作者:马如悦 Apache Doris 创始人
历史上,数据分析需求的不断提升(更大的数据规模、更快的处理速度、更低的使用成本)和计算基础设施的不断进化(从专用的高端硬件、到低成本的商用硬件、到云计算服务),这两大因素推动数据仓库的架构大体经历了三个时代:软硬一体的一体机时代、存算一体的分布式时代以及存算分离的云原生时代。
Apache Doris 诞生于存算一体的分布式时代,是典型的 Shared Nothing 架构:BE 节点上存储与计算紧密耦合、多 BE 节点采用 MPP 分布式计算架构,这种架构为 Apache Doris 带来了高可用、极简部署、横向可扩展以及强大的实时分析性能等一系列核心特色。随着云时代的到来,无论是公有云、私有云还是 K8S 容器平台,越来越多的企业都希望 Apache Doris 针对云计算这种新型基础设施提供更加深度的适配,以便提供更加灵活强大的弹性能力。
在过去的一年,飞轮科技(SelectDB)技术团队在基于 Apache Doris 内核研发全托管企业级云数仓产品的过程中,设计并实现了全新的云原生存算分离架构(即 SelectDB Cloud)。基于云原生存算分离的架构,SelectDB Cloud 在此基础上提供了多计算集群负载隔离和计算弹性扩缩容等功能。
秉持着“推动开源技术创新、繁荣开源社区生态”的首要目标,在 Apache Doris 2.0 即将发布之际,SelectDB 技术团队正式宣布,将存算分离架构实现贡献至 Apache Doris 社区。 这一工作预计将于 2023 年 10 月前后完成,届时全部存算分离的代码都将会提交到 Apache Doris 社区主干分支中。
