1、sqoop执行流程
1)读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop
2)设置好job,主要也就是设置好的各个参数
3)这里就由Hadoop来执行MapReduce来执行Import命令了,
a.首先要对数据进行切分,也就是DataSplit
DataDrivenDBInputFormat.getSplits(JobContext job)
b.切分好范围后,写入范围,以便读取
DataDrivenDBInputFormat.write(DataOutput output) 这里是lowerBoundQuery and upperBoundQuery
c.读取以上2)写入的范围
DataDrivenDBInputFormat.readFields(DataInput input)
d.然后创建RecordReader从数据库中读取数据
DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)

e.创建Map
TextImportMapper.setup(Context context)
f.RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给Map
DBRecordReader.nextKeyValue()
g.运行map
TextImportMapper.map(LongWritable key, SqoopRecord val, Context context)
最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()
参数:
Sqoop的包含很多工具,使用之前需要先指定具体的工具,在使用该工具的命令选项:
| 选项 |
含义说明 |
| --connect <jdbc-uri> |
指定JDBC连接字符串 |
| --connection-manager <class-name> |
指定要使用的连接管理器类 |
| --driver <class-name> |
指定要使用的JDBC驱动类 |
| --hadoop-mapred-home <dir> |
指定$HADOOP_MAPRED_HOME路径 |
| --help |
万能帮助 |
| --password-file |
设置用于存放认证的密码信息文件的路径 |
| -P |
从控制台读取输入的密码 |
| --password <password> |
设置认证密码 |
| --username <username> |
设置认证用户名 |
| --verbose |
打印详细的运行信息 |
| --connection-param-file <filename> |
可选,指定存储数据库连接参数的属性文件 |
2、数据导入工具import
所谓import工具,是将关系数据库数据导入到Hadoop平台,基本命令选项如下:
| 参数 | 说明 |
| --as-avrodatafile | 将数据导入到Avro数据文件 |
| --as-sequencefile | 将数据导入到SequenceFile |
| --as-textfile | 将数据导入到普通文本文件(默认) |
| --columns<cl,col,col,...> | 指定要导入的字段值 |
| -m或--num-mappers | 确定导入数据时启动的并行map数,默认为4 |
| --target-dir<dir> | 指定导入数据的hdfs路径--目标路径 |
| --query <selectstatement> | 从查询结果中导入数据,与--target-dir共用 |
| --hive-table | 导入的hive表 |
| --hive-database | 导入的hive库 |
| --where | 从关系型数据库导入数据时的查询条件,接where的查询条件。例如:‘–where id<100’ |
| --null-non-string<null-string> | 指定非字符串类型为null时的替代字符 |
