文章目录
一、实训课题
大数据项目之电商数据仓库系统
二、实训目的
完成一个电商数仓项目:
1、完成hadoop、kafka、flume、mysql以及zookeeper等相关环境的搭建。
2、安装与spark兼容的hive数据仓库环境,并使用 MySQL 存储Metastore,实现与其他客户端共享数据。
3、模拟在Kafka生产消息方输入的信息,可在Kafka消费消息方正常接收,启用kafka监控。
4、在hive数据仓库中创建一个gmall数据库,利用sqoop工具将mysql数据库数据先导入hadoop集群的HDFS中,再从HDFS导进到hive数据仓库的gmall数据库中,最后在gmall数据库中依次逐层从ODS层到ADS层导入数据。
三、操作环境
1. Linux系统:Centos 7.5
2. Hive on spark版本:apache-hive-3.1.2
3. Java版本:1.8.0_212
4. Kafka版本:kafka_2.11-2.4.1
5. Flume版本:apache-flume-1.9.0
6. Sqoop版本:sqoop-1.4.6
7. ZooKeeper版本:apache-zookeeper-3.5.7
8. MySQL版本:mysql-5.7.28
9. Spark版本:spark-3.0.0
| 相关技术 | 描述 |
|---|---|
| Hive | 基于Hadoop的数据仓库工具,将结构化的数据文件映射为数据库表,将SQL语句转换为MapReduce任务进行运行,快速实现简单MapReduce统计。 |
| Kafka | 一种高吞吐量的分布式发布订阅消息系统; |
| Flume | 分布式的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据; |
| Sqoop | 用于Hadoop、Hive与MySQL间数据的传递,可将MySQL中的数据导进Hadoop的HDFS中,也可将HDFS的数据导进到hive数据库中。 |
| ZooKeeper | 大型分布式系统的可靠协调系统,提供:配置维护、名字服务、分布式同步、组服务等。 |
| Spark | 很流行的开源大数据内存计算框架。可基于Hadoop上存储的大数据进行计算。 |
四、 实训过程(实训内容及主要模块)
1. 搭建hadoop集群环境:在大数据实践配置的hadoop集群的基础上快速完成再次搭建。
2. 安装与spark兼容的hive数据仓库环境。
3. 使用 MySQL 存储hive的元数据库Metastore,实现与其他客户端共享数据。
