Redis实现skipList(跳表)
项目介绍
非关系型数据库redis,以及levedb,rockdb其核心存储引擎的数据结构就是跳表。
本项目就是基于跳表实现的轻量级键值型存储引擎,使用C++实现。插入数据、删除数据、查询数据、数据展示、数据落盘、文件加载数据,以及数据库大小显示。
函数提供接口
int insert_element(K,V); (插入数据)
void display_list(); (展示跳表中数据)
bool search_element(K); (搜索数据)
void delete_element(K); (删除数据)
void dump_file(); (读取数据)
void load_file(); (存放数据)
int size(); (元素数量)
跳表原理解释
什么是跳表
单链表是是一种各性能比较优秀的动态数据结构,可以支持快速的插入、删除、查找操作。
即便在有序的单链表中,插入、删除操作仍然时间复杂度为O(N),那么有没有更好的优化方法呢?
跳表是在单链表的基础上进行对数据结构的优化,将插入、删除、查找时间复杂度都控制在O(log N)。我们这主要解释跳表原理和怎么讲单链表的插入、删除操作时间复杂度降低到O(log N)
我们可以按照元素的个数(n)分成好多层,每一层都有对应元素的索引。例如第一层就是原始单链表,第一层索引个数就是n,然而到了第二层,每个元素都有50%的几率上升到第二层。(解释:咱们要求插入、删除操作都控制在O(log N),每个元素都是随机,这个时间复杂度是O(1),如果隔一元素上升一层的话,要加判定条件,就需要时间复杂度为O(N))

下列是按照最优操作建的图


查找元素时,就是从顶层索引开始,对于每一层,大于当前索引对应的值,小于下层对应的值,开始执行下一层的操作。
当查找元素8时,按照二级索引,找到区间[ 7-12 ],执行下一层,执行[ 7-9 ]区间。继续执行下一层,找到元素8,只需要四次操作!
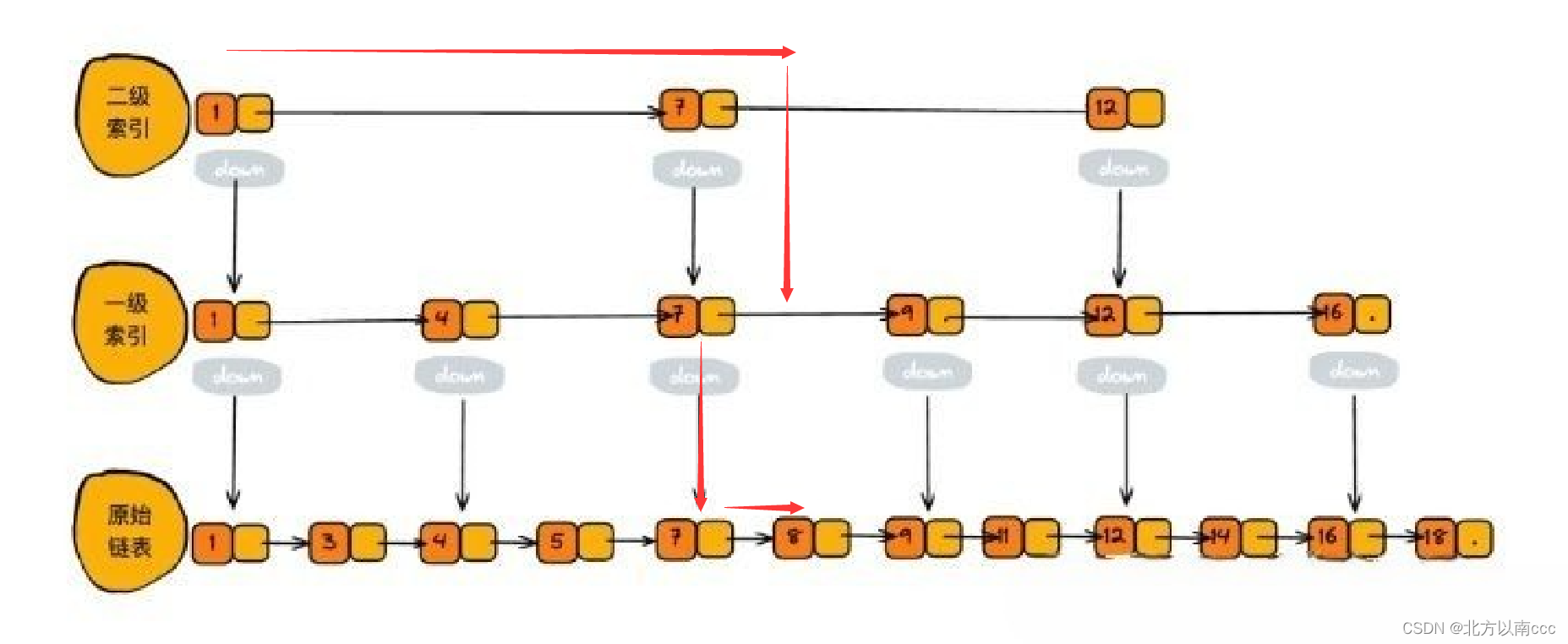
但是现在发现如果按照单链表查找的8话也只需要5次操作,根本没有表示出跳表的强大魅力!!!