| --null-string<null-string> | 指定字符串类型为null时的替代字符 |
| --boundary-query <statement> | 边界查询,用于创建分片(InputSplit) |
| --columns <col,col,col…> | 从表中导出指定的一组列的数据 |
| --append | 将数据追加到HDFS上一个已存在的数据集上 |
| --delete-target-dir | 如果指定目录存在,则先删除掉 |
| --direct | 使用直接导入模式(优化导入速度) |
| --direct-split-size <n> | 分割输入stream的字节大小(在直接导入模式下) |
| --fetch-size <n> | 从数据库中批量读取记录数 |
| --inline-lob-limit <n> | 设置内联的LOB对象的大小 |
| -m,--num-mappers <n> | 使用n个map任务并行导入数据 |
| -e,--query <statement> | 导入的查询语句 |
| --split-by <column-name> | 指定按照哪个列去分割数据 |
| --table <table-name> | 导入的源表表名 |
| --target-dir <dir> | 导入HDFS的目标路径 |
| --warehouse-dir <dir> | HDFS存放表的根路径 |
一、导入数据
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字。
RDBMS到HDFS
(1)全部导入
全量数据导入就是一次性将所有需要导入的数据,从关系型数据库一次性地导入到Hadoop中(可以是HDFS、Hive等)。
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--table staff \
--target-dir /user/company \
--delete-target-dir \ #如果目录存在,使用--delete-target-dir
--num-mappers 1 \ #默认启动4个进程导入(map数量),可以设置 1表示不并行
--fields-terminated-by "\t"
可以看到sqoop的作用其实是类似于hive的,都是将输入的指令转换为mapreduce任务:
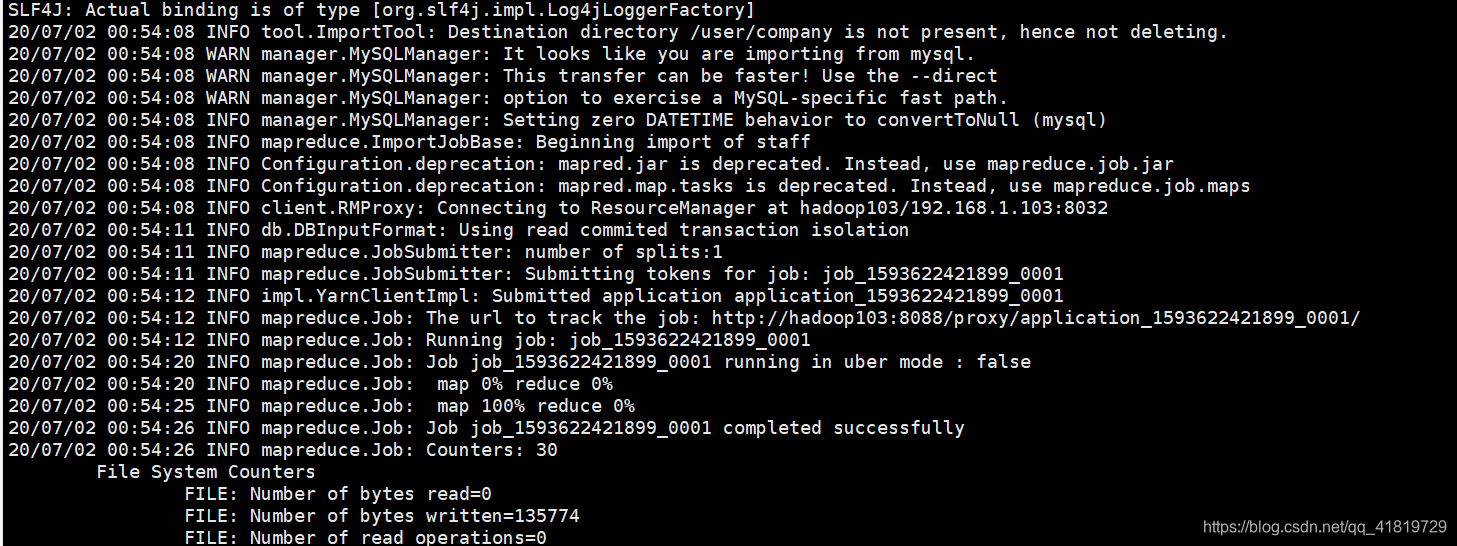

(2)query查询导入
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
and $CONDITIONS 不可省略,因为sqoop会补充当前操作所需的其他条件。如果不加该关键字,系统会提示:must contain ‘$CONDITIONS’ in WHERE clause.如果query后使用的是双引号,则$CONDITIONS前必须加转移符,防止shell识别为自己的变量
(3)导入指定列 columns
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex \
--table staff
columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格,原因在于命令行参数是用空格来隔开的

(4)使用where关键字筛选查询导入数据
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1" #--where "job='CTO'" (可以使用模糊批量匹配)

e. 启用压缩
sqoop import
--connect jdbc:mysql://crxy172:3306/test
--username root -password 123456
--table info -m 1 --append
--where "job like 'CTO'" -z