当存算分离代码合入 Apache Doris 社区后,Apache Doris 可以采用以下两种模式之一运行:存算一体的部署模式和存算分离的部署模式。在两种模式下运行的 Apache Doris 将以不同的方式来存储主数据。从用户使用体验上而言,绝大部分功能都是一致的,但是也会因为实现架构和部署模式的不同,带来一些功能上的差异。下面我们将分别介绍两种部署模式的核心特点和适用场景差异。
存算一体的分布式架构
存算一体架构,也是 Apache Doris 长久以来经历过数千家企业生产环境打磨、无论是性能亦或是易用性和稳定性都最为成熟的 MPP 分布式架构,总体架构图如下:
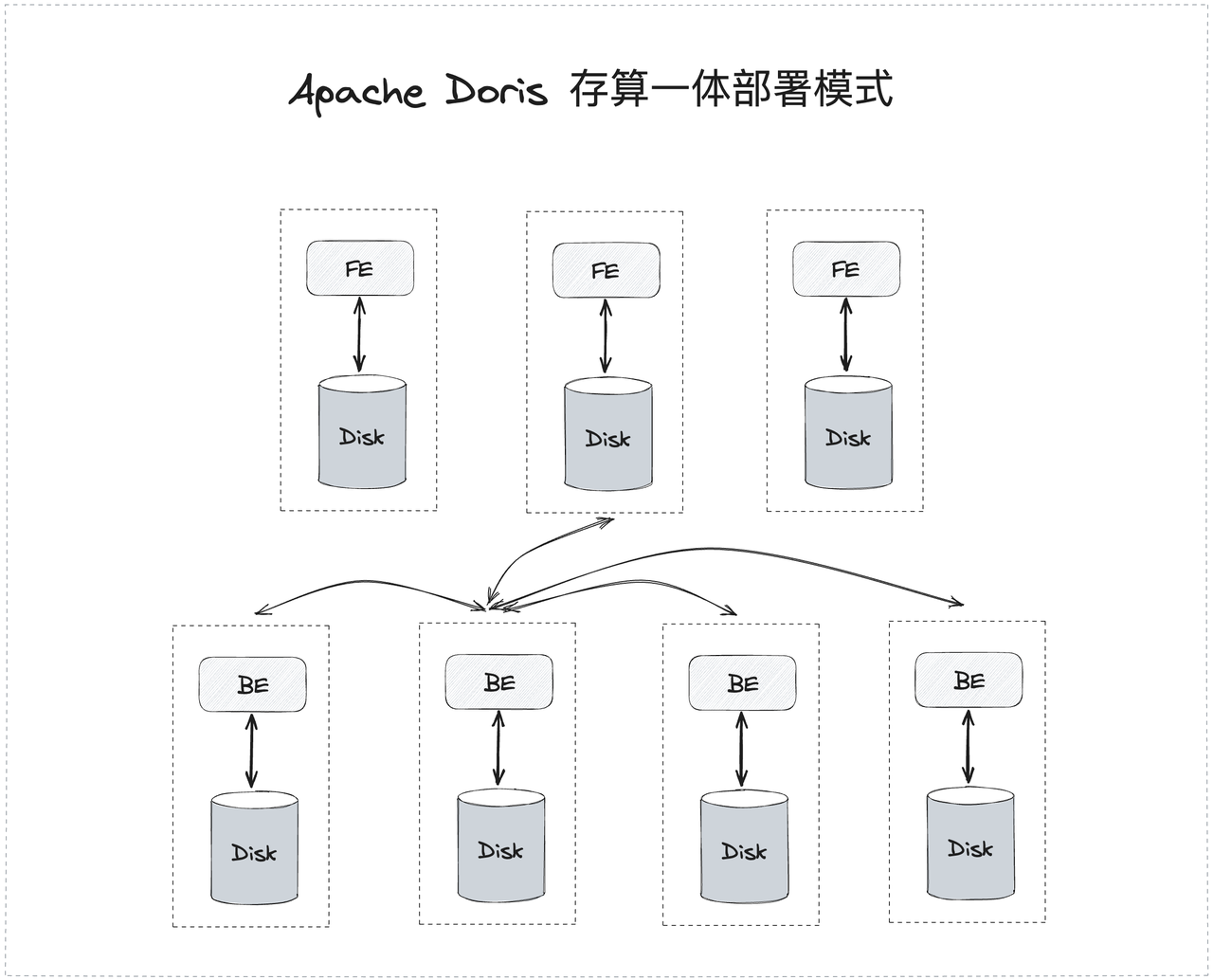
Apache Doris 存算一体架构
部署简易
在存算一体模式下,Apache Doris 不需要依赖类似外部共享文件系统或者对象存储,仅依赖物理服务器部署 FE 和 BE 两个进程即可完成集群的搭建,可以从一个节点扩展到数百个节点。这种不依赖第三方组件的部署模式极大降低了 Apache Doris 的使用门槛,甚至一台办公笔记本就可以完成 Apache Doris 的部署。
部署简单的同时,也拥有极简的运维成本:
- FE 和 BE 都支持横向线性扩展,扩缩容过程中无需停服,可正常提供稳定可靠的在线服务
- 数据多副本存储,自身的分布式管理框架自动管理数据副本的分布、修复和均衡,扩缩容时数据副本会自动在节点间负载均衡,无需任何人工操作
因为存算一体架构依赖少,不需要依赖任何其他其他系统,也增强了系统的稳定性。而存算分离模式则需要依赖于共享的存储系统。对于绝大多数企业来说,提供一个共享的存储系统并非如此轻而易举。依赖组件越多、任一组件的不稳定都会导致整个系统的稳定性受到影响。存算分离架构依赖共享存储系统,那么存储系统的稳定性和可用性、连接存储系统和计算节点的网络延迟以及稳定性,都会对整个存算分离架构的稳定性有着至关重要的影响。
性能优异