4. 完成kafka、flume以及zookeeper等集群环境的搭建。
5. 利用sqoop将mysql数据库数据先导入HDFS中,再导进到hive的gmall数据库中,最后依次从ODS层逐层导入数据直到ADS层为止。
五、实训中用到的课程知识点
-
数仓搭建时数据采用
LZO压缩,减少磁盘存储空间。比如100G数据可以压缩到10G以内。 -
数仓搭建时,数据采用
parquet存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的text方式存储数据,需要采用支持切片的,lzop压缩方式并创建索引。 -
数据装载到时间维度表时,dwd_dim_date_info是
列式存储+LZO压缩。直接将date_info.txt文件导入到目标表,并不会直接转换为列式存储+LZO压缩。需创建一张普通的临时表dwd_dim_date_info_tmp,将date_info.txt加载到该临时表中。最后通过查询临时表数据,把查询到的数据插入到最终的目标表中。 -
使用脚本可以较快启动相关服务进程、导入及导出数据等,其中
nohup表示不挂起的意思,不挂断地运行命令;/dev/null:是 Linux 文件系统中的一个文件,被称为黑洞,所有写入改文件的内容都会被自动丢弃;2>&1 : 表示将错误重定向到标准输出上;&: 放在命令结尾,表示后台运行。 -
使用
“select * from 表名” 不执行MR操作,默认采用的是ods_log建表语句中指定的DeprecatedLzoTextInputFormat,能够识别 lzo.index为索引文件。 -
使用
“select count(*) from 表名” 执行MR操作,默认采用的是CombineHiveInputFormat,不能识别lzo.index为索引文件,将索引文件当做普通文件处理。更严重的是,这会导致LZO文件无法切片,修改CombineHiveInputFormat为HiveInputFormat即可。
六、实训中遇到的问题及解决方法
所遇问题:
1) 再次格式化NameNode导致无法启动datanode进程
解决办法:格式化NameNode,会产生新的集群id,导致 NameNode和DataNode的集群id不一致,集群找不到已往数据。可删除所有机器的data和logs目录,然后再进行格式化,或者进入namenode对应的clusterID所在的文件,复制其clusterID到datanode对应的clusterID即可。