--compression-codec org.apache.hadoop.io.compress.SnappyCodec (直接指定压缩编码)
#(默认Gzip压缩)f. 导入空值处理
字符串类型:
sqoop import --connect jdbc:mysql://crxy172:3306/test --username root --password 123456 --table info -m 1 --append --null-string "--" (不可以,不能是关键字符)
sqoop import --connect jdbc:mysql://crxy172:3306/test --username root --password 123456 --table info -m 1 --append --null-string "*"
非字符串类型:
sqoop import --connect jdbc:mysql://crxy172:3306/test --username root --password 123456 --table info -m 1 --append --null-string "*" --null-non-string "="
二、RDBMS到Hive
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive
提示:该过程分为两步,第一步将数据导入到HDFS,第二步将导入到HDFS的数据迁移到Hive仓库,第一步默认的临时目录是/user/username/表名
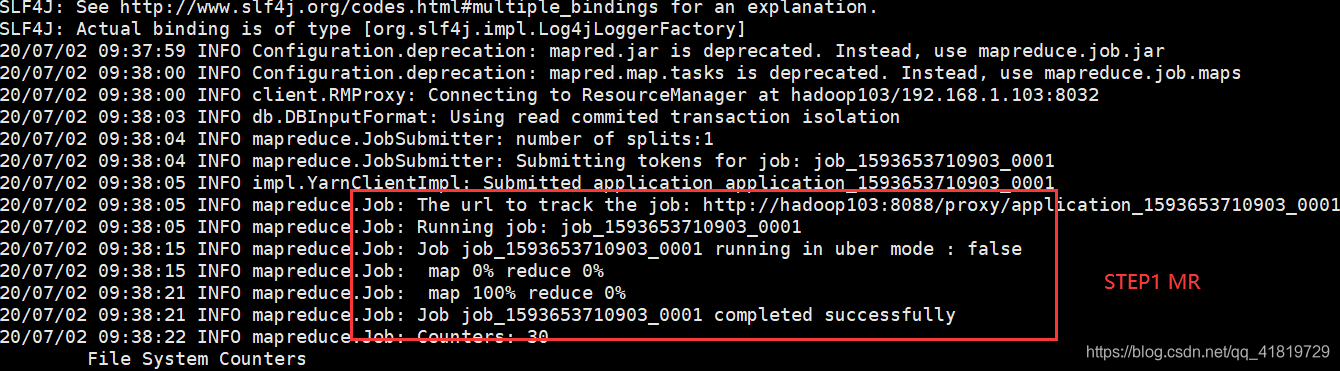
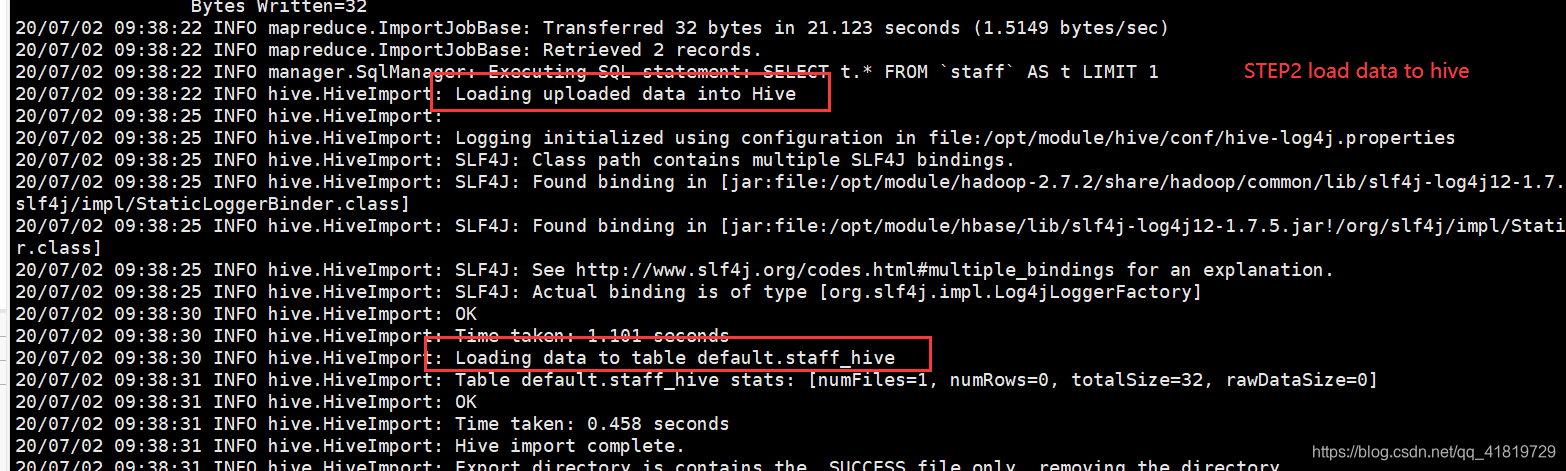
方法1(直接导入):将mysql数据直接导入hive表中
#直接导入适用于将单个表中部分数据或所有数据导入hive表中的情况
sqoop import \
--connect jdbc:mysql://localhost:3306/bdp \
--username root \
--password 123456 \
--table emp \
--hive-import #从关系型数据库向hive中导入数据的标志
--hive-database test #导入的hive库
--hive-table EMP #导入的hive表
#--columns class_id,class_name,teacher #仅导入class_id,class_name,teacher
#–columns接的字段时mysql表的字段,要求这些字段要和Hive表中的字段对应,数据类型要对应,否则会出现异常
#--where 'id>10' #where指定条件,用引号引起来
--hive-partition-key time # hive表的分区字段,字段类型默认为string
--hive-partition-value '2018-05-18' #与--hive-partition-key同时使用,指定导入的分区值
--hive-overwrite #可选,导入前清理hive表中所有数据
--null-string '\\N' #指定字符串类型为null时的替代字符
--null-non-string '\\N' #指定非字符串类型为null时的替代字符
--fields-terminated-by ','
--lines-terminated-by '\n'
-m 1
#多分区时,对应的参数应该为:
#--hcatalog-database,--hcatalog-table,--hcatalog-partition-keys和--hcatalog-partition-values
注意:fields-terminated-by 要是不指定值的话,默认分隔符为'\001',
并且以后每次导入数据都要设置 --fields-terminated-by '\001',
不然导入的数据为NULL。建议手动设置 --fields-terminated-by的值导入hive参数
