本深度学习入门教程是在polyu HPCStudio 启发以及资源支持下进行的,在此也感谢polyu以及提供支持的老师。
大纲(what will you learn from this project)
1:What are neural networks?
2:Why use neural networks in machine learning?
3:What is keras?
4:Flow of building a neural network model.
5:Example to build a Neural Network model to predict diabetes cases.
(1)神经网络:
模仿人脑神经网络是人工智能中的一种方法,它指导计算机以受人脑启发的方式处理数据。
它是一种称为深度学习的机器学习过程,它使用类似于人脑的分层结构中的互连节点或神经元。
自然是发明之母——模仿自然的创新。
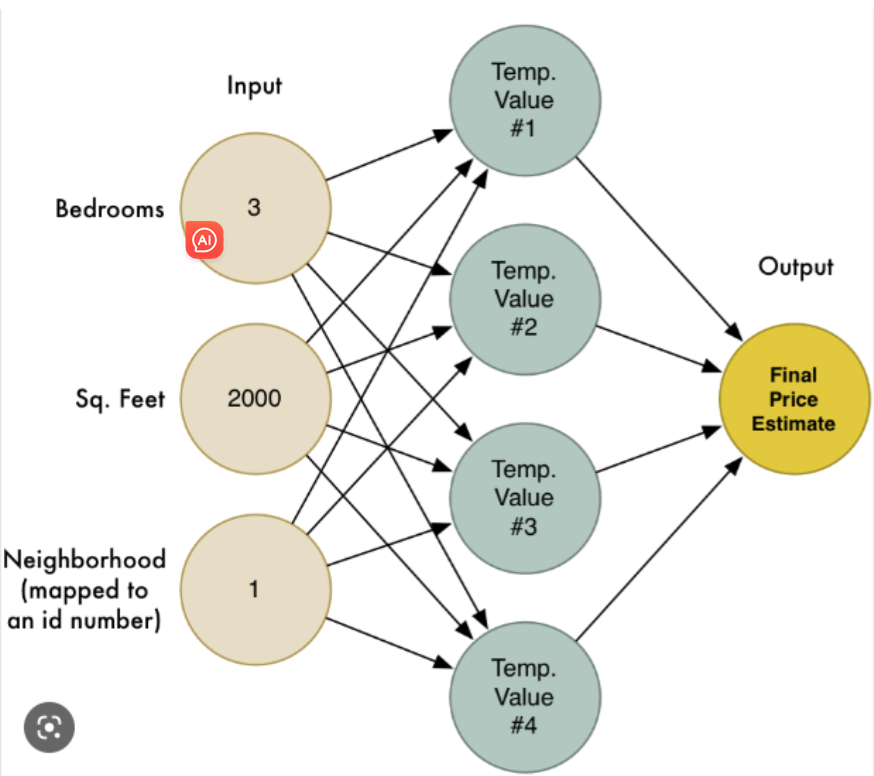
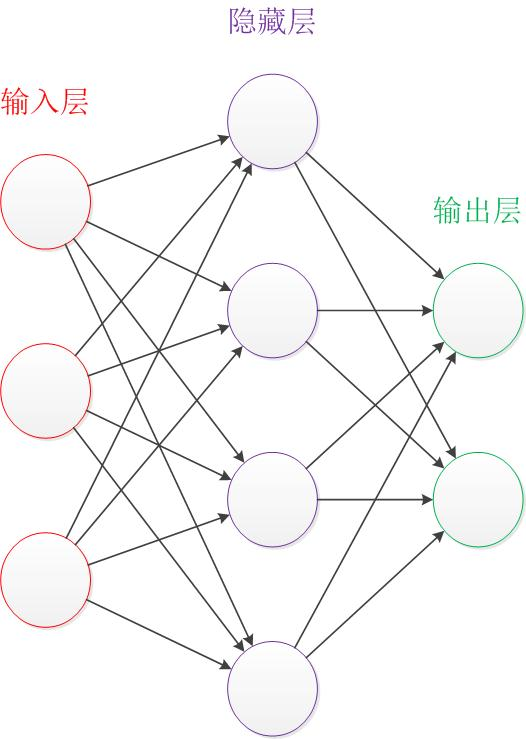
发展历程:


(2)为什么在机器学习中使用神经网络:
神经网络可以帮助计算机在有限的人类协助下做出明智的决策。
这是因为他们可以通过示例(数据)学习对非线性且复杂的输入和输出数据之间的关系进行建模。
可以自我训练/自我适应环境/数据的程序。
(3)Keras是什么
1Keras 是 Google 开发的用于实现神经网络的高级深度学习 API。
2它是用 Python 编写的,用于使神经网络的实现变得容易。 它还支持多个后端神经网络计算。
3更容易学习和使用。
4更简单的 API。
5后端:TensorFlow、Theano 或 CNTK其他一些用于机器学习的包。
例如。 PyTorch、TensorFlow、Theano。
(4)如何完成一个“用神经网络预测糖尿病病例”项目
步骤
- Collecting Data
- Cleaning Data and Feature Engineering
- Building Model
- Evaluating Model
- Deploying Model
- Go back to step 1 to reiterate if more data or features was found
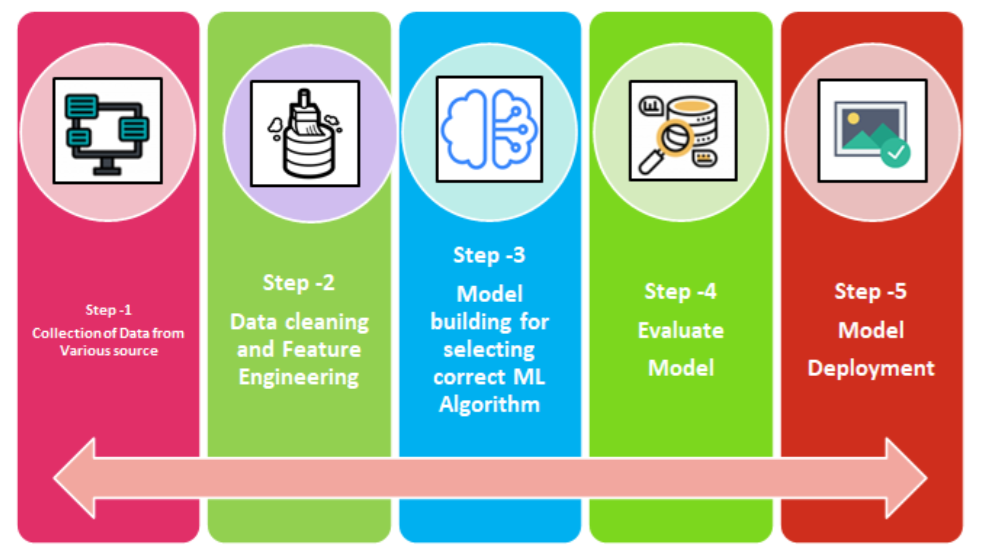
(5)数据集介绍:
The Pima Indians onset of diabetes dataset.
这是一个来自UCI机器学习库的标准机器学习数据集。它描述了皮马印第安人的五年内病历数据以及他们是否患有糖尿病。