2)xshell连接虚拟机后,输入指令时从数字小键盘输入的数字无效
解决办法:打开xshell,点击“默认属性”,打开对话框,在类别中选择 “VT模式”,然后在右侧的选项中,选择:初始数字键盘模式中的“设置为普通”,最后点击“确定”即可。
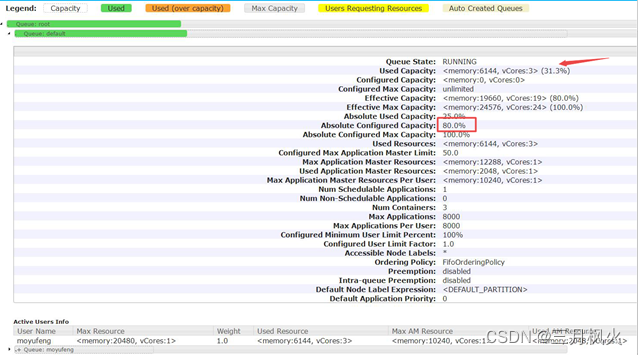
3)配置了多队列导致加载数据时,所用队列没有足够的空间
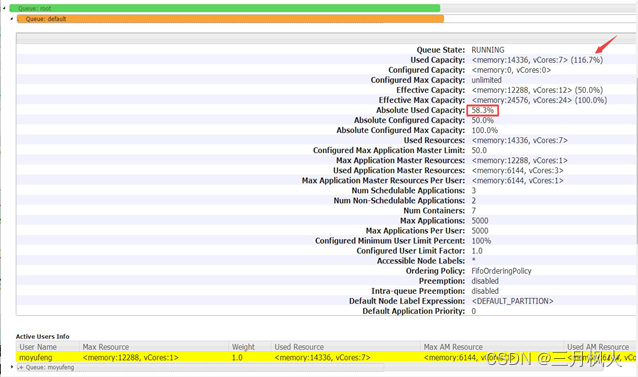
解决办法:修改hadoop安装目录下的配置文件:capacity-scheduler.xml,增加该队列的容量
4) 执行MapReduce任务时,虚拟内存超额,导致进程被杀掉
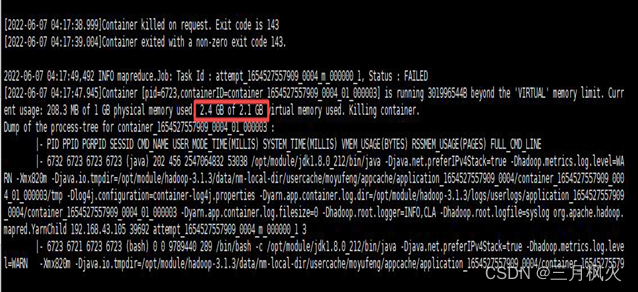
解决办法:适当增大 yarn.nodemanager.vmem-pmem-ratio 的大小,为物理内存增大对应的虚拟内存。
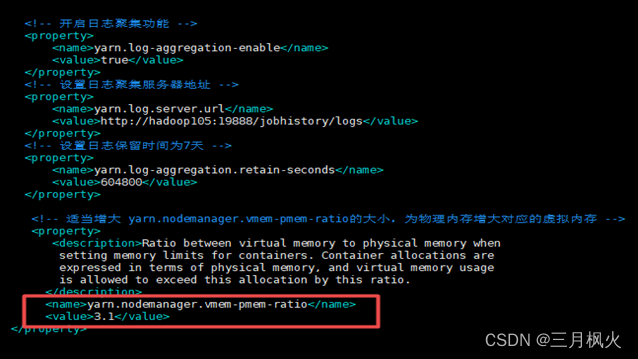
5) Hive版本和Spark版本不兼容,无法上传jar包、导入数据到hadoop HDFS。
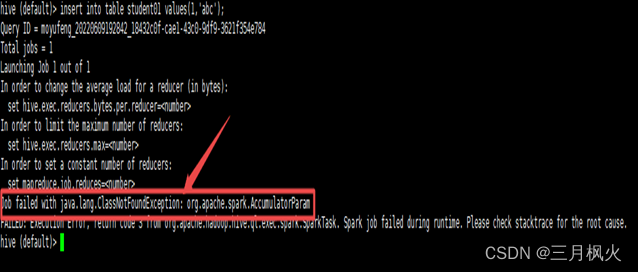
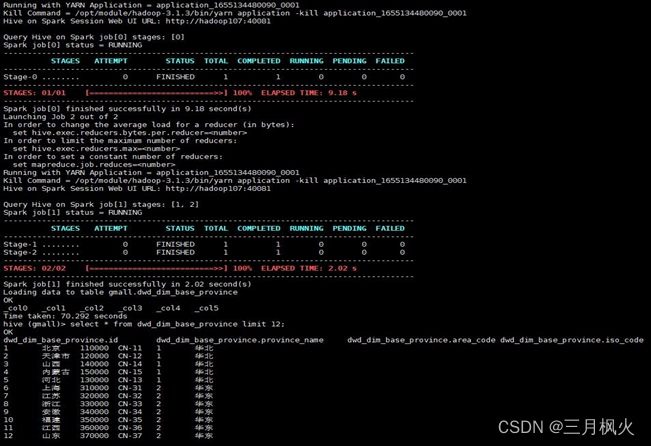
解决办法:使用经编译过与Spark版本兼容的hive环境,即hive on spark版本,重新执行任务进行测试,成功状态如下图:
七、课程实训体会与心得
-
通过为期两周的大数据project 5,我学会了
利用三台虚拟机作服务器搭建Hadoop、kafka、flume、mysql以及zookeeper等环境,利用sqoop工具将mysql数据导入hadoop 集群的HDFS上,再导进到hive的gmall数据库中。创建并使用脚本将数据依次从ODS层逐层导入数据直到ADS层为止。 -
正确搭建环境需有以下进程:
Hadoop105虚拟机上:
RunJar、RunJar、QuorumPeerMain、Kafka、NameNode、DataNode、NodeManager、Application、JobHistoryServer;
Hadoop106虚拟机上:
Application、QuorumPeerMain、Kafka、DataNode、ResourceManager、NodeManager;
Hadoop107虚拟机上:
QuorumPeerMain、Kafka、Application、SecondaryNameNode、DataNode 、NodeManager。