| 参数 |
说明 |
| --hive-home <dir> |
直接指定hive安装目录 |
| --hive-import |
使用默认分隔符导入hive |
| --hive-overwrite |
覆盖掉在hive表中已经存在的数据 |
| --create-hive-table |
生成与关系数据库表的表结构对应的HIVE表。如果表不存在,则创建,如果存在,报错。 |
| --hive-table <table-name> |
导入到hive指定的表,可以创建新表 |
| --hive-drop-import-delims |
导入数据到hive时,删除字符串字段中的 \n, \r, and \01 |
| --hive-delims-replacement |
用自定义的字符串替换掉数据中的\n, \r, and \01等字符 |
| --hive-partition-key |
创建分区,后面直接跟分区名即可,创建完毕后,通过describe 表名可以看到分区名,默认为string型 |
| --hive-partition-value <v> |
该值是在导入数据到hive中时,与–hive-partition-key设定的key对应的value值。 |
| --map-column-hive <map> |
生成hive表时,可以更改生成字段的数据类型,格式如:–map-column-hive LAST_ACCESS_TIME=string |
| --fields-terminated-by |
指定分隔符(hive默认的分隔符是/u0001) |
方法2(导入hdfs):先将mysql数据导入hdfs上,之后再将hdfs数据加载到hive中
# 全量数据导入
sqoop import \
--connect jdbc:mysql://192.168.xxx.xxx:3316/testdb \
--username root \
--password 123456 \
--query “select * from test_table where \$CONDITIONS” \
--query 'select id, brand_id,name ,sysdate from bbs_product where $CONDITIONS LIMIT 100' \
#将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
--query 'select * from emp inner join user on emp.id=user.id where id>10'
#--query参数可以对多个mysql表join后的数据集进行筛选,该方法可以将指定的数据集(可能涉及多张表)导入hdfs,并不限于单张表
--target-dir /user/root/person_all \
--fields-terminated-by “,” \
--hive-drop-import-delims \
--null-string “\\N” \
--null-non-string “\\N” \
--split-by id \
-m 6 \
加载数据到hive表:
load data inpath '/user/data/mysql/emp ' into table test.EMP2| 参数 | 说明 |
|---|---|
| – query | SQL查询语句,与--target-dir共用 |
| -query-sql: | 使用的查询语句,例如:”SELECT * FROM Table WHERE id>1 AND \$CONDITIONS”。 记得要用引号包围,最后一定要带上 AND \$CONDITIONS。 |
| – target-dir | HDFS目标目录(确保目录不存在,否则会报错,因为Sqoop在导入数据至HDFS时会自己在HDFS上创建目录) |
| –hive-drop-import- delims | 删除数据中包含的Hive默认分隔符(^A, ^B, \n) |
