
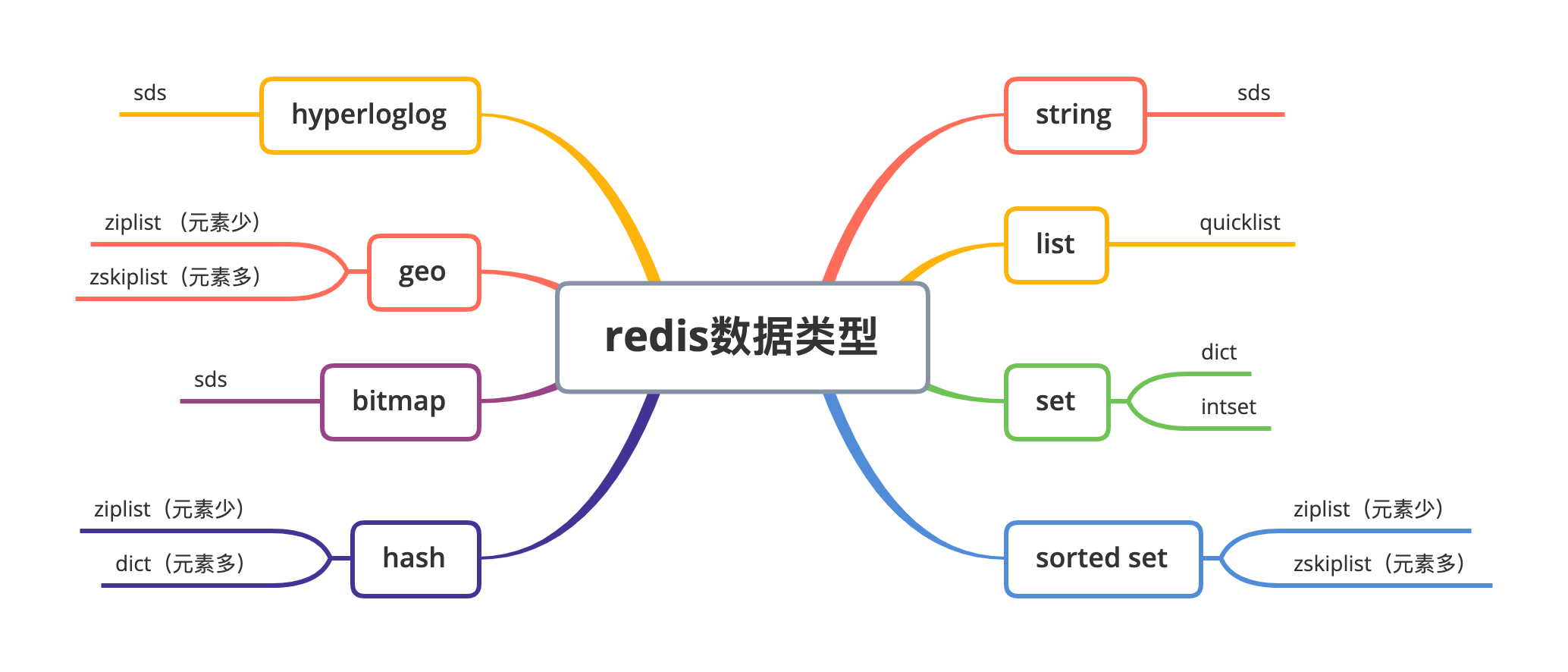
介绍
在redis 3.0版本及以前,采用压缩链表(ziplist)以及双向链表(linkedlist)作为list的底层实现。当元素少时用ziplist,当元素多时用linkedlist
在redis 3.0版本以后,采用quicklist作为list的底层实现
quicklist是一个双向链表,链表中每个节点是一个ziplist
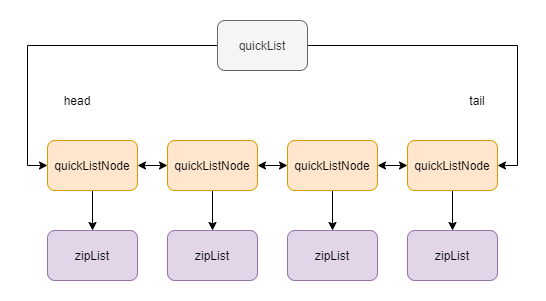
假如说一个quicklist包含4个quickListNode,每个节点的ziplist包含3个元素,则这里list中存的值为12个。
quicklist为什么要这样设计呢?大概是基于空间和效率的一个折中
- 双向链表方便在表两端执行push和pop操作。但是内存开销比较大,除了要保存数据,还要保存前后节点的指针。并且每个节点是单独的内存块,容易造成内存碎片
- ziplist是一块连续的内存,不用前后项指针,节省内存。但是当进行修改操作时,会发生级联更新,降低性能
于是结合两者优点的quicklist诞生了,但这又会带来新的问题,每个ziplist存多少元素比较合适呢?