那接下来咱们试试更多元素的查找
 原始链表有64个元素,查找第60个元素,如果按照单链表查找需要60次操作,如果跳表操作的话就可以6次操作即可查找出来第60个元素,符合时间复杂度O(log N)。
原始链表有64个元素,查找第60个元素,如果按照单链表查找需要60次操作,如果跳表操作的话就可以6次操作即可查找出来第60个元素,符合时间复杂度O(log N)。
这次是不是就可以体现跳表的强大能力啦!!!
分析跳表插入、删除、查找时间复杂度
插入、删除、查找在跳表中都是按照索引的方式查找,可以说三种方式几乎一样。以查找为例:
单链表元素个数为16,按照每元素50%的几率上升一层
0级(原始链表)索引数量 : 16
1级索引数量:8
2级索引数量:4
3级索引数量:2
基本可以确定索引数量按照层数以log次方递减。
分析跳表的空间复杂度
跳表的时间复杂度为O(log N),空间复杂度是拿空间换时间的操作,索引个数随着层数减半,成等比数列,空间复杂度为O(N)。
跳表索引更新
从上面插入元素8的过程中发现,我们插入8时没有更新索引,会出现 2 个索引结点之间数据非常多的情况,若频繁的插入数据,但不更新索引,最终会退化成单链表的数据结构,会导致查找数据效率变低。
跳表作为一个动态的数据结构,需要动态的维护索引与原始链表中的大小。若原始链表插入的结点变多了,那么相应的索引结点也需要增加,避免查找、删除、插入的性能下降。
其实是通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值rand,那就将这个结点添加到第一级到第rand级这rand级索引中。
代码源码
skipList.h包括函数的源码及详解
#include<iostream>
#include<cmath>
#include<cstring>
#include<mutex>
#include<fstream>
#define STORE_FILE "store/dumpFile"
std::mutex mtx; //代表互斥锁 ,保持线程同步
std::string delimiter=":"; //存放到STORE_FILE中时,将delimiter也存入进文件中,用于get_key_value_from_string的key与value区分
template<typename K,typename V>
class Node{
public:
Node(){
}
Node(K k,V v,int);
~Node();
K get_key() const;
V get_value() const;
void set_value(V);
Node <K,V> **forward; //forward是指针数组,用于指向下一层 例如 forward[0]是指向第一层,forward[1]指向上一层
int node_level;
private:
K key;
V value;
};
template<typename K,typename V>
Node<K,V>::Node(const K k, const V v, int level)
{
this->key=k;
this->value=v;
this->node_level=level;
this->forward=new Node<K,V> *[level+1];
memset(this->forward,0,sizeof(Node<K,V>*)*(level+1));
};
template<typename K,typename V>
Node<K,V>::~Node()
{
delete []forward;
};
template<typename K,typename V>
K Node<K,V>::get_key() const {
return key;
};
template<typename K,typename V>
V Node<K,V>::get_value() const {
return value;
};
template<typename K,typename V>
void Node<K,V>::set_value(V value)
{
this->value=value;
};
template<typename K,typename V>
class SkipList{
public:
SkipList(int);
~SkipList();
int get_random_level();
Node<K,V>*create_node(K,V,int);
int insert_element(K,V);
void display_list();
bool search_element(K);
void delete_element(K);
void dump_file();
void load_file();
int size();
private:
void get_key_value_from_string(const std::string &str,std::string*key,std::string *value);
bool is_valid_string(const std::string &str);
private:
int _max_level; //跳表的最大层级
int _skip_list_level; //当前跳表的有效层级
Node<K,V> *_header; //表示跳表的头节点
std::ofstream _file_writer; //默认以输入(writer)方式打开文件。
std::ifstream _file_reader; //默认以输出(reader)方式打开文件。
int _element_count; //表示跳表中元素的数量
};
//create_node函数:根据给定的键、值和层级创建一个新节点,并返回该节点的指针
template<typename K,typename V>
Node<K,V> *SkipList<K,V>::create_node(const K k, const V v, int level)
{
Node<K,V>*n=new Node<K,V>(k,v,level);
return n;
}
//insert_element 函数:插入一个新的键值对到跳表中。通过遍历跳表,找到插入位置,并根据随机层级创建节点。
//如果键已存在,则返回 1,表示插入失败;否则,插入成功,返回 0。
template<typename K,typename V>
int SkipList<K,V>::insert_element(const K key,const V value)
{
mtx.lock();
Node<K,V> *current=this->_header;
Node<K,V> *update[_max_level];
memset(update,0,sizeof(Node<K,V>*)*(_max_level+1));
//99-113行-为查找key是否在跳表中出现,也可以直接调用search_element(K key)
for(int i=_skip_list_level;i>=0;i--)
{
