今天我们来讲Python爬虫获取微博TOP10热搜关键词,如果对你有帮助的还请各位佬多多关注,多多点赞,多多收藏!!
步入正题
第一步,进入微博官网:点我进入
我们可以看到 热搜就在右下方

第 2 步,点击【f12】,或者【右击】检查,查看热搜的,网址来源
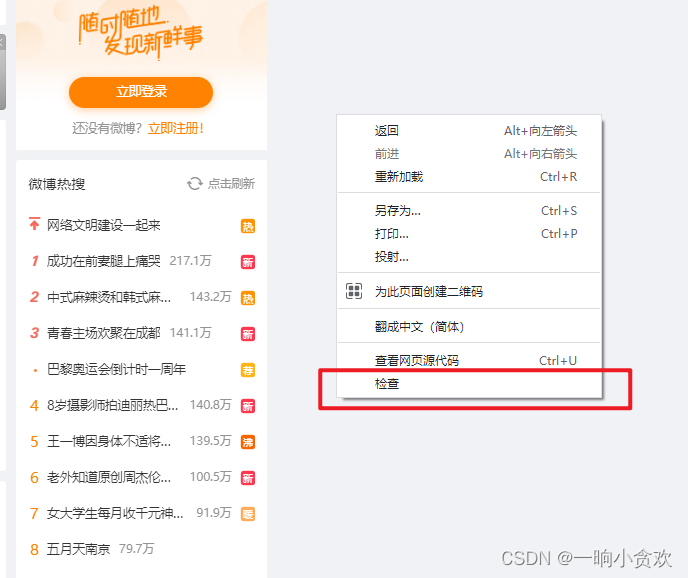
第 3 步