在存算一体模式下,Apache Doris 执行计算时,计算节点可直接访问本地存储数据,充分利用机器的 IO、减少不必要的网络开销、获得更极致的查询性能。而存算分离模式下网络传输带宽和耗时往往会制约系统性能的发挥,因此即便是 Hadoop、Spark 这种一开始便采用存算分离模式的分布式框架,也会尽量将计算逻辑推送到数据所在的节点,以此来提升计算任务的执行性能。
与此同时,存算一体模式对于谓词下推(Predicate Pushdown)更加友好,将条件判断逻辑更贴近数据源,减少查询时扫描、传输和计算的数据量,更能发挥系统的查询性能。相比存算分离模式,一般存储系统都没有执行谓词计算的能力,因此无法实现谓词下推,继而需要网络将大量的数据传输至计算侧。
冷热分层
在 Apache Doris 2.0 版本中,也实现了存算一体模式下的冷热数据分层。冷热数据分层功能使 Apache Doris 可以将冷数据下沉到存储成本更加低廉的对象存储中,同时冷数据在对象存储上的保存方式也从多副本变为单副本,存储成本进一步降至原先的三分之一。通过冷热数据分层,使得 Apache Doris 集群配置不再需要随着历史数据量的堆积而不断扩容机器。本质上,Apache Doris 2.0 版本的冷热数据分层也是一种存算分离的形态,只是实现了冷数据的存储分离。
关于 Apache Doris 2.0 冷热数据分层功能的详细介绍,可以参考 Apache Doris 冷热分层技术如何实现存储成本降低 70%?
存算一体架构的适用场景
基于以上的原因,如果满足下面任一条件,那么 Apache Doris 存算一体模式更加适合你:
- 简单使用 Doris,想快速试用一下,或者开发和测试使用
- 没有可靠的共享存储可用,比如 HDFS、Ceph、对象存储等
- 业务线独立维护 Apache Doris,没有专职 DBA 来维护 Doris 集群
- 不需要极致弹性扩缩容,不需要K8S容器化,不需要运行在公有云或者私有云上
