文章目录
摘要

随着深度学习技术的不断发展,越来越多的算法库被开发出来,其中MMPreTrain算法库就是其中之一。MMPreTrain算法库是一个强大的工具箱,提供了丰富的模型、推理API、环境搭建软件栈、代码框架、数据流、配置及运作方式等功能,使得用户可以快速构建高效、灵活、可扩展的深度学习模型。
一、工具箱介绍
MMPreTrain算法库是一个轻量级的深度学习框架,支持多种计算加速器,包括CPU、GPU、TPU等。它提供了大量的算法模型,可以帮助用户快速搭建深度学习模型,同时还提供了一系列的工具,如数据增强、数据读取、模型评估等,使得用户能够更加方便地进行模型训练和优化。

二、丰富的模型
MMPreTrain算法库提供了多种经典的深度学习模型,包括卷积神经网络、循环神经网络、Transformer等,同时还提供了一些先进的模型,如EfficientNet、MobileNetV3以及VIT等。这些模型都经过了严格的测试和优化,可以满足不同场景下的需求。同时支持数据增强和可视化分析等。

三、推理API
MMPreTrain算法库提供了多种推理API,包括TensorFlow Serving、ONNX Runtime等。这些API可以帮助用户将训练好的模型部署到生产环境中,以提供高效的推理服务。
支持多种开箱即用的推理任务:
- 图像分类
- 图像描述(Image Caption)
- 视觉问答(Visual Question Answering)
- 视觉定位(Visual Grounding)
- 检索(图搜图,图搜文,文搜图)

四、环境搭建——OpenMMLab软件栈
MMPreTrain算法库提供了完整的环境搭建软件栈,包括操作系统、CUDA、cuDNN、TensorFlow等。用户只需要按照文档的说明进行安装,即可快速搭建深度学习环境。


