“ LangChain 是一个强大的框架,可以简化构建高级语言模型应用程序的过程。”
01
—
什么是Langchain
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
LangChain有很多核心概念:
1. Components and Chains
在 LangChain 中,Component 是模块化的构建块,可以组合起来创建强大的应用程序。Chain 是组合在一起以完成特定任务的一系列 Components(或其他 Chain)。例如,一个 Chain 可能包括一个 Prompt 模板、一个语言模型和一个输出解析器,它们一起工作以处理用户输入、生成响应并处理输出。
2. Prompt Templates and Values
Prompt Template 负责创建 PromptValue,这是最终传递给语言模型的内容。Prompt Template 有助于将用户输入和其他动态信息转换为适合语言模型的格式。PromptValues 是具有方法的类,这些方法可以转换为每个模型类型期望的确切输入类型(如文本或聊天消息)。
3. Example Selectors
当您想要在 Prompts 中动态包含示例时,Example Selectors 很有用。他们接受用户输入并返回一个示例列表以在提示中使用,使其更强大和特定于上下文。
4. Output Parsers
Output Parsers 负责将语言模型响应构建为更有用的格式。它们实现了两种主要方法:一种用于提供格式化指令,另一种用于将语言模型的响应解析为结构化格式。这使得在您的应用程序中处理输出数据变得更加容易。
5. Indexes and Retrievers
Index 是一种组织文档的方式,使语言模型更容易与它们交互。检索器是用于获取相关文档并将它们与语言模型组合的接口。LangChain 提供了用于处理不同类型的索引和检索器的工具和功能,例如矢量数据库和文本拆分器。
6. Chat Message History
LangChain 主要通过聊天界面与语言模型进行交互。ChatMessageHistory 类负责记住所有以前的聊天交互数据,然后可以将这些交互数据传递回模型、汇总或以其他方式组合。这有助于维护上下文并提高模型对对话的理解。
7. Agents and Toolkits
Agent 是在 LangChain 中推动决策制定的实体。他们可以访问一套工具,并可以根据用户输入决定调用哪个工具。Tookits 是一组工具,当它们一起使用时,可以完成特定的任务。代理执行器负责使用适当的工具运行代理。
通过理解和利用这些核心概念,您可以利用 LangChain 的强大功能来构建适应性强、高效且能够处理复杂用例的高级语言模型应用程序。
What is a LangChain Agent?
LangChain Agent 是框架中驱动决策制定的实体。它可以访问一组工具,并可以根据用户的输入决定调用哪个工具。代理帮助构建复杂的应用程序,这些应用程序需要自适应和特定于上下文的响应。当存在取决于用户输入和其他因素的未知交互链时,它们特别有用。
如何使用 LangChain?
要使用 LangChain,开发人员首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
LangChain 为特定用例提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互、提取、评估和汇总。
What’s a LangChain model?
LangChain model 是一种抽象,表示框架中使用的不同类型的模型。LangChain 中的模型主要分为三类:
LLM(大型语言模型):这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
聊天模型( Chat Model):聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
开发人员可以为他们的用例选择合适的 LangChain 模型,并利用提供的组件来构建他们的应用程序。
LangChain 的主要特点
LangChain 旨在为六个主要领域的开发人员提供支持:
LLM 和提示:LangChain 使管理提示、优化它们以及为所有 LLM 创建通用界面变得容易。此外,它还包括一些用于处理 LLM 的便捷实用程序。
链(Chain):这些是对 LLM 或其他实用程序的调用序列。LangChain 为链提供标准接口,与各种工具集成,为流行应用提供端到端的链。
数据增强生成:LangChain 使链能够与外部数据源交互以收集生成步骤的数据。例如,它可以帮助总结长文本或使用特定数据源回答问题。
Agents:Agents 让 LLM 做出有关行动的决定,采取这些行动,检查结果,并继续前进直到工作完成。LangChain 提供了代理的标准接口,多种代理可供选择,以及端到端的代理示例。
内存:LangChain 有一个标准的内存接口,有助于维护链或代理调用之间的状态。它还提供了一系列内存实现和使用内存的链或代理的示例。
评估:很难用传统指标评估生成模型。这就是为什么 LangChain 提供提示和链来帮助开发者自己使用 LLM 评估他们的模型。
02
—
Langchain构建阅读助手
1、首先我们需要确定一个LLM,这次我们使用的ChatGLM-6B,ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。这个是我这台电脑能跑起来的极限了.
