文章目录
前言
主要内容
- 项目框架
- 数据源解析
- 统计推荐模块
- 基于LFM的离线推荐模块
- 基于自定义模型的实时推荐模块
- 其他形式的离线相似推荐模块
- 基于内容的模块推荐
- 基于物品的协同过滤推荐模块
一、项目框架
大数据处理流程
- 数据源:结构化数据(关系数据)、半结构化数据(日志数据)、非结构化数据(图片视频)
- 数据采集:ETL工具、Scribe、Flume、Kafka、Sqoop
- 数据存储:Oracle、GreenPlum、Cassandra、Hbase、HDFS
- 数据计算:Mahout、Storm、Flink、Spark、MapReduce
- 数据应用:业务应用、Tableau、BI分析、可视化ECharts D3
实时处理流程
- 用户接口 (业务请求)
- 后台服务器 (前端/后端埋点)
- 日志文件 (Flume)
- 日志采集 (kafka)
- 数据总线 (Kafka消息队列)
- 实时计算
- 数据存储
- 数据可视化
离线处理流程
用户接口 -> 后台服务器 -> 日志文件 -> 日志采集 -> 日志存储 -> 日志清洗 -> 数据加载 -> 数据仓库 -> 数据计算 -> 数据存储 -> 数据可视化
二、项目系统设计
系统模块设计
- 实时推荐
- 离线推荐
- 热门推荐
- 标签
- 相似推荐
项目系统架构
业务系统构成
-
用户可视化:NGULARJS
-
推荐结果展示
-
商品检索
-
商品信息详情
-
商品标签
-
商品评分
扫描二维码关注公众号,回复: 16557147 查看本文章
-
综合业务服务:Spring
-
推荐结果查询
-
商品检索
-
商品信息详情
-
商品标签
-
商品评分
-