| –null-string | string类型空值的替换符(Hive中Null用\n表示) |
| –null-non-string | 非string类型空值的替换符 |
| –split-by | 数据切片字段(int类型,m>1时必须指定) 指定根据哪一列来实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。 |
| --compression-codec | org.apache.hadoop.io.compress.SnappyCodec (直接指定压缩编码) --compression-codec lzop |
| -m | Mapper任务数,默认为4 |
2、增量数据导入
事实上,在生产环境中,系统可能会定期从与业务相关的关系型数据库向Hadoop导入数据,导入数仓后进行后续离线分析。
故我们此时不可能再将所有数据重新导一遍,此时我们就需要增量数据导入这一模式了。
增量数据导入分两种,
一是基于递增列的增量数据导入(Append方式)。
二是基于时间列的增量数据导入(LastModified方式)。
一)Append方式
举个栗子,有一个订单表,里面每个订单有一个唯一标识自增列ID,在关系型数据库中以主键形式存在。之前已经将id在0~5201314之间的编号的订单导入到Hadoop中了(这里为HDFS),现在一段时间后我们需要将近期产生的新的订单数据导入Hadoop中(这里为HDFS),以供后续数仓进行分析。此时我们只需要指定–incremental 参数为append,–last-value参数为5201314即可。表示只从id大于5201314后开始导入。
# Append方式的全量数据导入
sqoop import \
--connect jdbc:mysql://192.168.xxx.xxx:3316/testdb \
--username root \
--password 123456 \
--query “select order_id, name from order_table where \$CONDITIONS” \
--target-dir /user/root/orders_all \
--split-by order_id \
-m 6 \
--incremental append \
--check-column order_id \
--last-value 5201314sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--incremental append \
--check-column id \
--last-value 3 \
-m 1| 参数 | 说明 |
|---|---|
| –incremental append | 基于递增列的增量导入(将递增列值大于阈值的所有数据增量导入Hadoop) append:追加,比如对大于last-value指定的值之后的记录进行追加导入 |
| –incremental lastmodified | 基于时间列的增量导入(将时间列大于等于阈值的所有数据增量导入Hadoop) lastmodified:最后的修改时间,追加last-value指定的日期之后的记录 |
| –check-column | 时间列(int)用来作为判断的列名,如id |
| –last-value | 阈值(int)指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值 |
| –merge-key | 合并列(主键,合并键值相同的记录) |
二)lastModify方式
此方式要求原有表中有time字段,它能指定一个时间戳,让Sqoop把该时间戳之后的数据导入至Hadoop(这里为HDFS)。因为后续订单可能状态会变化,变化后time字段时间戳也会变化,此时Sqoop依然会将相同状态更改后的订单导入HDFS,当然我们可以指定merge-key参数为orser_id,表示将后续新的记录与原有记录合并。
