W!NCE: Unobtrusive Sensing of Upper Facial Action Units with EOG-based Eyewear
文章目录
每一篇论文都需要问自己:
什么是EOG?
眼球是一个双极性的球体,角膜相对于视网膜呈现正电位,两者之间有电位差,在眼睛的周围形成一个电场,当眼球转动时,该电场的空间相位发生变化。眼球运动可以产生生物电现象,角膜和网膜之间存在一个电位差,角膜对网膜是带正电的。当眼睛注视前方不动时,可以记录到稳定的基准电位。眼睛在水平方向上运动时,眼睛左侧和右侧的皮肤之间的电位差会发生变化,在垂直方向上运动时,眼睛的上下侧的电位会发生变化。电位的变化由置于皮肤相应位置的电极导入放大器,有放大器的电流计显示出来或在示波器上显示,就是眼电信号。来源
创新在哪里?
EOG的电极分布不一样。更加没有侵入性的布置,初步消除了运动伪影。
与最相似的论文的区别在哪里?
用了不同的脸部表情,这篇的脸部动作都是为了检测疼痛,做一个疼痛检测系统作为他的贡献。EOG的电极分布不一样。
得到什么样子的效果?
达到了准确0.88的准确率。局限在于都是根据已知动作去训练然后进行分类,而不是无穷尽动作。
摘要:
以往利用while wearable EEG [12, 34], electrodermal activity [16, 38], and respiration sensors[32]去情感检测。现在利用市面上一个基于EOG的只能眼镜通过两个阶段的处理阶段去除了运动伪影,然后进行脸部运动检测。达到了准确0.88的准确率。
需要解决的挑战:
1.之前实验室的EOG是在脸部的前额和眼镜的周围放置了五个电极,而我们只是在眼镜的鼻托上放置电极,信号会变得比较微弱,以及没有那么多角度去测量。
解决方案:在信号的振幅、方向和时间模式上观察特征加以克服。
2. 这会导致信号会受到头部和身体变动所引起的阻抗变化。这些变化会引起运动伪影,干扰我们做各种表情的真实信号,需要进行消除。
解决方案:结合加速度计和陀螺仪通过自适应滤波器或CNN网络进行消除。
以往的方式
以下一些方式的对比:包括在不同的技术下的用户体验的舒适性和侵犯性?能移动使用吗?用户评价接受度有多广?

基于相机的方式[6, 15, 37, 48]
1、用户很难自由移动
2、有限视场(FOV)
接近传感器([52],[30])
1、受到光照的印象,太需要指向脸部,而且近距离视场
EMG([49][20][19])
1、需要遍布脸部电极,侵入性比较大。
EOG([8,9][23]
1、侧重点不同。
从生理信号中去除动作伪影
去除伪影在PPG、EEG和ECG都比较经常用到。
滤波方式
1、频域滤波(用在ECG PPG,需要是周期性信号)【54】
2、时域噪声去除方法,比如自适应滤波,不需要周期性信号【8,14】;很多自适应滤波方法采用递归最小二乘(RLS)、最小均方乘(LMS)、归一化最小均方乘(NLMS)等。
3、非线性函数逼近器(神经网络)【18,40,56】
本文采用了NLMS方法以及神经网络的方式。
传感器选择
我们需要一个传感器来准确知道引起伪影的时间。通常都是使用IMU,还有一些人用了加速度计【8,10,44】;压电和拉伸传感器。【7,21】
IMU和EOG之间的关键区别在于它们检测上面部和下面部手势的能力。
解决过程
第一阶段去除伪影,第二阶段脸部识别。
去除伪影

我们需要建立一个模型来去除伪影,也就是将IMU的数据与EOG的伪影数据进行映射,然后真实EOG数据减掉伪影数据就好了。
参数:
S(n)代表的是真实数据,n是时间刻度,M(n)是估计的运动伪影。
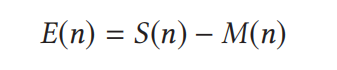
要从IMU的数据映射到M(n),因此我们需要建模。构建一个时变函数:
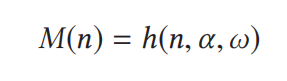
α是线性加速度,ω是旋转角速度。为了求取这个函数:
我们用了两种方法。
1、NLMS方法
输入:六个输入流:三个加速度和三个陀螺仪轴。
输出:四个输出流:(The signals it provides are the vertical difference (V), horizontal difference (H) and the raw left (L)and right ® electrode readings)
不应该是4*7 = 28个吗,不明白为啥是30个(原文:For each output stream, we need six NLMS filters per input stream and one adaptive filter to fuse these outputs.In other words, we need a total of 30 filters.)
滤波器的权重是自适应线上更新的。采用50order(利用50个进行训练估计),学习率设置为0.05。

2、基于神经网络回归模型
输入:300size的向量(50个数据点 x 6轴)
输出:4轴数据
隐藏层:20个神经元
还有可缩放后处理模块(让估计的振幅和EOG信号有相同的标准差,因此能相互抵消)

脸部动作识别
CNN结构

个性化迁移学习
由于不同人的表情动作不太一样,所以作者进行了一定的迁移学习训练。在原有的CNN模型中添加了迁移学习训练,重新训练了全连接层。
减少计算复杂度
通过触发机制来减小运算负担。没有实时进行CNN等运算,而是当有活动出现的时候则触发运动伪影算法,只有触发伪影后才触发后续模块算法。
怎么设计实验
建立数据集
1、设置了三种场景:固定的面部动作、边走路边面部动作、边动头边面部动作(因为用户很难这么做,所以进行了信号合成);以及最后用OpenFace作为ground truth labeling。
2、17个用户,男女比例,平均年龄;动作包括:抬起眉毛,减低眉毛,抬起脸颊、皱鼻子,眨眼和“none class”;每一个用户每一个动作分别做20次;还简单收集了过程中的非自愿眨眼动作,把这一类分给“none” class;

评估
1、准确率
2、滤波后信噪比
3、伪影消除前后的信号图
3、伪影去除的噪声 比较(自适应滤波&神经网络&完全没滤波);(加速度计 陀螺仪 加速度计和陀螺仪);
4、不同用户的动作差异带来的迁移学习结果,发现6个人动作 准确率不会再上升了。