存算分离的新架构
如上所述,如果存算一体模式有这么多优势,为何我们还需要提供存储计算分离的新架构?核心动力来自于新兴云计算基础设施的成熟,无论是公有云、私有云以及基于 K8s 的容器平台,云计算基础设施的革新催生了新的需求。
云本身就是存储计算分离的,其极致弹性带来极大的成本经济优势:
- 计算资源的弹性:可以根据计算负载的需求,按需购买或者按需扩缩容计算节点,在满足计算需求的情况下,使得成本达到最低;
- 存储资源的低成本与弹性:对象存储提供极其可靠的低成本存储,并且按照使用容量计费,这样可以让数据存储得更多更久。
即便是没有使用云平台的公司,也可以利用低成本的共享存储系统,在降低存储成本和提高计算弹性的同时,还能获得多计算集群等额外的优质特性。
未来存算分离架构如下图所示:

存算分离新架构
基于共享存储系统的主数据存储
在存算一体的架构下,数据主要存储在计算节点上,即使使用了冷热数据分层,热数据依旧只在计算节点上存储,计算节点需要依靠自身的多副本机制保证数据的可靠性。在存算分离架构下,计算节点不再存储主数据,而是将共享存储层作为统一的数据主存储空间,这将带来如下收益:
- 上层的计算节点可以做到无状态,可以实现完全关机
- 更便捷的数据共享,不同的集群之间以及不同的仓库可以便捷地进行数据共享
- 更简易的数据备份与恢复,以及实现数据的 Time Travel
当然,成熟稳定的 HDFS/对象存储还为系统带来极低的存储成本和极高的数据可靠性,并且大大简化上层计算节点的实现复杂度。
基于本地高速缓存的性能优化
存算分离依赖从网络上读取存储系统的数据来进行计算,在一定程度上会造成计算性能的下降,这也是相较于存算一体架构的主要劣势。为了解决这一问题,可以在本地利用 SSD 提供高速缓存。