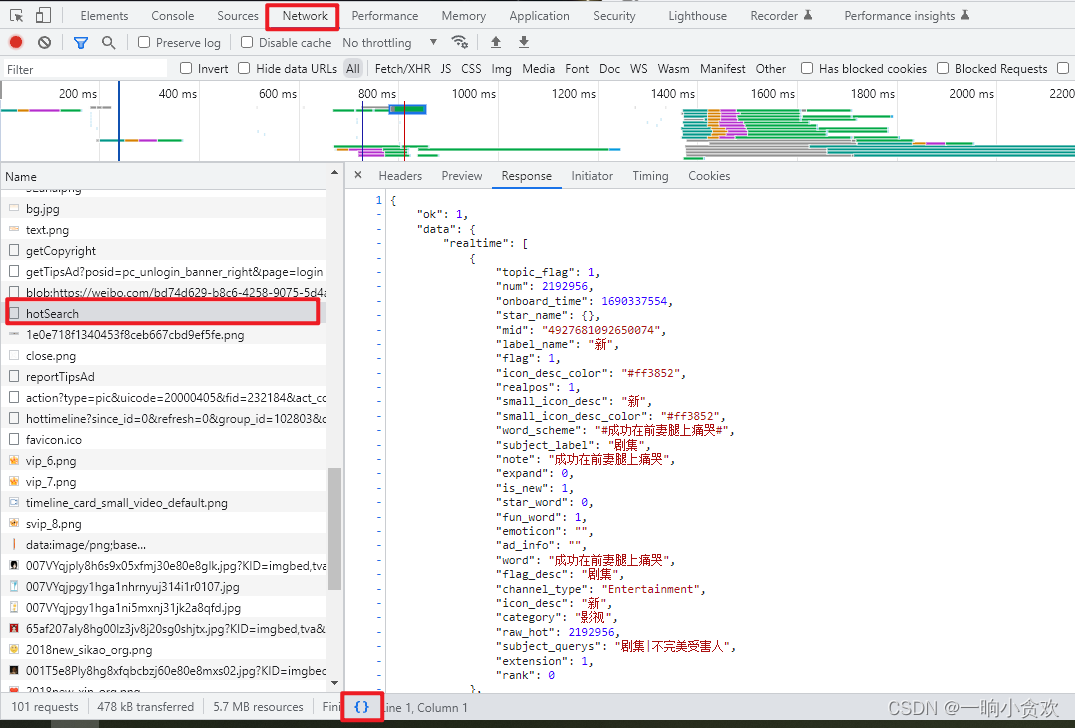
1、点击Network,刷新页面,所有的加载资源会在左方出现
2、我们发现有一个【hotSearch】这个就是热搜的链接
3、点击下方的【{}】这个小图标,格式化一下json信息
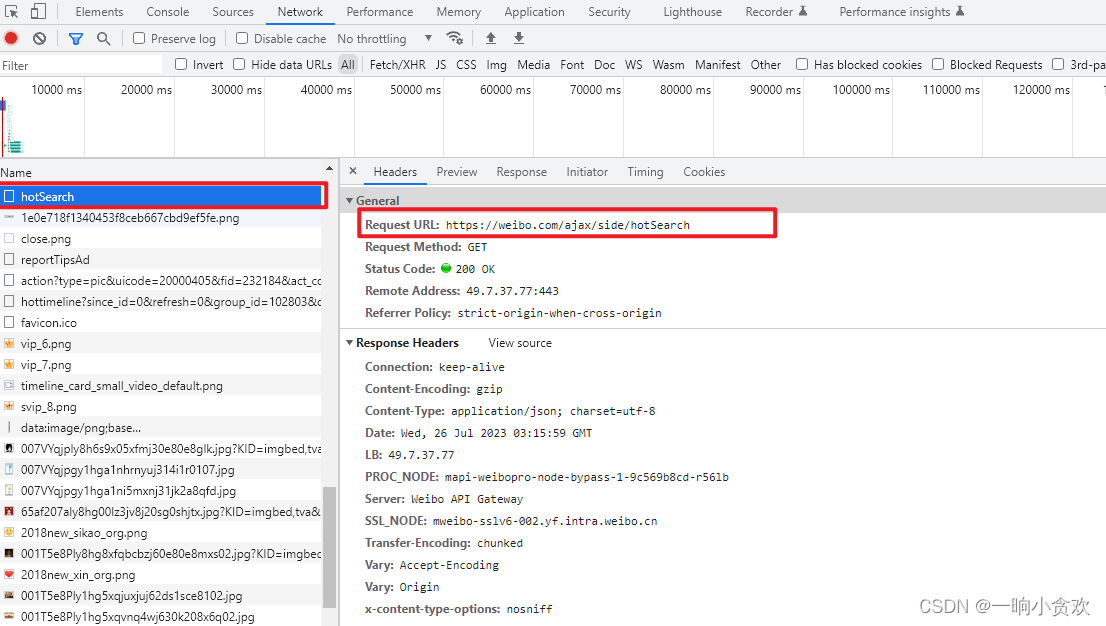
第 4 步 找到请求URL