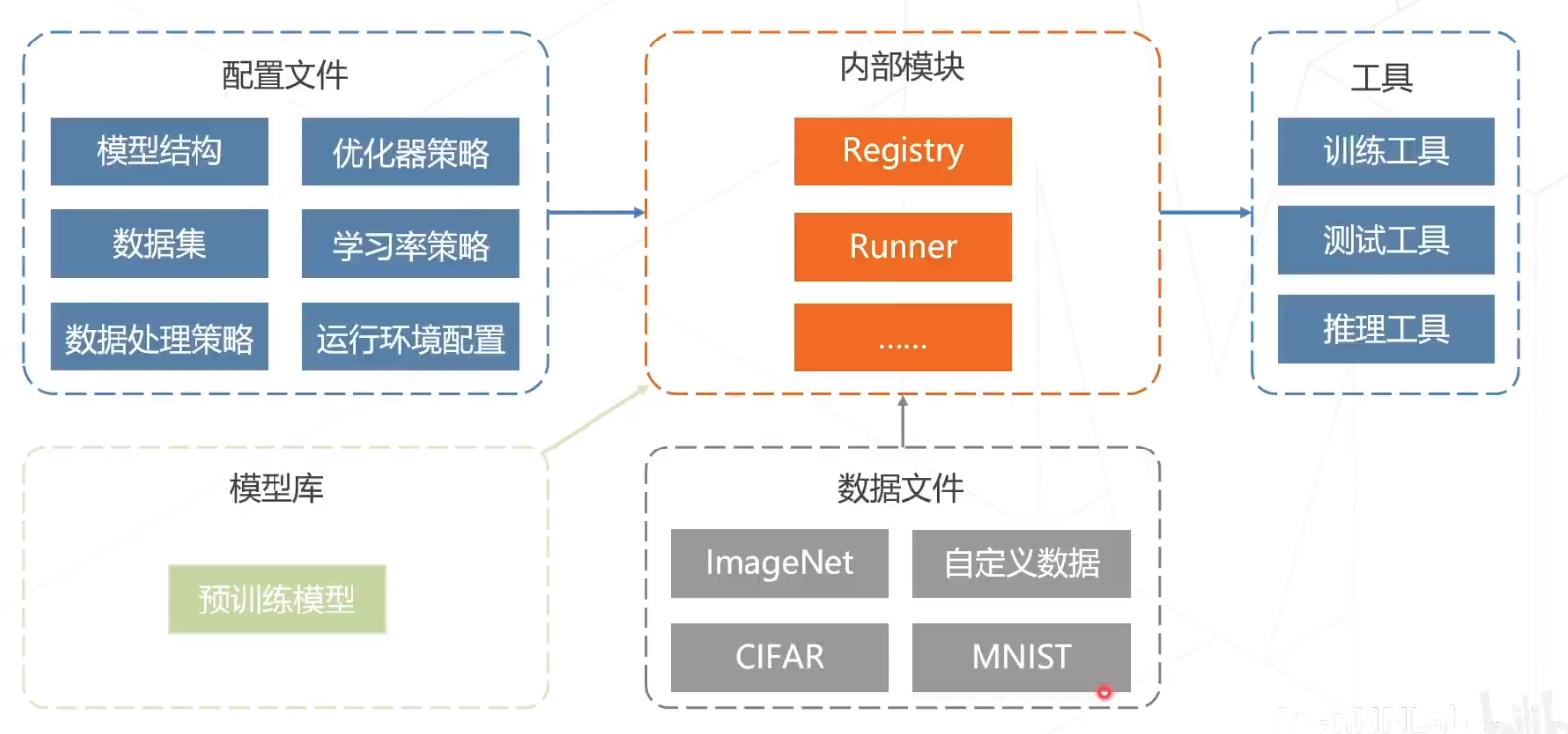
五、OpenMMLab重要概念——配置文件
使用配置文件就可以完成深度学习模型的训练、预测等。配置文件主要包括以下几个方面:

六、代码框架
MMPreTrain算法库提供了完整的代码框架,包括数据读取、数据结构的定义、模型定义、训练、评估等。用户可以根据自己的需求进行修改和扩展。

六、数据流
MMPreTrain算法库提了多种数据流处理方式,包括数据增强、数据预处理、数据读取等。这些功能可以帮助用户更加方便地进行数据处理和训练。
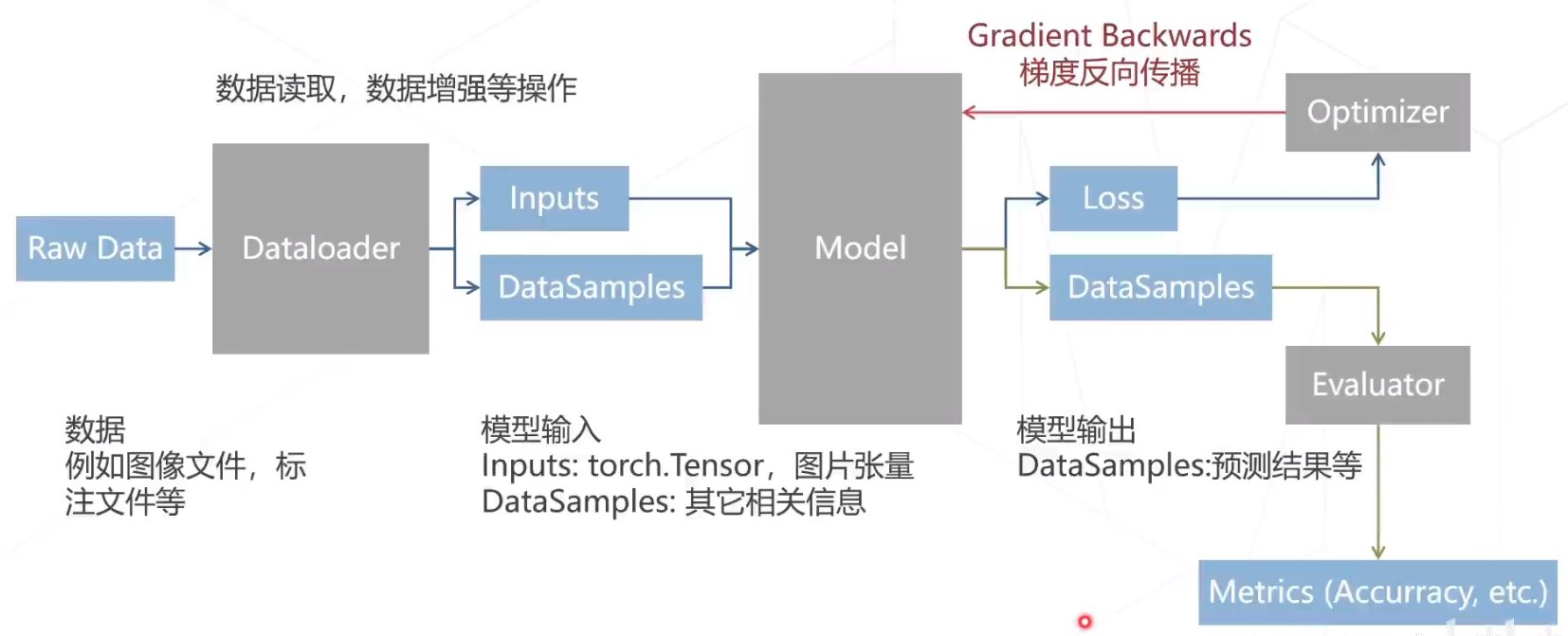
七、配置及运作方式
