前言
关于Redis的相关知识点可看我之前的文章:
科普下Redis数据类型中底层的数据结构(常考点)
| 数据类型 | 可以存储的值 | 操作 | 应用场景 |
|---|---|---|---|
| string | 字符串、整数或者浮点 | 对整个字符串或者字符串的其中一部分执行操作,对整数和浮点数执行自增或者自减操作 | 做简单的键值对缓存,计数器,共享session以及限速 |
| list | 列表 | 从两端压入或者弹出元素,对单个或者多个元素进行修剪,只保留一个范围内的元素 | 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的 |
| set | 无序集合 | 添加、获取、移除单个元素,检查一个元素是否存在于集合中。计算交集、并集、差集。从集合里面随机获取元素 | 交集、并集、差集的操作,比如交集,可以把两个人的粉丝列表整一,或者是用户的喜好标签等 |
| hash | 包含键值对的无序散列 | 添加、获取、移除单个键值对。获取所有键值对。检查某个键是否存在 | 结构化的数据,比如一个对象 |
| zset | 有序集合 | 添加、获取、删除元素。根据分值范围或者成员来获取元素。计算一个键的排名。 | 去重但可以排序,如获取排名前几名的用户,排行榜等 |
1. zset底层结构
zset主要是有序集合
底层结构有压缩列表和跳表两种结构
| 数据结构 | 描述 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|---|
| 压缩列表 | 在列表的前面加入了列表长度、尾部偏移量、列表元素个数,在列表的后面加入了列表结束标识 | 有利于快速的找到首尾节点 | 不利于找其他的元素,只能一个个遍历 | 1.有序集合保存的元素数量小于128个 2.有序集合保存的所有元素长度小于64字节 |
| 跳表 | 在链表的基础上增加了多级索引,通过多级索引位置的转跳,实现快速查找元素 | 可快速查找对应元素,用空间换实践,实践复杂度笑了 | 元素数量比较多 或者 元素比较长的字符串 |
2. 跳表结构
之所以有跳表这个结构是为了解决平衡二叉树复杂问题
hash可快速定位,但是不是有序
若用二叉查找树,有序的话会退化为链表
链表加平衡因子,变成平衡二叉树(可分为b树、b+树、红黑树等)
跳表和平衡二叉树的区别如下:
| 共同点 | 差异 |
|---|---|
| 查找、插入、删除的时间复杂度都是o(logn) | 跳表 查找区间元素比较快,但是 平衡二叉树 查找区间元素 一开始需要定位左端点,之后查找后续节点比较费时 |
最后选用了跳表,是因为跳表实现起来容易,所以用它来实现有序集合
基本的性质:
-
主要是单链表 + 索引的方式实现,以空间换时间的形式,提高查找速度
-
底层主要由两个结构组成
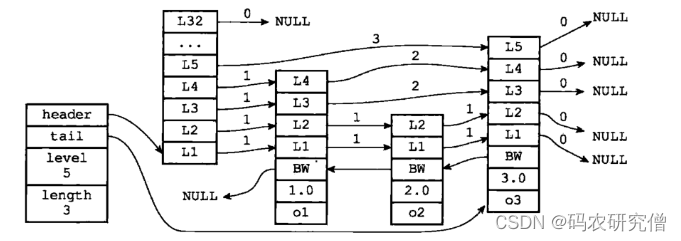
- zskiplist:保存跳表信息(头尾节点、跳表层数最大的层数、长度)
- zkiplistnode:保存跳表节点信息(比如level层:每层都有两个属性,指针和跨度,跨度大距离远)
类似如下结构,原本是1到6的链表结构,专门找5这个数字的话,需要遍历5个节点
如果每隔一个数字建立一个索引,具体如下:
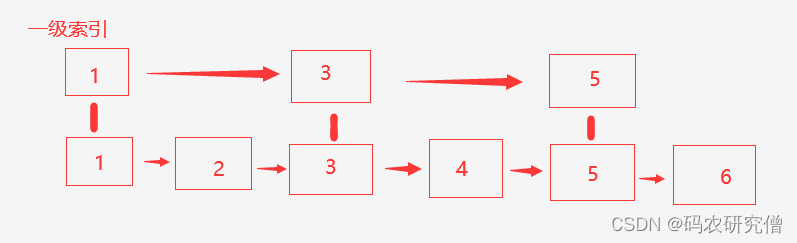
通过一级索引来减少遍历节点的次数
如果觉得一级索引比较慢,可以在一级索引的基础上在建立索引
当数据量比较大的时候,跳表查询、插入、删除的复杂度均为为 O(logn),本身的主要思想是二分法
3. 拓展思考
为什么zset使用跳表而不用红黑树或者二叉树?
Redis直接操作内存而不是磁盘,所以不需读取IO,速度比较快
- 跳表不是很占用内存(基本取决于节点数据),本身节点的数据参数会让内存密集度小于B+树
- 跳表本身实现方式比其他结构都要简单(将相同级别的节点存储在同一个文件或者映射中,有利于解决缓存局部性问题)
而MYSQL使用B+树是为了减少IO以及支持范围查询
关于这个问题的讲解,结合MYSQL的底层结构讲解比较清晰。
(对应的数据库最终使用了b+树,可看我这篇文章的推理:Mysql底层原理详细剖析+常见面试题(全))