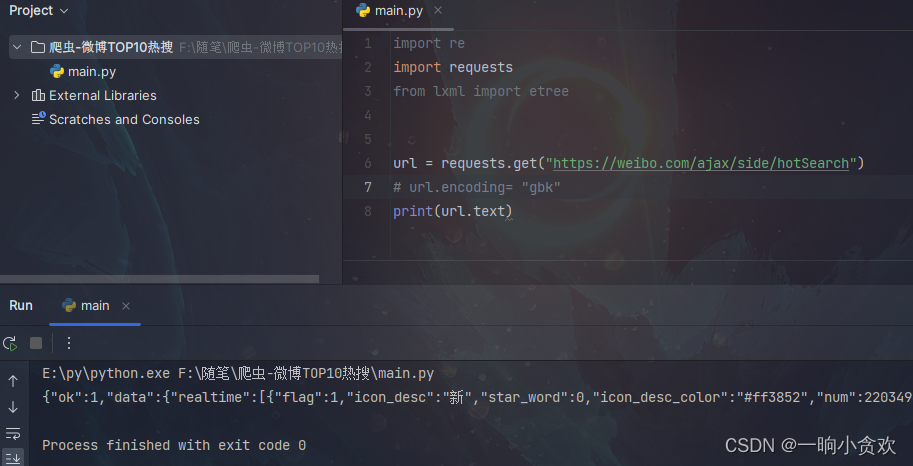
第 5 步 代码请求
如图所示请求成功
第 6 步整理数据
1、将返回数据(string)转为dict
2、经过分析发现热搜主要在一个列表里:json.loads(url.text)['data']['realtime']
3、获取
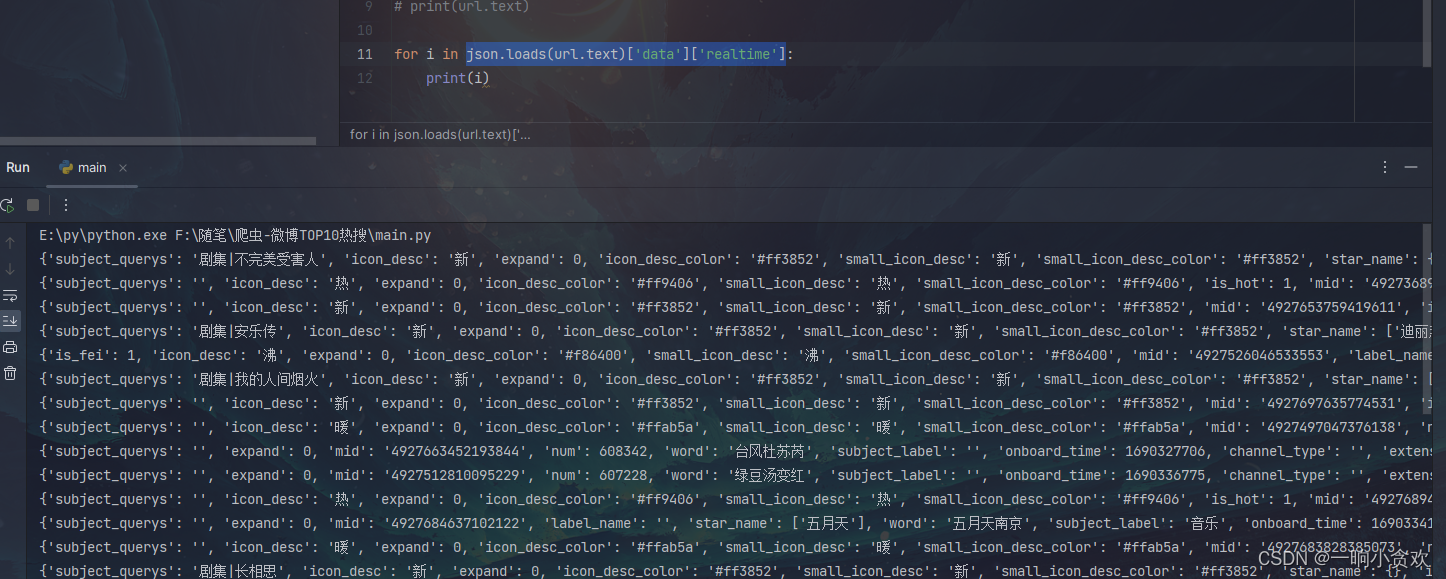