# 将时间列大于等于阈值的数据增量导入HDFS
sqoop import \
--connect jdbc:mysql://192.168.xxx.xxx:3316/testdb \
--username root \
--password transwarp \
--query “select order_id, name from order_table where \$CONDITIONS” \
--target-dir /user/root/order_all \
--split-by id \
-m 4 \
--incremental lastmodified \
--merge-key order_id \
--check-column time \
# remember this date !!!
--last-value “2014-11-09 21:00:00” --merge-key的作用:修改过的数据和新增的数据(前提是满足last-value的条件)都会导入进来,并且重复的数据(不需要满足last-value的条件)都会进行合并
sqoop import --connect jdbc:mysql://192.168.0.8:3306/hxy \
--username root \
--password 123456 \
--table data \
--target-dir '/soft/hive/warehouse/data' \
--check-column last_mod \
--incremental lastmodified \
--last-value '2019-08-30 16:49:12' \
--m 1 \
--append重要Tip:
生产环境中,为了防止主库被Sqoop抽崩,我们一般从备库中抽取数据。
一般RDBMS的导出速度控制在60~80MB/s,每个 map 任务的处理速度5~10MB/s 估算,即 -m 参数一般设置4~8,表示启动 4~8 个map 任务并发抽取
RDBMS即关系数据库管理系统(Relational Database Management System)
原文:Sqoop全量数据导入、增量数据导入、并发导入 (Sqoop进阶)_little prince,blue coder-CSDN博客_sqoop增量导入
#!/bin/bash
source /etc/profile
num=0
list="table1 table2 table3"
for i in $list; do
echo "$sum"
echo "$i"
echo "sqoop开始批量导入......"
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --hive-table db.$i --delete-target-dir --hive-overwrite --hive-import &
num=$(expr $num + 1)
if [$sum -gt 4 ]; then
{
echo "等待批量任务完成"
wait
echo "开始下一批导入"
num = 0
}
fi
done
echo "等待最后一批任务完成"
wait
echo "全部导入完成"二、导出数据
数据导出工具export参数
| 选项 |
含义说明 |
| --validate <class-name> |
启用数据副本验证功能,仅支持单表拷贝,可以指定验证使用的实现类 |
| --validation-threshold <class-name> |
指定验证门限所使用的类 |
| --direct |
使用直接导出模式(优化速度) |
| --export-dir <dir> |
导出过程中HDFS源路径 |
| -m,--num-mappers <n> |
使用n个map任务并行导出 |
| --table <table-name> |
导出的目的表名称 |
| --call <stored-proc-name> |
导出数据调用的指定存储过程名 |
| --update-key <col-name> |
更新参考的列名称,多个列名使用逗号分隔 |
| --update-mode <mode> |
指定更新策略,包括:updateonly(默认)、allowinsert:如果存在就更新,不存在就插入 |
| --input-null-string <null-string> |
使用指定字符串,替换字符串类型值为null的列 |
| --input-null-non-string <null-string> |
使用指定字符串,替换非字符串类型值为null的列 |
| --staging-table <staging-table-name> |
在数据导出到数据库之前,数据临时存放的表名称(用于事务处理) |
| --clear-staging-table |
清除工作区中临时存放的数据 |
| --batch |
使用批量模式导出 |
| –bindir <dir> |
指定生成的java文件、编译成的class文件及将生成文件打包为JAR的JAR包文件输出路径 |
| –class-name <name> |
设定生成的Java文件指定的名称 |
| –outdir <dir> |
生成的java文件存放路径 |
| –package-name<name> |
包名,如cn.cnnic,则会生成cn和cnnic两级目录,生成的文件(如java文件)就存放在cnnic目录里 |
| –input-null-non-string<null-str> |
在生成的java文件中,可以将null字符串设为想要设定的值(比如空字符串’’) |
| –input-null-string<null-str> |
同上,设定时,最好与上面的属性一起设置,且设置同样的值(比如空字符串等等)。 |
| –map-column-java<arg> |
数据库字段在生成的java文件中会映射为各种属性,且默认的数据类型与数据库类型保持对应,比如数据库中某字段的类型为bigint,则在Java文件中 的数据类型为long型,通过这个属性,可以改变数据库字段在java中映射的数据类型,格式如:–map-column-java DB_ID=String,id=Integer |
| –null-non-string<null-str> |
在生成的java文件中,比如TBL_ID==null?”null”:””,通过这个属性设置可以将null字符串设置为其它值如ddd,TBL_ID==null “ddd”:”” |
| –null-string<null-str> |
同上,使用的时候最好和上面的属性一起用,且设置为相同的值 |
| –table <table-name> |