MMPreTrain算法库提供了多种配置方式,包括命令行参数、配置文件等。用户可以根据自己的需求进行配置,以满足不同场景下的需求。
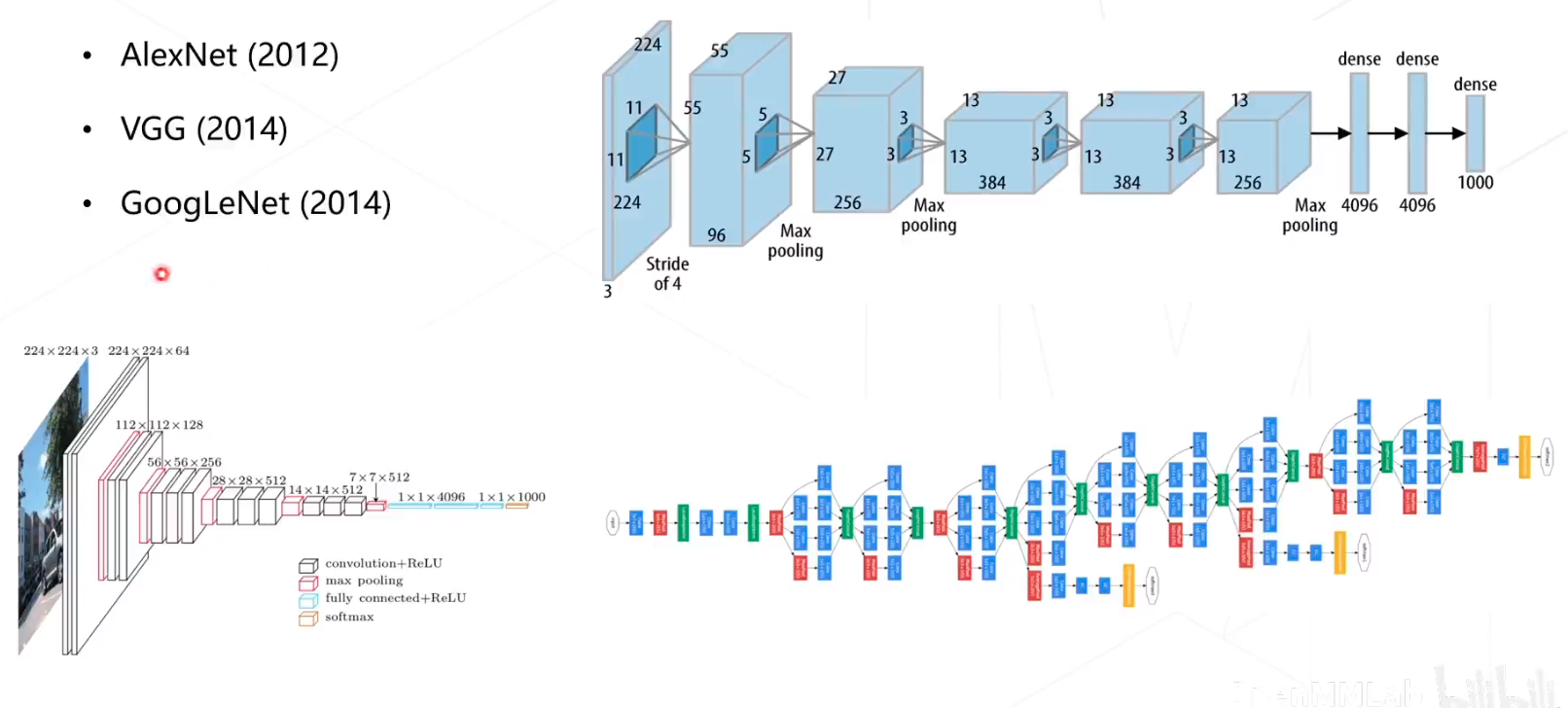
经典主干网络
Alexnet、VGG、GooleNet,关于这部分,可以看我的专栏:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/category_12157249.html?spm=1001.2014.3001.5482,我对模型作了详细的解释。
残差网络
残差网络的思想:
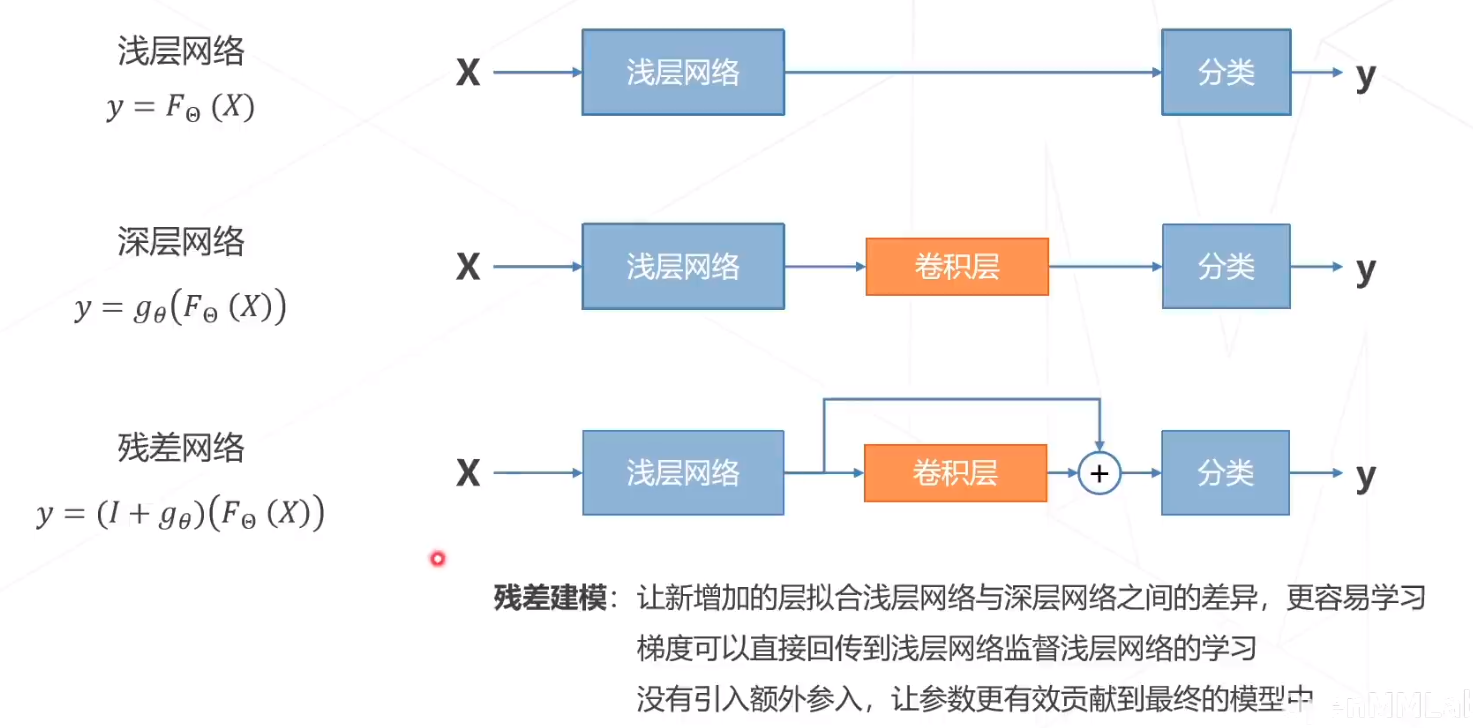
残差网络的两种结构:
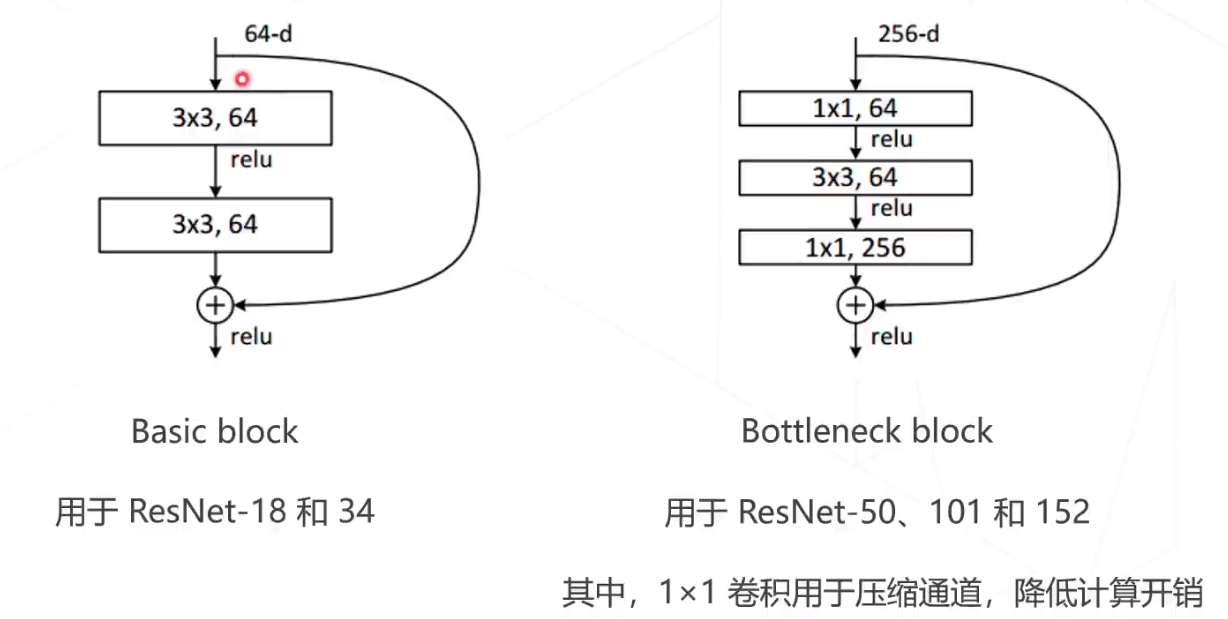
残差网络和VGG 对比:

ResNet34在ImageNet Top5的准确率为94.4%
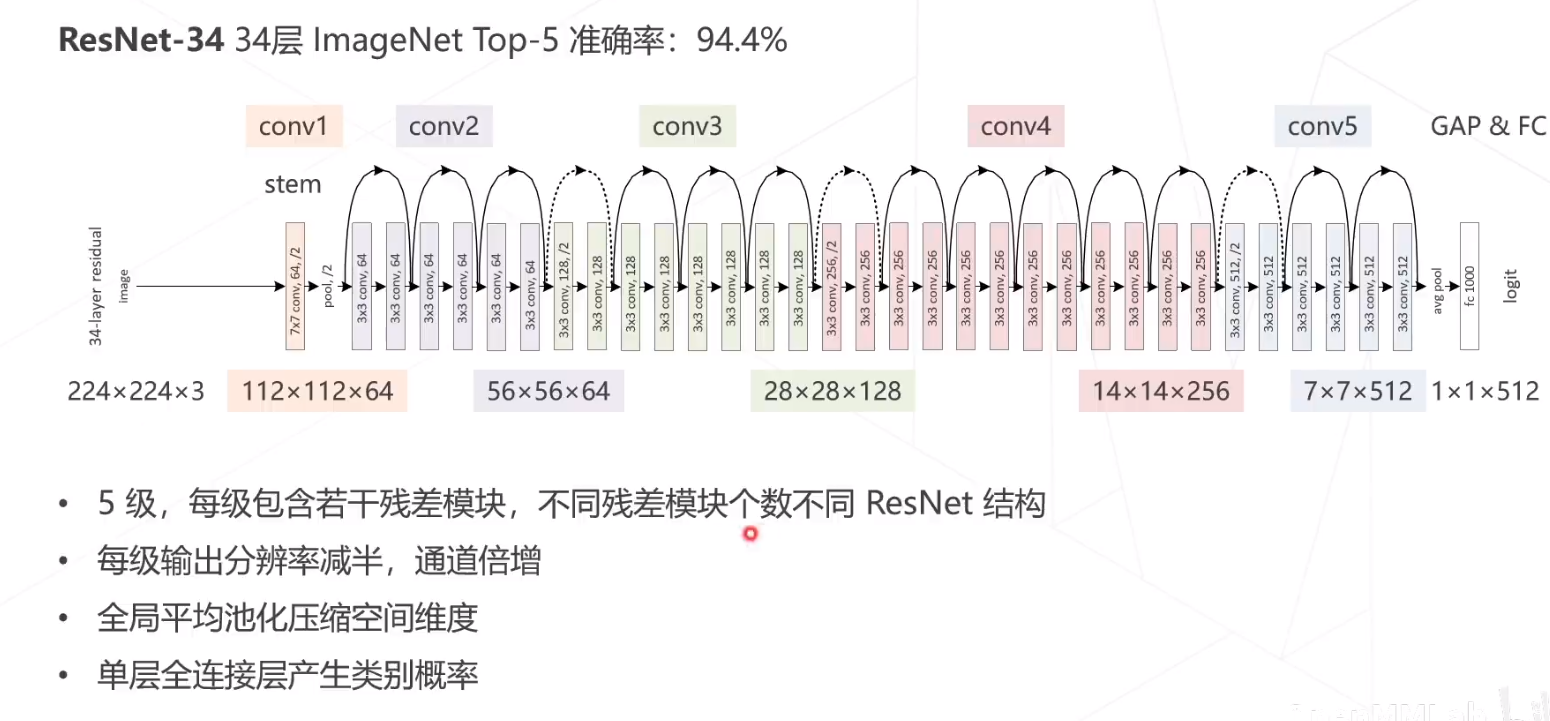
ResNet是CNN网络中影响力最大的网络。
Vison Transformer(VIT)
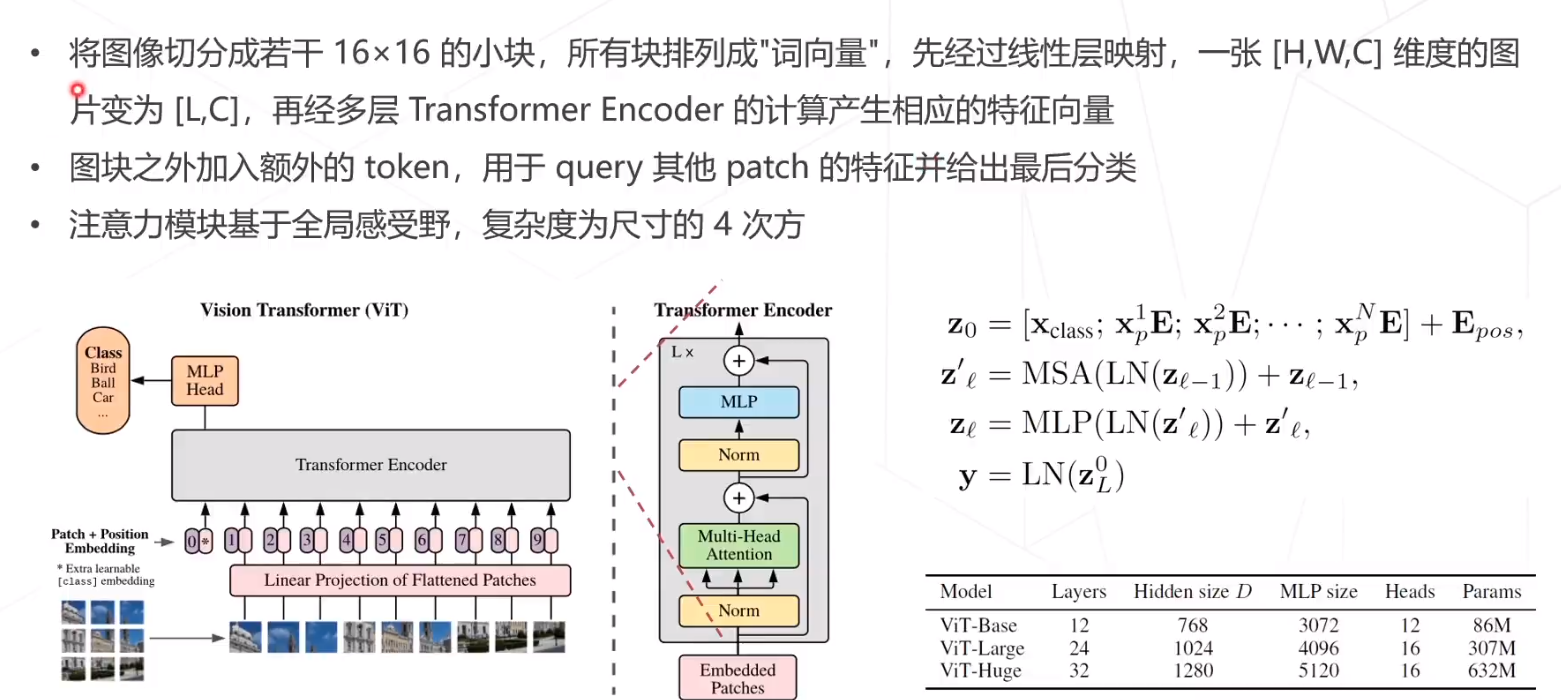
在nlp中,输入transformer中的是一个序列,而在视觉领域,模型训练中图片的大小是224*224=50176,而正常的bert的序列长度是512,所以展开成1d的序列是bert的100倍,这个的复杂度太高了。
ViT的总体想法是基于纯Transformer结构来做图像分类任务。其核心流程包括图像分块处理 (make patches)、图像块嵌入 (patch embedding)与位置编码、Transformer编码器和MLP分类处理等4个主要部分。
