计算机视觉面试(二)
1. ROI pooling 作用
一、提出的原因
对于Two-stage目标检测大概分为两步:
1.给定一张输入image找出objects可能存在的所有位置。这一阶段的输出应该是一系列object可能位置的bounding box。这些通常称之为
region proposals或者 regions of interest(ROI)。
2.根据上一阶段的region proposal确定是否属于目标。
这样子可能会导致一些问题:
1.检测速度过慢,不能达到实时性要求。
2.无法做到end-to-end training。
这就是ROI pooling提出的根本原因。
ROI pooling层能实现training和testing的显著加速,提高检测准确性。
二.具体操作
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;
这样可以从不同大小的方框得到固定大小的相应的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
方法:直接Pooling,若尺寸不对应则直接取整
具体计算:
下图为一张88的feature map,选取其中一个57的region输入ROIPooling输出2*2结果。
a.划分为2*2=4块区域
1)5/2 = 2.5 --> 2, 剩下的为3,则2+3 向下取整floor
2)7/2 = 3.5 -->3, 剩下的为4,则3+4
b.取每个小区域的最大值为pooling值
考虑一个88大小的feature map,一个ROI,以及输出大小为22.
(1)输入的固定大小的feature map 8*8
(2)region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
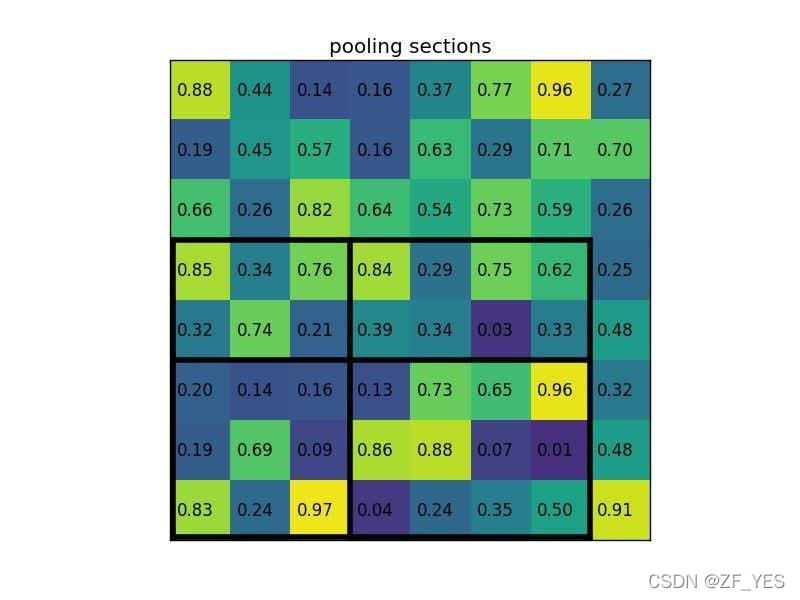
(3)将其划分为(22)个sections(因为输出大小为22),我们可以得到:[(0,3),(3,5)],[(3,3),(7.5)],[(0,5),(3,8)],[(3,5),(7,8)] 4个sections
(4)对每个section做max pooling(每个section取最大值),可以得到:
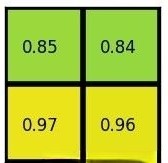
三.优点
-
允许我们对CNN中的feature map进行reuse;
-
可以显著加速training和testing速度;
-
允许end-to-end的形式训练目标检测系统。
四.缺点
由于 RoIPooling 采用的是 INTER_NEAREST(即最近邻插值) ,在resize时,对于缩放后坐标不能刚好为整数的情况,采用了粗暴的舍去小数,相当于选取离目标点最近的点,损失一定的空间精度。
例如:原图上的bbox大小为665x665,经backbone后,spatial scale=1/32。因此bbox也相应应该缩小为665/32=20.78,但是这并不是一个真实的pixel所在的位置,因此这一步会取为20。0.78的差距反馈到原图就是0.78x32=25个像素的差距。如果是大目标这25的差距可能看不出来,但对于小目标而言差距就比较巨大了。
(这里采用了ROI Align进行优化)
2.朴素贝叶斯,为什么朴素?
贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。
公式如下:
P(B|A)=P(A|B)P(B)P(A)P(B|A)=P(A|B)P(B)P(A)
该公式最大的优点就是可以忽略AB的联合概率直接求其条件概率分布。
朴素的原因是:所有的特征在数据集中的作用是独立,相互不影响。
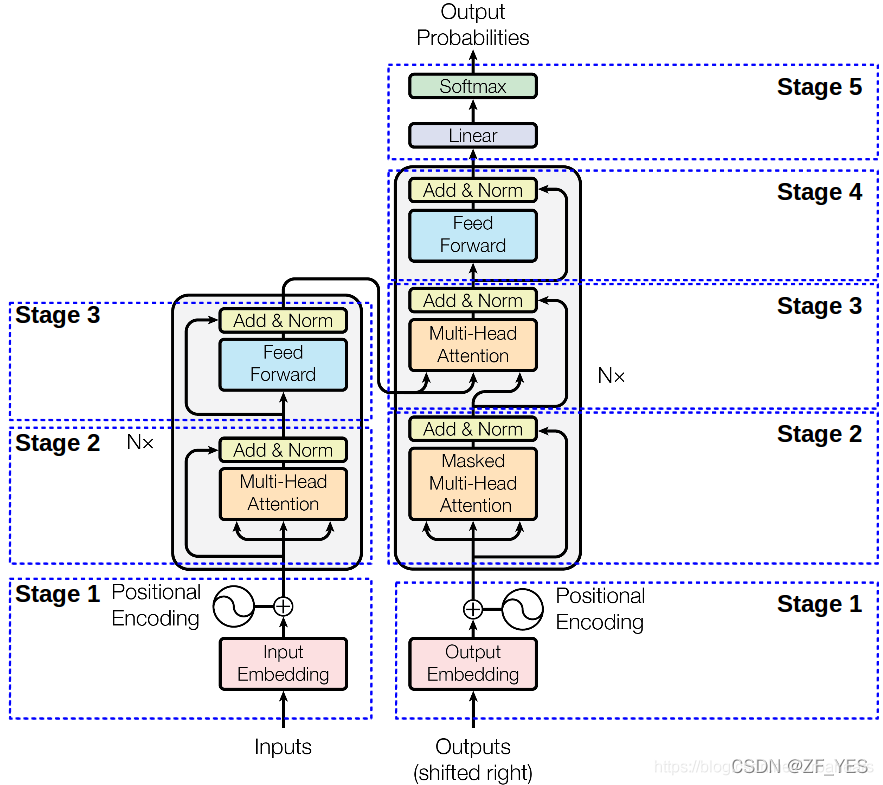
3.画一下Transformer结构图
4. 1*1的卷积核的作用
NIN(Network in Network)【1】
是第一篇探索1×11×1卷积核的论文,这篇论文通过在卷积层中使用MLP替代传统线性的卷积核,使单层卷积层内具有非线性映射的能力,也因其网络结构中嵌套MLP子网络而得名NIN。NIN对不同通道的特征整合到MLP自网络中,让不同通道的特征能够交互整合,使通道之间的信息得以流通,其中的MLP子网络恰恰可以用1×1的卷积进行代替。
GoogLeNet 【2】
则采用1×1卷积核来减少模型的参数量。在原始版本的Inception模块中,由于每一层网络采用了更多的卷积核,大大增加了模型的参数量。此时在每一个较大卷积核的卷积层前引入1×1卷积,可以通过分离通道与宽高卷积来减少模型参数量。
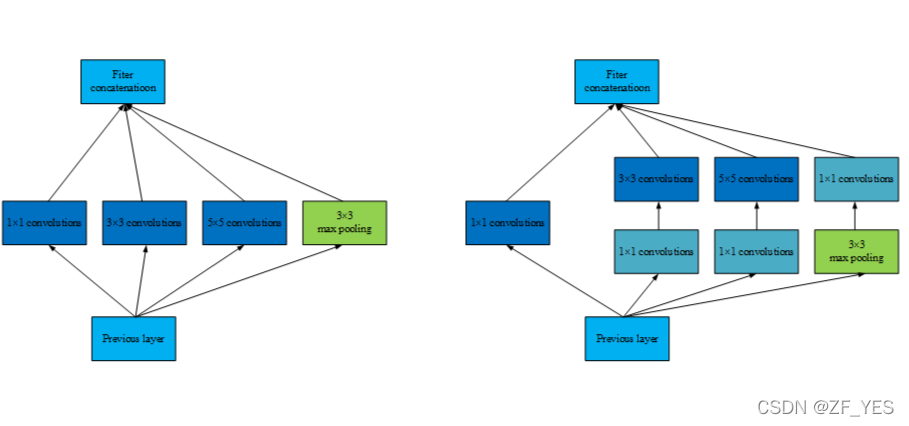
综上所述,1×11×1卷积的作用主要为以下两点:
- 实现信息的跨通道交互和整合。(高效的低维嵌入,或特征池)
- 对卷积核通道数进行降维和升维,减小参数量。
- 卷积后再次应用非线性
[1] He K, Gkioxari G, Dollar P, et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):1-1.
[2] Hoochang S, Roth H R, Gao M, et al. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning[J]. IEEE Transactions on Medical Imaging, 2016, 35(5):1285-1298.
##思考:
- 使用大卷积核的好处
- SVM 如何实现多分类?
- 双边滤波为什么能保留边缘?
- 池化层的反向传播是怎么实现的?