对应关系数据库的表名,生成的java文件中的各属性与该表的各字段一一对应。 |
乱码问题
sqoop export --connect "jdbc:mysql://crxy172:3306/test?useUnicode=true&characterEncoding=utf-8" --username root --password 123456 --table info --export-dir export
f. 导出空值处理
--input-null-string string类型使用参数
--input-null-non-string <null-string> 非string类型使用参数
二、HIVE/HDFS到RDBMS
1.全部导出
sqoop export
--connect jdbc:mysql://192.168.32.128:3306/hive
--username root
--password root
--table t_user
--export-dir /usr/hive/warehouse/hivetest.t_user
--input-fields-terminated-by '\001' #sqoop默认的分隔符是','
--num-mappers 4
#--input-fields-terminated-by和-fields-teminated-by区别
--input-fields-terminated-by:表示用于hive或hdfs数据导出到外部存储分隔参数;
--fields-terminated-by:表示用于外面存储导入到hive或hdfs中需要实现字段分隔的参数;Sqoop export
--connect jdbc:mysql://127.0.0.1:3306/dbname
--username mysql(mysql用户名)
--password 123456(密码)
--table student(mysql上的表)
--columns "id,name,age"
--hcatalog-database sopdm(hive上的schema)
--hcatalog-table student(hive上的表)
--hcatalog-database temp \
--hcatalog-table js_pianyuan_orc \
--hcatalog-partition-keys curdate \
--hcatalog-partition-values 20180122 \2.部分导入,增量导出
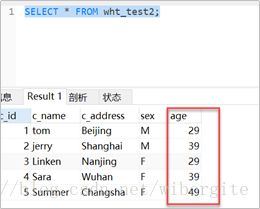
修改Hive表数据,修改age的值,并新增一行记录,然后重新导出,看目标表中的数据是否会被修改
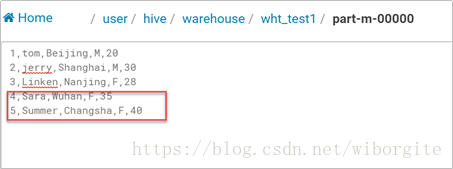
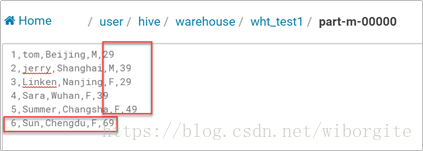
Ø allowinsert模式 ,新增数据被导出:
sqoop export
--connectjdbc:mysql://localhost:3306/wht
--username root
--password cloudera
--tablewht_test2
--fields-terminated-by ','
--update-key c_id
--update-mode allowinsert
--export-dir /user/hive/warehouse/wht_test1
Ø updateonly模式:Hive表中修改的数据被更新,但不会导出新插入的记录:
sqoop export
--connectjdbc:mysql://localhost:3306/wht
--username root
--password cloudera
--tablewht_test2
--fields-terminated-by ','
--update-key c_id
--update-mode updateonly
--export-dir/user/hive/warehouse/wht_test1
2、sqoop无法导出parquet文件到mysql,问题解决
创建分区 外部表 采用 parquet 格式 ,SNAPPY压缩
create external table if not exists dwd_report_site_hour(
sitetype string,
sitename string,
innum int,
outnum int,
datatime string,
inserttime timestamp,
modifyTime timestamp
)
partitioned by(dt string)
row format delimited
fields terminated by '\001'
stored as parquet TBLPROPERTIES('parquet.compression'='SNAPPY');sqoop export \
--connect jdbc:mysql://localhost:3306/test_db \
--username root \
--password 123456 \
--table mytest_parquet \
--export-dir /user/hive/warehouse/mytest_parquet \
-m 1分区外部表,使用 parquet 文本格式加 SNAPPY 压缩方式存储,将 指标数据 由 Hive 数仓导入 MySQL job任务失败。
Sqoop: org.kitesdk.data.DatasetNotFoundException: Descriptor location does not exist: hdfs://nameservice1/user/hive/warehouse/mytest_parquet/.metadata
Exception: Descriptor location does not exist: hdfs://nameservice1/user/hive/warehouse/mytest_parquet/.metadata
at org.kitesdk.FileSystemMetadataProvider.checkExists(FileSystemMetadataProvider.java:562)
at org.kitesdk.FileSystemMetadataProvider.find(FileSystemMetadataProvider.java:605)
at org.kitesdk.ileSystemMetadataProvider.load(FileSystemMetadataProvider.java:114)