其中,除了原hadoop集群所必备的进程外,启动 metastore与启动 hiveserver2各对应一个RunJar进程;启动 hadoop105及hadoop106 采集flume各对应一个Application进程,
启动 hadoop107 消费flume也对应一个Application进程;启动Kafka、zookeeper在三台虚拟机上各对应一个Kafka、QuorumPeerMain进程。
-
安装与spark兼容的hive环境后,
Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。可使用MySQL存储hive的元数据库Metastore,可实现与其他客户端共享数据。 -
数仓搭建时数据
采用LZO压缩,减少磁盘存储空间。比如100G数据可以压缩到 10G以内。搭建数仓时,数据采用parquet存储方式,是可以支持切片的,不需要再对数据创建索引。如果单纯的text方式存储数据,需要采用支持切片的,lzop压缩方式并创建索引。 -
对于采用
列式存储+LZO压缩的数据库表。直接将txt文件导入到目标表,并不会直接转换为列式存储+LZO压缩。需创建一张普通的tmp临时表,将txt文件加载到该临时表中。最后通过查询临时表数据,把查询到的数据插入到最终的目标表中。
6.一些同学采用了对项目操作过程采用视频录制放入PPT进行演示,也可减少一些对应PPT页数,同时让PPT内容更生动和具备动态效果,也是一种不错的选择。
八、自定义的相关脚本
自定义脚本存放在自定义用户 moyufeng 的 bin 目录下,其中 绿色的文件 是经过source生效的脚本, 一般以.sh为后缀标识,对于常用的脚本,可以考虑通过mv改名将.sh后缀去掉(更方便一点),不太常用的脚本还是建议加.sh为后缀进行标识。
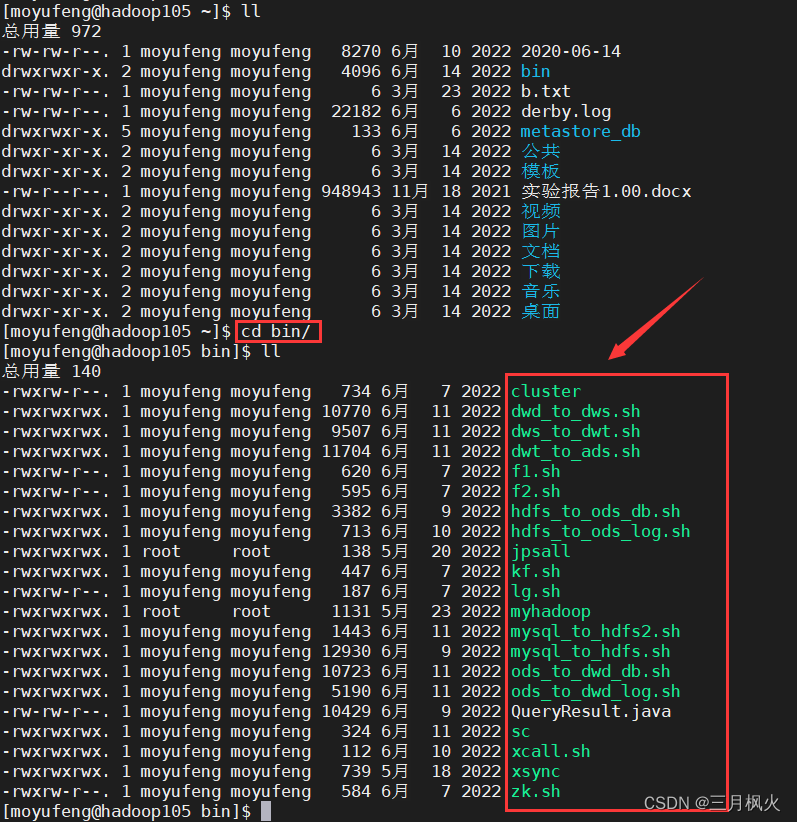
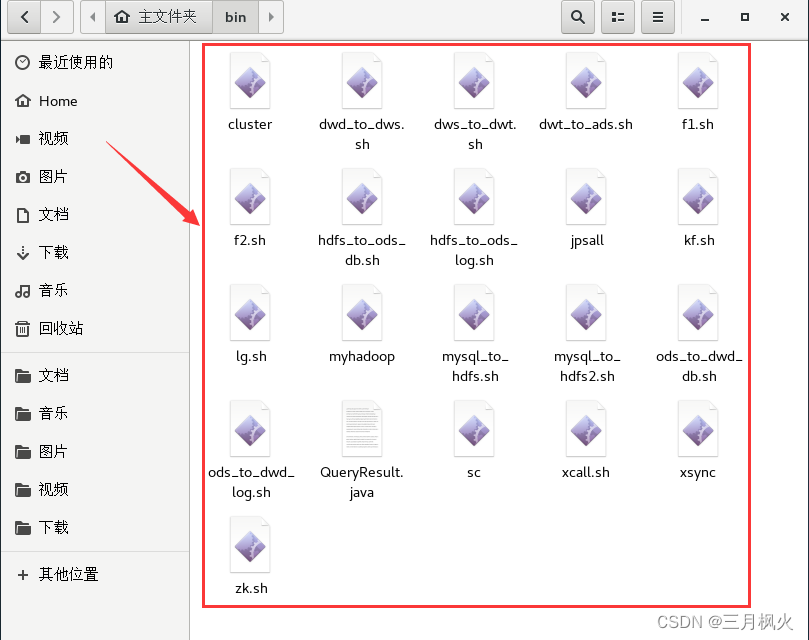
由于自定义脚本较多,部分脚本篇幅较长,具体的脚本内容放入另一篇文章:
大数据电商数仓相关脚本
https://blog.csdn.net/m0_48170265/article/details/130376063
九、项目启动
1. 配置hosts文件和虚拟机 ip地址
下面以 VMnet8 NAT模式连接网络为例(若NAT模式虚拟机无法联网,则需要改为桥接模式)
查看本地网络 ip:
win+r 输入cmd后,再输入:
ipconfig