- Number of times pregnant 怀孕次数
- Plasma glucose concentration at 2 hours in an oral glucose tolerance test 口服葡萄糖耐量试验2小时血浆葡萄糖浓度
- Diastolic blood pressure (mm Hg) 舒张压(毫米汞柱)
- Triceps skin fold thickness (mm) 肱三头肌皮褶厚度(mm)
- 2-hour serum insulin (mu U/ml) 2小时血清胰岛素(mu U/ml)
- Body mass index (weight in kg/(height in m)^2) 体重指数(体重公斤/(身高米)^2)
- Diabetes pedigree function - indicates the function which scores likelihood of diabetes based on family history糖尿病谱系函数 - 表示根据家族史对糖尿病可能性进行评分的函数
- Age (years)糖尿病谱系函数 - 表示根据家族史对糖尿病可能性进行评分的函数
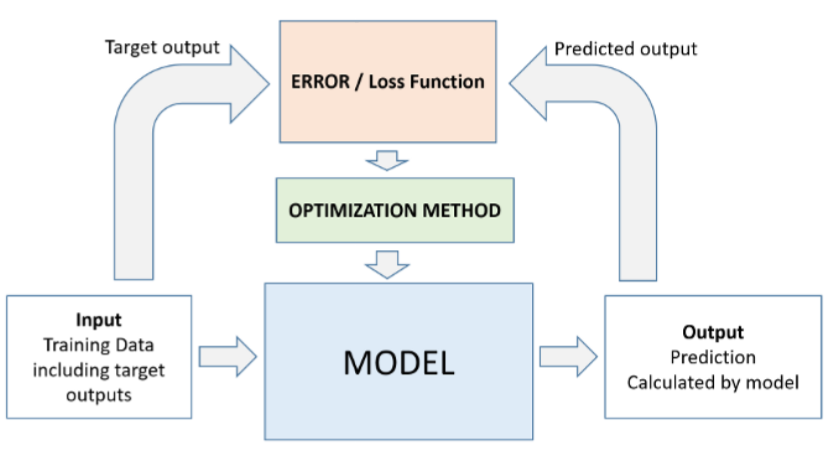
(6)Loss Function and Optimizer 损失函数和优化器介绍
损失是对错误预测的惩罚。 也就是说,损失是一个数字,表明模型对单个示例的预测有多糟糕。 如果模型的预测是完美的,则损失为零; 否则,损失更大。
优化器是修改神经网络属性(例如权重和学习率)的函数或算法。 因此,它有助于减少总体损失并提高准确性。
损失函数是目标。 优化器是到达目标的方式。
(7)训练和测试需要分开 train/test —split
为什么我们需要它? 打个比方,假设你教孩子乘法,让孩子在小乘法表上训练,即从 1 * 1 到 9 * 9 的所有数字。
接下来,您测试孩子是否能够执行相同的乘法。 结果是成功了。 这孩子几乎每次都答对了。 这里有什么问题呢? 你不知道孩子是否完全理解乘法,或者只是记住了表格!
所以你要做的就是测试孩子的乘法,比如 11*12,这些都在表之外。
这正是我们需要在看不见的数据上测试机器学习模型的原因。 否则,我们无法知道算法是否已经学会了可概括的模式或只是记住了训练数据。
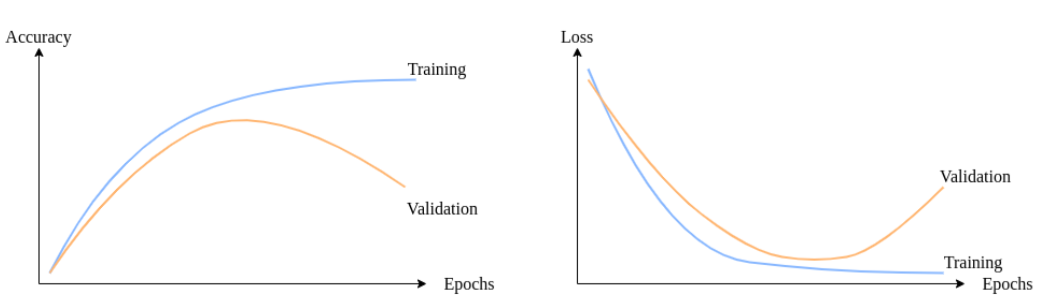
(8)模型收敛Model Convergence
收敛:优化算法的停止条件,其中稳定点位于并且算法的进一步迭代不太可能导致进一步的改进。我们可以根据经验测量和探索优化算法的收敛性,例如使用学习曲线。