4、继续分析(大家可以继续分析,里面的分类还有很多,我这里就不分析了)
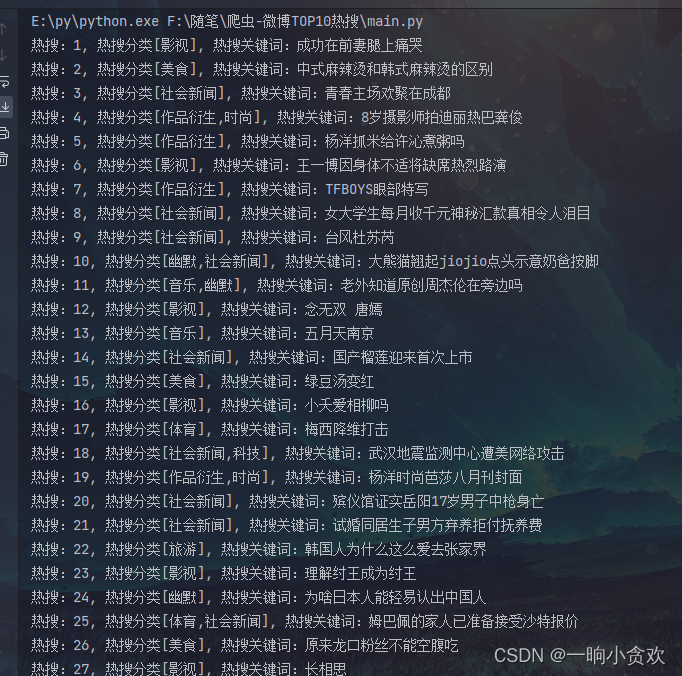
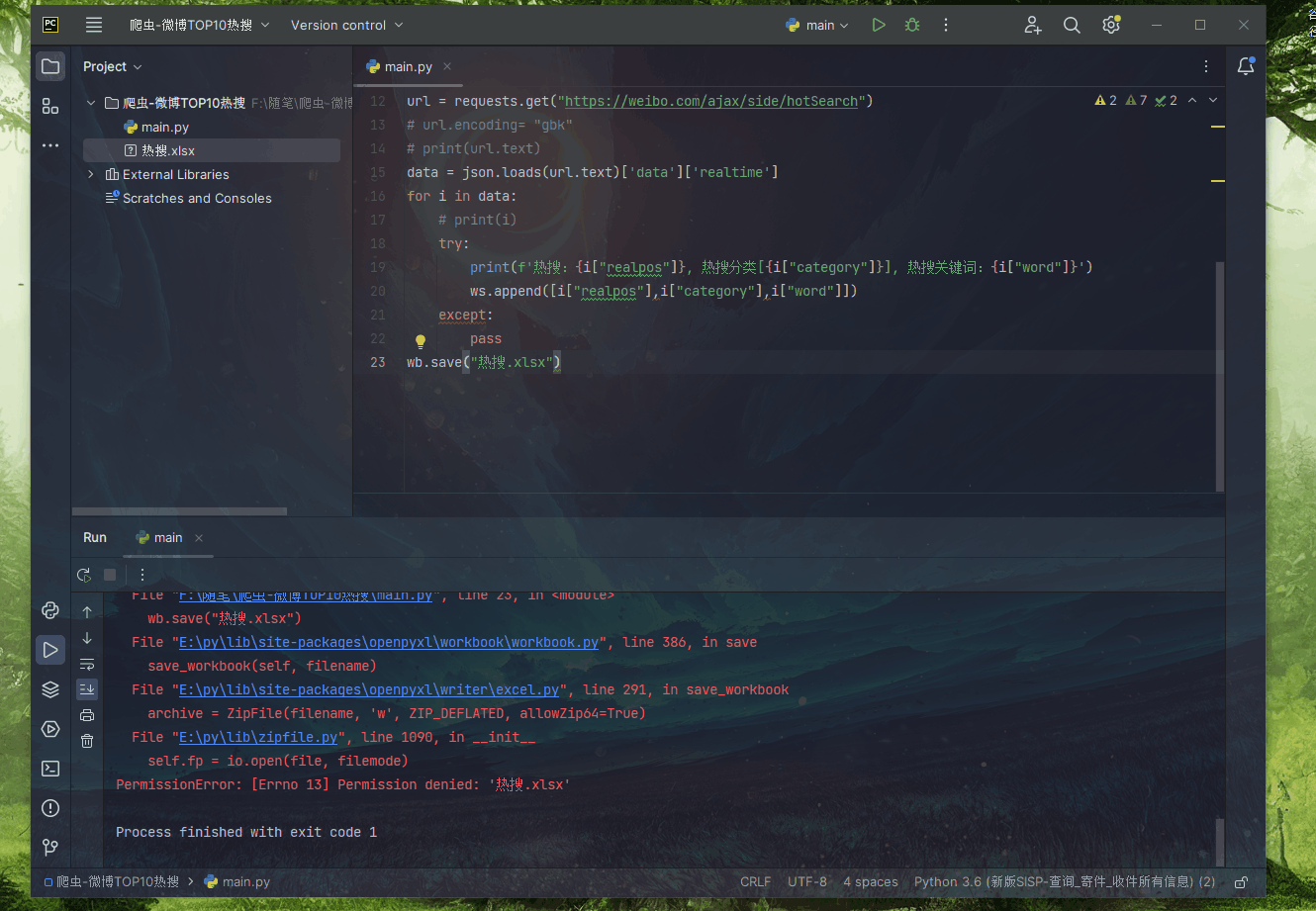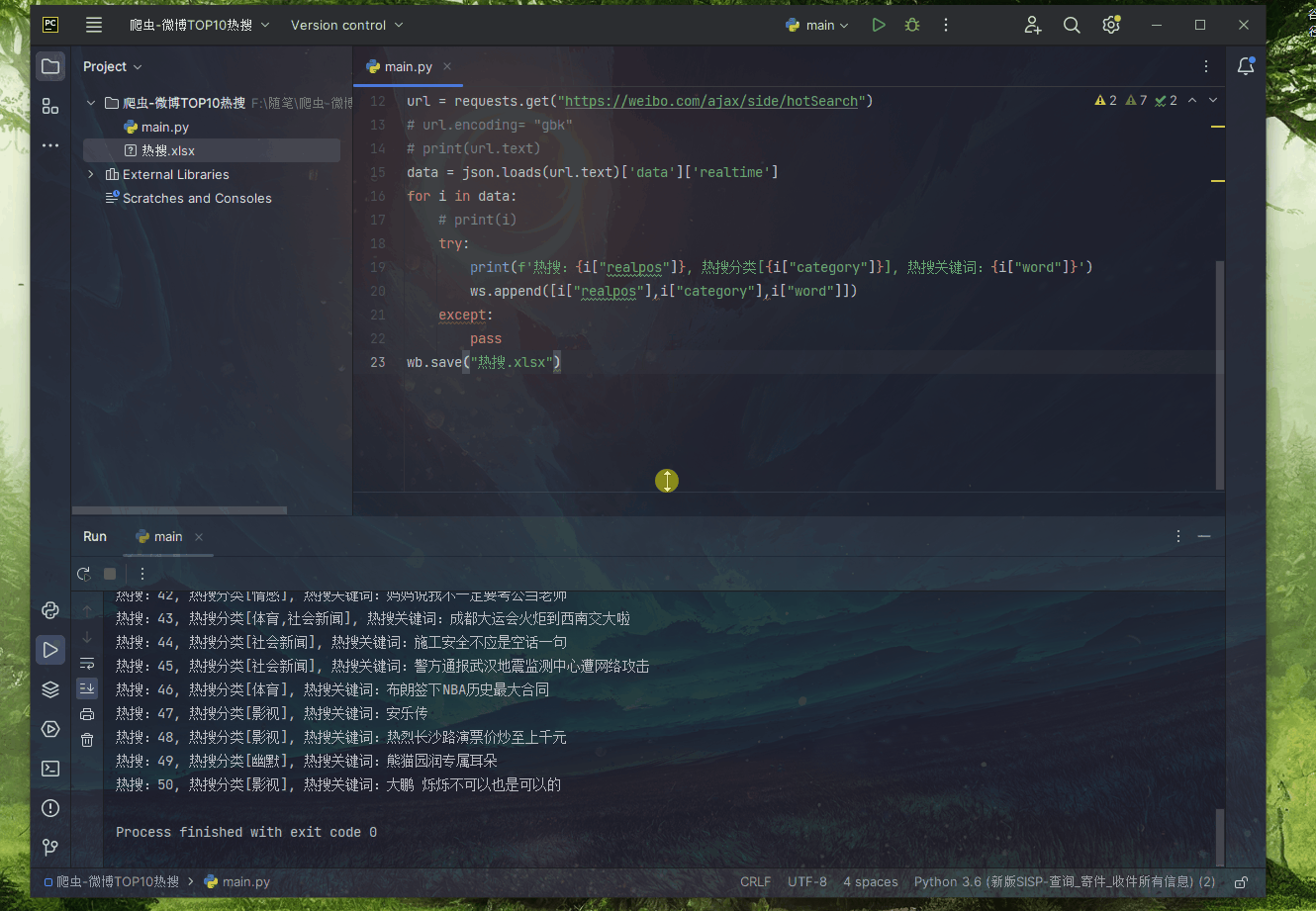