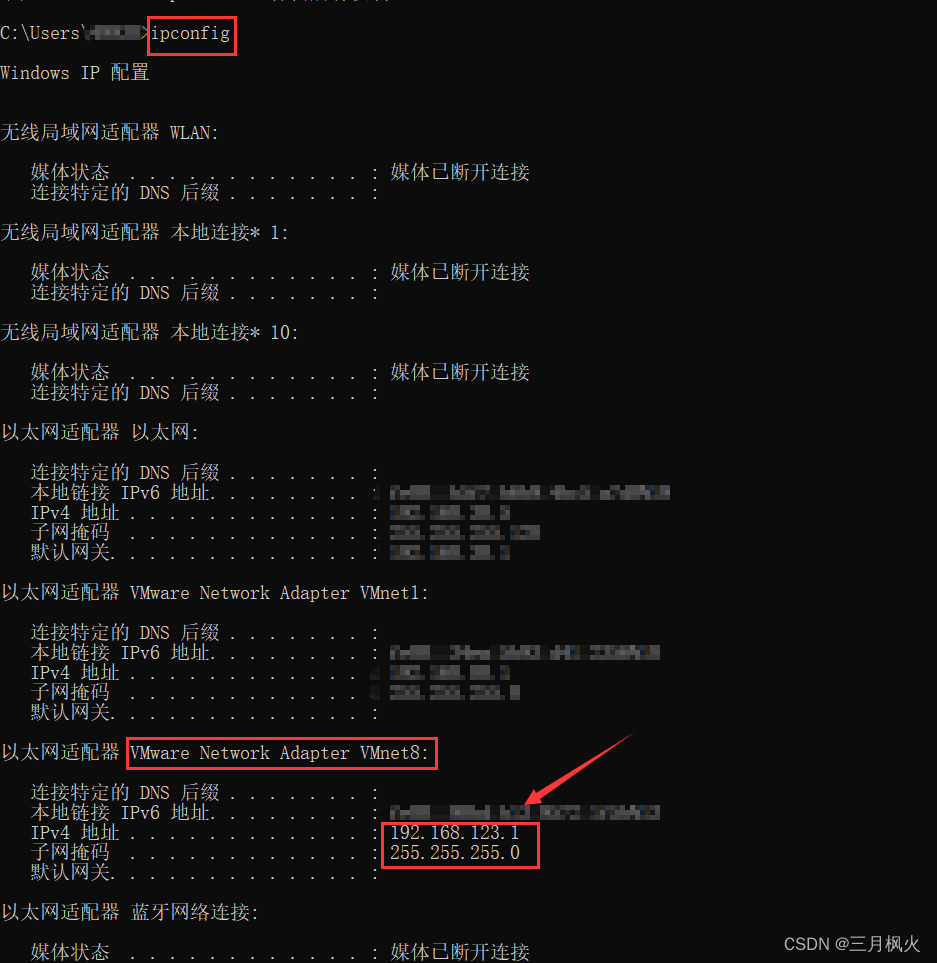
找到VMnet8 的网络IPv4地址的网段(前三位)和子网掩码(一般是255.255.255.0)
这里的网段是: 192.168.123.*
子网掩码: 255.255.255.0
配置虚拟网络:保持虚拟网络子网ip的前三位网段和上面的网段相同,子网掩码和上面也相同
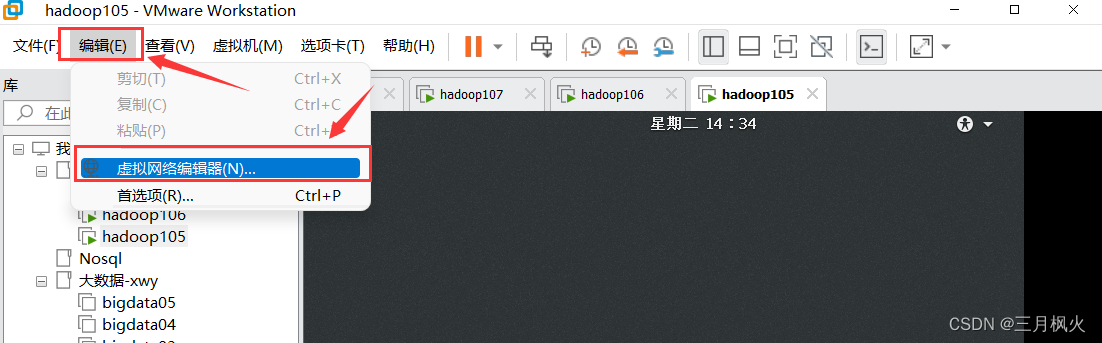
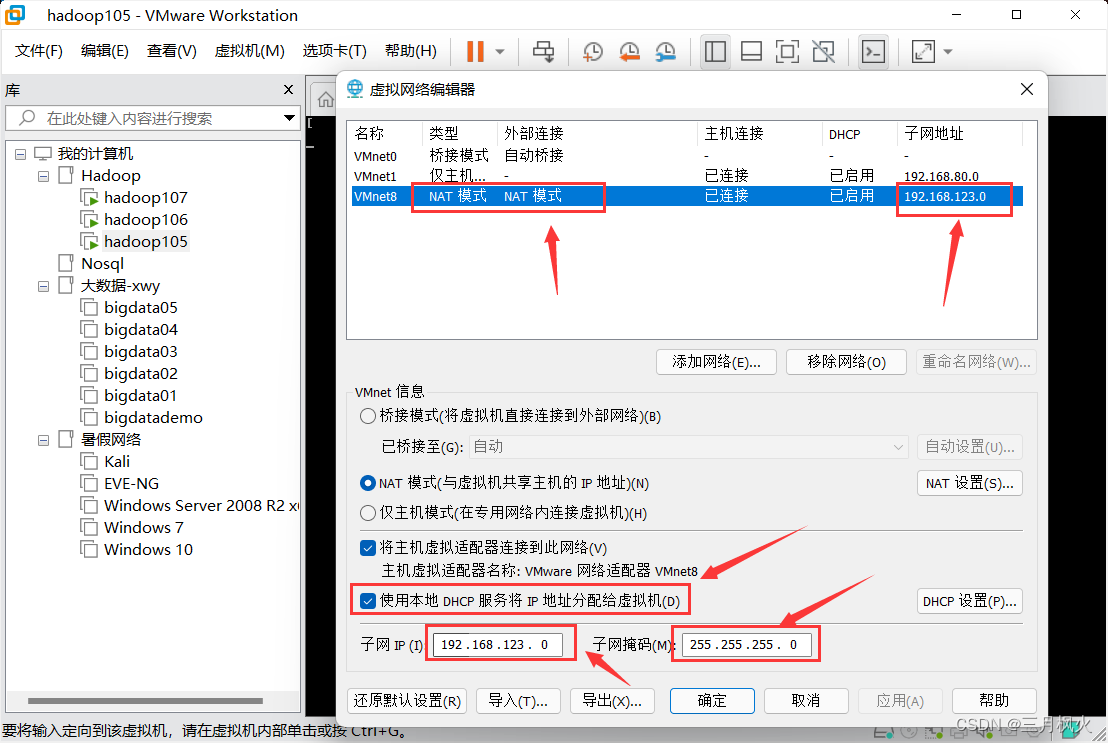
配置NAT网络参考 https://blog.csdn.net/m0_48170265/article/details/129982752 中的 3. 设置虚拟网络
配置Windows本地hosts文件:
C:\Windows\System32\drivers\etc\hosts
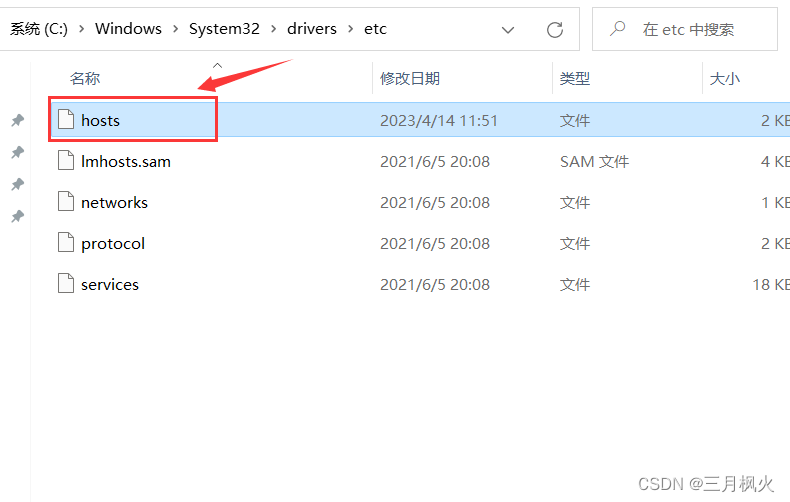
确保子网ip地址的前三位网段和电脑所连网络的网段相同,第四位可任取,一个子网ip地址对应一个自定义主机名,方便本地浏览器解析出自定义主机名对应的ip地址
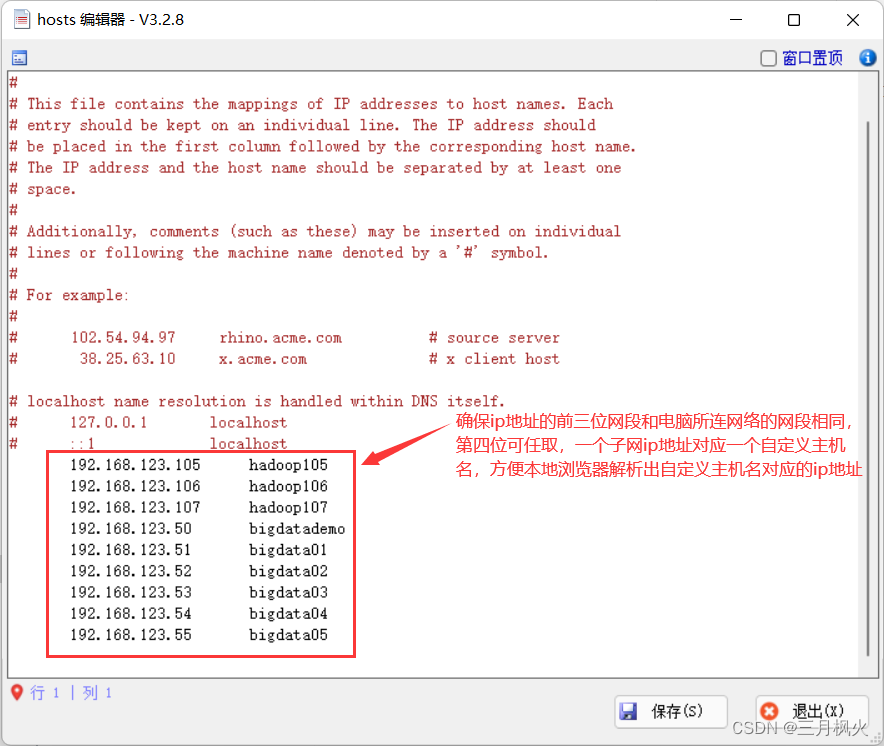
同理,依次分别在三台虚拟机hadoop105,hadoop106,hadoop107上配置hosts文件。若编写了xsync分发脚本,在一台虚拟机上配置好后,用脚本分发到其他两台相关虚拟机也行。
vim /etc/hosts
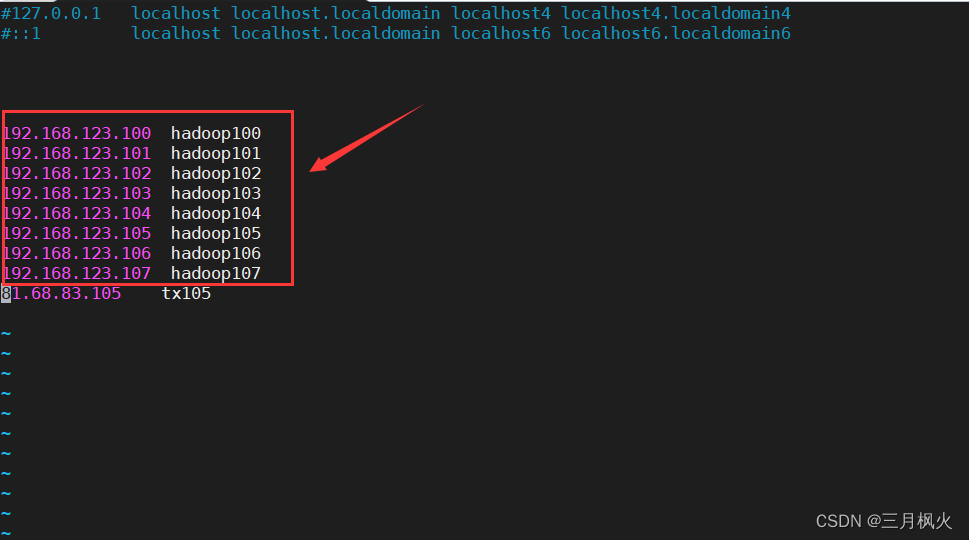
依次配置三台虚拟机主机名hadoop105,hadoop106,hadoop107(方便其他虚拟机根据hosts文件进行解析识别):
vim /etc/hostname
需reboot 重启生效
-- 查看虚拟机名称
hostname
-- 修改虚拟机名称
vi /etc/hostname
按 i 修改名称为 xxx
-- 重启生效
reboot
根据hosts文件,依次配置三台虚拟机ip地址,缺一不可
# 修改ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
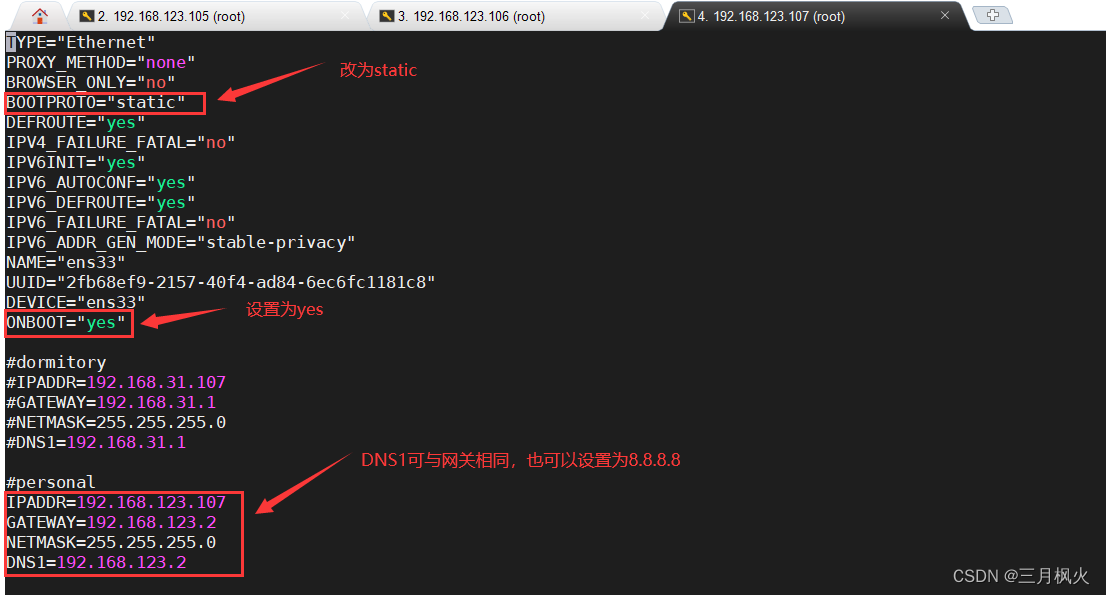
查看ip地址:
ip addr 或 ifconfig
若更改了ip地址,需要输入命令进行重启
systemctl restart network
2. 用自定义脚本群起集群和相关服务
2.1 启动 sc 脚本
