目录标题
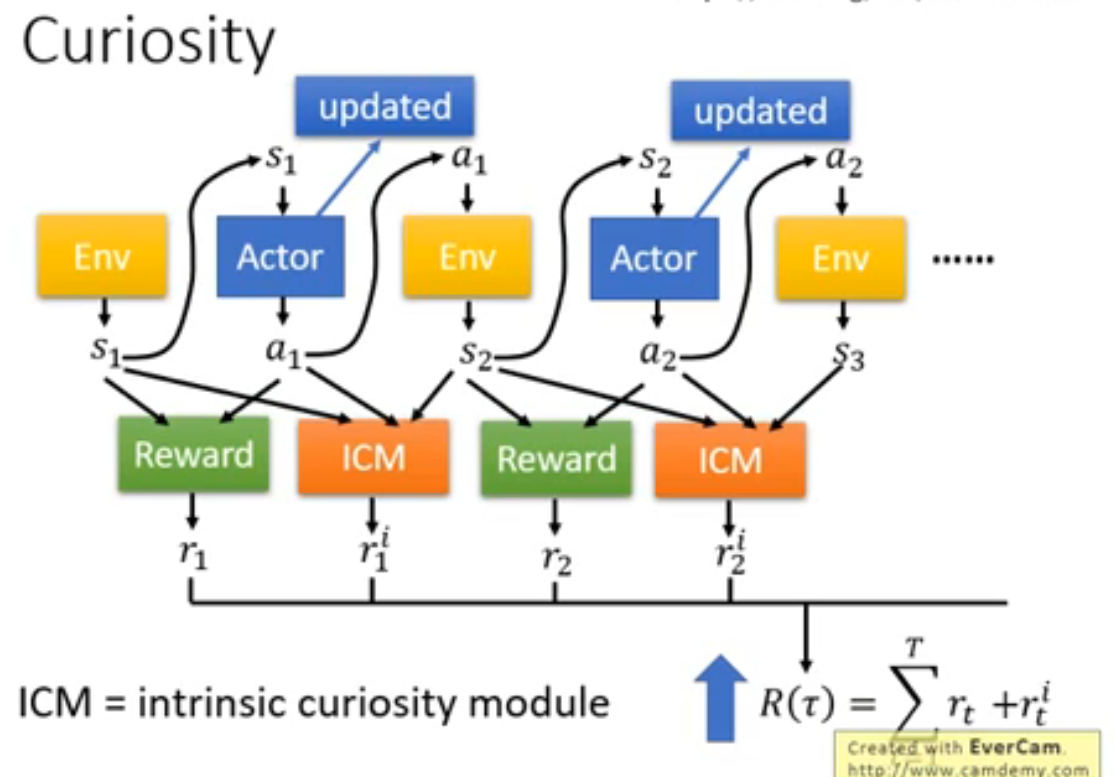
一、探索与利用-基于内在激励的方法ICM
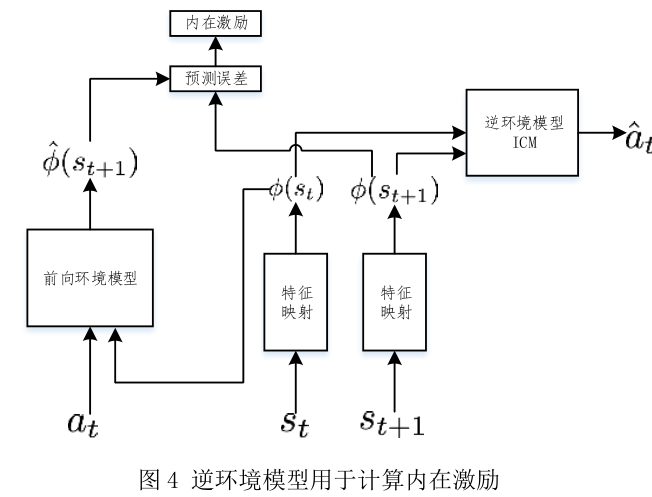
Pathak 等 [73] 使用逆环境模型(ICM)来获得状态的特征表示,去除环境模型中与动作无关的部分,提高了内在激励的效果。具体地,在构建环境模型的同时构建 ICM,其输入为状态 s t s_t st和 s t + 1 s_{t+1} st+1 ,输出为 a t a_t at。ICM 通过学习可以在特征空间中去除与预测动作无关的状态特征,在特征空间中构建环境模型可以去除环境噪声。
1.domain knowledge
- domain knowledge 是指对某个特定领域、专业或活动的知识,与一般知识相对1。也就是说,domain knowledge 是专家或专业人士在某个领域的知识。例如,在软件工程中,domain knowledge 可以指对目标系统所处环境的特定知识2。
- 拥有 domain knowledge 可以帮助你更好地理解和沟通某个行业的运作方式和需求,也可以提高你的工作效率和质量。
- domain knowledge 可以通过研究、教育、培训、网络和提问等方式来提高3。
2.curriculum learning
- curriculum learning 是一种训练策略,它模仿人类的学习过程,让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识1。
- curriculum learning 可以提高模型的性能和收敛速度,而不需要额外的计算成本。
- curriculum learning 的核心问题是如何对样本或任务进行难度排序,以及如何根据难度调整训练的进度2。
- curriculum learning 可以分为预定义的方法和自动的方法,前者需要人为地设计难度测量器和训练调度器,后者可以利用数据驱动的方式自动设计3。
- curriculum learning 在各个领域和任务中都有广泛的应用和研究价值。
二、多目标学习
1. 学习框架
针对奖励的稀疏性,Andrychowicz 等 [80] 提出了一种多目标学习 [7] 算法,智能体可以从已经到达的位置来获得奖励。该算法在训练中使用虚拟目标替代原始目标,使智能体即使在训练初期也能很快获得奖励,极大地加速了学习过程。

2.目标经验回放法(Hindsight Experience Replay, HER)
使用已经到达的目标来替代原始目标,使智能体能够更快地获得奖励。HER 算法适用于离策略的强化学习算法。
三、辅助任务