(9)现在让我们开始编程
导入需要的包
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
加载读取数据
#read data from csv
diabetesData = pd.read_csv('N:/PolyuML/NeuralNetworks/data/diabetes/diabetes.csv')
diabetesData.head()

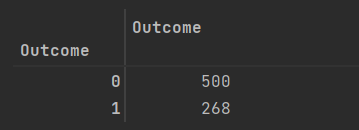
统计0,1(没患病与患病的人数)
#count outcome
diabetesData.groupby("Outcome")[["Outcome"]].count()
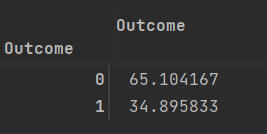
转化为百分百
diabetesData.groupby("Outcome")[["Outcome"]].count().apply(lambda my_df: my_df*100 / my_df.sum())
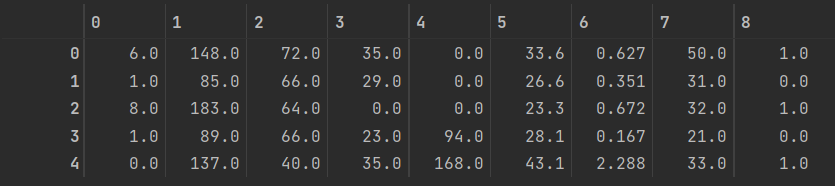
转化数据格式方便训练
#convert dataframe to numpy for training
dataset = diabetesData.to_numpy()
查看下转化后的数据
dataset[0:5]
定义一个神经网络模型
# define the keras model
model = Sequential()
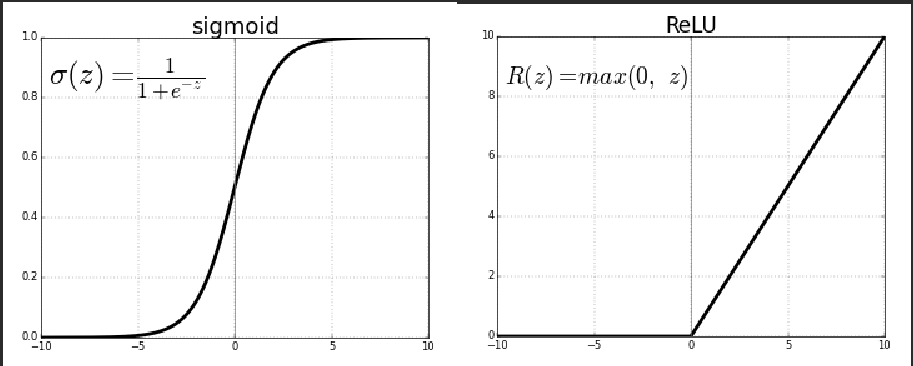
model.add(Dense(12, input_shape=(8,), activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
查看模型的结构
model.summary()
'''
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12) 108
dense_1 (Dense) (None, 8) 104
dense_2 (Dense) (None, 1) 9
=================================================================
我们有 3 层神经网络。 input_shape=(8,) - 模型有 8 个输入。 (对应8列输入数据,8维的数据)第一层-layer1,有12个节点。 第二层 - Layer2,有 8 个节点。 第 3 层 - 第 3 层,输出层,有 1 个节点。