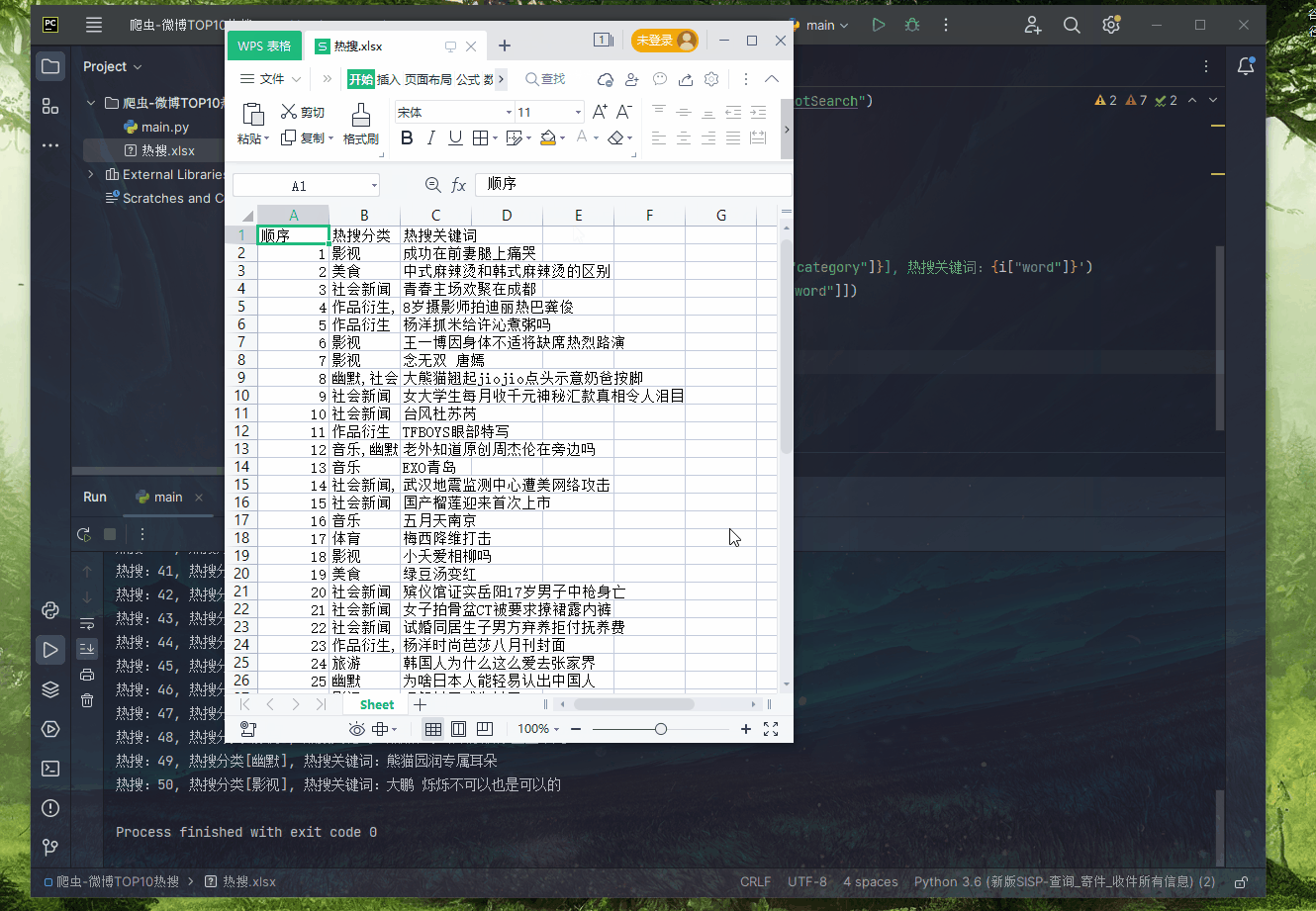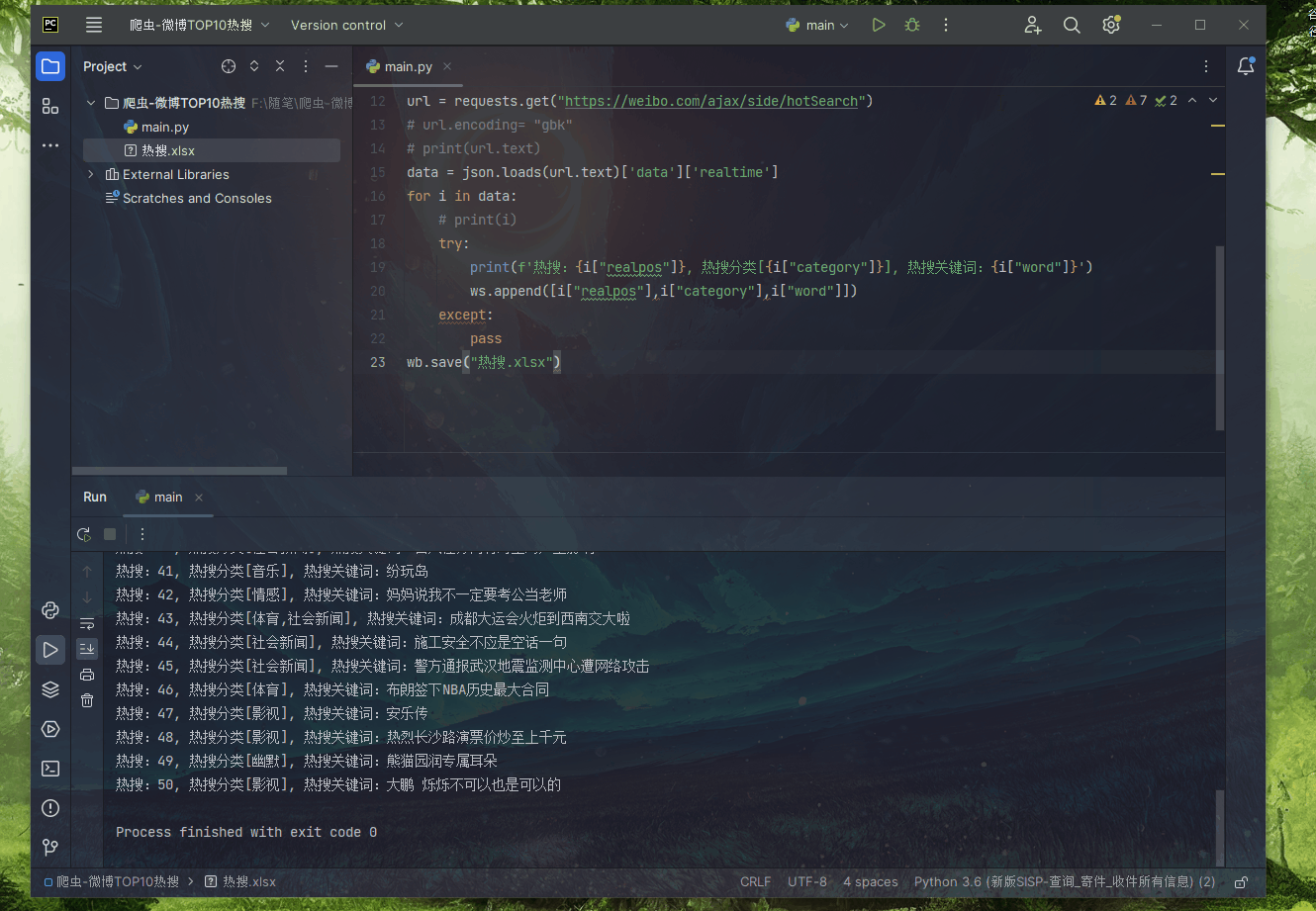
到这里已经全部获取了,接下来写入Excel

import json
import re
import openpyxl
import requests
from lxml import etree
wb = openpyxl.Workbook()
ws = wb.active
ws.append(['顺序','热搜分类','热搜关键词'])
url = requests.get("https://weibo.com/ajax/side/hotSearch")
data = json.loads(url.text)['data']['realtime']
for i in data:
try:
print(f'热搜:{
i["realpos"]}, 热搜分类[{
i["category"]}], 热搜关键词:{
i["word"]}')
ws.append([i["realpos"],i["category"],i["word"]])
except:
pass
wb.save("热搜.xlsx")
希望对大家有帮助
都看到这了,关注+点赞+收藏=不迷路!!