反向传播算法
反向传播是一种有监督学习算法,用于训练多层感知器(人工神经网络)。
OK,为什么我们需要反向传播?
在设计神经网络时,首先,我们使用一些随机值或任何变量来初始化权重。很显然,我们不是超人,我们无法保证我们选择的任何权重都是正确的或者是最适合我们模型的。Okay, fine!我们开始时选择了一些权重值,但我们发现:模型的输出与实际输出有很大的不同,即误差值很大。
现在,我们如何减小这个误差值呢?
基本上,我们需要做的就是以某种方式不断的改变模型的参数,从而使得误差变得最小。换一种说法就是我们需要训练我们的模型,再具体些,那就是对我们的模型进行反向传播!
看看下面这些图表:
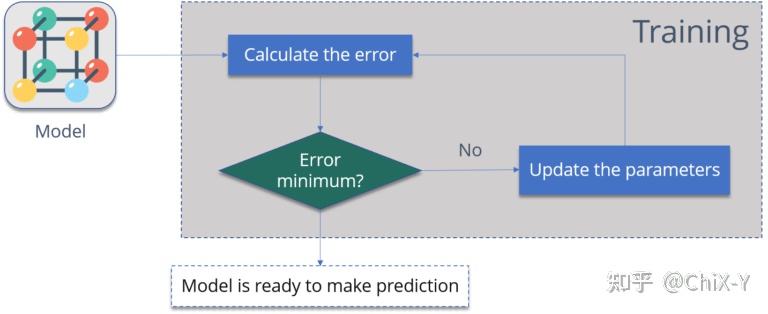
上面这个图总结一下反向传播步骤,就是:
1. 计算误差 – 模型输出与实际输出之间的差值。

2. 最小化误差 – 检查误差是否最小化。
3. 更新参数(模型权重)。
然后再次计算误差,直至误差降低到最低。
当模型误差变为最小的时候,那就是模型准备好的时候!
我很确定,现在你知道了,为什么我们需要反向传播,或者为什么以及训练模型的意义是什么,那接下来看看反向传播的真正要义。
什么是反向传播?
反向传播算法使用称为增量规则或梯度下降的技术在权重空间中寻找误差函数的最小值,然后,将使误差函数最小化的权重视为机器学习问题的最终解决方案。
举个例子:
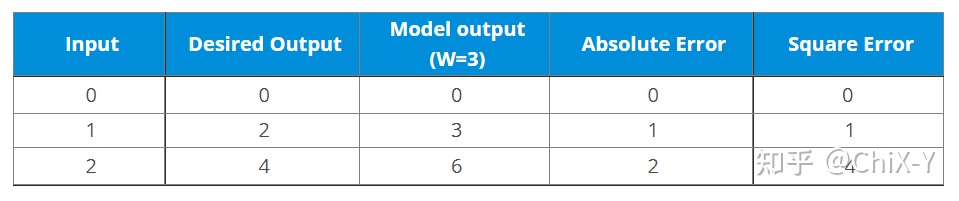
比如你现在有一个具有标签的数据集:

然后目前你的模型,如果权重值为3的时候输出如下:

可以计算出实际输出与理想输出之间的误差值:
那么如果将W改为4呢?

可以看到,如果我们增大了W,那么误差也增大了,所以我们增大W是没有正向意义的,那么如果我们减小W呢?

现在,我们在这里所做的:
1. 我们首先将一些随机值初始化为“W”,然后向前传播。
2. 然后,我们注意到有一些误差。为了减少这个误差,我们反向传播并增加“W”的值。
3. 在那之后,我们还注意到误差增加了。我们知道,我们不能增加“W”值。所以,我们再次反向传播,减少了“W”值,这个时候误差减小了。
因此,我们试图得到权重的值,使得误差最小。基本上,我们需要确定是否需要增加或减少权重值。一旦我们知道了这一点,我们将继续在该方向上更新权重值,直到误差变为最小。可能会遇到这样的情况:如果进一步更新权重,误差将增加。此时,就需要停止,这是我们的最终权重值。
看看下面这幅图:

我们需要达到的就是“Global Loss Minimum”,这就是反向传播算法,下面看一下它背后的数学原理。
反向传播算法到底怎么算的?
看看下面的神经网络:

上面的神经网络包含如下要点:
两个输入单元、两个隐含单元、两个输出单元,两个偏置单元。
以下是反向传播涉及的步骤:
步骤1:前向传播。
步骤2:反向传播。
步骤3:将所有值放在一起并计算更新的权重值。
步骤1 前向传播
首先,让我们开始前向传播:

我们将输出层神经元重复这个过程,使用隐藏层神经元的输出作为输入。

现在让我们看看误差情况:

步骤2 反向传播
现在,我们将向后传播。这样,我们将尝试通过改变权重和偏差值来减少误差。
考虑W5,我们将计算权重W5中误差变化的变化率。

由于我们是反向传播,我们需要做的第一件事是计算总误差Etotal对于out o1和out o2的变化率(偏导数),如下所示:

现在我们将进一步向后传播,计算输出out o1(或者out o2)对于net o1(或者net o2)的变化率:
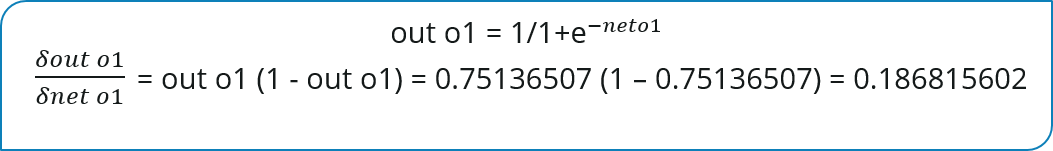
同理计算net o1对于W5的变化率:

步骤3 计算新的权重值
现在,让我们把所有的值算在一起:
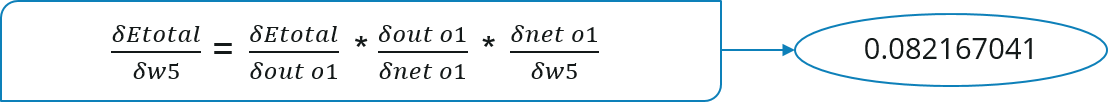
现在让我们用之前学习过的梯度下降算法中的计算式,更新W5:

同样,我们也可以用完全一样的方法去更新其他权重值,之后,我们将再次前向传播并计算输出,然后计算误差,如果误差达到最小,我们就停止,否则我们就继续反向传播更新权重。
最后编写个伪代码,更形象的描述一下反向传播算法:
initialize network weights (often small random values)
do
forEach training example named ex
prediction = neural-net-output(network, ex) // forward pass
actual = teacher-output(ex)
compute error (prediction - actual) at the output units
compute {displaystyle Delta w_{h}} for all weights from hidden layer to output layer // backward pass
compute {displaystyle Delta w_{i}} for all weights from input layer to hidden layer // backward pass continued
update network weights // input layer not modified by error estimate
until all examples classified correctly or another stopping criterion satisfied
return the network