去年面试字节的时候,准备了一些算法常用的面试知识点,事实证明,准备的还不错。现在分享给大家,希望自己求职路也顺利些。
目录
优化算法,Adam, Momentum, Adagard,SGD原理:
高频问题:
优化算法,Adam, Momentum, Adagard,SGD原理:
自适应学习率算法
Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与梯度历史平方值总和的平方根成反比。用adagrad将之前梯度的平方求和再开根号作为分母,会使得一开始学习率呈放大趋势,随着训练的进行学习率会逐渐减小
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。用来解决梯度下降不稳定,容易陷入鞍点的缺点
SGD为随机梯度下降,每一次迭代计算数据集的mini-batch的梯度,然后对参数进行跟新。优点是更新速度快,缺点是训练不稳定,准确度下降。
Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,在经过偏置的校正后,每一次迭代后的学习率都有个确定的范围,使得参数较为平稳,结合momentum和adagrad两种算法的优势
正则化:
用来显示地设计来减少测试误差,修改学习算法,降低泛化误差而非训练误差.通过对目标函数添加一个参数范数惩罚,限制模型的学习能力。
L1正则化 各个参数的绝对值之和, 可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;一定程度上可以防止过拟合。
稀疏矩阵指的是很多元素为0、只有少数元素是非零值的矩阵。以线性回归为例,即得到的线性回归模型的大部分系数都是0,这表示只有少数特征对这个模型有贡献,从而实现了特征选择。总而言之,稀疏模型有助于进行特征选择。
L2正则化可以防止模型过拟合 L2是各个参数平方和的开方值
L1不可导的时候该怎么办?
Q: 当损失函数不可导,梯度下降不再有效,可以使用坐标轴下降法,梯度下降是沿着当前点的负梯度方向进行参数更新,而坐标轴下降法是沿着坐标轴的方向,假设有m个特征个数,坐标轴下降法进参数更新的时候,先固定m-1个值,然后再求另外一个的局部最优解,从而避免损失函数不可导问题
了解L1、L2范数:
深入理解L1、L2范数_取个名字最难了的博客-CSDN博客_l1范数图像
Logit函数和sigmoid函数的关系:
logistic function 是 logit funciton的反函数
sigmoid function不是某一个函数,而是指某一类形如"S"的函数,都可以成为sigmoid的函数.
区别logit\logistic\simoid函数:
一篇文章搞懂logit, logistic和sigmoid的区别 - 知乎 关于机器学习中logit的含义,对于理解模型很有帮助
sigmoid的优点在于输出范围有限,所以数据在传递的过程中不容易发散。当然也有相应的缺点,就是饱和的时候梯度太小。
sigmoid还有一个优点是输出范围为(0, 1),所以可以用作输出层,输出表示概率;处处可导,
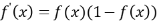
损失函数:
交叉熵损失 Cross Entropy :多分类问题常用的损失函数
交叉熵主要是用来判定实际的输出与期望的输出的接近程度
交叉熵公式:

交叉熵损失函数:
交叉熵损失函数经常用于分类问题中,特别是在神经网络做分类问题时,也经常使用交叉熵作为损失函数,此外,由于交叉熵涉及到计算每个类别的概率,所以交叉熵几乎每次都和sigmoid(或softmax)函数一起出现。
我们用神经网络最后一层输出的情况,来看一眼整个模型预测、获得损失和学习的流程:
1. 神经网络最后一层得到每个类别的得分scores(也叫logits);
2. 该得分经过sigmoid(或softmax)函数获得概率输出;
3. 模型预测的类别概率输出与真实类别的one hot形式进行交叉熵损失函数的计算


n代表类别的数量
神经网络为啥使用交叉熵?
MSE:均方误差,
回归任务中最常用的性能度量
一道实际应用题
损失函数|交叉熵损失函数 - 知乎 写的无敌好,用一个多分类问题来讲解
softmax和sigmoid函数的区别与联系:
Sigmoid =多标签分类问题=多个正确答案=非独占输出
Softmax =多类别分类问题=只有一个正确答案=互斥输出

激活函数的作用:
是为了增加神经网络模型的非线性。没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。所以你没有非线性结构的话,根本就算不上什么神经网络。
relu比sigmoid的效果好在哪里?
relu(x) = max(0,x) 在大于0的部分梯度为常数,不会有梯度弥散现象;relu的导数计算的更快;relu在负半区的导数为0,所以神经元激活值为负数时,梯度为0,该神经元不参与训练,具有稀疏性。
relu的变体:leaky/'li:ki/ relus

逻辑回归和线性回归:
线性回归用来做预测,LR用来做分类。线性回归是来拟合函数,LR是来预测函数。线性回归用最小二乘法来计算参数,LR用最大似然估计来计算参数。线性回归更容易受到异常值的影响,而LR对异常值有较好的稳定性。LR本质上还是线性回归,只是特征到结果的映射过程中加了一层函数映射,即sigmoid函数,即先把特征线性求和,然后使用sigmoid函数将线性和约束至(0,1)之间,结果值用于二分或回归预测。
SVM的推导
:
推导 | SVM详解(1)SVM基本型 - 知乎