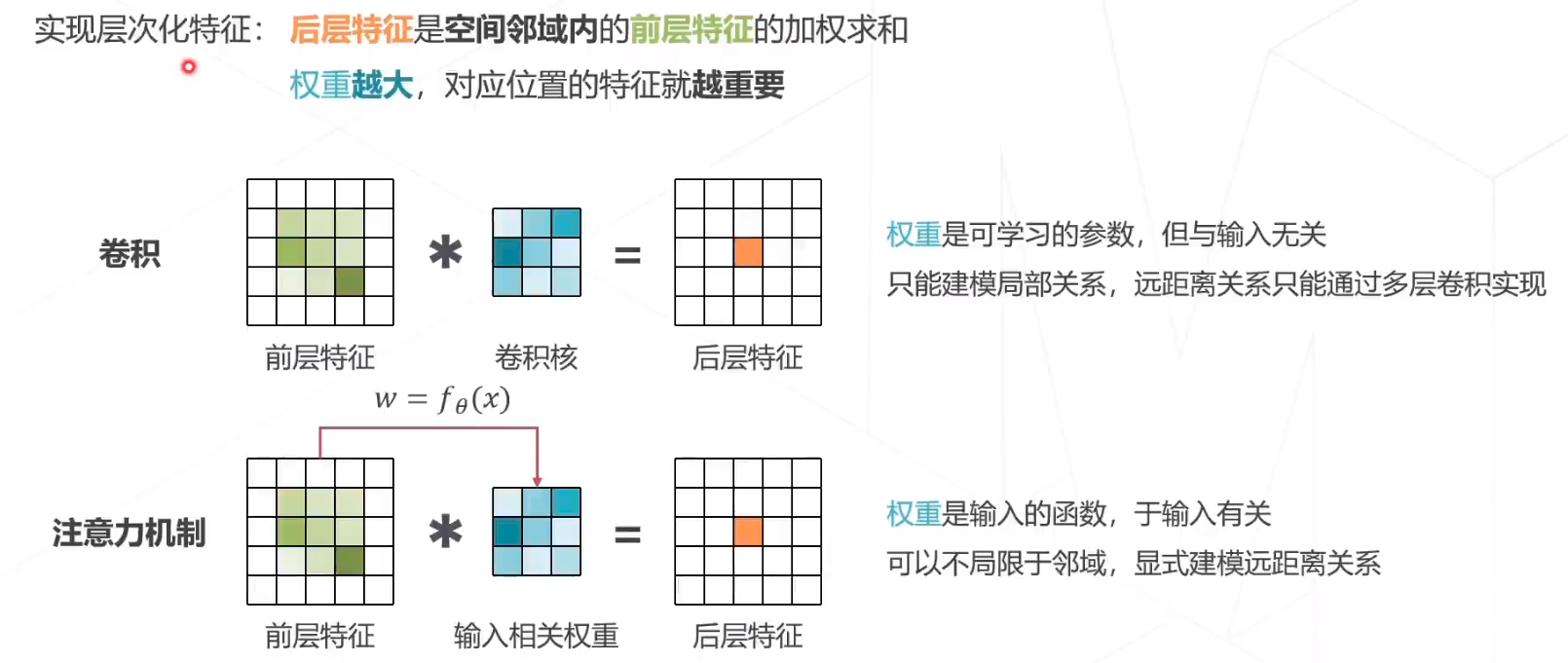
注意力机制
加入注意力机制后,实现层次化特征,后层特征是空间邻域内的前层特征的加权求和,权重越大,对应位置的特征月重要。
注意力机制的计算方式
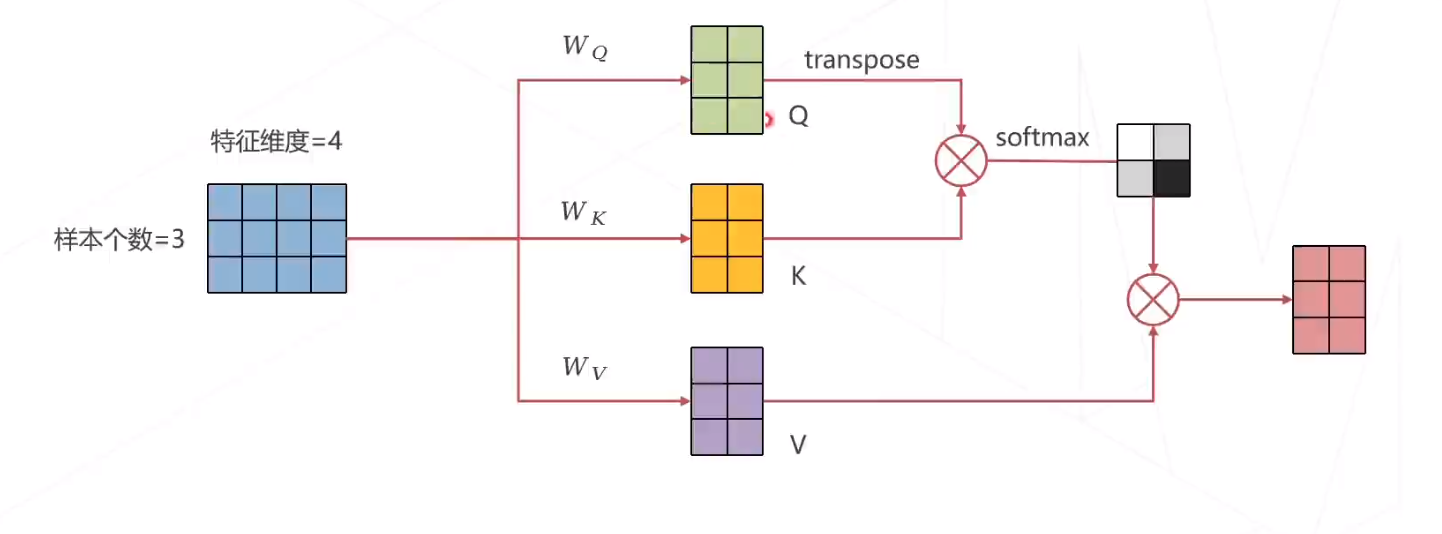
多头注意力机制的计算方式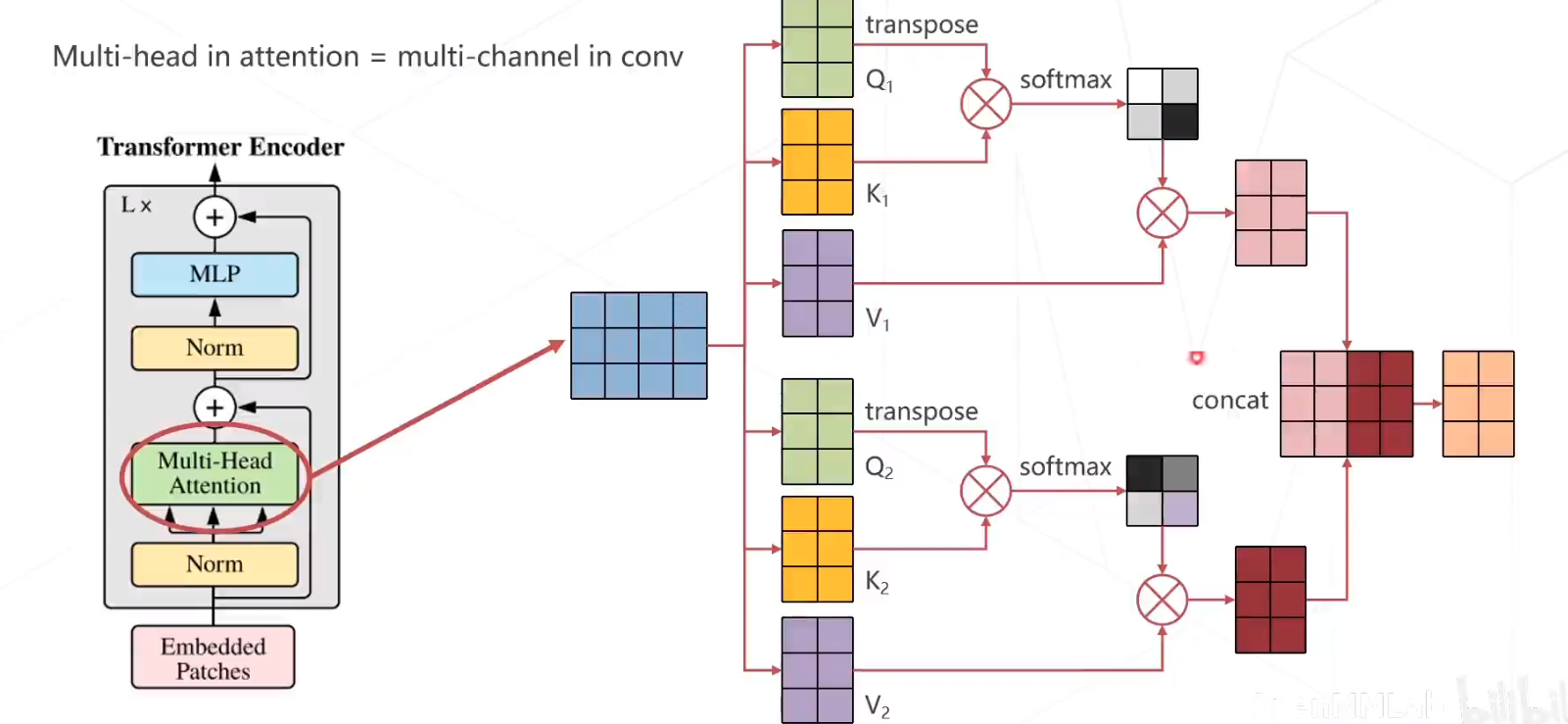
自监督学习
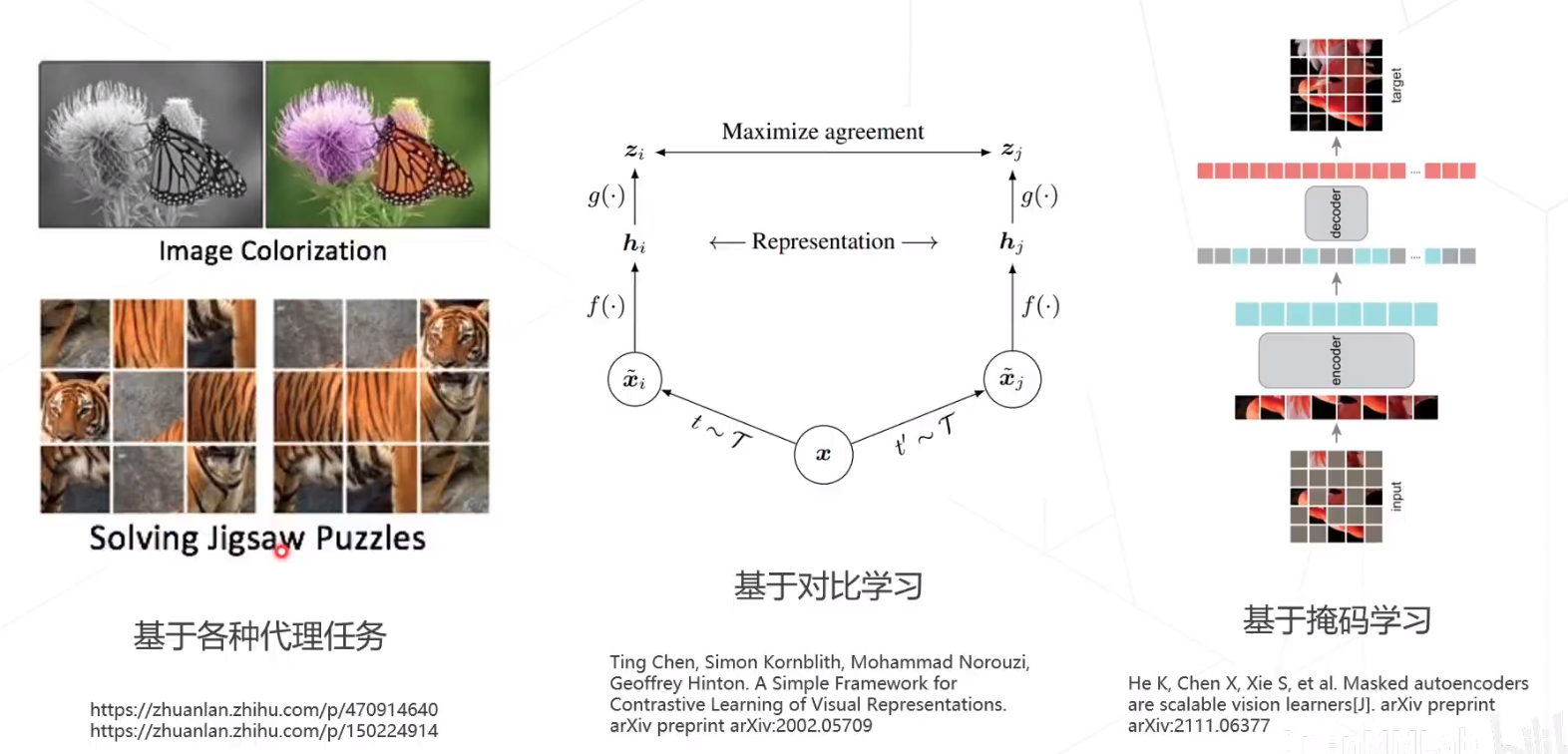
常见类型
- 基于代理任务
- 基于对比学习
- 基于掩码学习
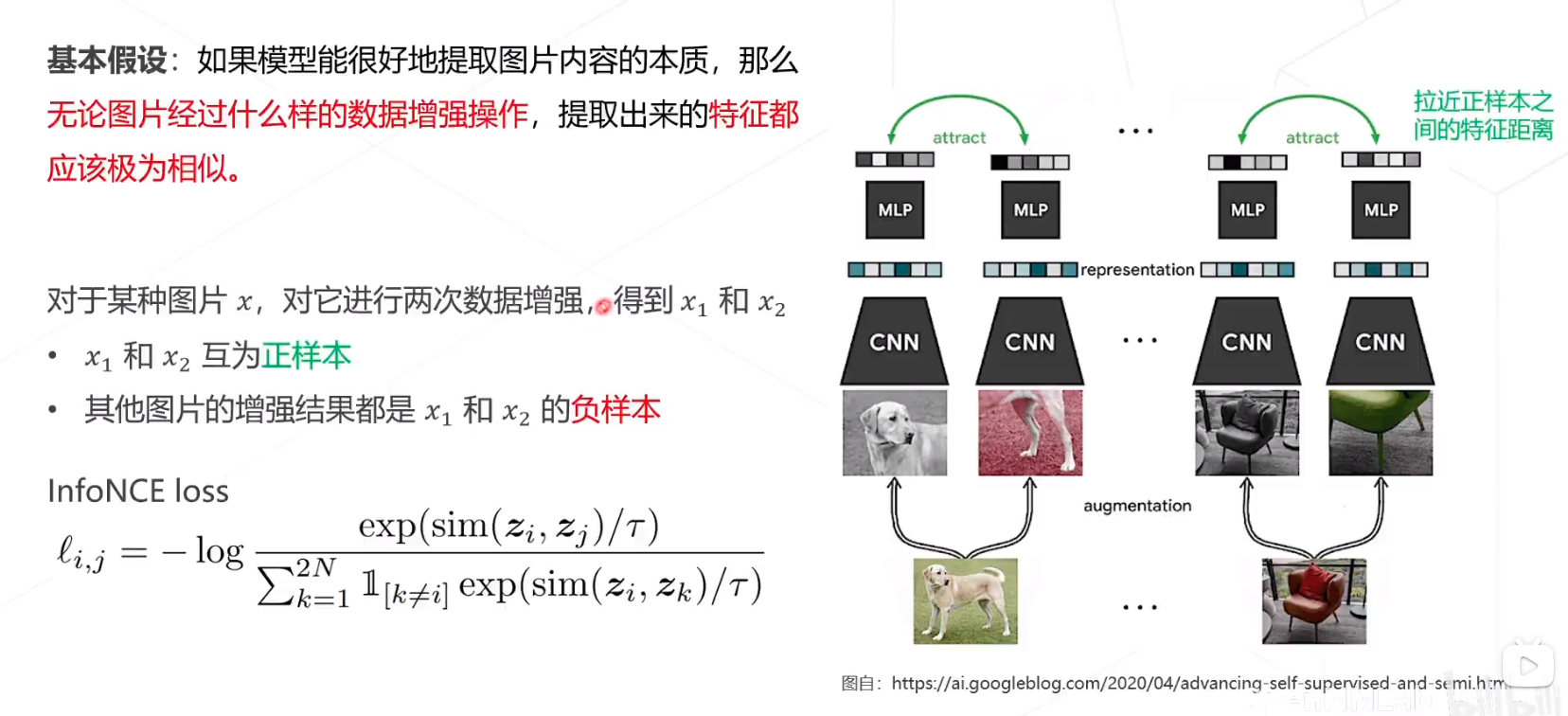
SimCLR
推远副样本的距离,拉近正样本之间的特征距离
MAE
基于掩码的自监督学习。
