论文地址:https://arxiv.org/abs/2006.13108
github地址:无
本文提出了一种针对任务级自适应正则化的目标检测蒸馏方式,从三个模块对模型进行蒸馏:提取特征的backbone,用于分类的header以及用于回归的header。
Motivation
目前的知识蒸馏算法大多数都应用于分类任务,很难直接应用于检测模型。原因主要有两个方面:1. 检测任务中大量的背景样本使得正负样本不均衡,导致模型的分类任务更困难;2. 目标检测的网络更加复杂,尤其对于二阶段网络而言,有许多模块组合而成。为了解决上述问题,作者提出了随插随用的蒸馏方法,具有可移植性。
Methods
作者从三个层面进行蒸馏。算法整体框架如下图所示:
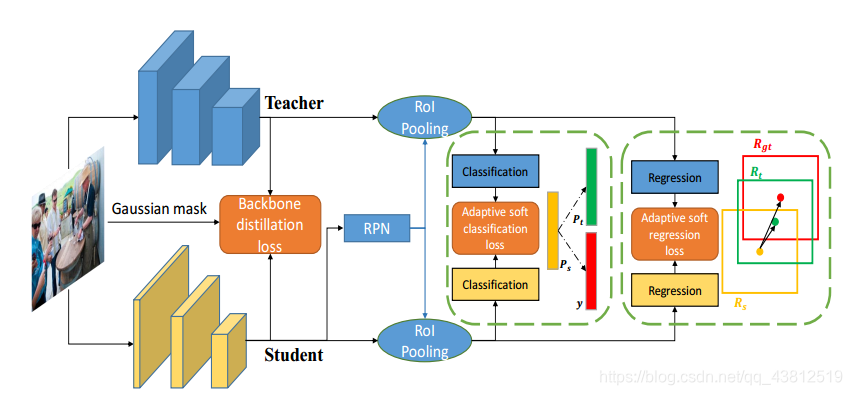
backbone层面的蒸馏:
作者使用gaussian mask提取出feature map中前景也就是目标所在的区域特征进行蒸馏。使用gaussian mask的目的是为了突出强调目标的中心区域,降低使用目标所在区域的背景引入的噪声。
具体而言,在给定目标框B后,gaussian mask的定义方式如下式所示:
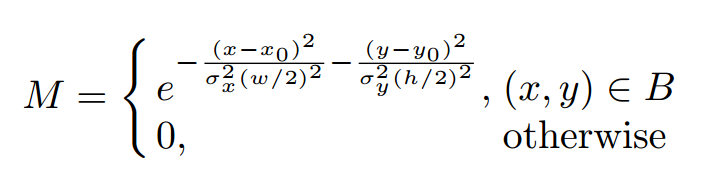 其中w,h为框的长宽,(x0,y0)为中心点, σ x \sigma_{x} σx, σ y \sigma_{y} σy为两个方向上的衰减因子,论文中简单起见设为相等的值。其效果如下图所示。
其中w,h为框的长宽,(x0,y0)为中心点, σ x \sigma_{x} σx, σ y \sigma_{y} σy为两个方向上的衰减因子,论文中简单起见设为相等的值。其效果如下图所示。

当同一个像素点上有多个框叠加时,去其中最大的值作为掩膜值。
其蒸馏loss的表达式如下式所示:
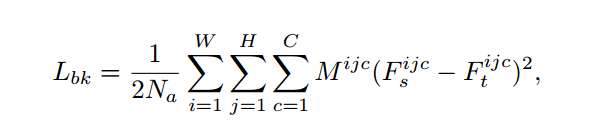
其中Na为掩膜的元素和。F分别为teacher和student的特征图。
classification层面的蒸馏:
由于在二阶段检测网络中教师和学生的RPN预测出的框不同,以及分类预测中存在大量负样本,在蒸馏时会引入噪声,因此作者在classification层面提出共享学生和教师的RPN网络从而能够实现蒸馏。另一方面,作者仅利用正样本的分类知识来指导学生学习。作者认为使用RPN共享一方面可以利于蒸馏,另一方面也提高了知识的泛化性,因为教师网络对于学生提供的预测框并没有先验知识,其分类结果具有一定的泛化能力。其loss如下式所示:
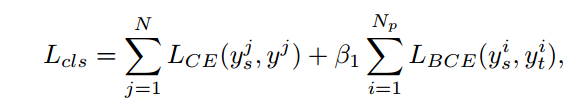
regression层面的蒸馏:
由于回归预测的无界性可能会导致教师的预测知识是错误的甚至是与groundtruth相反的,因此,作者提出基于任务的自适应蒸馏。当教师网络的预测是正确的时,将其作为知识指导学生学习,否则不蒸馏。通过计算IOU的是否叫RPN的预测有所改进来判断教师的预测正确性。其蒸馏的loss如下式所示:
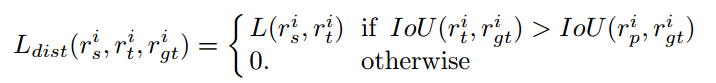
完整的回归loss如下式所示:
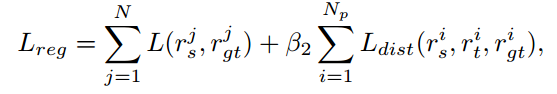
最终的loss如下式所示,为三项相加。
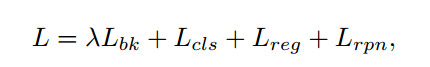
同时,为了保证训练的收敛和稳定,作者提出了自适应的蒸馏衰减。即在训练过程中,随着训练的推移,蒸馏部分的权重逐渐衰减至0,使得荀谌模型逐渐集中于检测任务本身。
Experiments
数据集:VOC0712, COCO2017
Baseline:Faster R-CNN,RetinaNet
GPU:Tesla V100 *8
batchsize:16,2 per GPU
σ x , σ y \sigma_{x}, \sigma_{y} σx,σy:2
resolution:(1333, 800) for COCO, (1000,600) for VOC
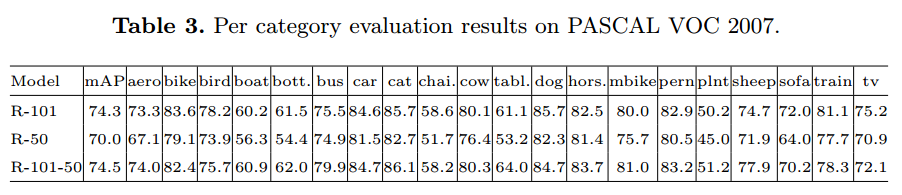
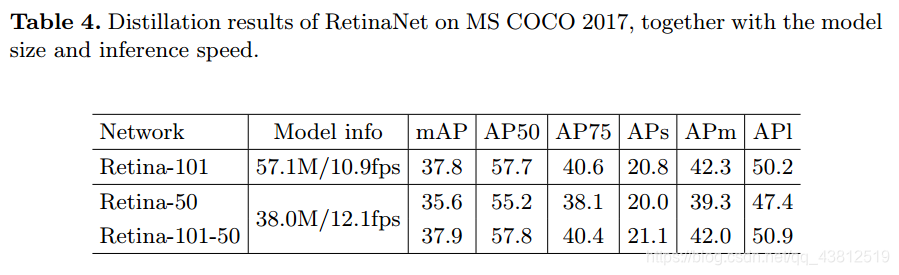
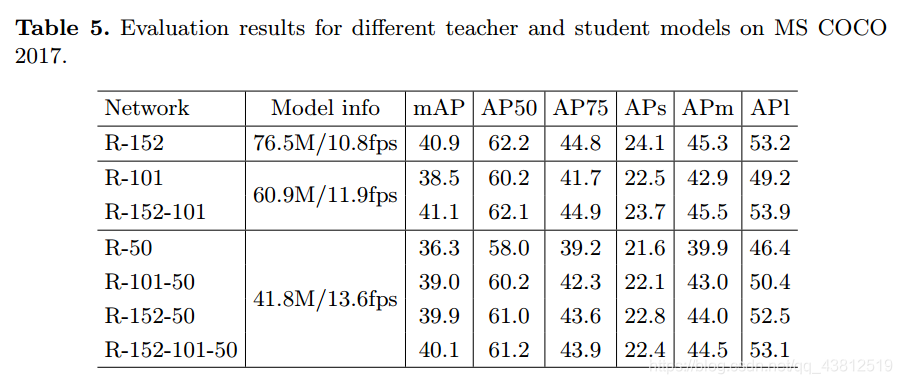
Results