文章目录
4. 用户行为数据采集模块
4.3 日志采集Flume
4.3.4 日志采集Flume测试
4.3.4.1 启动Zookeeper、Kafka集群
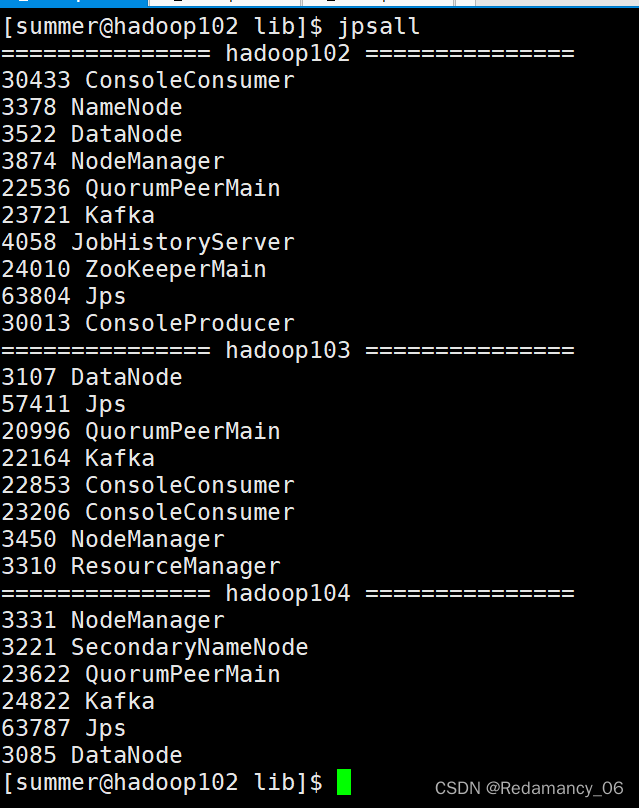
4.3.4.2 启动hadoop102的日志采集Flume
[summer@hadoop102 flume-1.9.0]$ bin/flume-ng agent -n a1 -c conf/ -f job/file_to_kafka.conf -Dflume.root.logger=info,console
启动一个agent ,-n(name)名字为a1,-c就是找到后面的目录,找到conf目录,-f指定我们job目录下面的file_to_kafka.conf,-Dflume.root.logger=info,console是logger的打印,只在控制台上打印,info级别的,输出到console控制台
4.3.4.3 启动一个Kafka的Console-Consumer
[summer@hadoop102 kafka-3.0.0]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
