大家好,我是 Jambo。我们已经学习了如何使用 LangChain 的一些基本功能,解下我们就应该要结合这些功能来做一些复杂的东西了。但在这之前,为了让同学们更好的理解 LangChain 在这其中做了什么,我想先介绍一下关于 GPT 使用方面的一些知识。
在 ChatGPT 开放之初,除了各大公司在 AI 算法方面竞争,还有许多人在研究如何仅通过修改 prompt 就能让 GPT-3 做出更好的回答,这种方法被称为“提示工程(Prompt Engineering)”。如果把 LLM 比喻成一个拥有一般常识的大脑,那么提示工程就是在教它如何思考,从而更有效的结合知识得出答案。像 AutoGPT 就是这样,他通过精心设计的 prompt,就能让 GPT-4 自行完成各种任务。为了让同学们了解这其中的思想,我们先从“思维链”开始介绍。
思维链(Chain of Thought)
思维链(Chain of Thought)在 ChatGPT 推出后不久就被提出,具体来说就是通过手动编写示例的方式让 GPT-3 将问题的思考过程也生成出来,通过这种方式 GPT-3 回答的效果会有大幅提升。就像我们在写比较复杂的计算题,将过程一步一步写出来的正确率会比直接写出答案要高。
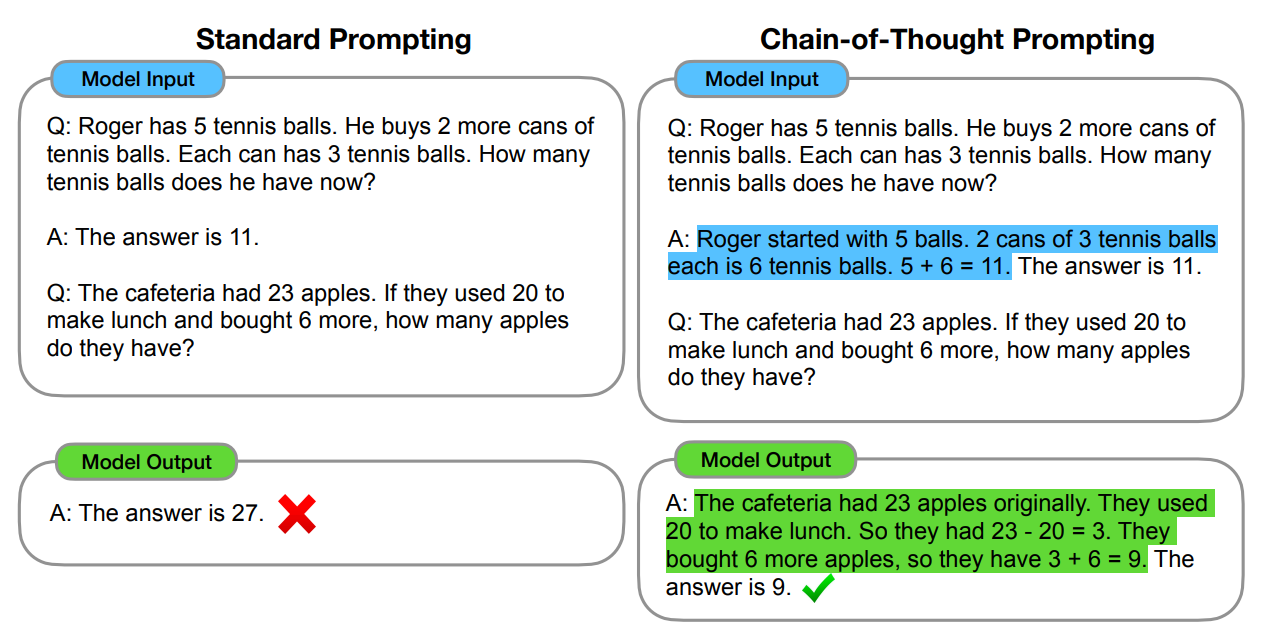