正如存算一体通过冷热数据分层技术来大大缓解了存储和计算必须同时扩展的问题,同样在存算分离架构中引入计算节点本地高速缓存实际也是融合了存算一体的能力。这种本地高速缓存加上共享存储系统,我们也可以称之为混合模式,无论是 Snowflake 还是 Redshift,实际上都是采用了这种方式来应对底层对象存储系统性能不佳和网络传输带来的性能下降。
引入本地高速缓存后,系统会自动根据 LRU 来缓存最新写入和访问数据,当然也可以手动设定表的缓存策略。由于只是缓存,因此本地只存储了单个副本,这样大大提升了缓存利用率,相比存算一体模式可以降低 2/3 的高速存储使用。
另外,在存算一体的模式下,每个 Tablet 有 3 个节点来存储其 3 个数据副本,在三副本上都需要独立进行数据合并(Compaction)计算。而在存算分离下,只有一个节点进行数据合并计算,这样就可以降低 2/3 的数据合并计算量。
所以,通过引入本地高速缓存,不仅仅可以基本达到原来存算一体的性能,在有些情况下还会超越原来存算一体的性能。
多计算集群实现工作负载隔离
用户通常希望对同一份数据上的分析负载进行隔离。例如,导入的工作负载与查询的负载进行隔离,Adhoc 的大查询负载和在线点查询的负载间相互隔离,避免不同负载间相互资源抢占。
在 Apache Doris 2.0 版本中提供了工作负载组(Workload Group)的资源隔离方案。这个方案是一种软限隔离,可以为特定查询或者特定用户指定查询优先级,但是基于 Workload Group 的隔离无法达到存算分离模式下多计算集群的真正物理隔离性。
在存算分离模式下,提供了同一个仓库多个物理计算集群的隔离方式。因为主数据存储在共享的对象存储上,因此用户可以按需创建多个计算集群但共享同一份数据。计算集群之间是物理隔离的,可以独立扩缩容,其计算节点的本地高速缓存都是隔离的,这样保证了尽可能比较好的隔离性。
极致的弹性扩缩容