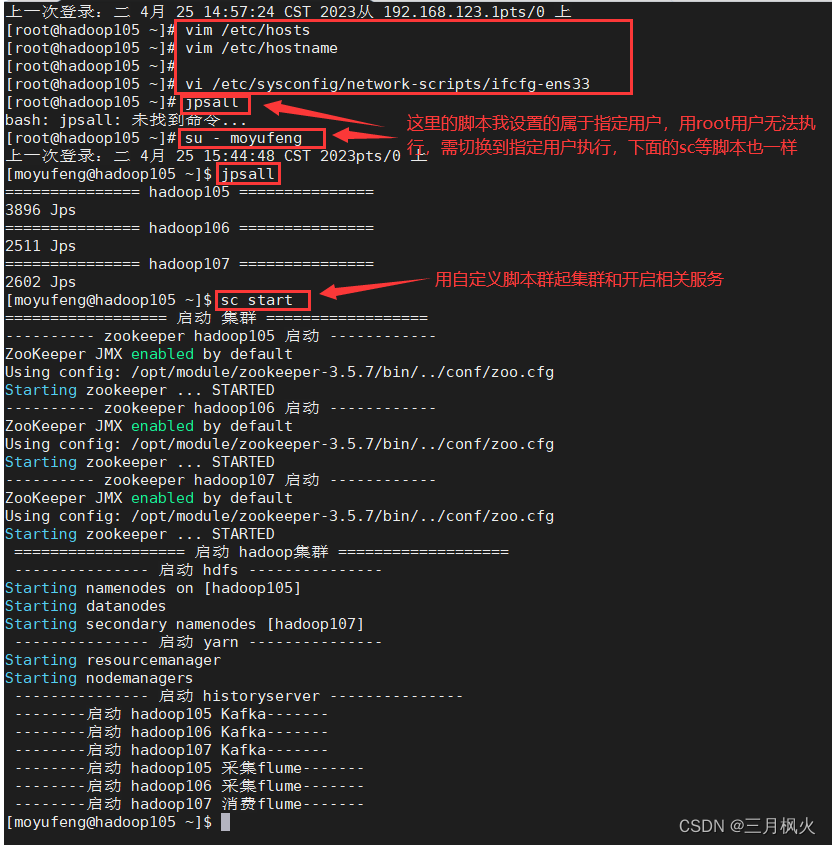
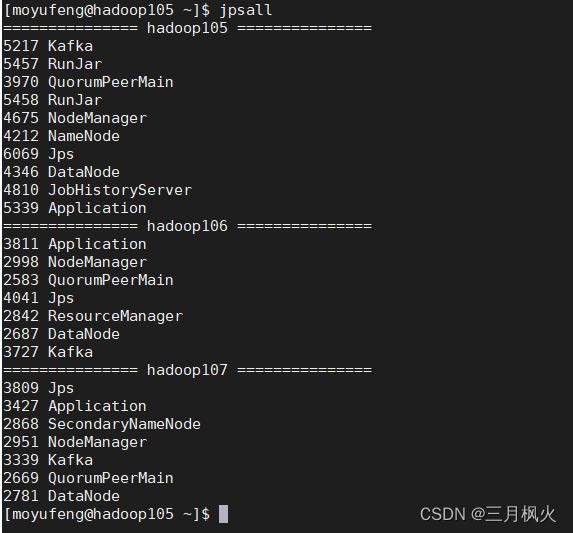
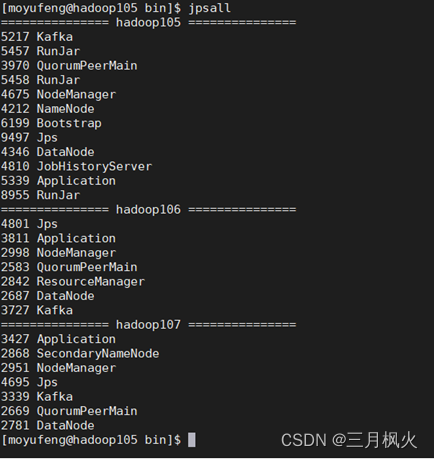
此时所有的进程如下:
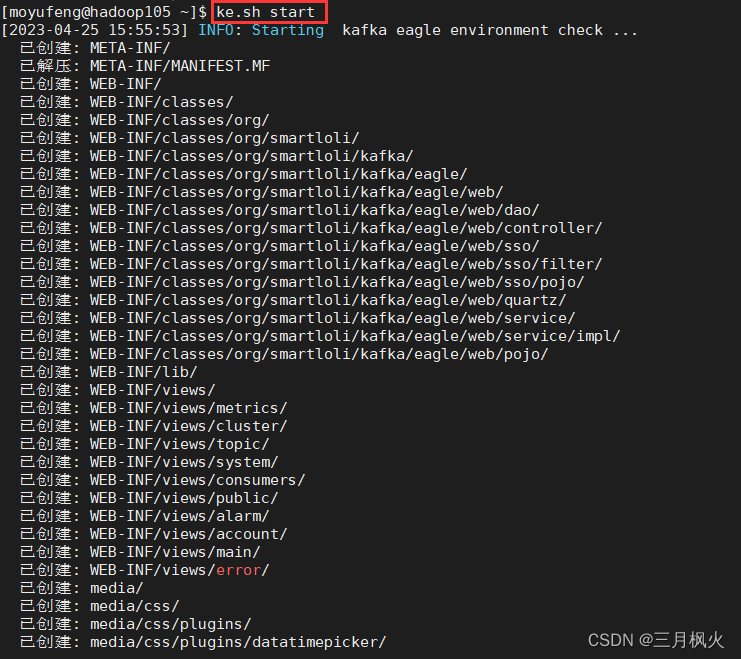
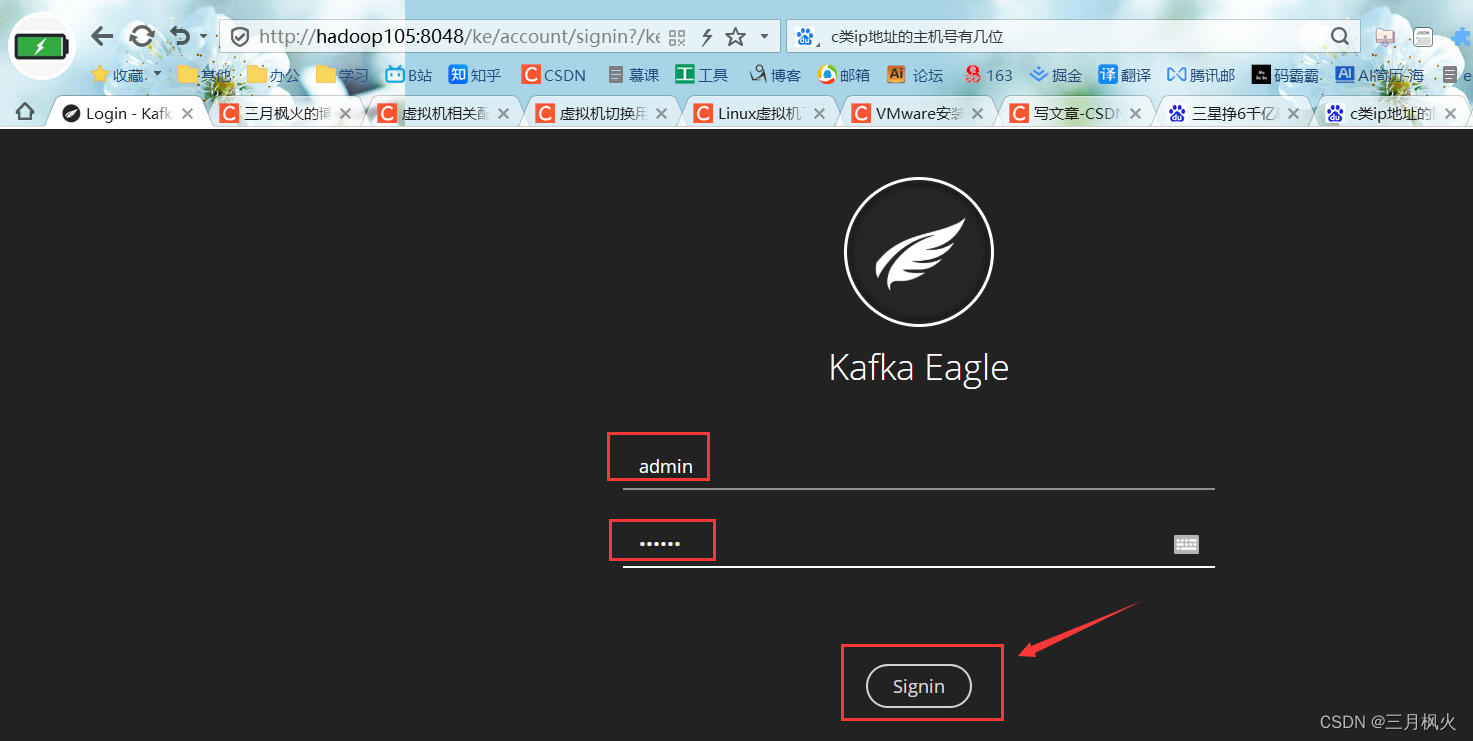
2.2 用ke.sh 脚本启动kafka监控
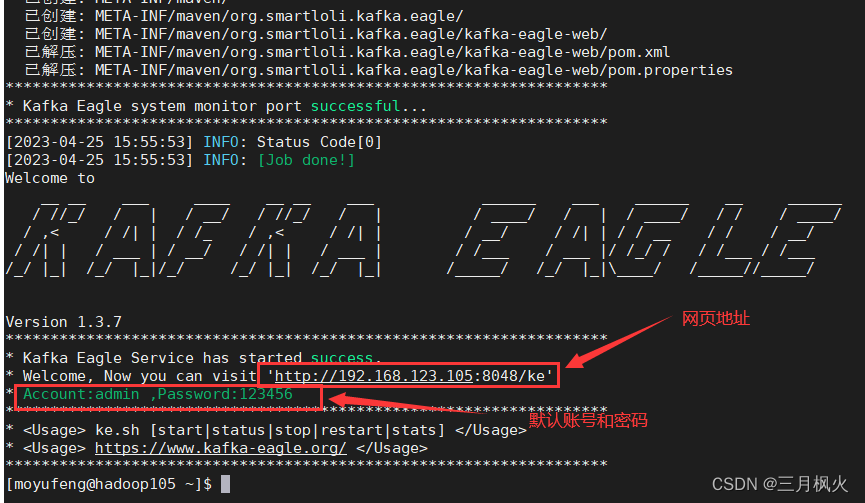
默认账号 admin ;密码 123456
此时所有的进程如下:
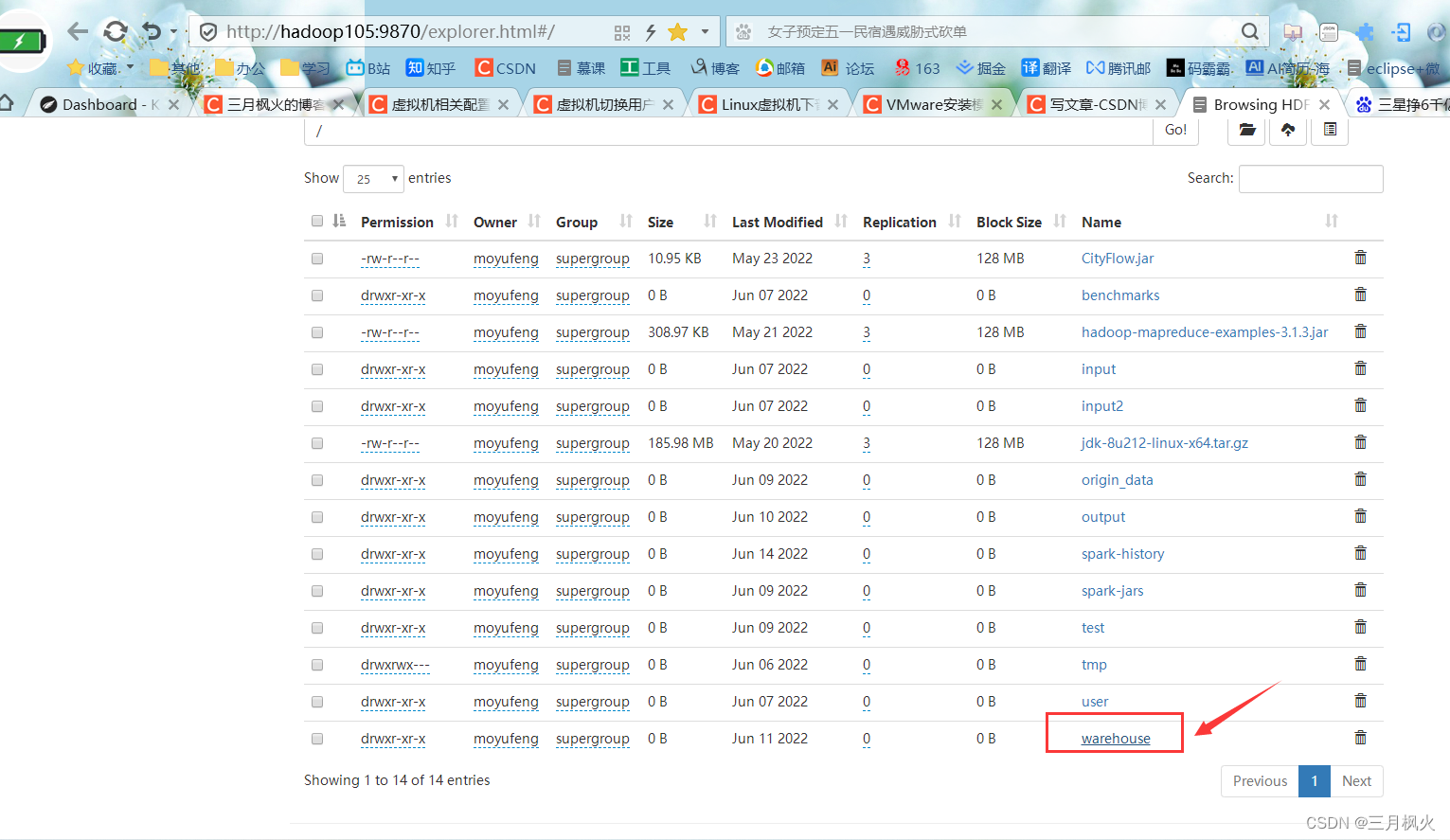
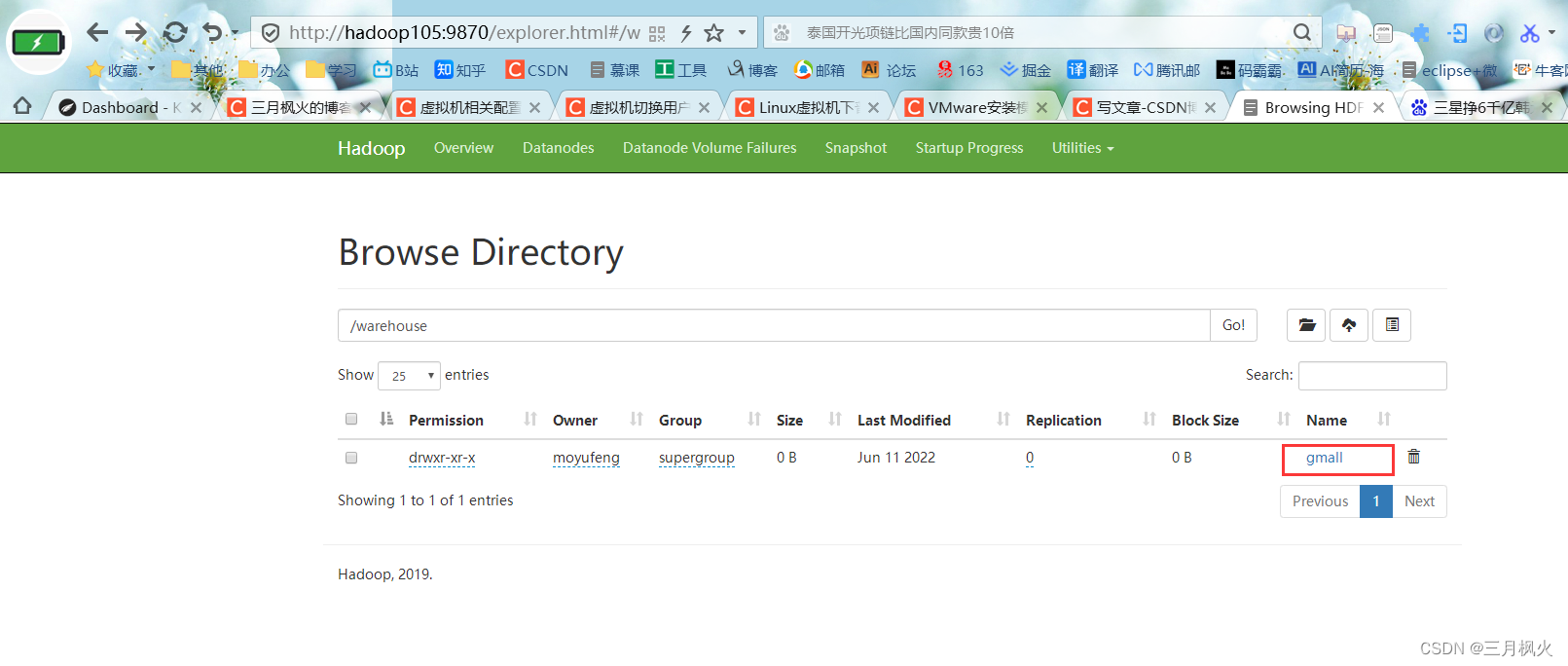
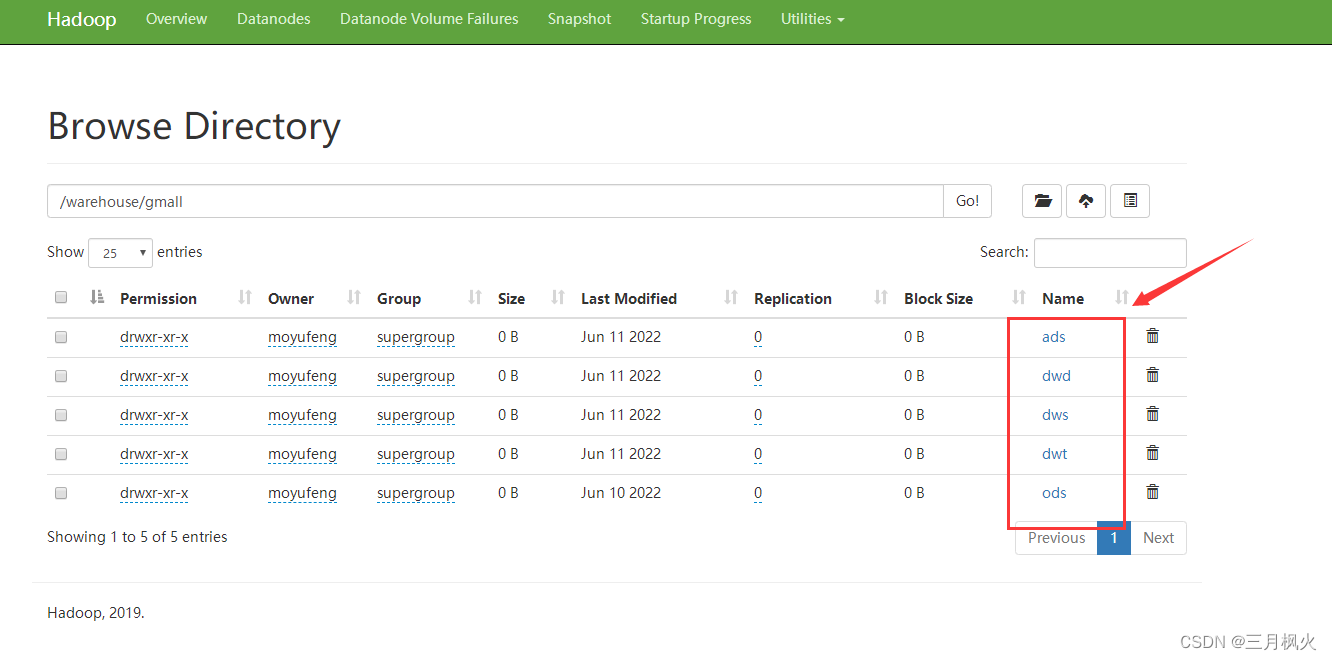
3. gmall数据仓库在hdfs上的存储位置
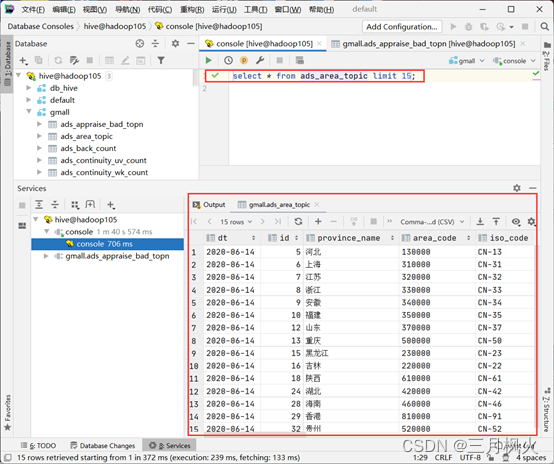
4. 用DataGrip 连接hive数据库
使用DataGrip连接hive数据库,方便进行数据查询
hive启动的前置条件
1.保证hdfs和yarn已启动
2.保证hive的元数据库mysql已启动
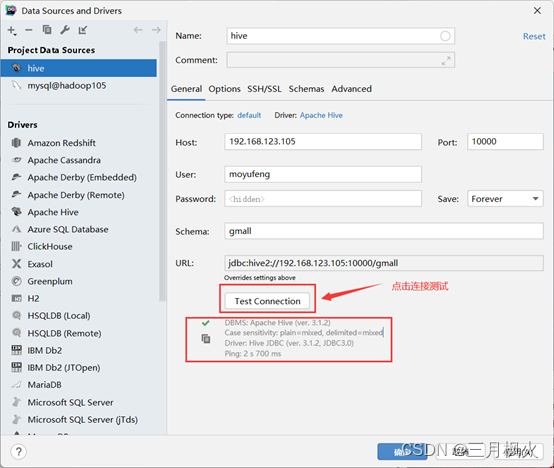
点击测试,发现连接成功
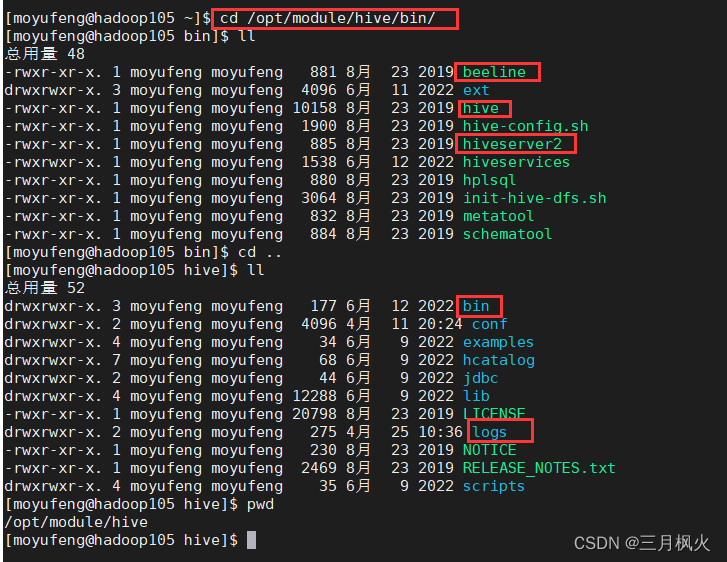
若连接失败,可能需要重新开启下hiveserver2服务(hiveserver2启动完成会偏慢,要等待两三分钟),需等hiveserver2服务启动完成才能连接hive数据库,在hadoop105上输入如下启动指令:
cd /opt/module/hive/bin/
nohup hive --service hiveserver2 1>/opt/module/hive/logs/hive.log 2>/opt/module/hive/logs/hive_err.log &
– nohup:放在命令的开头,表示的意思为不挂起即关闭终端进程也保持允许状态
–1:代表标准日志输出
–2:表示错误日志输出
– /opt/module/hive/logs : 其中/opt/module/hive/为你自己hive解压目录,若该目录下无logs目录,
需自行mkdir一个logs目录,用于存放hive.log和hive_err.log日志文件,这两个日志文件不需要自己创建,相关服务运行时自动创建