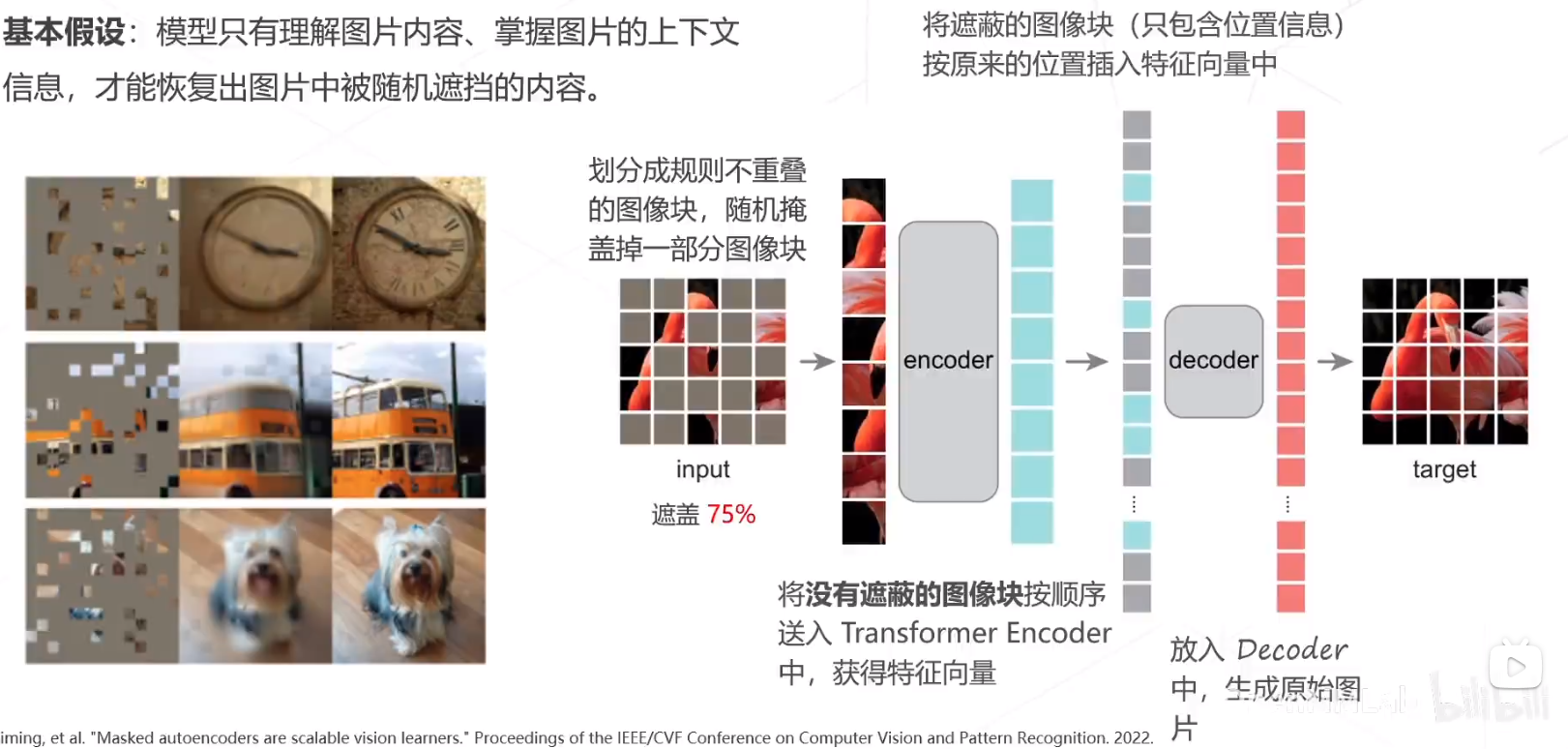
自监督学习
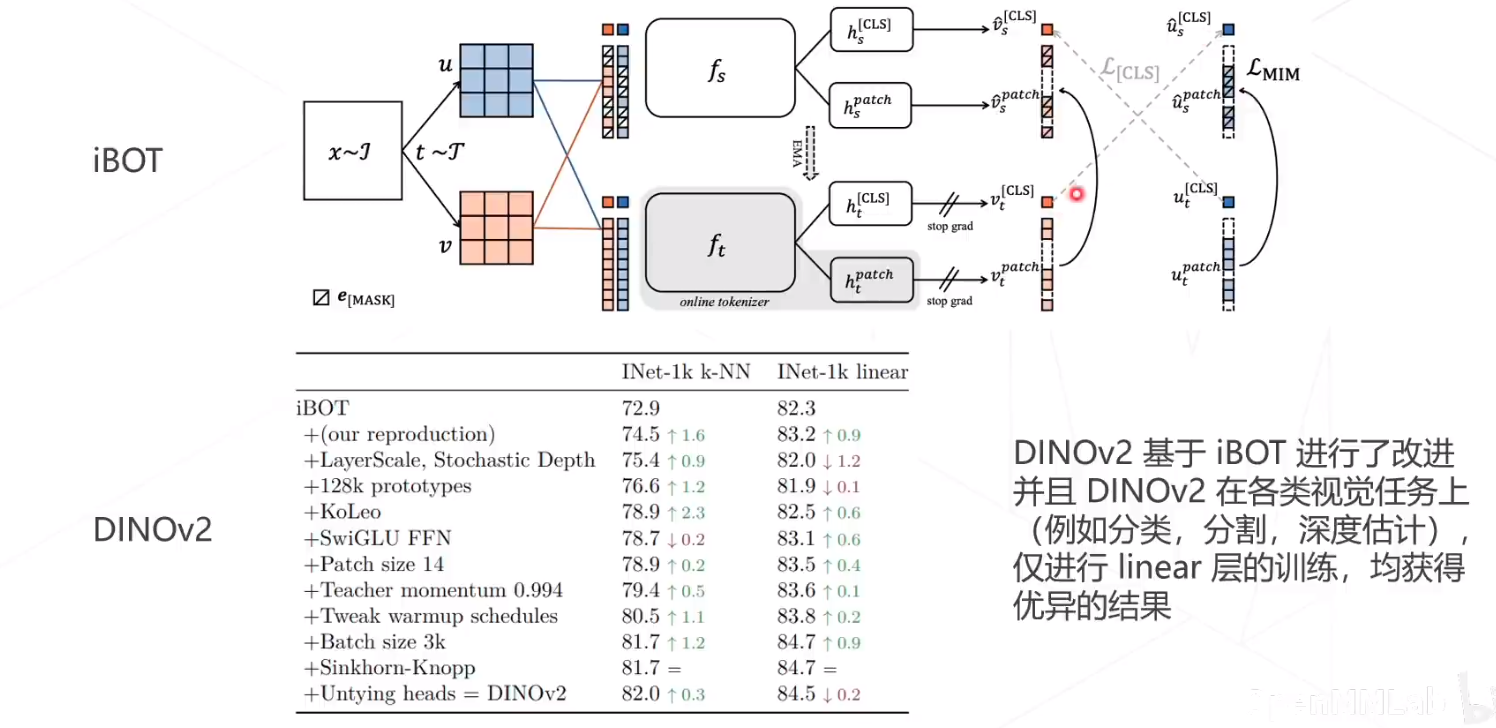
DINOV2在iBOT上作了改进
多模态
CLIP
论文翻译:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/125452516,出自OpenAI,论文比较长。文本图像对。
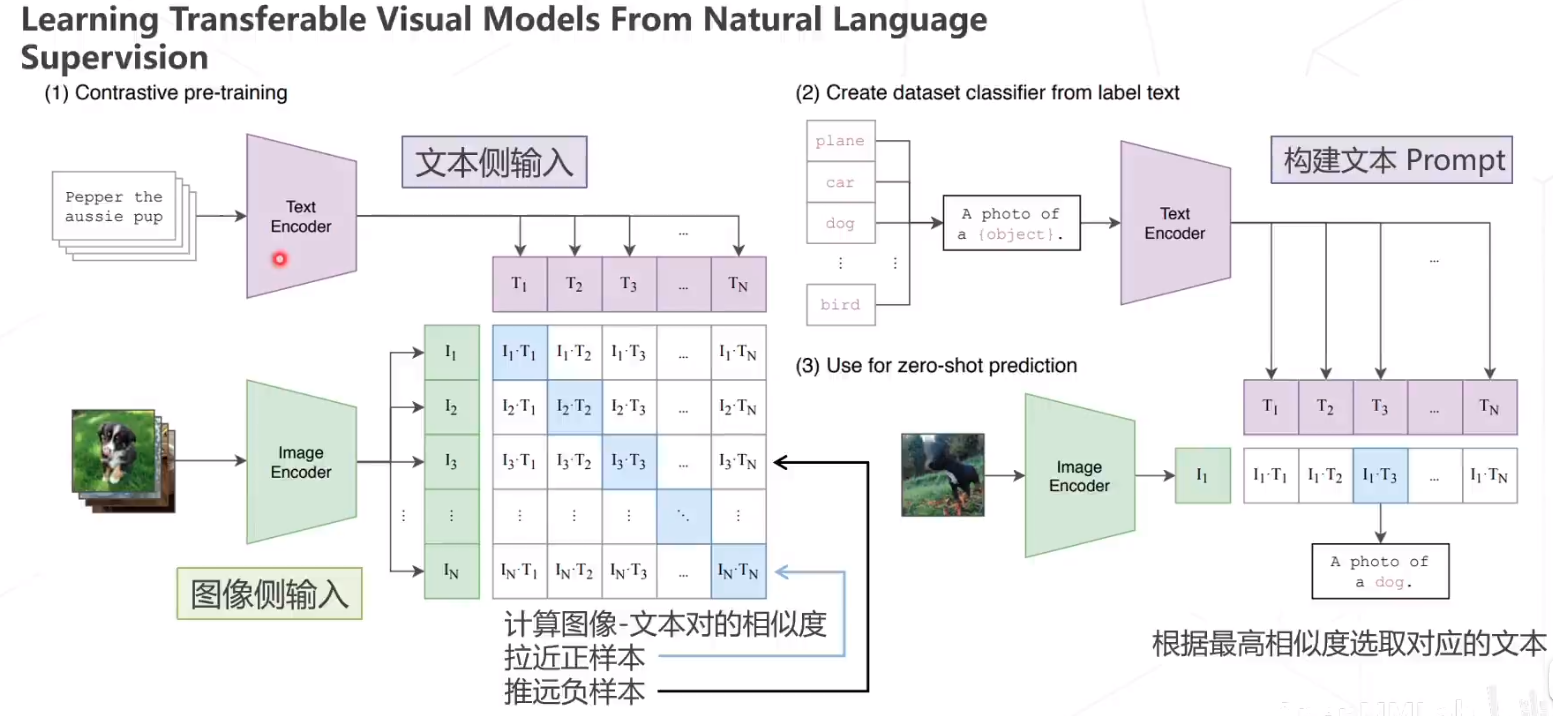
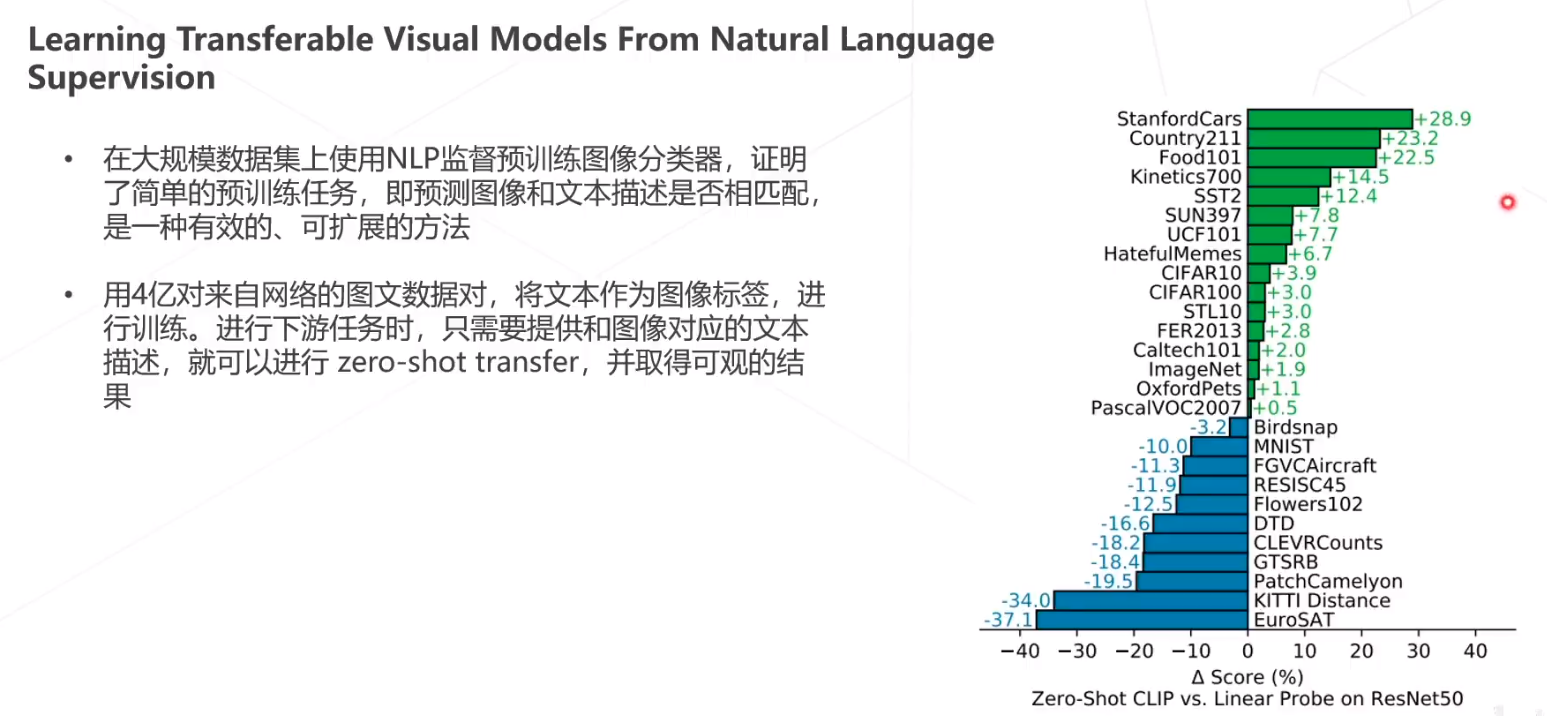
CLIP,零样本迁移,几乎超越了ResNet50
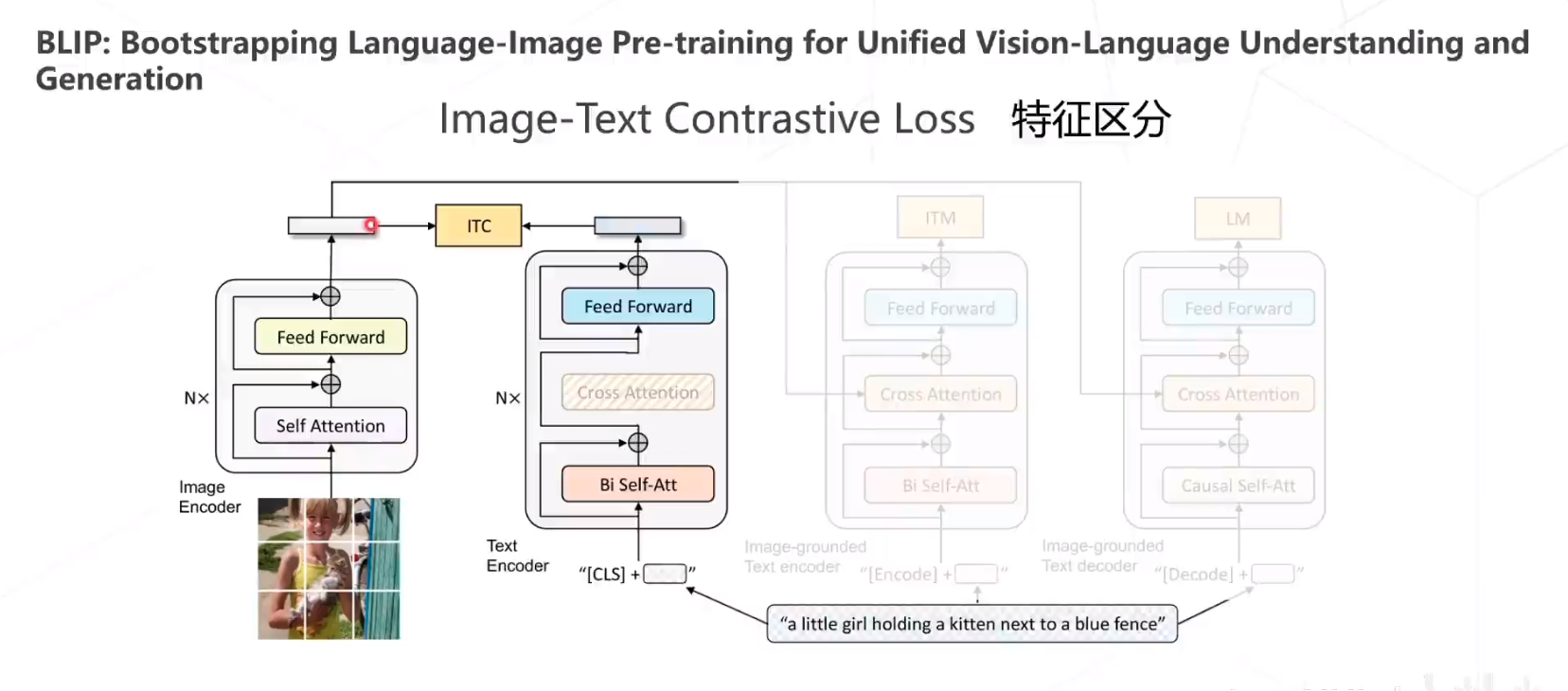
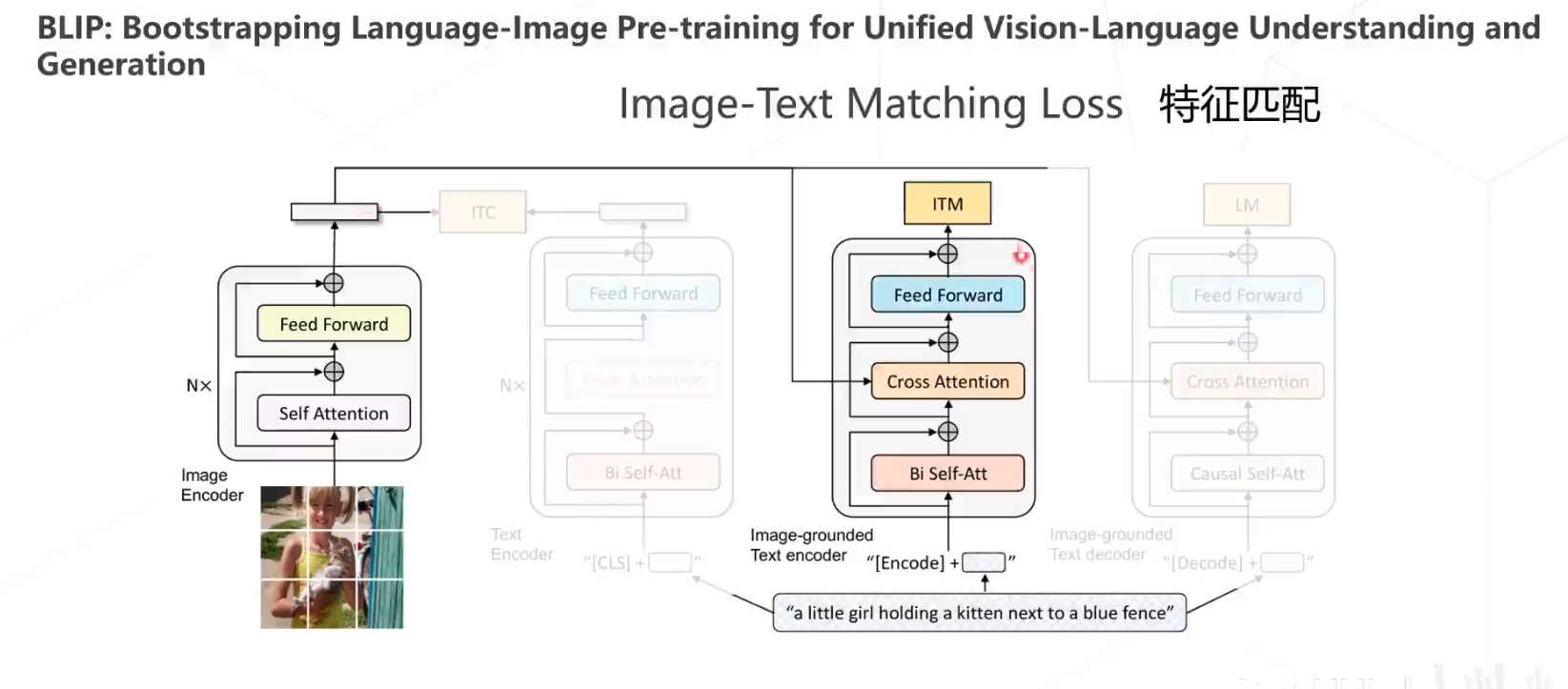