消费topic_log这个主题
4.3.4.4 生成模拟数据
[summer@hadoop102 ~]$ lg.sh
========== hadoop102 ==========
========== hadoop103 ==========
[summer@hadoop102 ~]$ cd /opt/module/applog/log/
[summer@hadoop102 log]$ ll
总用量 3352
-rw-rw-r--. 1 summer summer 808665 10月 23 09:27 app.2022-10-23.log
-rw-rw-r--. 1 summer summer 2388678 10月 25 17:45 app.2022-10-25.log
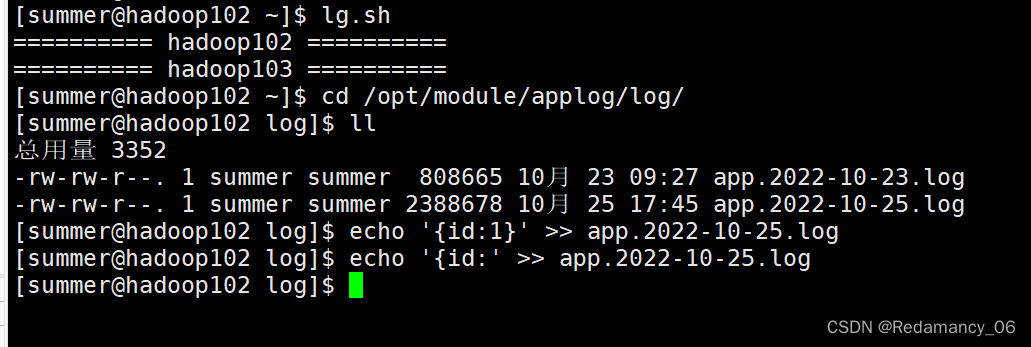
[summer@hadoop102 log]$ echo '{id:1}' >> app.2022-10-25.log
[summer@hadoop102 log]$ echo '{id:' >> app.2022-10-25.log
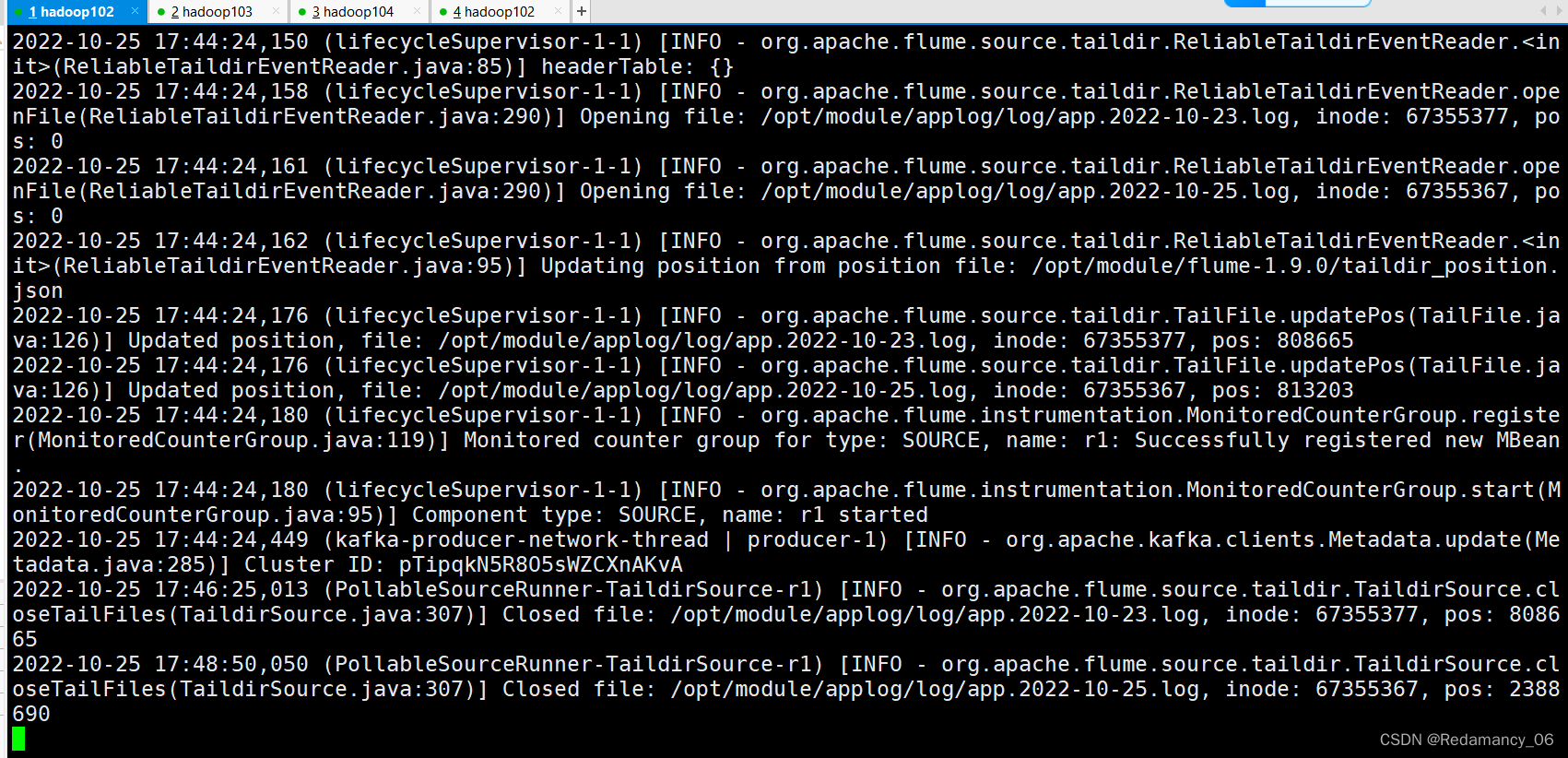
