转眼将就来到了我们爬虫基础课的第 6 节课,今天我们来获取微某博信息来进行阅读学习!
PS前面几节课的内容在专栏这里,欢迎大家考古:点我
首先第一步我们先登录一下微x博:点我
点击左上角的搜索框,找到你想获取的用户:
大家可以看到这里有两种搜索方式:
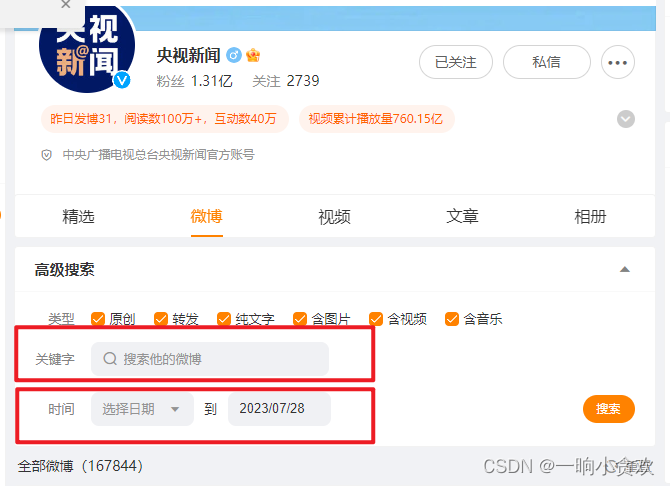
1、按照关键字搜索
2、按照时间搜索
今天我们的代码都会讲!!
首先我们讲按照【时间】去搜索,选好时间,按【f12】或者右击检查,然后点击搜索
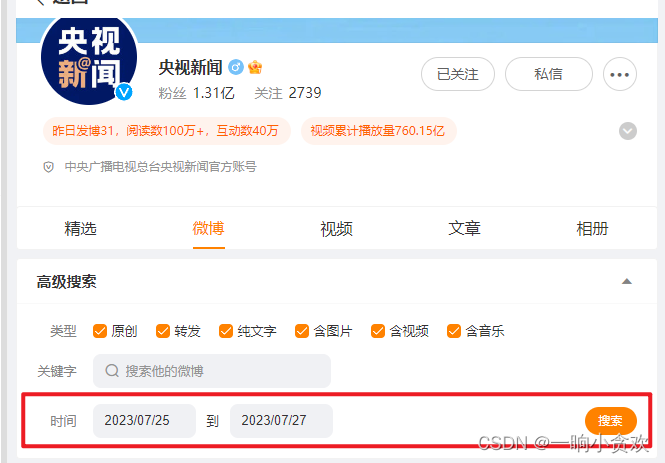
这时候我们发现这是一个【get请求】参数在url中也会显示,我们看一下参数
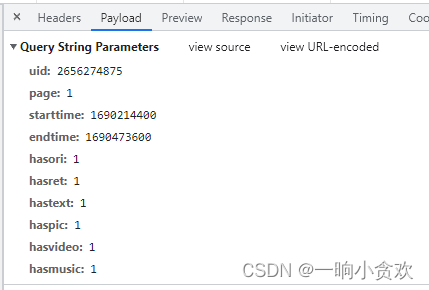
【uid】这是用户id
‘starttime’: ‘1690214400’, 时间戳
‘endtime’: ‘1690473600’, 时间戳


代码 1 —获取json(最后附上完整版代码)
注意,请填写自己cookie
import json
import time
import requests
cookie = {
'cookie': '请填写自己的cookie'}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
搞定:

代码 2 【展开内容:】如果不点【展开】获取的将是部分内容,不是完整的

如法炮制,点击展开,获取当前这个微博动态的 id,然后再次请求就可以获取完整版的内容!!

代码 2 数据清洗
date = con_json[‘data’][‘list’][i][‘created_at’] # 日期
con = con_json[‘data’][‘list’][i][‘text_raw’] # 内容
reposts_count = con_json[‘data’][‘list’][i][‘reposts_count’] # 转发量
comments_count = con_json[‘data’][‘list’][i][‘comments_count’] # 评论
attitudes_count = con_json[‘data’][‘list’][i][‘attitudes_count’] # 点赞
mblogid = con_json[‘data’][‘list’][i][‘mblogid’] # 微博ID
这里我不知道有这段时间发了多少个,就写了999页
import json
import time
import requests
cookie = {
'cookie': '请填写自己的cookie'}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
for i1 in range(1, 999):
params2 = {
'uid': '2656274875',
'page': f'{
i1}',
'feature': '0',
'starttime': '1690214400',
'endtime': '1690473600',
'hasori' :1 ,
'hasret' :1 ,
'hastext' :1 ,
'haspic' :1 ,
<