一、概述
Swin Transformer是一个用了移动窗口的层级式Vision Transformer。
在图像领域,Transformer需要解决如下两个问题:
①尺度问题:同一语义的物体在图像中有不一样的尺度。(大小不同)
②Resolution过大:若以像素点作为单位,则会出现序列过长的情况。
由于使用了移动窗口,Swin Transformer的自注意力仅在窗口中计算,降低了计算量;同时移动窗口的应用还带来了图像之间的层级关系,使得其能更好的应用在图像领域。
二、重要操作
1.移动窗口
对于视觉任务而言,多尺度特征极为重要。例如对于目标检测而言,常用的方法是提取不同尺度的特征后进行特征融合(FPN),这样可以很好的把握物体不同尺寸的特征。而对于语义分割而言,也需要对多尺寸特征进行处理。(skip connection/空洞卷积等)
patch:最小的计算单元
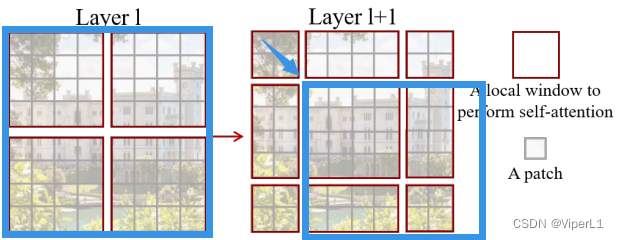
window:原文中默认有 7x7(合计49个)个patch
Shift操作:将原来的Window往右下移动窗口大小/2并向下取整(2个patch),再沿着原window的延长线对图进行分割。可以使得一个窗口中的自注意力机制注意到其他patch中的信息。
Masked掩码:
窗口移动后,由于窗口大小不一致无法直接merging,通常的操作是将小patch进行padding补至与中间大patch一致。但是这样会提升计算复杂度。
而Masked是在窗口移动后再进行一次循环移位(cyclic shift);
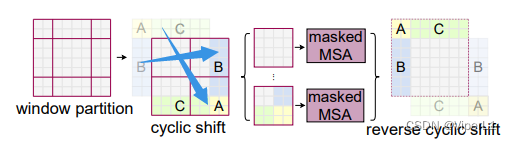
组合后的窗口由于发生了patch移动导致除左上角的patch保持原有位置信息之外全部混入和其他位置的patch;针对这种情况。在对其进行自注意力运算,然后对运算后的结果中不是原始组合的部分按照特定的遮罩进行求和(用来屏蔽错误的组合),如下图所示。
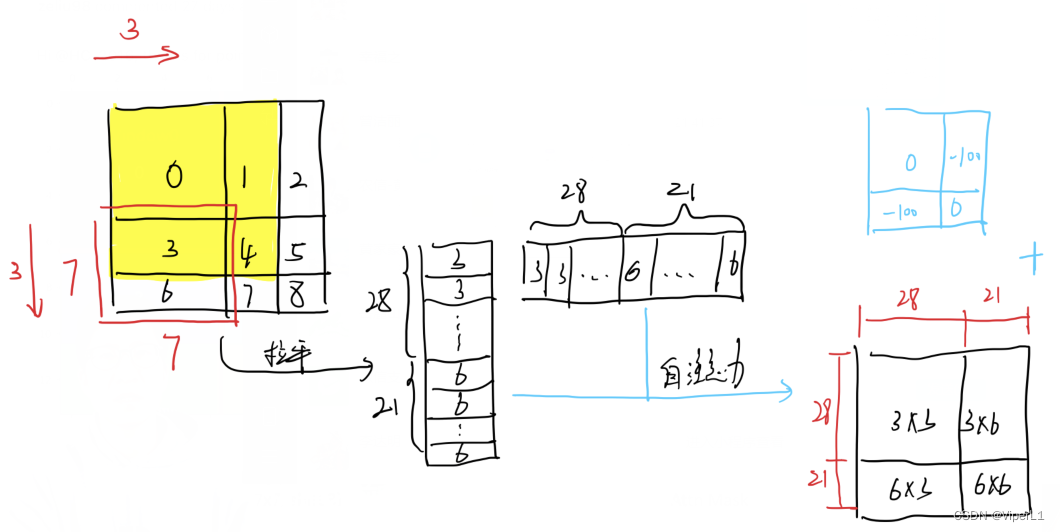
遮罩模板如下:

2.patch merging
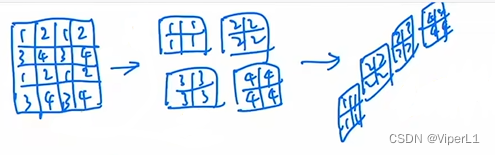
用于生成多尺寸特征,类似于CNN中的Pooling(池化)。具体做法是将相邻的小patch合并成一个大patch。
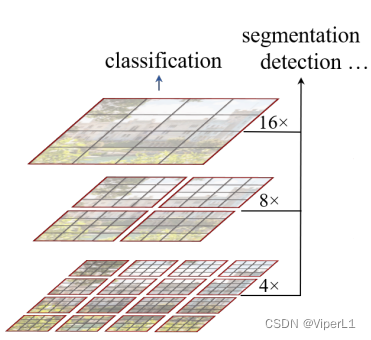
三.模型架构

①Patch Partition:在图上划分patch(原文为4x4,对于标准的224*224*3的图片而言,经过此操作后尺寸变为56*56*48)
②Linear Embeding:将向量的维度转换为预先设定好的值;原文设置了一个超参数c=96(操作后尺寸变为96*96*96,前面的96*96将被拉直成3136成为序列长度,最后一个96编程每个token的维度;由于96*96拉直后一共3136对于Transformer太长了,所以采用基于窗口的自注意力,默认每个窗口仅有7x7=49个patch)
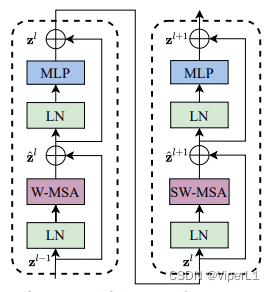
③Swin Transformer Block:每组做两次多头自注意力:①基于窗口的多头自注意力;②基于移动窗口的多头自注意力。这样做可以实现窗口与窗口之间的通信。

④Patch Merging:Transformer若不进行限制的话,输入和输出尺度并不会发生改变。如果想像CNN一样得到多尺度特征的话就必须使用Patch Merging。具体做法是将相邻的小patch合并成一个大patch(以原文为了例下采样数为2倍,采用跳步式合并--每隔一个点采集一个);
但是经过Merging后,通道数会变为4c,为了和CNN每卷积一次通道数仅x2,在进行Merging后再进行一个1x1卷积将通道数调整为2c。(空间大小/2,通道数x2)