at org.kitesdk.FileSystemDatasetRepository.load(FileSystemDatasetRepository.java:197)
at org.kitesdk.data.Datasets.load(Datasets.java:108)
at org.kitesdk.data.Datasets.load(Datasets.java:140)目前通过Sqoop从Hive的parquet抽数到关系型数据库的时候会报kitesdk找不到文件的错,这是Sqoop已知的问题,参考SQOOP-2907(参考):https://issues.apache.org/jira/browse/SQOOP-2907
解决方法:
- 指定导出的hive数据库名称与表名,去掉hdfs路径
- 使用hcatalog,指定hive的数据库与表名
sqoop-export --connect jdbc:mysql://192.168.2.226:3306/kangll \
--username root \
--password winner@001 \
--table dwd_report_site_hour \
--update-key sitetype,sitename \
--update-mode allowinsert \
--input-fields-terminated-by '\001' \
--hcatalog-database kangll \
--hcatalog-table dwd_report_site_hour \
--hcatalog-partition-keys dt \
--hcatalog-partition-values '20200910' \
--num-mappers 1 \
--input-null-string '\\N' \
--input-null-non-string '\\N'
参数说明:
--table MySQL库中的表名
--hcatalog-database Hive中的库名
--hcatalog-table Hive库中的表名,需要抽数的表
--hcatalog-partition-keys 分区字段
--hcatalog-partition-values 分区值
--num-mappers 执行作业的Map数三、RDBMS到Hbase。MYSQL-->HBASE
bin/sqoop import \
--connect jdbc:mysql://hadoop102:3306/company \
--username root \
--password 123 \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id
sqoop import -D sqoop.hbase.add.row.key=true
--connect jdbc:mysql://localhost:3306/gznt
--username gznt
--password '123'
--table t_bmda
--columns NodeCode,NodeType,NodeName,IsWarehouse,IsAssetUser
--where "ID >= 5"
--hbase-table hbase_bmda
--column-family info
--hbase-row-key NodeCode
导入HBase参数:
| 选项 |
说明 |
| --hbase-table |
指定导入到hbase中的表 |
| --column-family |
创建列族 |
| --hbase-row-key <id> |
以id字段作为key,如果输入表包含复合主键,用逗号分隔 |
| --hbase-create-table |
创建hbase表,如果hbase中该表不存在则创建 ps:我加了这个,就报错了,据说了版本兼容问题,可以先手动创建好hbase的表和列族 |
| -D sqoop.hbase.add.row.key | -D sqoop.hbase.add.row.key=true是否将rowkey相关字段写入列族中,默认false,默认你在列族中看不到任何row key中的字段。 |
四、HIVE与HBASE整合
CREATE TABLE IF NOT EXISTS all_detail (
key string comment "rowkey",
SaleDate varchar(60),
NodeCode varchar(60),
NodeName varchar(60)
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key, info:SaleDate, info:NodeCode, info:NodeName")
TBLPROPERTIES("hbase.table.name" = "hbase_tb");
;注意点:
1.建表的时候,必须建一个 key column, 如上的 key string comment "rowkey"
2.hbase.columns.mapping中是hive与hbase的对应,即 把SaleData,NodeCode,NodeName数据同步到hbase_tb下的info列族下。
Sqoop Job:
Sqoop 提供一种能力,可以把我们经常会执行的任务存储成 jobs. 这些 jobs 可以在未来任何一个时间点被我们拿来使用。
3)job生成
- 创建job:--create
- 删除job:--delete
- 执行job:--exec
- 显示job:--show
- 列出job:--list
sqoop job
--create myjob
-- import
--connect jdbc:mysql://crxy172:3306/test
--username 'root' --password '123456'
--table infosqoop job --list
sqoop job --exec myjob
sqoop job \
--create job_name \
--import \
--connect jdbc:mysql://localhost:3306/retry_db \
--username cloudera \
--password departments sqoop job -list
sqoop还支持查看已创建任务的参数配置
使用命令 sqoop job --show jobname
执行job
sqoop job --exec sqoopimport1
执行成功后可查看hive中表的数据