后来有人发现,只需要加上 “Let’s think step by step.” 这一魔法提示,就能达到一样的效果,还不需要写示例。并且他还在这基础上,额外让 GPT 根据它前面附带思考过程的回答,再总结出一个更简洁的答案,相当于把思考过程隐藏起来。
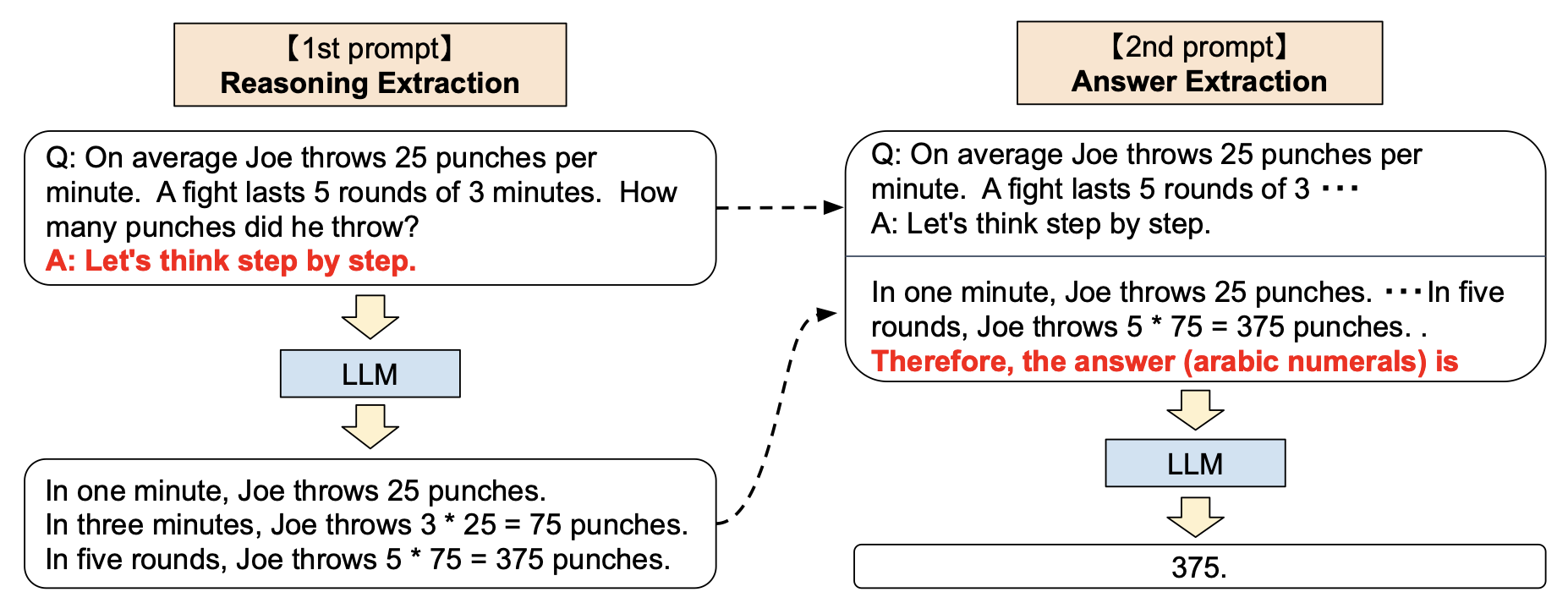
我这里想强调的是,我们用 LLM 构建应用时,完全可以在输出最终答案前多次用 LLM 分析、拆解、解决问题。就像深度学习网络中的介于输入和输出之间的隐藏层,我们可以在这里加入更多的逻辑,让 LLM 能够更好的理解问题,从而得出更好的答案。
ReAct
无论我们如何调整 prompt,但 LLM 仍然存在一个重大缺陷:它始终基于训练时的数据集和 prompt 中提供的信息生成回答。如果提问有关天气、新闻或内部文件等问题,LLM 将无法回答或会产生虚假回答(“幻觉”)。
当然,我们可以在用户提出问题后,先使用搜索引擎或内部资料库来搜索问题,然后将搜索结果作为 prompt 的一部分。但在实际应用中,这种方法的效果并不总是好的,甚至在某些情况下会产生误导。例如,如果我们想让 LLM 帮助我们修改一篇文章,在这种流程下,程序会首先使用搜索引擎搜索文章,但很可能搜索不到相关结果。这样一来,LLM 就会直接罢工,因为我们通常要求 LLM 仅根据 prompt 提供的信息生成内容,以确保准确性。