4.3.4.5 观察Kafka消费者是否能消费到数据
通过
[summer@hadoop102 log]$ echo '{id:1}' >> app.2022-10-25.log
[summer@hadoop102 log]$ echo '{id:' >> app.2022-10-25.log
这两行代码,可以检查出我们写的拦截器是成功的
4.3.5 日志采集Flume启停脚本
4.3.5.1 分发日志采集Flume配置文件和拦截器
若上述测试通过,需将hadoop102节点的Flume的配置文件和拦截器jar包,向另一台日志服务器发送一份。直接使用分发脚本。
4.3.5.2 方便起见,此处编写一个日志采集Flume进程的启停脚本
nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
当使用ps -ef | grep Application
[summer@hadoop102 log]$ ps -ef | grep Application
 会多出来一个grep进程,因此可以使用grep -v grep来过滤掉grep进程
会多出来一个grep进程,因此可以使用grep -v grep来过滤掉grep进程
[summer@hadoop102 log]$ ps -ef | grep Application | grep -v grep

这样就可以查出来想要的进程了,然后把进程号给提取出来,这里使用awk,
(awk ‘{[pattern] action}’ {filenames} # 行匹配语句 awk ‘’ 只能用单引号)进行切割
[summer@hadoop102 log]$ ps -ef | grep Application | grep -v grep |awk '{print $2}'
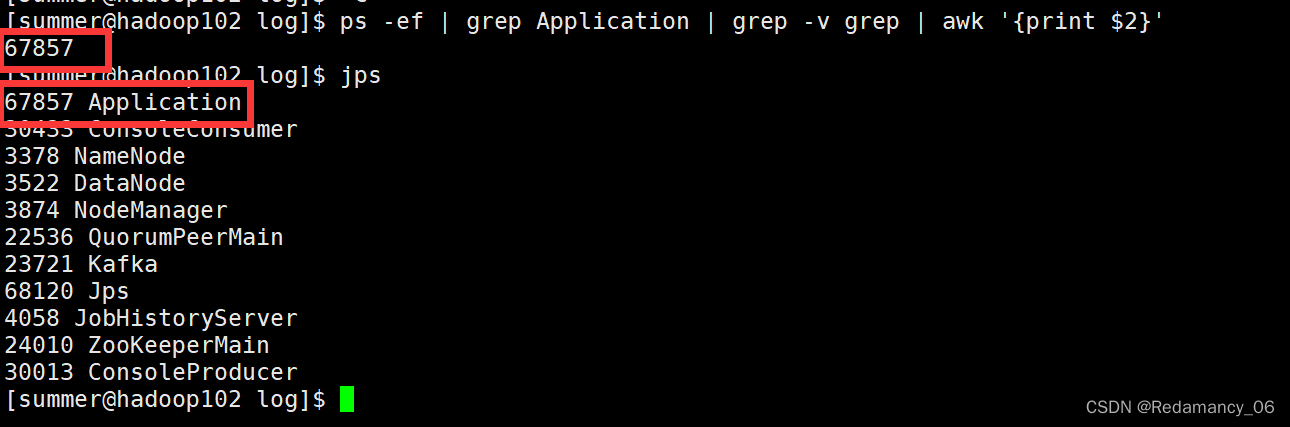 提取到我们想要的进程了,然后进行kill进程
提取到我们想要的进程了,然后进行kill进程
[summer@hadoop102 log]$ kill -9 ps -ef | grep Application | grep -v grep |awk '{print $2}'

正常顺序的kill命令不能用,他会将-9后面的整体当做字符串,因此我们可以使用xargs -n 反向输出
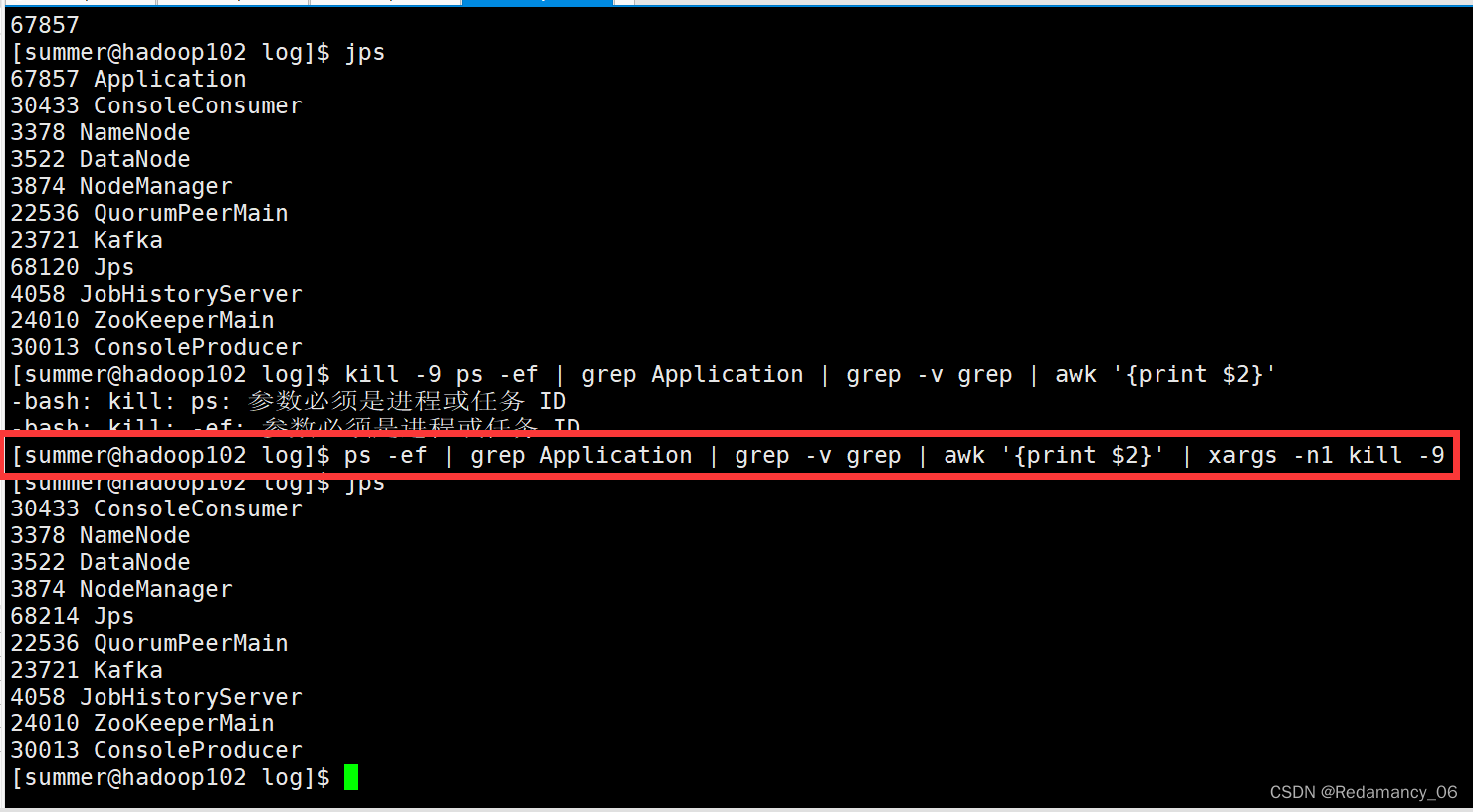