业务数据库:MongDB(流行、数据量大、文档型数据库=>Json串)
-
离线统计服务:历史热门商品统计、近期热门商品统计、商品平均分统计
-
离线推荐服务:
- ALS - LFM – UserRecs – ProductRecs
- TF-IDF –
-
缓存数据库:Redis
推荐系统构成
离线推荐(离线):
- 离线统计服务 Scala Spark SQL
- 离线推荐服务 Scala Spark MLlib
实时推荐(在线): - 日志采集服务 Flume-ng
- 消息缓冲服务 kafka
- 实施推荐服务 Spark Streaming
项目数据流图
数据源解析
- 商品信息:products.csv
- 商品ID(productId)
- 商品名称(name)
- 商品种类(categories)
- 商品图片URL(imageUrl)
- 商品标签(tags)
- 用户评分数据:ratings.csv
- 用户ID(uid)
- 商品ID(productid)
- 商品评分(score)
- 评分时间(timestamp)
主要数据模型
-
商品信息表
-
用户评分信息表
-
用户表
-
历史热门商品统计表
-
近期热门商品统计表
-
商品平均评分统计表
-
离线(基于LFM)用户推荐列表
-
离线(基于LFM)商品相似度表(为后续实时推荐准备)
-
离线(基于内容)商品相似度表
-
离线(基于Item-CF)商品相似度表
-
实时用户推荐列表
实现模块
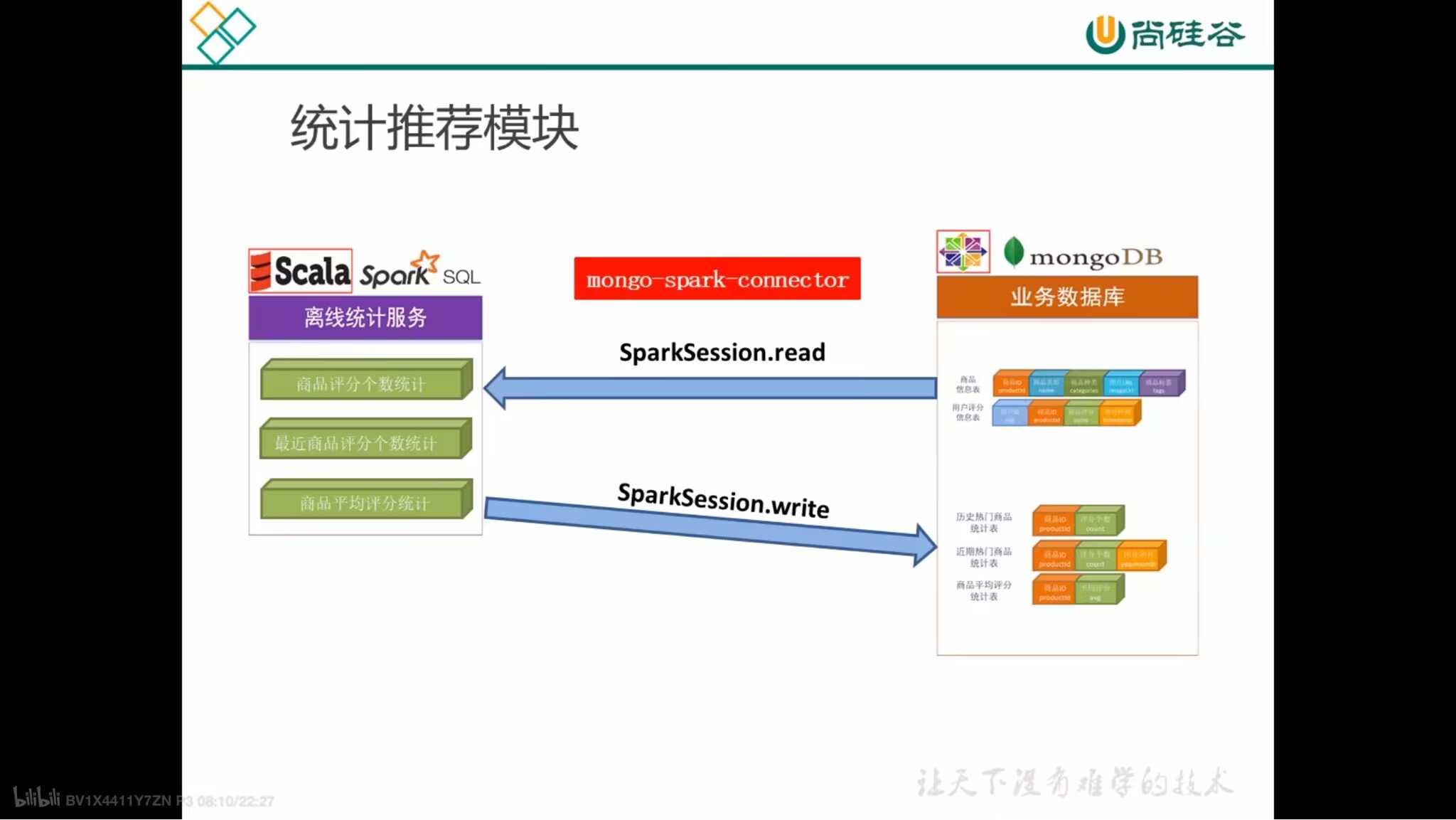
统计推荐模块
历史热门商品统计
- 统计所有历史数据中每个商品的平分数