– &:代表在后台运行
所以整个命令可以理解为:将hiveserver2服务后台运行在标准日志输出到hive.1og,错误日志输出到hive_err.log,唧使关闭终端(窗口),也会保持运行状态
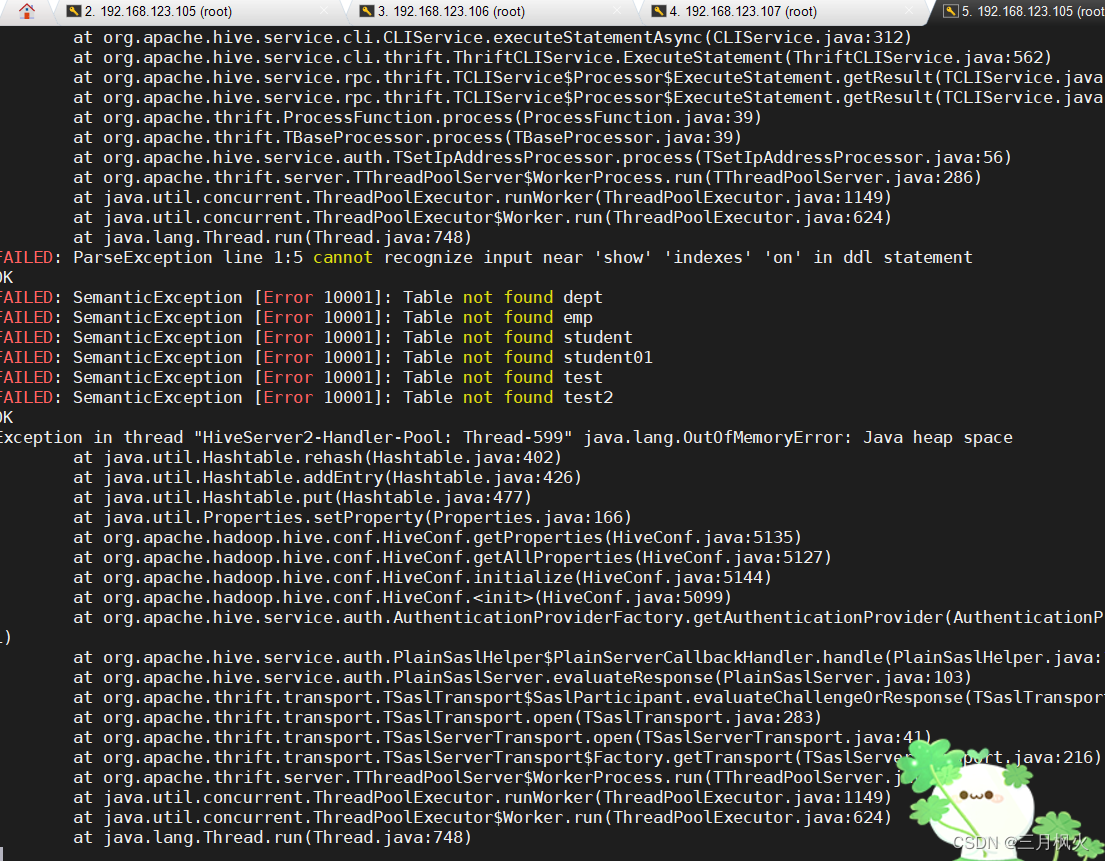
cd /opt/module/hive/logs 进入日志目录后,
可用 tail -300f hive_err.log 查看最后/近300行错误日志信息,其中的数字300可自行按需求更改为500或者1000

同理,tail -300f hive_err.log 可查看最后/近300行标准日志输出
5. 在虚拟机本地查看hive数据库
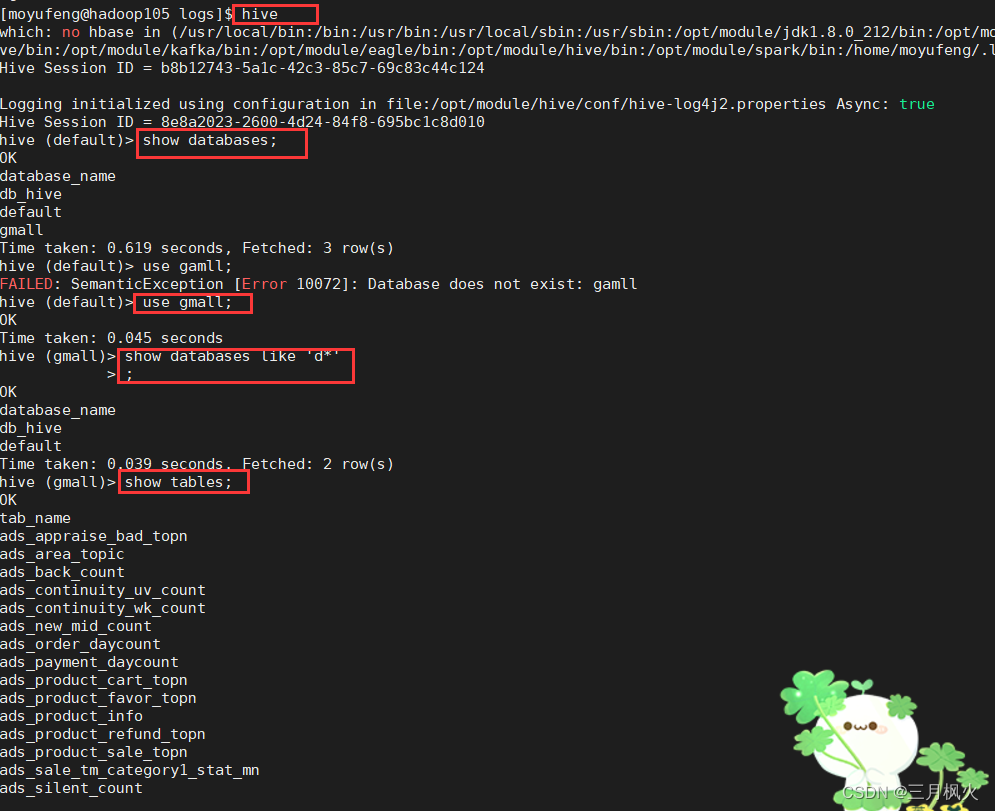
查看gmall数据库:
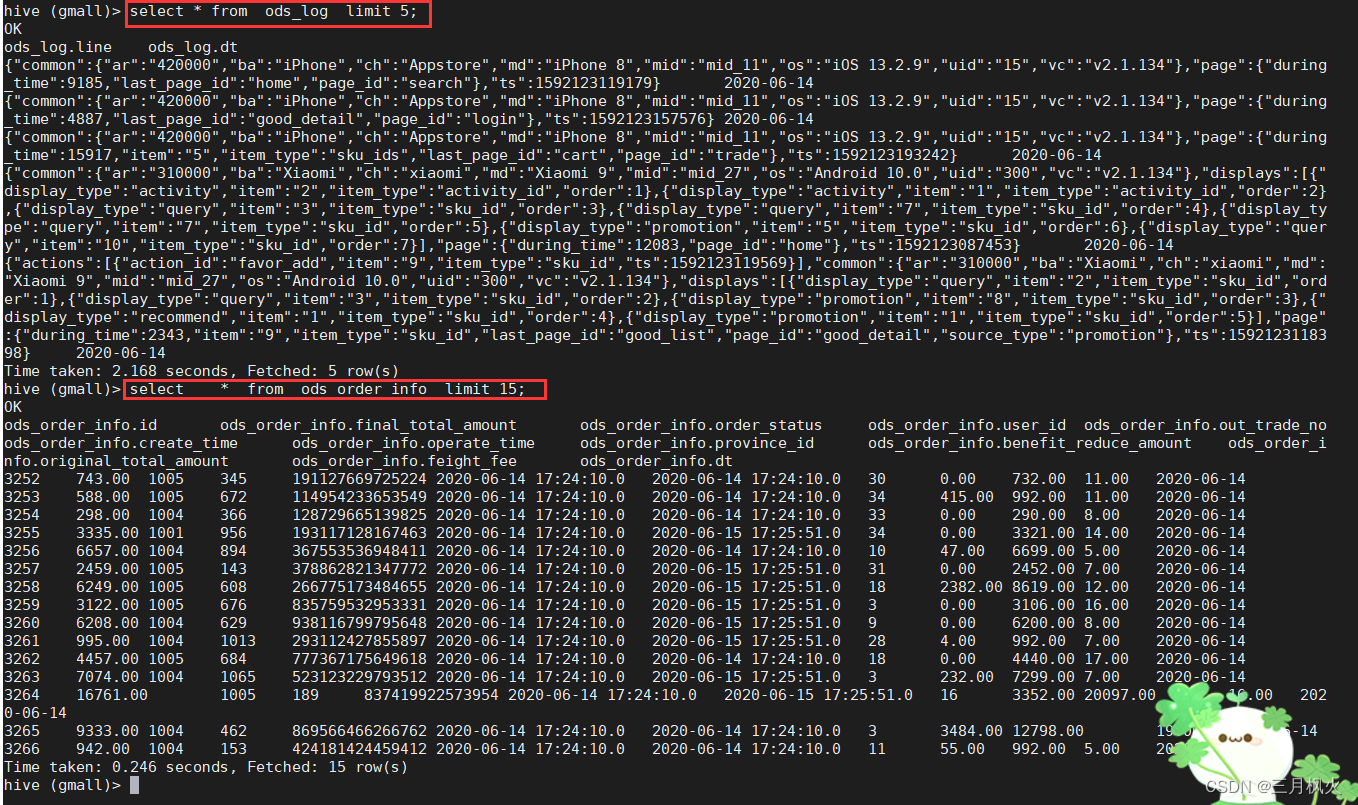
十、程序清单
结果演示:
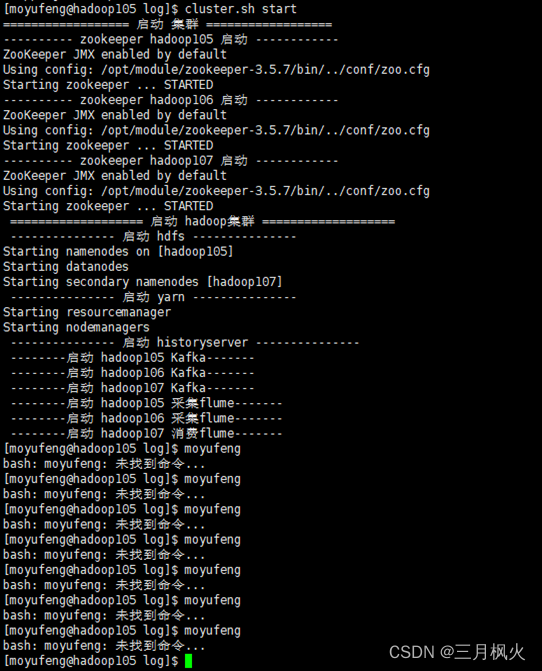
1、 cluster.sh启动截图(全屏幕,带多条自己名字)
cluster.sh start
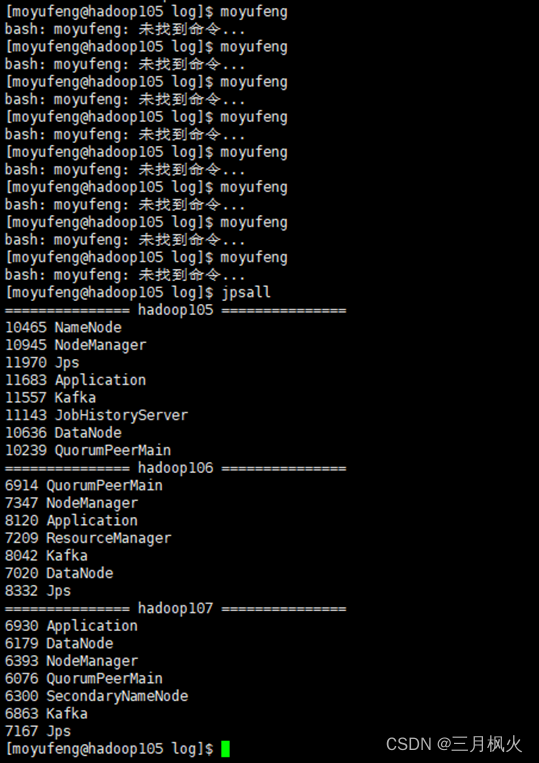
2、 cluster.sh启动后,jpsall截图(全屏幕,带多条自己名字)
jpsall
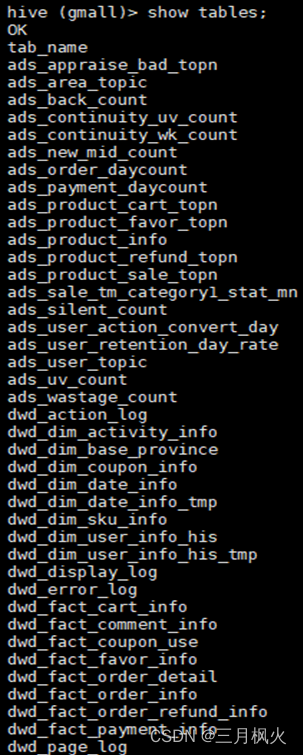
3、gmall数据仓库建表结果
show tables;
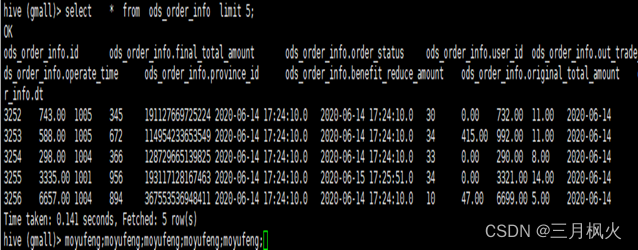
4、ods层订单表数据查询(带着名字缩写5遍)
select * from ods_order_info limit 5;
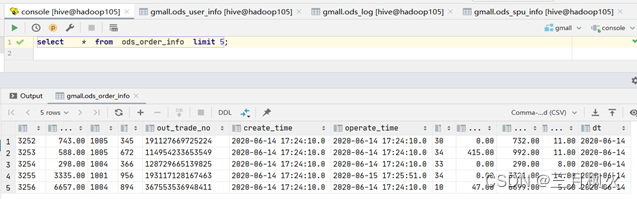
DataGrip连接hive数据仓库查询:
- DWD层数仓数据查询(带着名字缩写5遍)
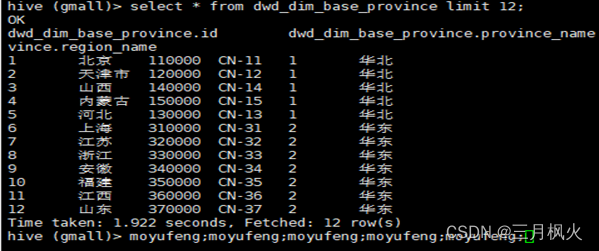
7.1 查看地区维度表
select * from dwd_dim_base_province limit 12;
7.2查看时间维度表
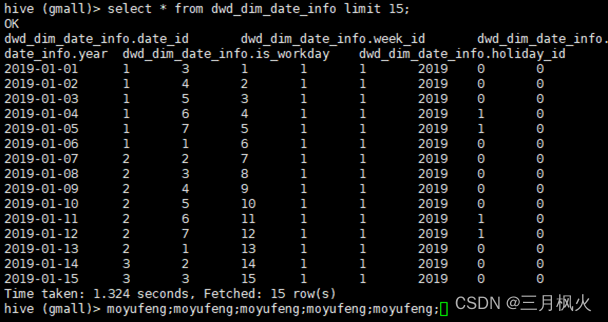
select * from dwd_dim_date_info limit 15;
- DWS层数仓数据查询(带着名字缩写5遍)
8.1 查看每日商品行为