将进程号为67857的kill了,但是我们还有一个问题,这样写如果有多个Application的进程,多个Flume的job,也都会同时一起杀死,我们不想这样做,因此可以进行改进,可以根据文件名,一台机器上一个Flume的配置只会启动一次,不会启动多次。

[summer@hadoop102 log]$ ps -ef | grep file_to_kafka | grep -v grep | awk '{print $2}'
 因此可以使用这个命令进行查询进程号
因此可以使用这个命令进行查询进程号
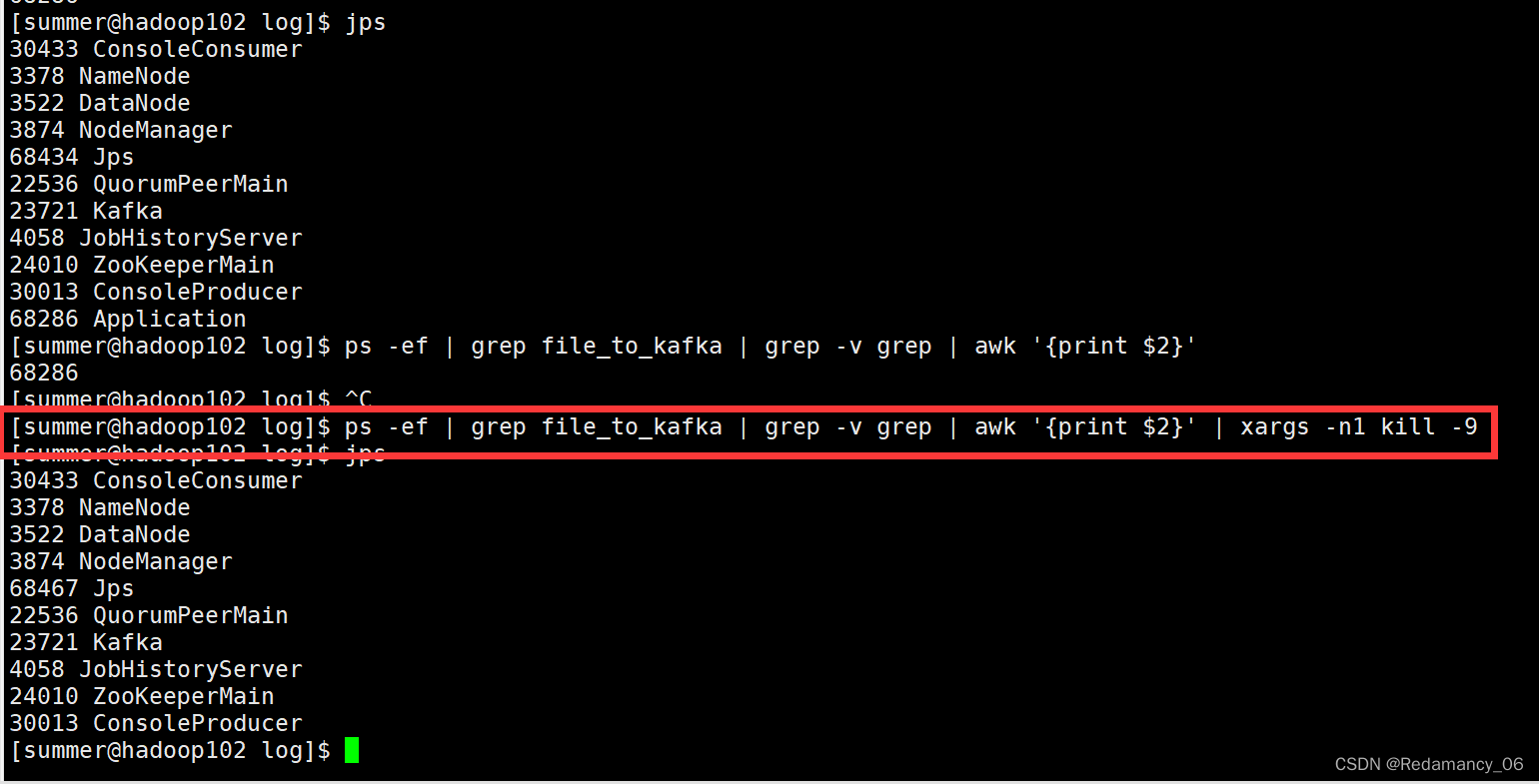
这样就达到我们想要的结果了。
但是要是往脚本里面写的话得在awk '{print $2}‘里面多加一个反斜杠,因为最外层有$1了,如果在写$2会和外层冲突,所以加一个’'比较好awk ‘{print $2}’
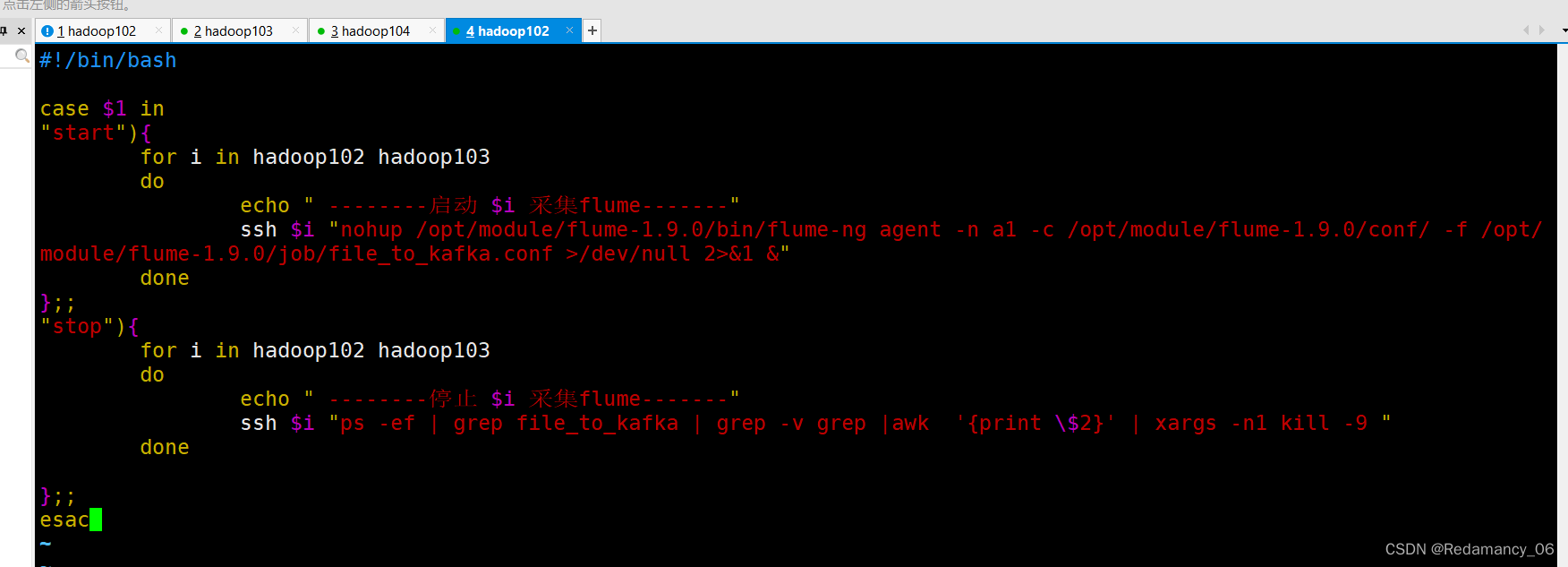
在hadoop102节点的/home/summer/bin目录下创建脚本f1.sh
完整的脚本代码如下:
#!/bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/flume-1.9.0/bin/flume-ng agent -n a1 -c /opt/module/flume-1.9.0/conf/ -f /opt/module/flume-1.9.0/job/file_to_kafka.conf >/dev/null 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file_to_kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac

[summer@hadoop102 applog]$ cd /home/summer/bin/
[summer@hadoop102 bin]$ vim f1.sh
4.3.5.3 增加脚本执行权限
[summer@hadoop102 bin]$ chmod 777 f1.sh
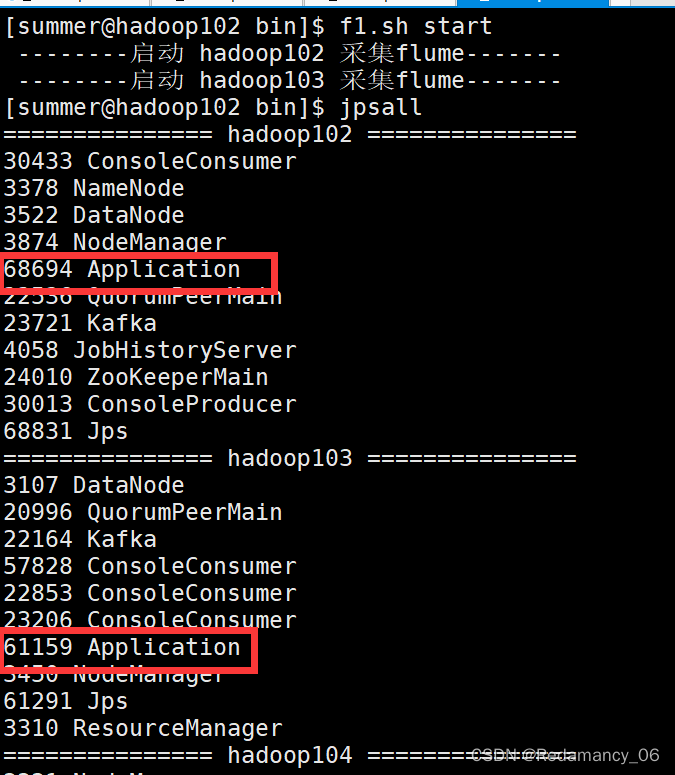
4.3.5.4 f1启动
[summer@hadoop102 bin]$ f1.sh start
4.3.5.5 f2停止
[summer@hadoop102 bin]$ f1.sh stop
