使用trtexec将onnx模型转换为tensorRT模型,以及转换过程中模型的批处理和量化

避免在torch model中使用numpy或Python内置类型:因为numpy和Python内置类型在torch的grt trace过程中会被torch当作常量,相当于输入固定不变了。