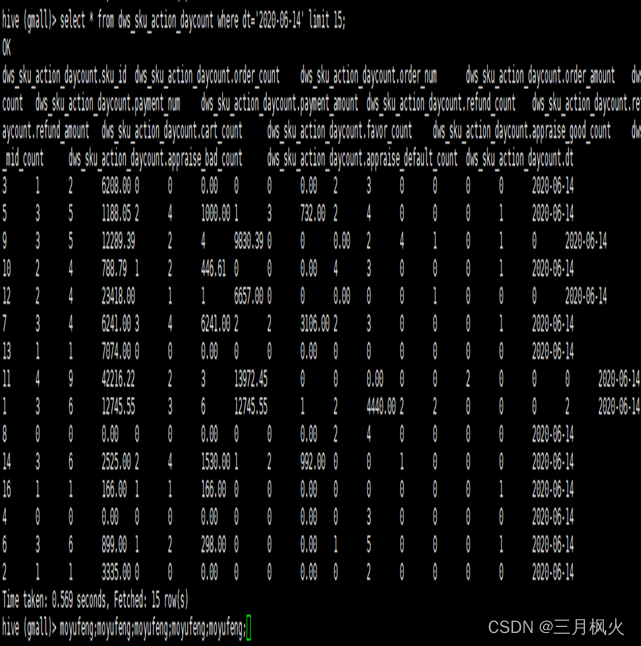
select * from dws_sku_action_daycount where dt=‘2020-06-14’ limit 15;
8.2 查看每日地区统计
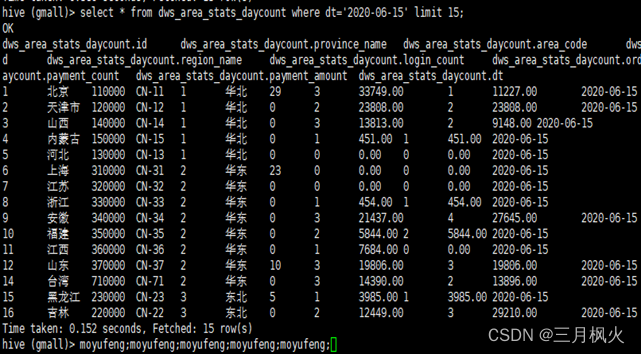
select * from dws_area_stats_daycount where dt=‘2020-06-15’ limit 15;
- DWT层数仓数据查询(带着名字缩写5遍)
9.1 查看商品主题宽表
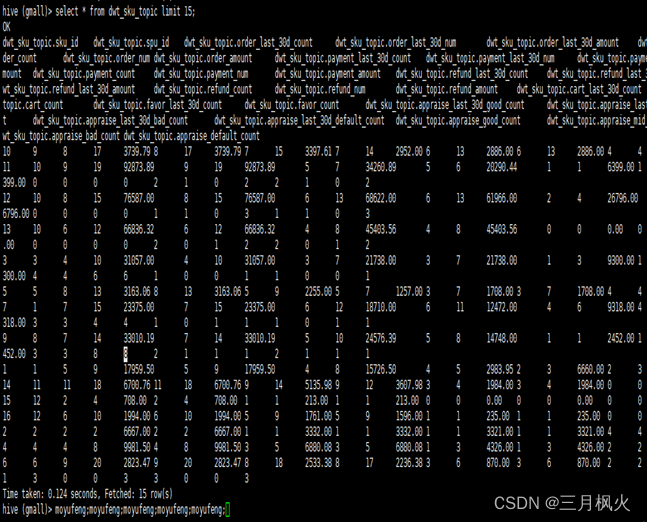
select * from dwt_sku_topic limit 15;
9.2查看地区主题宽表
select * from dwt_area_topic limit 15;
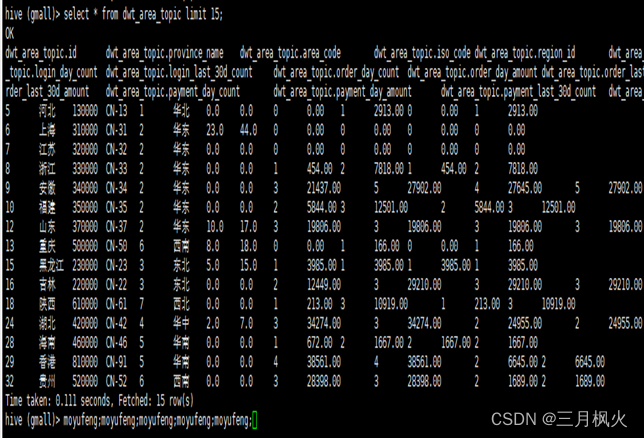
- ADS层数仓数据查询(带着名字缩写5遍)
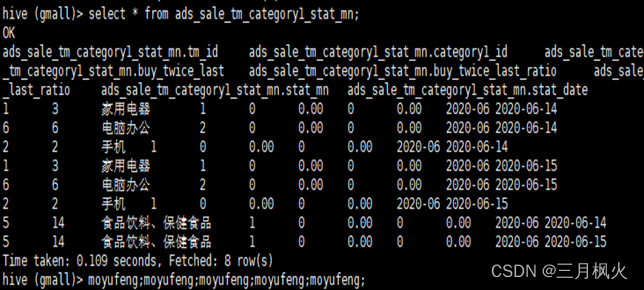
10.1 查看品牌复购率
select * from ads_sale_tm_category1_stat_mn;
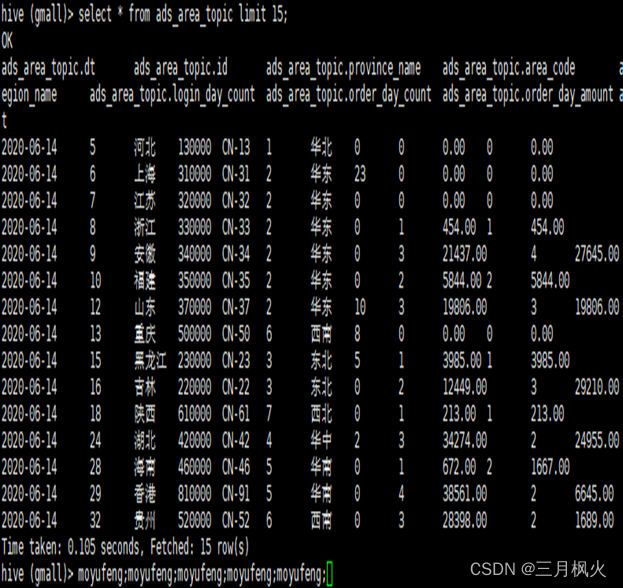
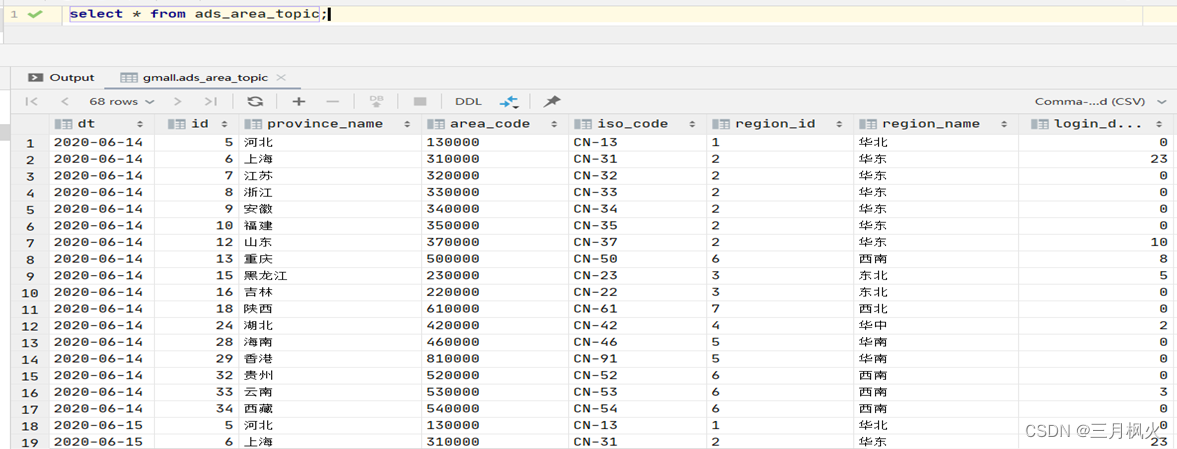
10.2 查看地区主题信息
select * from ads_area_topic;
- kafka数据采集
Kafka生产消息
kafka-console-producer.sh --broker-list hadoop105:9092 --topic topic01

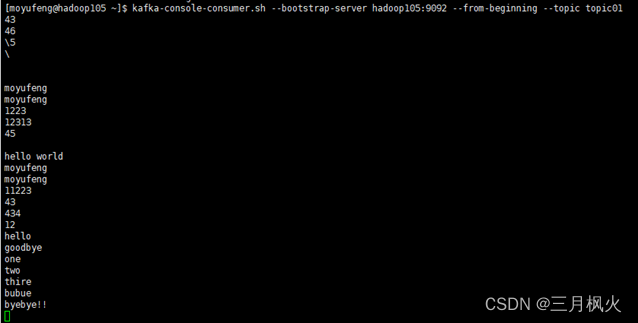
Kafka消费消息
kafka-console-consumer.sh --bootstrap-server hadoop105:9092 --from-beginning --topic topic01
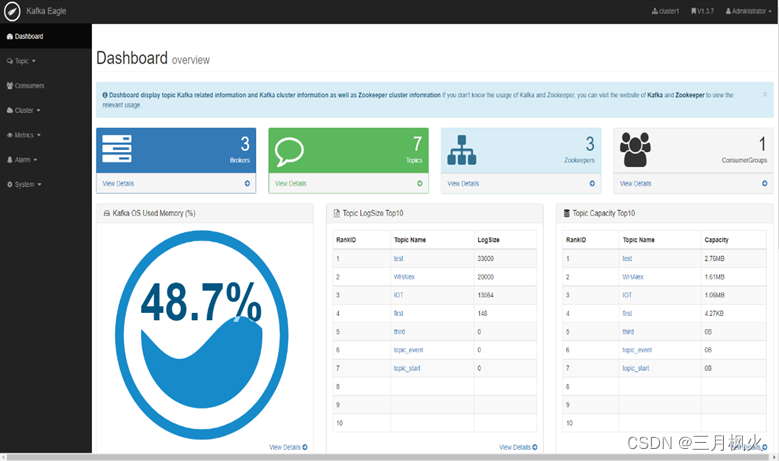
Kafka监控
先使用ke.sh启动相关服务,登录http://hadoop105:8048/ke查看相关信息。
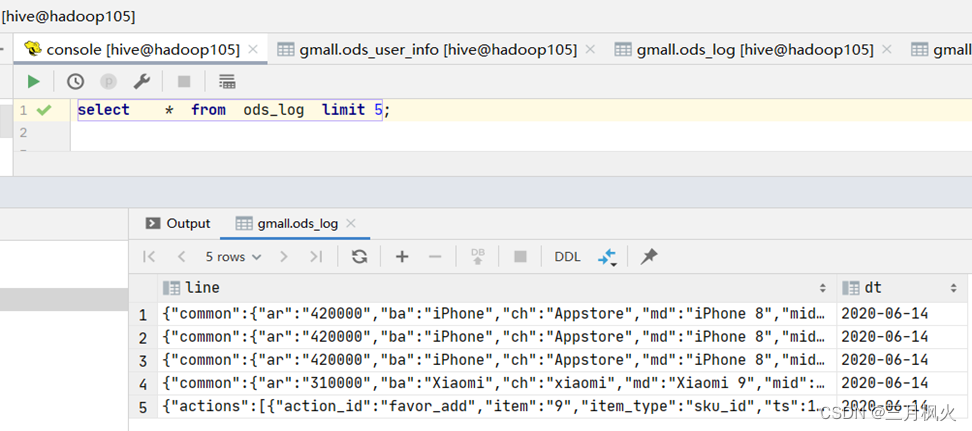
12. 查看ods_log日志
应用:使用DataGrip工具连接本地hive数据库,并检测数据库表里数据的一致性