存储与计算的分离,带来的最大优势是存储和计算可以独立扩缩容。数据存储在 HDFS 或对象存储上,可以按需扩缩容。每个计算集群的计算节点,可以实现更加高效的弹性扩缩容,包括手动扩缩容、分时扩缩容以及自动停机。
存算分离特性演示
在此我们以 SelectDB Cloud 现有产品为例,来向大家演示全新存储计算分离模式的特性和功能。
SelectDB Cloud 上新建仓库

SelectDB Cloud 上多集群演示

SelectDB Cloud 上的手动扩缩容
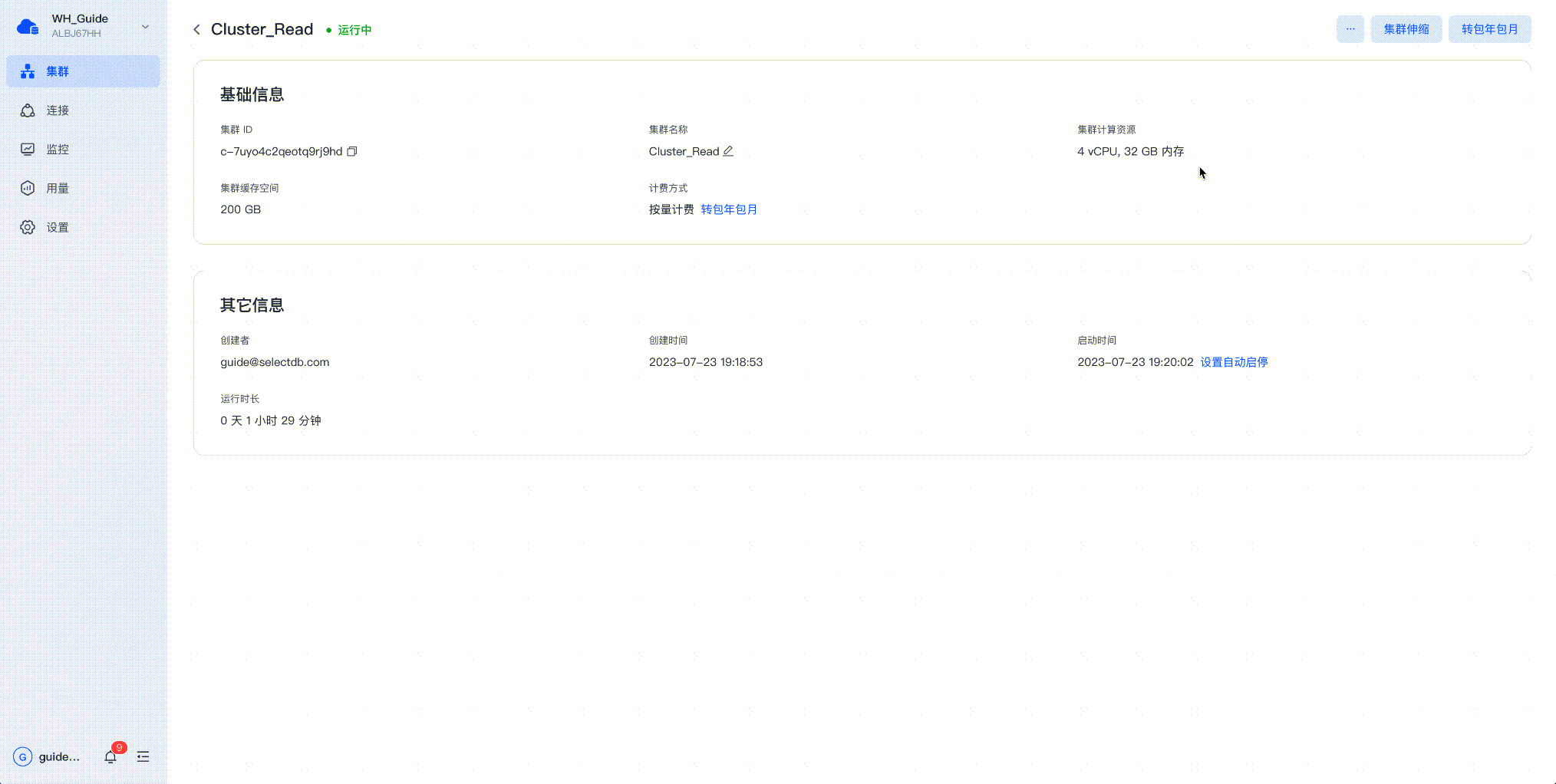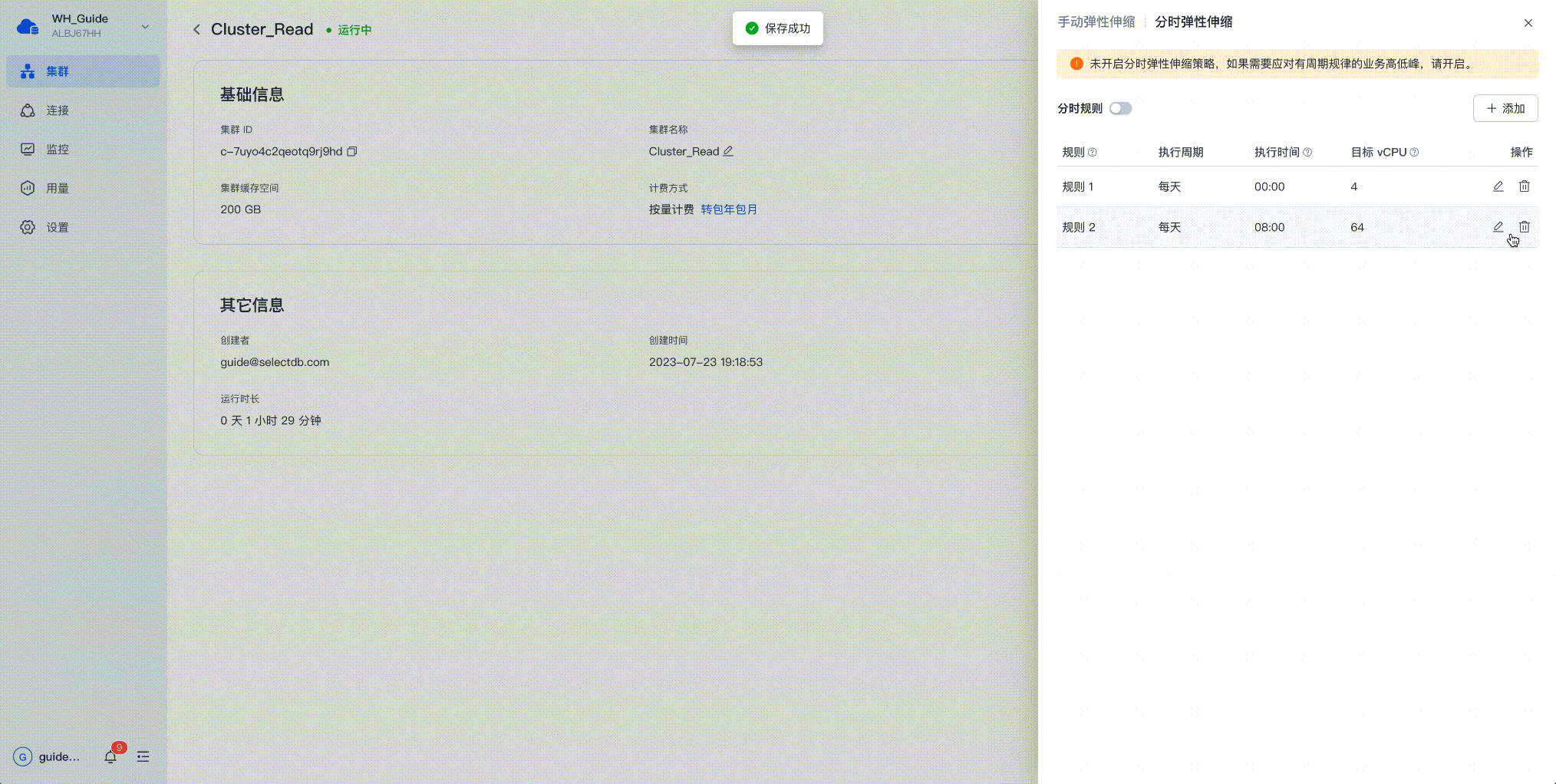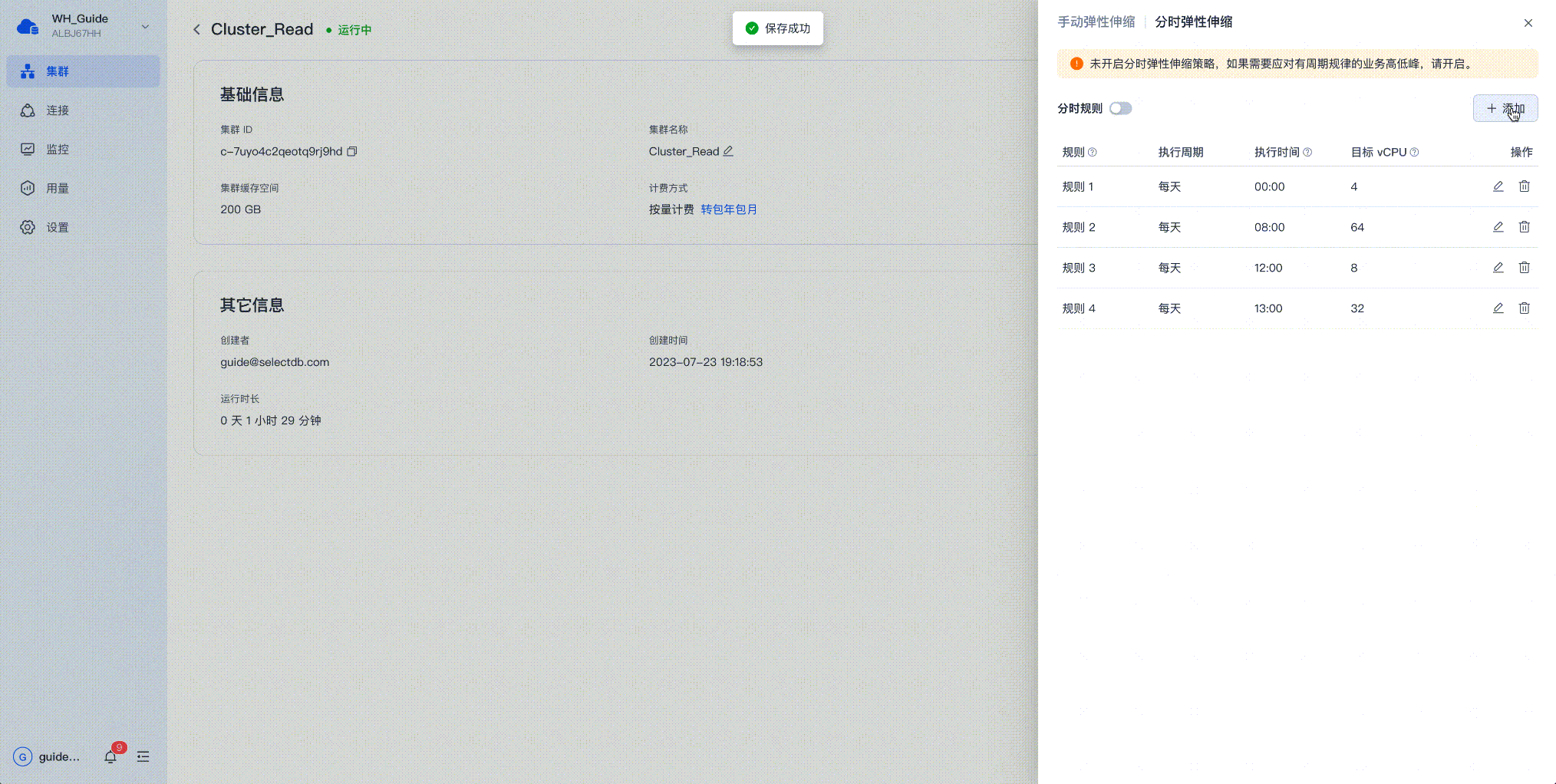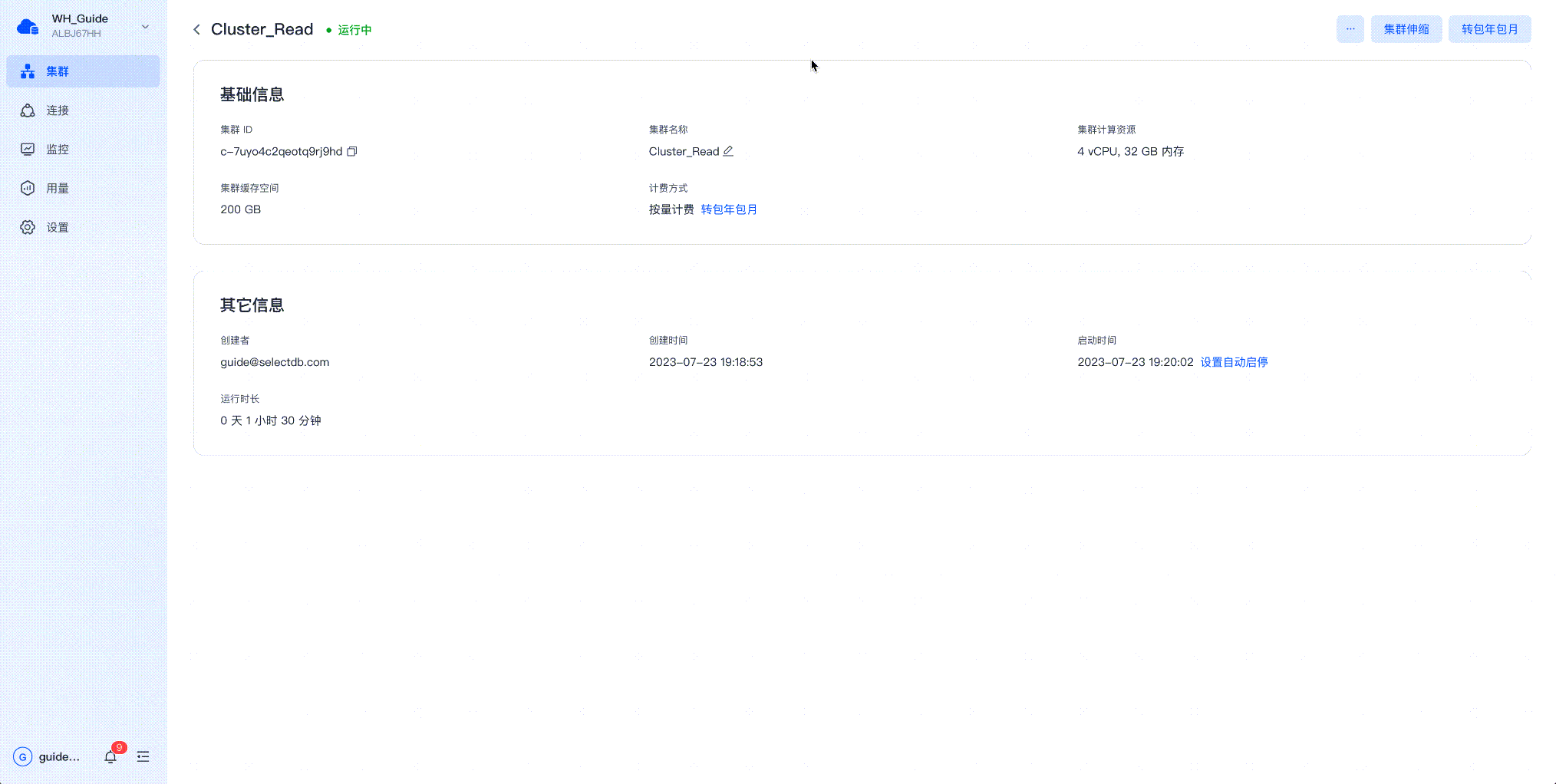
SelectDB Cloud 上的分时扩缩容
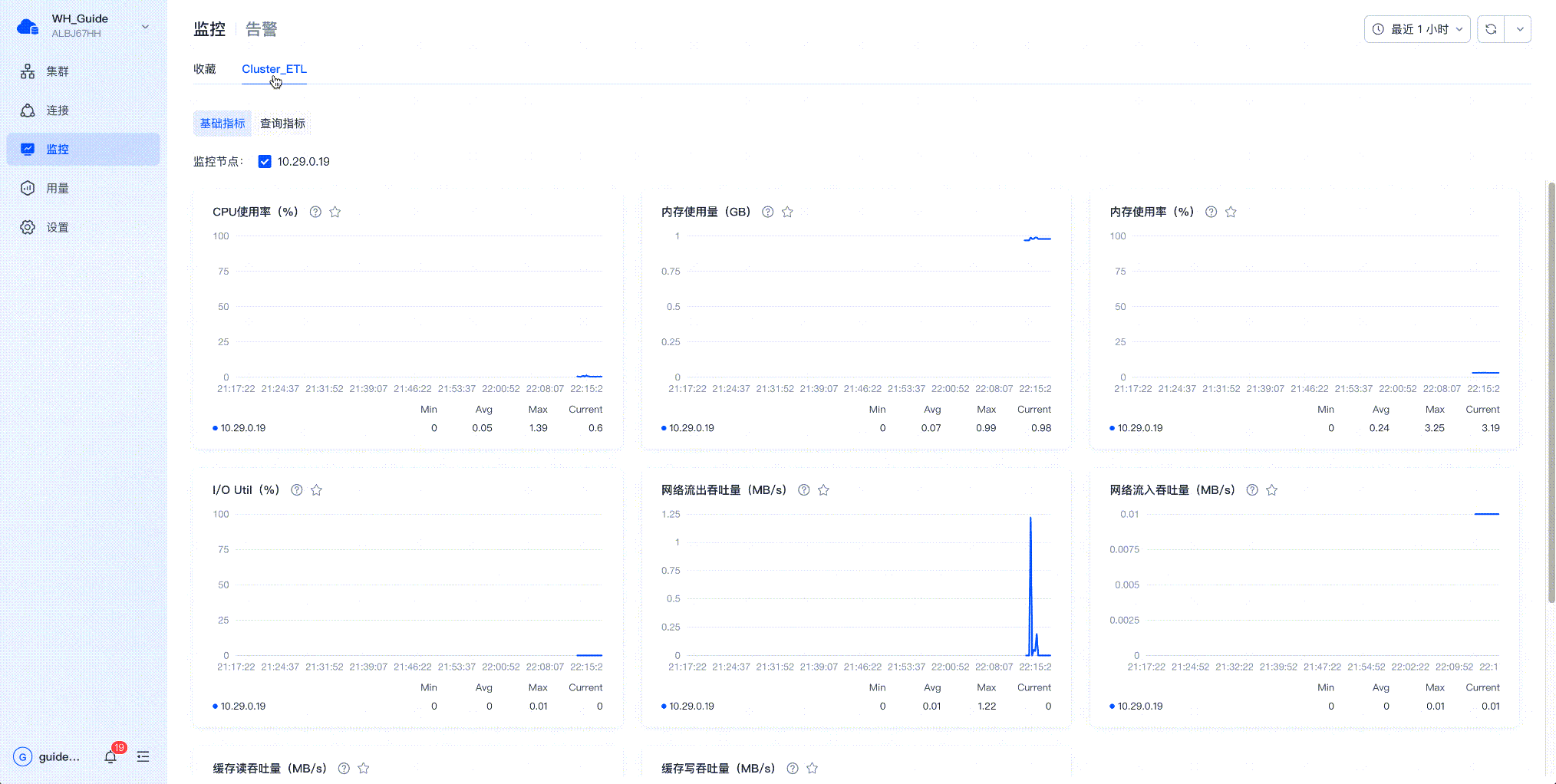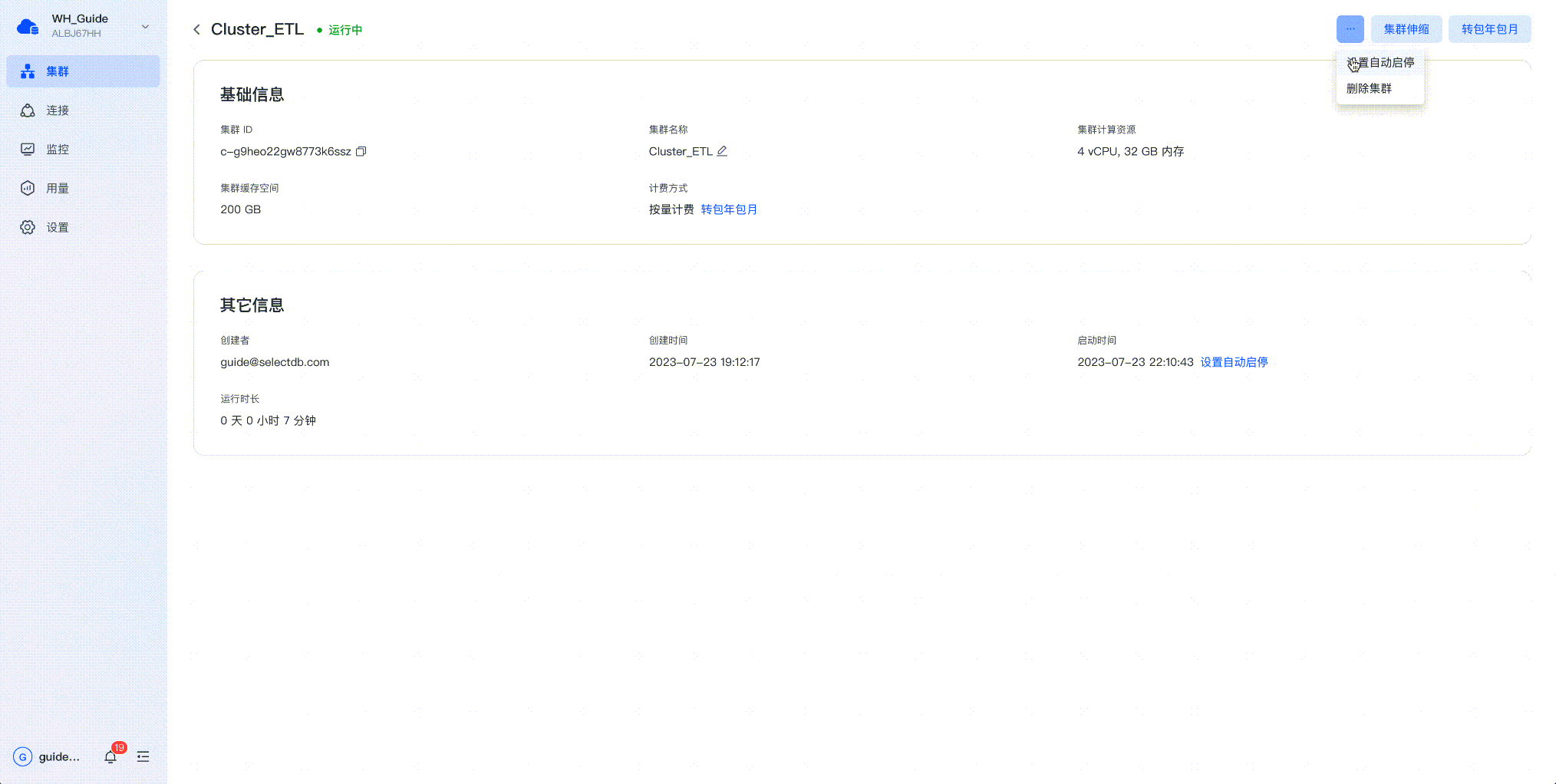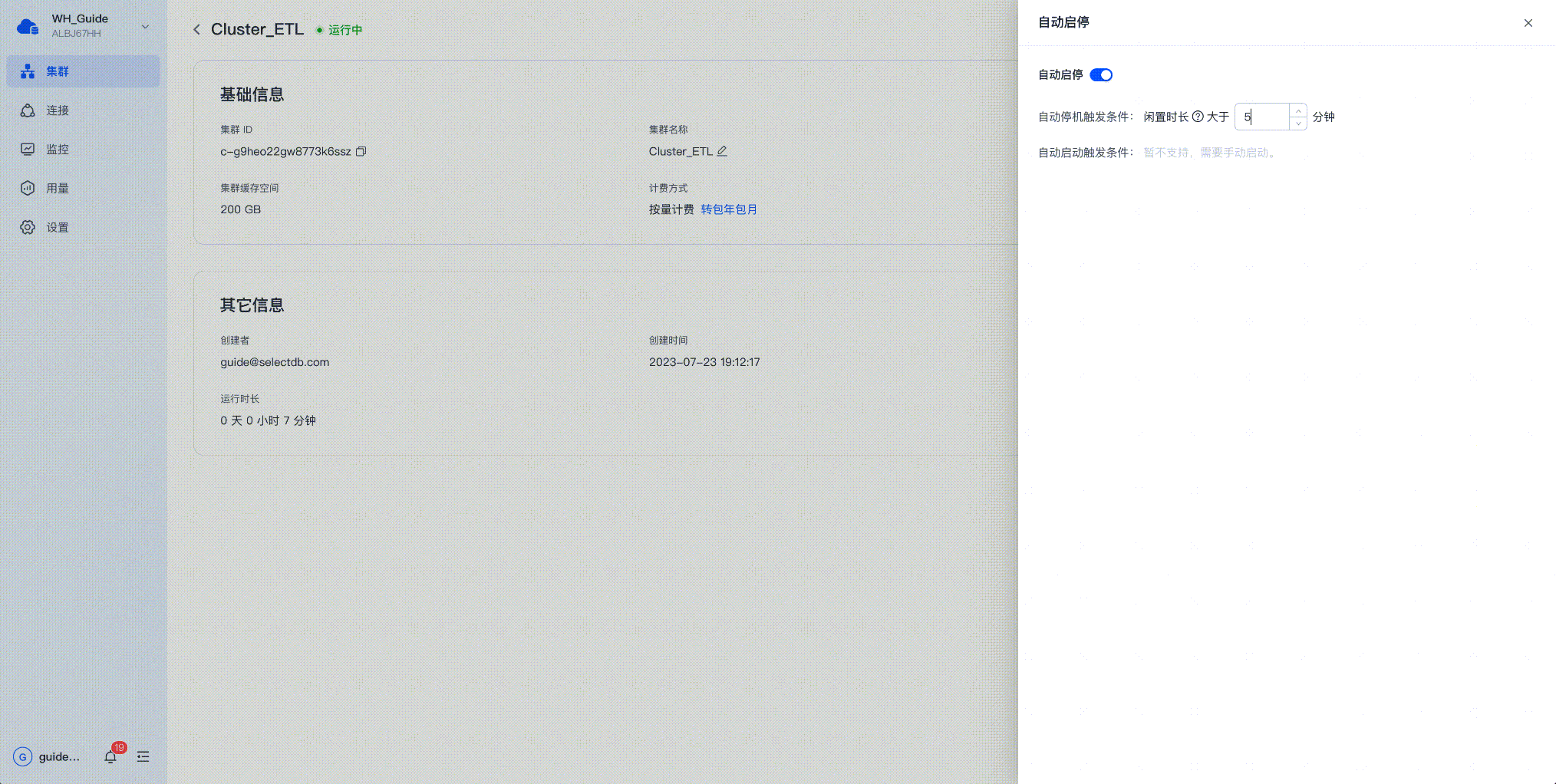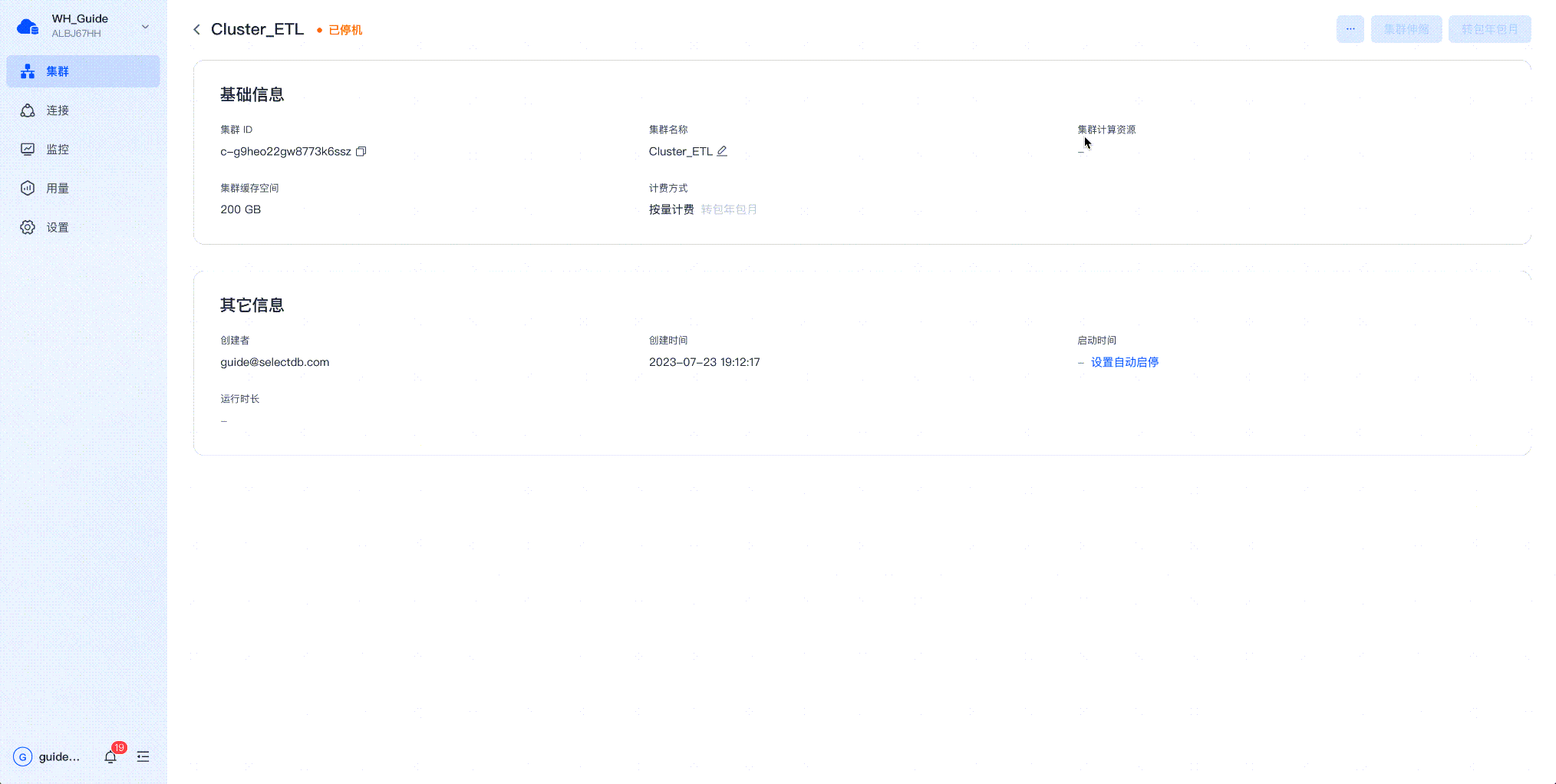
SelectDB Cloud上的集群自动启停
存算分离架构的适用场景
基于以上的介绍,毫无疑问也帮助我们进一步明晰了存算分离架构的适用场景,满足下列任一条件,存算分离架构更适合你:
- 如果已经使用公有云服务,那么存算分离架构绝对值得尝试
- 拥有可靠的共享存储系统,比如 HDFS、Ceph、对象存储等
- 需要极致弹性扩缩容,需要 K8S 容器化,需要运行在私有云上
- 有专职的团队维护整个公司的数据仓库平台
数据湖分析
需要说明的是,针对不同的技术群体,存储、计算与存算分离这些概念指代着不同的含义。