为了解决这个问题,我们可以让 LLM 自己决定是否要进行搜索,要搜索什么内容,就和上一篇教程中提到的用 LLM 优化搜索语句一样。于是 ReAct 系统就被提出来了,通过 prompt 中的示例告诉 LLM 可以使用哪些工具,然后让 LLM 自己决定是否要使用这些工具,以及如何使用这些工具。ReAct 总共有三个部分:
- 思考:根据当前的信息思考需要做什么动作。
- 行动:根据思考结果做出相应的行动,如调用工具。程序可以分析这一步生成的字符串,来调用相应的工具,类似 Python 的
eval函数。 - 观察:存放行动的结果,如搜索的内容,以便下一次思考时使用。
这三个步骤会不断循环,直到思考步骤判断已经找到答案,并在下面的行动中给出最终答案。
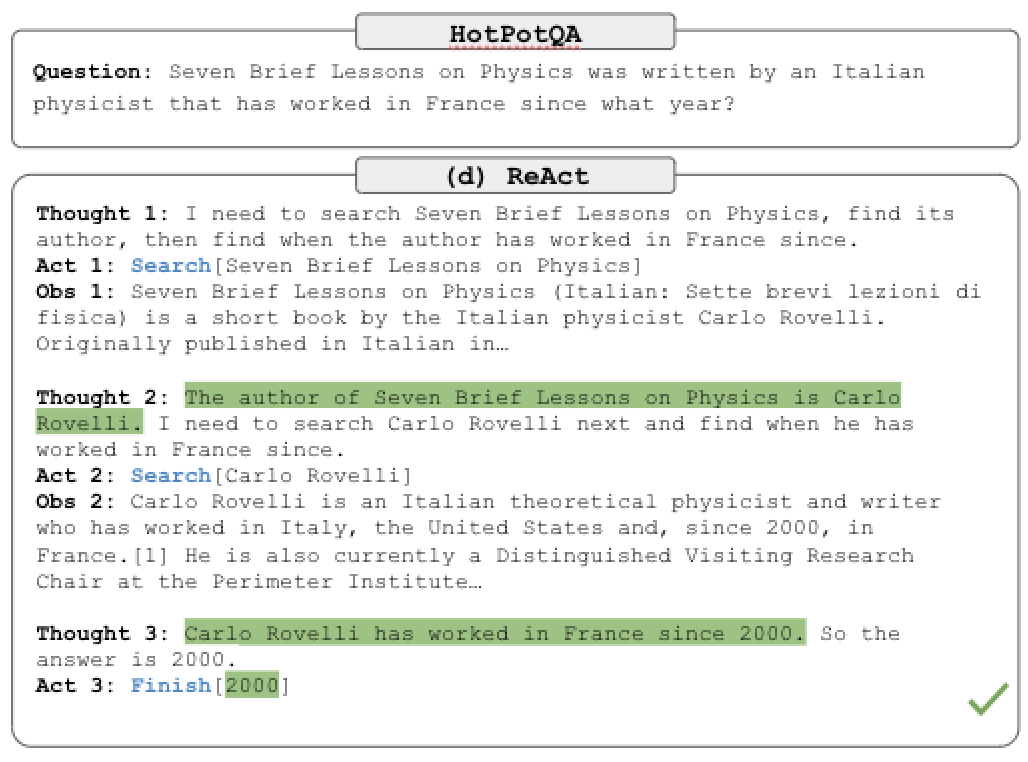
其实你仔细回想一下,这个过程和我们人类思考的过程是类似的。我们在思考时,会根据当前的信息判断是否需要做出某些行动,然后根据行动的结果来判断是否已经找到答案,如果没有就继续思考,直到找到答案为止。
AutoGPT 的行为模式实际上和 ReAct 一样,只是相比提出 ReAct 的论文中的步骤,AutoGPT 的 prompt 更加详细,并且提供了更多的工具给 LLM 使用。但不管哪种方式,都需要编写大量的示例来告诉 LLM 如何思考、行动,并且根据提供工具的不同,效果也会有所不同,并且 ReAct 的思考流程会有很多步骤。而 LangChain 帮我们把这些步骤都隐藏起来了,将这一系列动作都封装成 “代理”,而这就是我们下一章要介绍的内容了。