'''
编译模型,这里定义了使用的损失函数以及优化器
# compile the keras model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
切分数据集,分为X输入的和Y输出的
#split the dataset to X (input) and y (output)
X = dataset[:,0:8]
y = dataset[:,8]
开始使用刚刚定义的模型在处理好的数据上运行
# fit the keras model on the dataset
model.fit(X, y, epochs=200, batch_size=12)
batch_size批量大小是模型更新之前处理的样本数量。 epochs是完整通过训练数据集的次数。 我们可以调整batch size和epochs来看看是否可以获得更好的结果。
训练完之后需要对模型进行评估
#evaluate the keras model
_, accuracy = model.evaluate(X, y)
print('Accuracy: %.2f' %(accuracy*100))
'''
24/24 [==============================] - 0s 696us/step - loss: 0.4587 - accuracy: 0.7747
Accuracy: 77.47
'''
使用训练好的模型去预测糖尿病病例的发生
predictions = (model.predict(X) > 0.5).astype(int)
# predict for some cases
for i in range(5):
print('%s => %d (expected %d)' % (X[i].tolist(), predictions[i], y[i]))
'''
[6.0, 148.0, 72.0, 35.0, 0.0, 33.6, 0.627, 50.0] => 1 (expected 1)
[1.0, 85.0, 66.0, 29.0, 0.0, 26.6, 0.351, 31.0] => 0 (expected 0)
[8.0, 183.0, 64.0, 0.0, 0.0, 23.3, 0.672, 32.0] => 1 (expected 1)
[1.0, 89.0, 66.0, 23.0, 94.0, 28.1, 0.167, 21.0] => 0 (expected 0)
[0.0, 137.0, 40.0, 35.0, 168.0, 43.1, 2.288, 33.0] => 1 (expected 1)
'''