select productId, count(productId) as count from rating group by productId order by count desc=> RateMoreProducts- RateMoreProducts 数据结构:productId,count
近期热门商品统计
- 统计每月的商品评分个数,代表商品近期的热门度
select productId, score, changeDate(timestamp) as yearmonth from ratings=> ratingOfMonthselect productId, count(productId) as count, yearmonth from ratingOfMonth group by yearmonth, productId order by yearmonth desc, count desc=> RateMoreRecentlyProducts- changeDate:UDF函数,使用SimpleDateFormat对Date进行格式转化,转化格式为’‘yyyyMM’’
- RateMoreRecentlyProducts 数据结构:productId,count,yearmonth
商品平均评分统计
select productId, avg(sorce) as avg from ratings group by productId order by avg desc=> AverageProducts- AverageProducts 数据结构:productId,avg
基于LFM的离线推荐模块
-
用ALS算法训练隐语义模型
val model = ALS.train(trainData, rank, iterations, lambda)- 要求数据结构:RDD / DataFrame
- trainData:训练数据
- rank:隐特征个数k
- iterations:迭代次数
- lambda:正则化次数
- RMSE:均方根误差
- 参数调整:通过均方根误差,多次调整参数值,选择RMSE最小的一组参数值

-
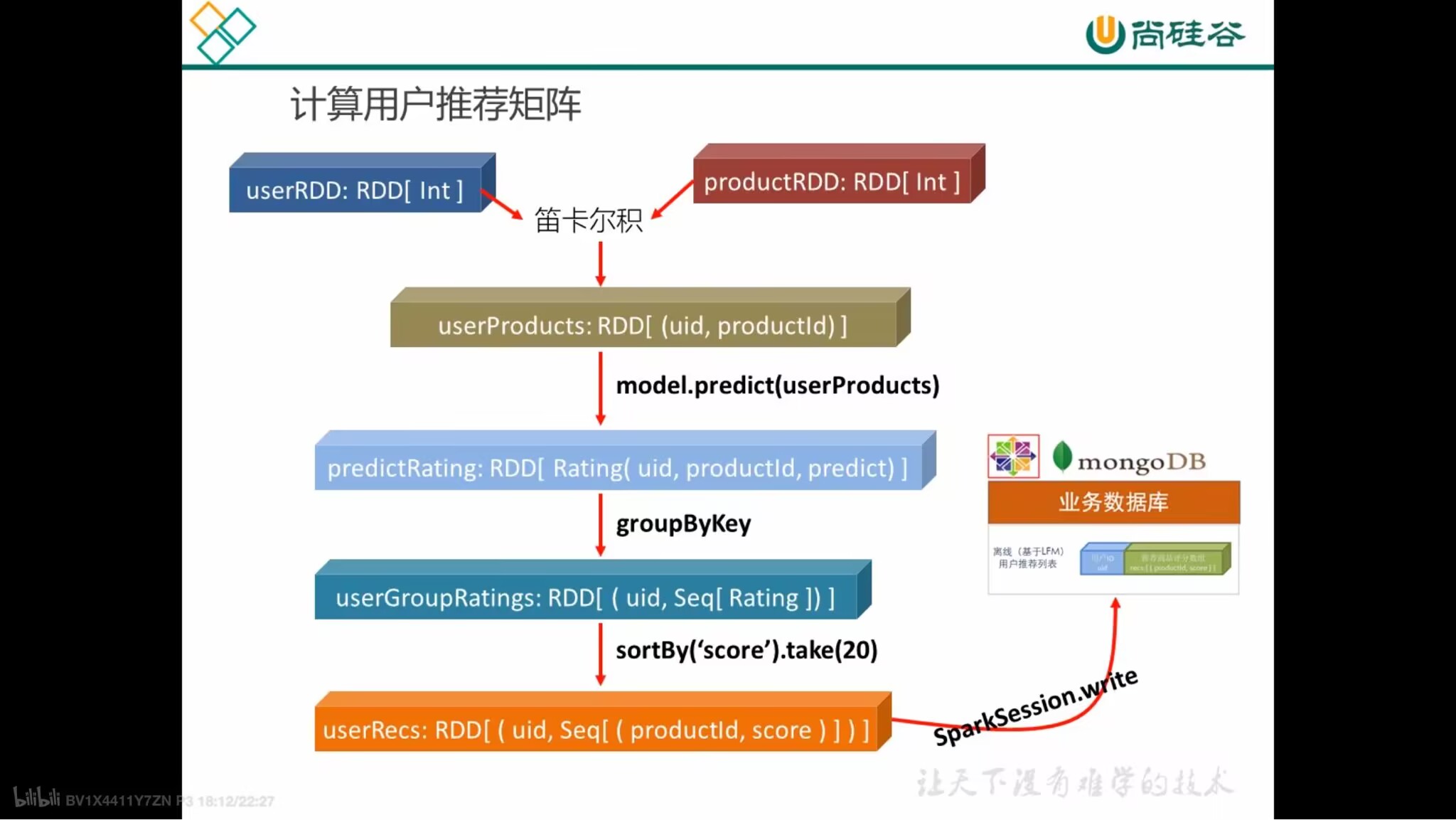
计算用户推荐矩阵
-
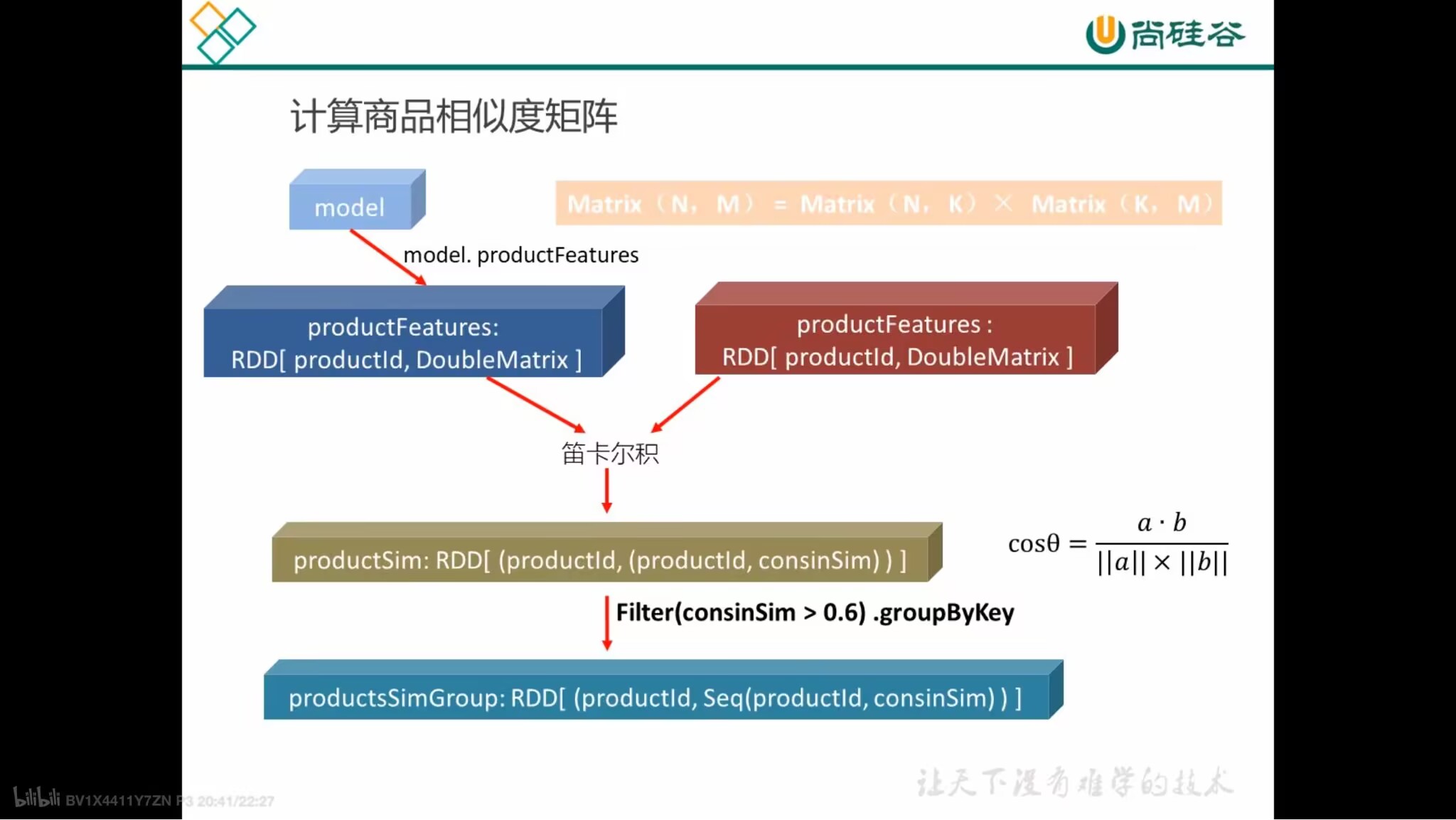
计算商品相似度矩阵
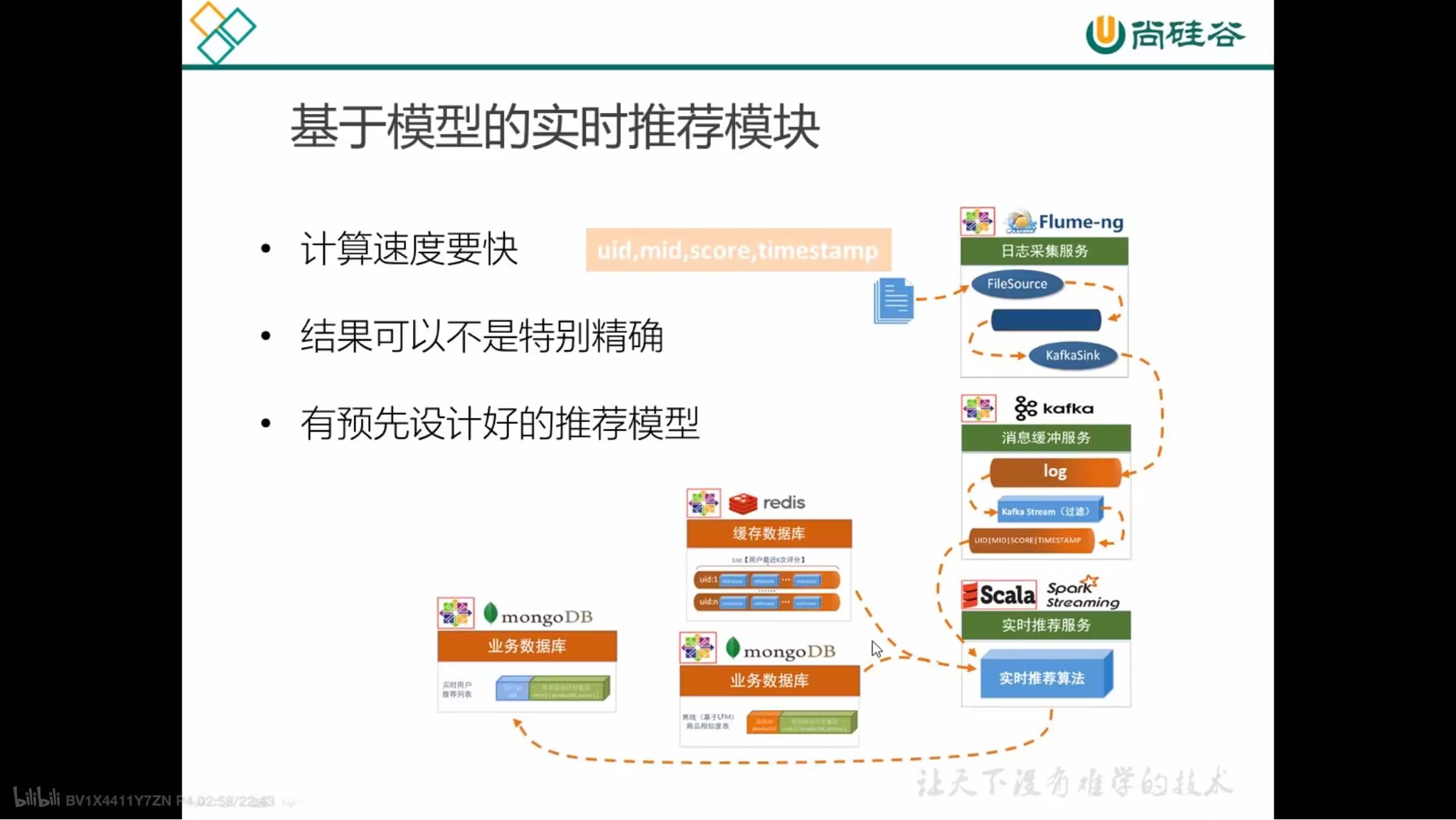
基于模型的实时推荐模块
- 计算速度快
- 结果可以不是特别精确
- 有预先设计好的推荐模型
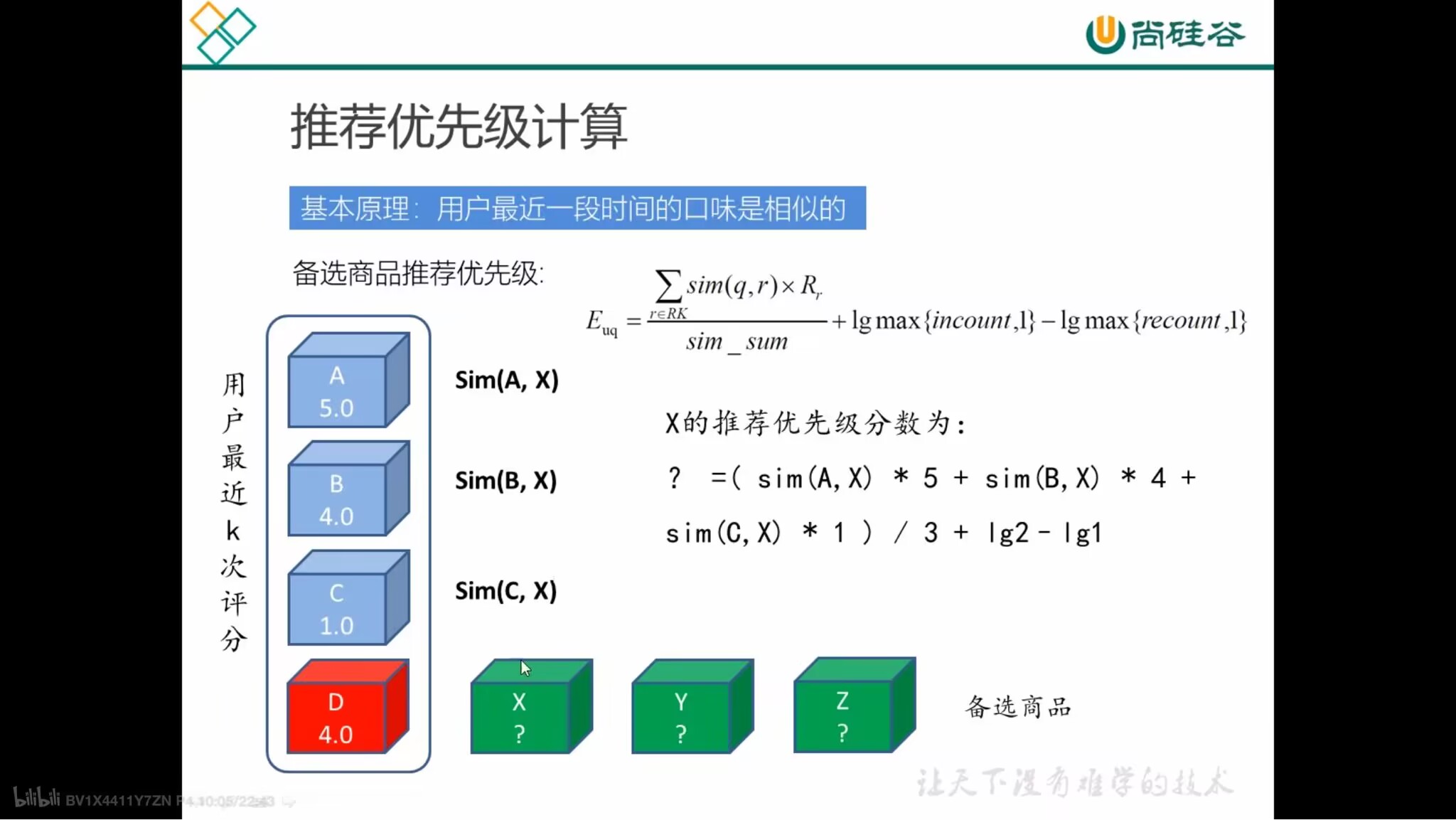