2、然后我们需要构建一个WebUI,理所当然的就是我们的老演员Gradio了,主要包含prompt输入部分以及文件上传部分。
03
—
基本步骤
1、输入文档,然后将文档分割
2、将分割后的文档转换成embedding
3、输入prompt,将prompt转换成embedding
4、将这两个embedding进行对比,找出文档中相似内容embedding
5、将找出的embedding和prompt构建成新的prompt输入给ChatGLM
主要代码实现如下:
import gradio as gr
from PyPDF2 import PdfReader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import ElasticVectorSearch, Pinecone, Weaviate, FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.document_loaders import UnstructuredFileIOLoader
import os
os.environ["OPENAI_API_KEY"] = "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"
from transformers import AutoTokenizer,AutoModel
tokenizer = AutoTokenizer.from_pretrained("H:\\text-generation-webui\\models\\THUDM_chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("H:\\text-generation-webui\\models\\THUDM_chatglm-6b", trust_remote_code=True).half().cuda()
chatglm = model.eval()
class llmwebui:
def file_upload(self,file):
# 在这里添加文件上传的代码
reader = PdfReader(file.name)
raw_text = ''
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text:
raw_text += text
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
#文本分割
texts = text_splitter.split_text(raw_text)
#构建embedding
embeddings = OpenAIEmbeddings()
#搜索相近的embedding
self.docsearch = FAISS.from_texts(texts, embeddings)
self.chain = load_qa_chain(OpenAI(), chain_type="stuff")
return "file upload ok"
def chatbot(self,text):
# 在这里添加聊天机器人的代码,使用输入的文本作为聊天机器人的输入,并返回答复文本
query = text
docs = self.docsearch.similarity_search(query)
prompt = ""
#构建prompt
for doc in docs:
prompt = prompt + "\n" + doc.page_content
# result = self.chain.run(input_documents=docs, question=query)
prompt = prompt+"\n根据已知信息回答问题:{}".format(query)
response,history = chatglm.chat(tokenizer,prompt,history=[])
return response
myllmwebui = llmwebui()
with gr.Blocks() as demo:
with gr.Column():
with gr.Column():
result = gr.Interface(fn=myllmwebui.file_upload,inputs="file",outputs="text")
with gr.Row():
r = gr.Interface(fn=myllmwebui.chatbot, inputs="text", outputs="text")
demo.launch()运行demo.py,出现如下截图,按照上面的步骤,我们先输入文档,这个文档是近期才发表的“Humans in 4D: Reconstructing and Tracking Humans with Transformers”,然后提问什么是“Humans in 4D”,得到如下回答,满意度80%吧,毕竟只有6B的模型
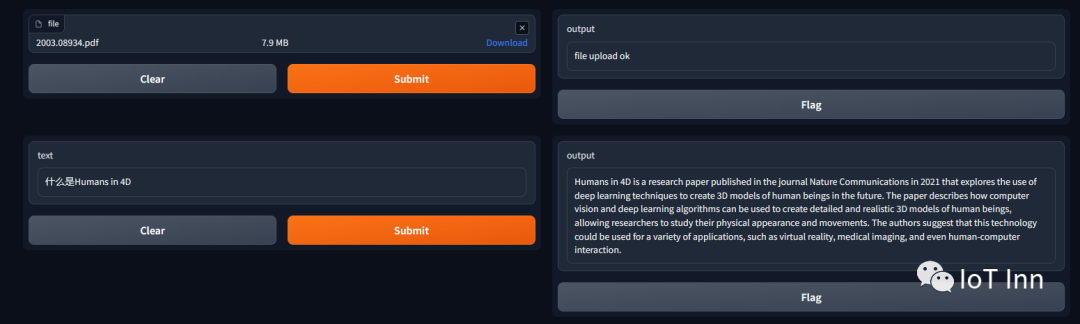
然后我们用同样的问题问chatgpt,得到如下回答,显然不是这篇文章中所描述的东西,从另一方面验证了整个流程的可行性。

03
—
将LLM替换成OpenAI
只需要将
chatglm.chat(tokenizer,prompt,history=[])替换成
self.chain.run(input_documents=docs, question=query)从这里可见langchain的优势所在,更换模型只需要简单的操作即可,同时可以提供丰富的api,很多模型的接口以及数据处理的接口都已经封装好了。
有兴趣的同学可以自己尝试下,虽然Langchain这个框架最近很火,但是没有看到什么特别亮眼的例子。后面再琢磨吧