while(current->forward[i]!=NULL&¤t->forward[i]->get_key()<key)
{
current=current->forward[i];
}
update[i]=current; //update是存储每一层需要插入点节点的位置
}
current=current->forward[0];
if(current!=NULL&¤t->get_key()==key)
{
std::cout<<"key:"<<key<<",exists"<<std::endl;
mtx.unlock();
return 1;
}
//添加的值没有在跳表中
if(current==NULL||current->get_key()!=key)
{
int random_level=get_random_level();
if(random_level>_skip_list_level)
{
for(int i=_skip_list_level+1;i<random_level+1;i++)
{
update[i]=_header;
}
_skip_list_level=random_level;
}
Node<K,V>*inserted_node= create_node(key,value,random_level);
for(int i=0;i<random_level;i++)
{
inserted_node->forward[i]=update[i]->forward[i]; //跟链表的插入元素操作一样
update[i]->forward[i]=inserted_node;
}
std::cout<<"Successfully inserted key:"<<key<<",value:"<<value<<std::endl;
_element_count++;
}
mtx.unlock();
return 0;
}
//display_list函数:输出跳表包含的内容、循环_skip_list_level(有效层级)、从_header头节点开始、结束后指向下一节点
template<typename K,typename V>
void SkipList<K,V>::display_list()
{
std::cout<<"\n*****SkipList*****"<<"\n";
for(int i=0;i<_skip_list_level;i++)
{
Node<K,V>*node=this->_header->forward[i];
std::cout<<"Level"<<i<<":";
while(node!=NULL)
{
std::cout<<node->get_key()<<":"<<node->get_value()<<";";
node=node->forward[i];
}
std::cout<<std::endl;
}
}
//dump_file 函数:将跳跃表的内容持久化到文件中。遍历跳跃表的每个节点,将键值对写入文件。
//其主要作用就是将跳表中的信息存储到STORE_FILE文件中,node指向forward[0],每一次结束后再将node指向node.forward[0]。
template<typename K,typename V>
void SkipList<K,V>::dump_file()
{
std::cout<<"dump_file-----------"<<std::endl;
_file_writer.open(STORE_FILE);
Node<K,V>*node=this->_header->forward[0];
while(node!=NULL)
{
_file_writer<<node->get_key()<<":"<<node->get_value()<<"\n";
std::cout<<node->get_key()<<":"<<node->get_value()<<"\n";
node=node->forward[0];
}
_file_writer.flush(); //设置写入文件缓冲区函数
_file_writer.close();
return ;
}
//将文件中的内容转到跳表中、每一行对应的是一组数据,数据中有:分隔,还需要get_key_value_from_string(line,key,value)将key和value分开。
//直到key和value为空时结束,每组数据分开key、value后通过insert_element()存到跳表中来
template<typename K,typename V>
void SkipList<K,V>::load_file()
{
_file_reader.open(STORE_FILE);
std::cout<<"load_file----------"<<std::endl;
std::string line;
std::string *key=new std::string();
std::string *value=new std::string();
while(getline(_file_reader,line))
{
get_key_value_from_string(line,key,value);
if(key->empty()||value->empty())
{
continue;
}
int target=0;
std::string str_key=*key; //当时定义的key为int类型,所以将得到的string类型的 key转成int
for(int i=0;i<str_key.size();i++)
{
target=target*10+str_key[i]-'0';
}
int Yes_No=insert_element(target,*value);
std::cout<<"key:"<<*key<<"value:"<<*value<<std::endl;
}
_file_reader.close();
}
//表示跳表中元素的数量
template<typename K,typename V>
int SkipList<K,V>::size() {
return _element_count;
}
//从STORE_FILE文件读取时,每一行将key和value用 :分开,此函数将每行的key和value分割存入跳表中
template<typename K,typename V>
void SkipList<K,V>::get_key_value_from_string(const std::string &str, std::string *key, std::string *value)
{
if(!is_valid_string(str)) return ;
*key=str.substr(0,str.find(delimiter));
*value=str.substr(str.find(delimiter)+1,str.length());
}
//判断从get_key_value_from_string函数中分割的字符串是否正确
template<typename K,typename V>