无论是 Apache Doris 的存算分离、还是 Snowflake 的存算分离,都是指单一系统内部存储和计算模块之间的分离。对于数据湖和湖仓一体(Lakehouse)的用户,则是希望做到更加彻底的分离,即计算系统和存储系统是两个不同的产品。存储系统通过统一的开放表格式面向计算系统开放,而计算系统也可以开放地对接不同的底层存储系统。
对于 Apache Doris 而言,无论是存算一体的架构还是存储计算分离的架构,都支持湖仓一体这种新型 Lakehouse 系统形态,即可以直接查询湖存储以及当前流行的各类开放表格式,包括 Hive、Iceberg 和 Hudi 等。需要说明的是,Apache Doris 目前对数据湖的读取已经比较完备,包括支持 Snapshot 读和 Time Travel,而后续还会进一步支持湖上数据的写回,形成更加闭环的数据分析和流转。
除了对数据湖的集成与分析,Apache Doris 目前还支持了对当前常见的关系型数据库、对象存储以及 HDFS 上 CSV、Parquet 等格式数据的直接查询分析。
未来计划
围绕着存算分离,SelectDB 技术团队会与 Apache Doris 社区未来一起推进下面相关方向的研发:
Workload Group 与多计算集群的融合
当前存算一体架构下的 Workload Group 与存算分离架构的多计算集群实际都是用来解决负载隔离的,一个偏软限,一个是硬限,当前具体实现方式存在一定差异,后面将考虑二者融合,对用户而言提供统一一致的使用体验。
与外部数据湖 更便捷的 数据 导入导出
外部数据湖的数据可以增量持续写入内表,也可以使得内表的数据可以增量持续写入到外表数据湖的格式。
通过提供更加便捷的外表导入内表的功能,Doris 可以持续加载最新的数据湖数据,以便提供更高的数据计算性能。