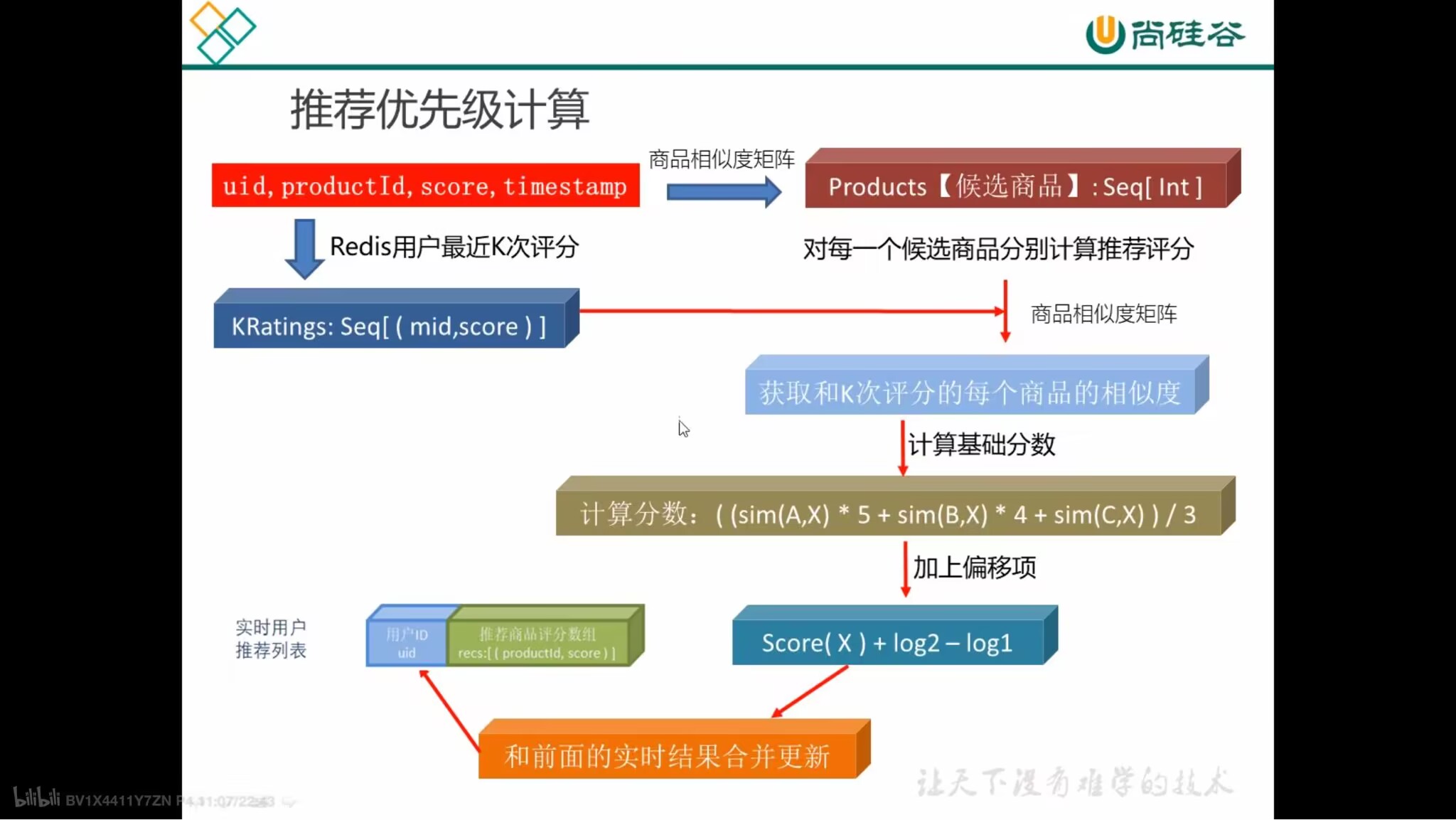
推荐优先级计算
- 基本原理:用户最近一段时间的口味是相似的
- 相似度 - 评分分值
其他形式的离线相似推荐
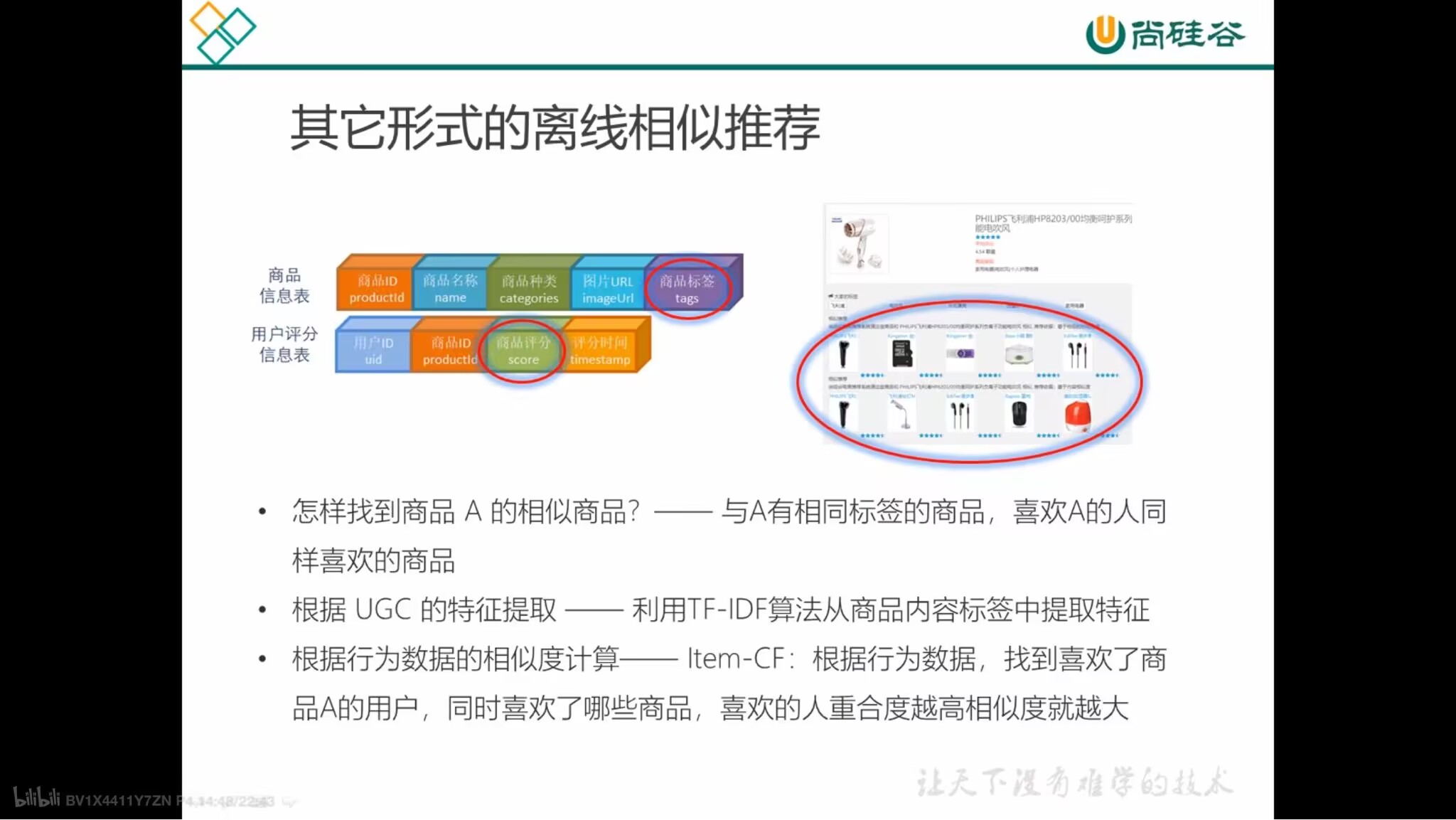
基于内容的推荐
- 基于商品的用户标签信息,用TF-IDF算法提取特征向量
- 计算特征向量的余弦相似度,得到商品的相似列表
- 在实际应用中,一般会在商品详情页、或商品购买页将相似商品推荐出来

基于物品的协同过滤推荐
- 基于物品的协同过滤(Item-CF),只需手机用户的常规行为数据(比如点击、收藏、购买)就可以得到商品间的相似度,在实际项目中引用广泛
- “同现相似度”——利用行为数据计算不同商品间的相似度

混合推荐——分区混合
- 基于模型的推荐
- 基于协同过滤的推荐
- 基于内容的推荐
- 基于统计的推荐