bool SkipList<K,V>::is_valid_string(const std::string &str)
{
if(str.empty())
{
return false;
}
if(str.find(delimiter)==std::string::npos)
{
return false;
}
return true;
}
//遍历跳表找到每一层需要删除的节点,将前驱指针往前更新,遍历每一层时,都需要找到对应的位置
//前驱指针更新完,还需要将全为0的层删除
template<typename K,typename V>
void SkipList<K,V>::delete_element(K key)
{
mtx.lock();
Node<K,V>*current=this->_header;
Node<K,V>*update[_max_level+1];
memset(update,0,sizeof(Node<K,V>*)*(_max_level+1));
for(int i=_skip_list_level;i>=0;i--)
{
while(current->forward[i]!=NULL&¤t->forward[i]->get_key()<key)
{
current=current->forward[i];
}
update[i]=current;
}
current=current->forward[0];
if(current!=NULL&¤t->get_key()==key)
{
for(int i=0;i<=_skip_list_level;i++) {
if (update[i]->forward[i] != current) {
break;
}
update[i]->forward[i] = current->forward[i];
}
while(_skip_list_level>0&&_header->forward[_skip_list_level]==0)
{
_skip_list_level--;
}
std::cout<<"Successfully deleted key"<<key<<std::endl;
_element_count--;
}
mtx.unlock();
return ;
}
//遍历每一层,从顶层开始,找到每层对应的位置,然后进入下一层开始查找,直到查找到对应的key
//如果找到return true 输出Found 否则 return false ,输出Not Found
template<typename K,typename V>
bool SkipList<K,V>::search_element(K key)
{
std::cout<<"search_element------------"<<std::endl;
Node<K,V> *current=_header;
for(int i=_skip_list_level;i>=0;i--)
{
while(current->forward[i]&¤t->forward[i]->get_key()<key)
{
current=current->forward[i];
}
}
current=current->forward[0];
if(current and current->get_key()==key)
{
std::cout<<"Found key:"<<key<<",value:"<<current->get_value()<<std::endl;
return true;
}
std::cout<<"Not Found Key:"<<key<<std::endl;
return false;
}
template<typename K,typename V>
SkipList<K,V>::SkipList(int max_level)
{
this->_max_level=max_level;
this->_skip_list_level=0;
this->_element_count=0;
K k;
V v;
this->_header=new Node<K,V>(k,v,_max_level);
};
//释放内存,关闭_file_writer _file_reader
template<typename K,typename V>
SkipList<K,V>::~SkipList()
{
if(_file_writer.is_open())
{
_file_writer.close();
}
if(_file_reader.is_open())
{
_file_reader.close();
}
delete _header;
}
//生成一个随机层级。从第一层开始,每一层以 50% 的概率加入
template<typename K,typename V>
int SkipList<K,V>::get_random_level()
{
int k=1;
while(rand()%2)
{
k++;
}
k=(k<_max_level)?k:_max_level;
return k;
};
main函数负责函数的调用测数据测试。
//所有函数的解释与用法都在skiplist.h中,main主函数主要用于测试各种函数是否可行
#include <iostream>
#include "skiplist.h"
#define FILE_PATH "./store/dumpFile"
int main()
{
SkipList<int ,std::string>skipList(6);
skipList.insert_element(1,"学习");
skipList.insert_element(3,"跳表");
skipList.insert_element(7,"去找");
skipList.insert_element(8,"GitHub:");
skipList.insert_element(9,"shy2593666979");
skipList.insert_element(19,"赶紧给个");
skipList.insert_element(19,"star!");
std::cout<<"skipList.size = "<<skipList.size()<<std::endl;
skipList.dump_file();
skipList.search_element(8);
skipList.search_element(9);
skipList.display_list();
skipList.delete_element(3);
skipList.load_file();
std::cout<<"skipList.size = "<<skipList.size()<<std::endl;
skipList.display_list();
}
下载源码地址
Github下载地址(国际网站)
Gitee下载地址 (国内网站)
参考资料
https://github.com/youngyangyang04/Skiplist-CPP
https://juejin.cn/post/7149101822756519949