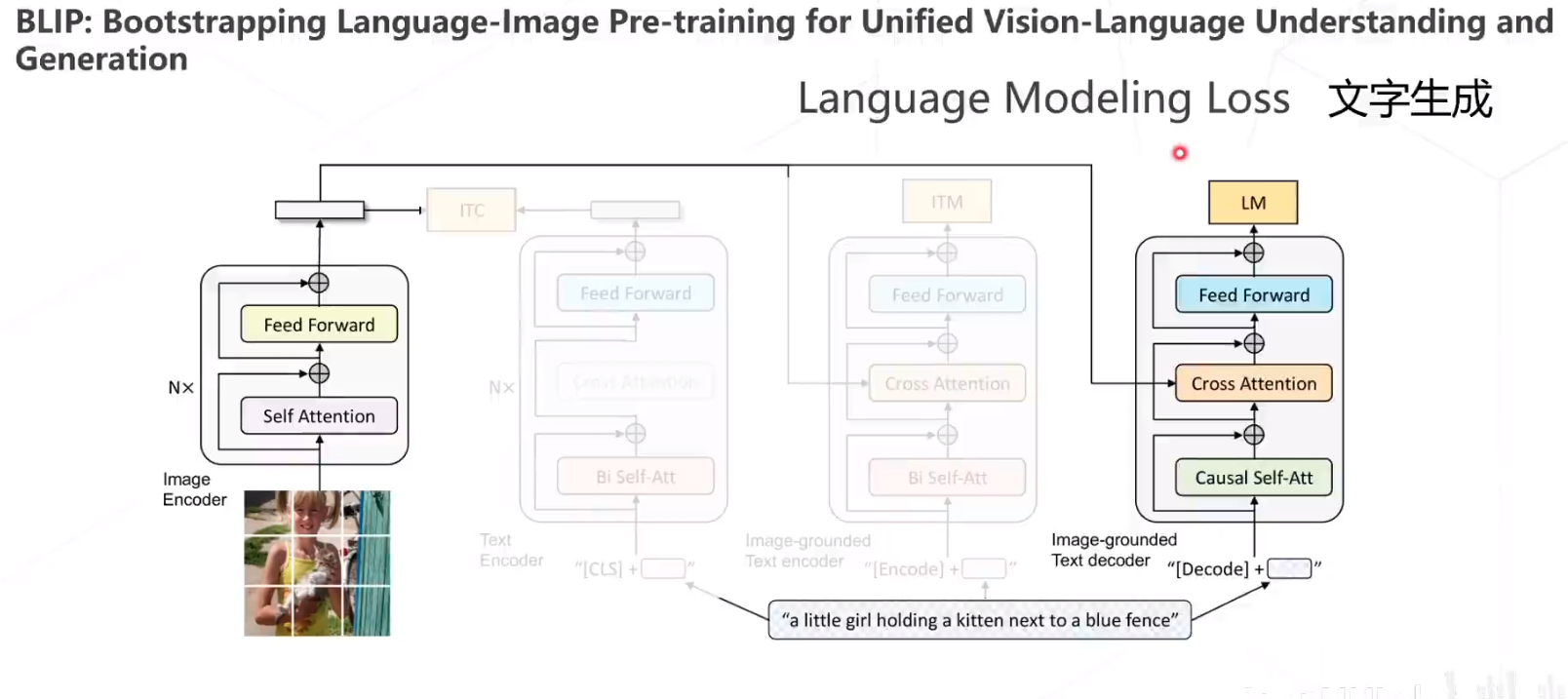
BLIP
BLIP包含三个Loss,第一个是 Image-Text

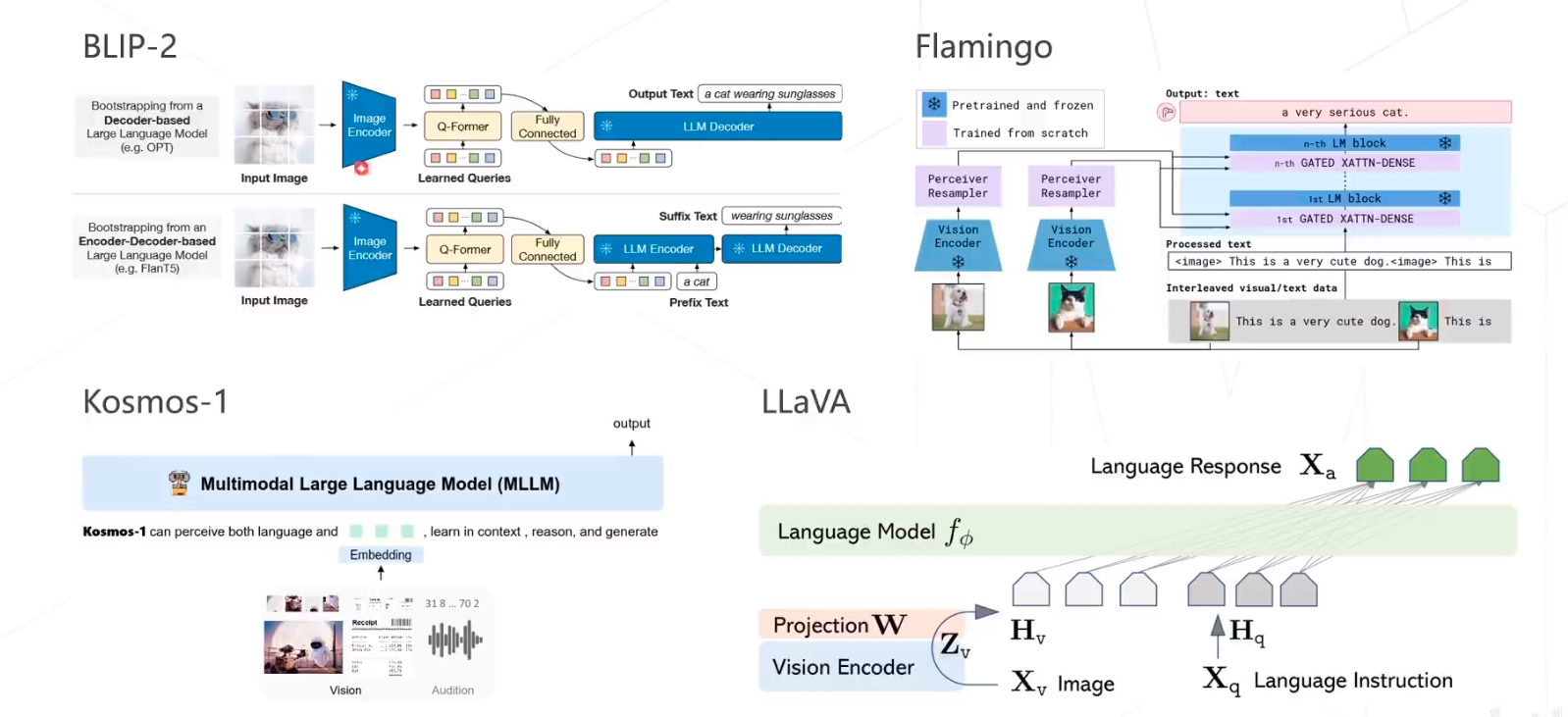
Others
总结
首先,学习了MMPreTrain,MMPreTrain算法库是一个非常强大的工具箱,可以帮助用户快速构建高效、灵活、可扩展的深度学习模型。如果您想要学习深度学习或者构建深度学习模型,那么MMPreTrain算法库绝对是一个不错的选择。
然后,学习了经典的主干网络,比如AlexNet、VGGNet以及Reset。
接下来,学习了自监督学习,自监督学习有三种方式,包含基于代理任务、基于对比学习、基于掩码学习。
最后,讲解了多模态任务,常用的有CLIP和BLIP。