LR和SVM的异同:
LR和SVM都是分类算法(SVM也可以用与回归)LR是参数模型,SVM为非参数模型。LR采用的损失函数为logisticalloss,而SVM采用的是hingeloss。在学习分类器的时候,SVM只考虑与分类最相关的少数支持向量点。LR的模型相对简单,在进行大规模线性分类时比较方便。
逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
分类算法及其应用场景:
单一的分类方法主要包括:LR逻辑回归,SVM支持向量机,DT决策树、NB朴素贝叶斯、NN人工神经网络、K-近邻;集成学习算法:基于Bagging和Boosting算法思想,RF随机森林,GBDT,Adaboost,XGboost。
Batch Normalization:批标准化
通过规范化的手段,将越来越偏的分布拉回到均值为0方差为1的标准正态分布,使得激活函数的输入值落在激活函数对输入比较敏感的区域,从而使梯度变大,加快学习收敛速度,避免梯度消失的问题。

参考:深度学习中 Batch Normalization为什么效果好?
深度学习中 Batch Normalization为什么效果好? - 知乎
BN带来的好处。
(1) 减轻了对参数初始化的依赖,这是利于调参的朋友们的。
(2) 训练更快,可以使用更高的学习率。
(3) BN一定程度上增加了泛化能力,dropout等技术可以去掉。
欠拟合、过拟合的解决方法:
过拟合:早停法、决策树剪枝、正则化、
神经网络的dropout
逐层归一化(batch normalization)
增加样本,数据清洗之后在进行模型训练
集成学习Bagging使模型更加的稳定,其作用是因为降低了模型的方差,对过拟合有一定的作用
如何解决梯度消失和梯度爆炸问题
激活函数的原因,由于梯度求导的过程中梯度非常小,无法有效反向传播误差,造成梯度消失的问题
1)使用 ReLU、LReLU、ELU、maxout 等激活函数
sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。
2)使用批规范化
通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。从上述分析分可以看到,反向传播式子中有w的存在,所以w的大小影响了梯度的消失和爆炸,Batch Normalization 就是通过对每一层的输出规范为均值和方差一致的方法,消除了w带来的放大缩小的影响,进而解决梯度消失和爆炸的问题。
如何解决正负样本不平衡问题:
数据不平衡问题:
过采样,对训练集里面样本数量较少的类别(少数类)进行过采样,合成新的样本来缓解类不平衡。
欠采样,对训练集里面样本数量较多的类别(多数类)进行欠采样,抛弃一些样本来缓解类不平衡。
合成新的少数类
阈值移动
线性回归和逻辑回归:
参考:
一、线性回归和逻辑回归_呆呆的猫的博客-CSDN博客_线性回归和逻辑回归
整理的特别好!!!必看!

逻辑回归的损失函数:对数似然损失函数
loss = -【yln a - (1-y)ln a】
其中y表示样本的真实标签,即0或者1.
a表示预测结果是0或者1的概率,则a的取值在区间【0,1】。
当因此上面多项式中我们单次智能考虑一种预测的结果--正例/负例。
考虑正例时,即y= 1时,loss函数=-【yln a】, 当a越接近于1,则ln a取的最大值, y = 1,则损失函数取得最小值。
补充:逻辑回归是做二分类的,也就是依据伯努利分布进行推导的算法

1、LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题)
2、两个方法都可以增加不同的正则化项,如l1、l2等等。所以在很多实验中,两种算法的结果是很接近的。
区别:
1、LR是参数模型,SVM是非参数模型。
2、从目标函数来看,区别在于逻辑回归采用的是logistical loss,SVM采用的是hinge loss,这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
3、SVM的处理方法是只考虑support vectors,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重。
4、逻辑回归相对来说模型更简单,好理解,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些,SVM转化为对偶问题后,分类只需要计算与少数几个支持向量的距离,这个在进行复杂核函数计算时优势很明显,能够大大简化模型和计算。
5、logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
训练网络不收敛的原因:
(1)没有做数据归一化;
(2)没有检查过预处理结果和最终的训练测试结果;
(3)没有做数据预处理;
(4)没有使用正则化;
(5)Batch Size设的太大;
(6)学习率设的不合适;
(7)最后一层的激活函数错误;
(8)网络存在坏梯度,比如当Relu对负值的梯度为0,反向传播时,梯度为0表示不传播;
(9)参数初始化错误;
(10)网络设定不合理,网络太浅或者太深;
(11)隐藏层神经元数量错误;
(12)数据集标签的设置有错误
使用较小卷积核的好处:
使用了3个3*3卷积核来代替7*7卷积核,使用了2个3*3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
对于两个3*3卷积核,所用的参数总量为2*(3*3)*channels, 对于5*5卷积核为5*5*channels, 因此可以显著地减少参数的数量。