- ziplist越短,内存碎片增多,影响存储效率。当一个ziplist只存一个元素时,quicklist又退化成双向链表了
- ziplist越长,为ziplist分配大的连续的内存空间难度也就越大,会造成很多小块的内存空间被浪费,当quicklist只有一个节点,元素都存在一个ziplist上时,quicklist又退化成ziplist了
我们可以在redis.conf配置文件中通过如下参数来控制ziplist能存的节点元素
list-max-ziplist-size -2
- 当值为正数时,表示quicklistNode节点上的ziplist的长度。比如当这个值为5时,每个quicklistNode节点的ziplist最多包含5个数据项
- 当值为负数时,表示按照字节数来限制quicklistNode节点上的ziplist的的长度,可选值为-1到-5,每个值的含义如下
| 值 | 含义 |
|---|---|
| -1 | ziplist节点最大为4kb |
| -2 | ziplist节点最大为8kb |
| -3 | ziplist节点最大为16kb |
| -4 | ziplist节点最大为32kb |
| -5 | ziplist节点最大为64kb |
因为列表的两端是经常被访问的数据,而中间的数据则不怎么被访问。基于这个特性,redis对list提供了如下配置项,能够对节点中间的数据进行压缩,进一步节省内存
list-compress-depth 0
值的含义如下
| 值 | 含义 |
|---|---|
| 0 | 特殊值,表示都不压缩 |
| 1 | quicklist两端各有1个节点不压缩,中间的节点压缩 |
| 2 | quicklist两端各有2个节点不压缩,中间的节点压缩 |
| n | quicklist两端各有n个节点不压缩,中间的节点压缩 |
这个参数表示的是quicklist两端不被压缩的节点个数(即quicklistNode的个数)
quicklist数据结构定义
typedef struct quicklist {
// 指向quicklist的首节点
quicklistNode *head;
// 指向quicklist的尾节点
quicklistNode *tail;
// quicklist中元素总数
unsigned long count; /* total count of all entries in all ziplists */
// quicklistNode节点个数
unsigned long len; /* number of quicklistNodes */
// ziplist大小设置,存放list-max-ziplist-size参数的值
int fill : 16; /* fill factor for individual nodes */
// 节点压缩深度设置,存放list-compress-depth参数的值
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
quicklistNode定义如下
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
prev:指向前一个节点的指针
next:指向后一个节点的指针
zl:数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构
sz:表示zl指向的ziplist的总大小(包括zlbytes, zltail, zllen, zlend和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小
count:ziplist里面包含的元素个数
encoding:ziplist是否压缩了,1没有压缩,2是用lzf进行压缩
container:是一个预留字段。本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作一个数据容器,所以叫container)。但是,在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器
recompress:当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩
attempted_compress:这个值只对Redis的自动化测试程序有用
extra:扩展字段,目前没有使用
参考博客
[1]http://zhangtielei.com/posts/blog-redis-quicklist.html