通过提供更加便捷的内表导出外表的功能,使得内表的数据可以增量写出为开放的外表格式。数据转换为开放格式,一个是方便与相关大数据生态系统打通,另一个是打消企业对封闭数据格式被锁定的担忧。
实现共享的高速缓存,与计算节点进一步分离
当前存算分离模式下,高速缓存使用的是计算节点的本地磁盘,所以计算节点还不能做成真正的无状态。当进行节点快速扩容的时候,需要考虑缓存的预热均衡;当进行节点快速缩容的时候,需要考虑缓存的失效,以及向其他节点的缓存转移。未来,我们将实现一种与计算节点分离的共享高速缓存,实现计算、缓存和对象存储完全的分离,以便提供秒级扩缩容能力。
存算一体和存算分离两种模式的融合
存算一体和存算分离的架构在部署之初就需要确定下来,而对于多数用户都可能存在不同架构之间的转化,因此后续也会不断改进实现方式,让两种模式间可以更便捷地进行相互转换,甚至逐步融合成一套架构。
交流与试用
存算分离架构的代码将于 2023 年 10 月份前后提交至 Apache Doris 社区,当前正处于紧锣密鼓的代码整理阶段。对于存算分离架构感兴趣的用户可以扫描下面二维码加入存算分离技术沟通群,了解代码开源的最新进展。当前,我们也开放了部分企业的提前试用,有需要可以联系 [email protected]。
关于 MyBatis-Flex 抄袭 MyBatis-Plus 的澄清 Arc 浏览器正式发布 1.0,声称是 Chrome 的替代品 OpenAI 正式上线安卓版 ChatGPT VS Code 优化名称混淆压缩,将内置 JS 减小 20%! LK-99:第一种室温常压超导体? 马斯克“零元购”,强夺 @x 推特账号 Python 指导委员会计划接受 PEP 703 提案,让全局解释器锁成为可选 特斯拉中国商城上架 1TB 固态硬盘,售价 2720 元 ProxyPin - 全平台系统开源免费抓包软件 Stack Overflow 访问量大幅下降,马斯克称其已被 LLM 取代