在稀疏奖励情况下,当原始任务难以完成时,往往可以通过设置辅助任务的方法加速学习和训练。该方法主要包括两种类型。
- 第一类方法是“课程式”强化学习。当完成原始任务较为困难时,奖励的获取是困难的。此时智能体可以先从简单的、相关的任务开始学习,此后不断增加任务的难度,逐步学习更加复杂的任务。
- 第二类方法直接在原任务的基础上添加并行的辅助任务,原任务和辅助任务共同学习。使用此类辅助任务的优势在于:
- 1)当原任务奖励稀疏时,智能体可以从辅助任务中获得奖励,从而缓解了稀疏奖励带来的问题;
- 2)通过训练辅助任务可以使智能体掌握某些技能,这些技能对完成原任务会有帮助;
- 3)辅助任务与原任务在网络层面会共享一部分表示,在训练辅助任务时会促进原任务的网络迭代。
四、奖励的设置
(1)正负奖励
根据这些原则,我们可以根据不同的任务来设置不同的奖励函数。例如:
- 对于一个走迷宫的任务,我们可以设置到达终点时给予一个正奖励;撞到墙壁时给予一个负奖励;每走一步时给予一个很小的负奖励,以鼓励代理尽快找到出口12。
- 对于一个下棋的任务,我们可以设置赢棋时给予一个正奖励;输棋时给予一个负奖励;平局时给予一个零奖励;每走一步时给予一个潜在奖励,根据棋盘局面评估当前策略的优劣12 。
- 对于一个自动驾驶的任务,我们可以设置安全到达目的地时给予一个正奖励;发生事故或违反交通规则时给予一个负奖励;每行驶一段距离时给予一个中间奖励,根据车速、路况、油耗等因素评估当前行驶效率12。
- 正奖励通常表示智能体做了一些有利于达成目标的行为,负奖励通常表示智能体做了一些不利于达成目标的行为。根据不同的问题和环境,奖励可以有不同的形式和大小。
有一些方法可以帮助设计合理的奖励函数,比如:
-
奖励塑形(reward shaping):这是一种在原始奖励函数的基础上添加一些额外的奖励信号,以加速学习过程或改善学习结果的方法12。比如,在一个迷宫寻路问题中,除了给出到达终点的正奖励和每走一步的负奖励外,还可以给出接近终点的正奖励或远离终点的负奖励,以引导智能体更快地找到正确的路径。但是,奖励塑形需要遵循一些原则,以避免改变最优策略或引入不良的副作用12。
-
分层强化学习(hierarchical reinforcement learning):这是一种将复杂的问题分解为多个子问题,并分别设计子问题的奖励函数和策略函数的方法34。比如,在一个游戏中,要让智能体从一个地方到达另一个地方,可以将任务拆分为四个阶段,每个阶段都有一个子目标和子奖励3。这样可以减少稀疏奖励(sparse reward)的问题,也可以提高学习效率和可解释性4。
-
奖励设置过于密集且为正,可能会导致agent一直持续获得该奖励,陷入局部情况,不能完成通关。
以下是ChatGPT的答案:
处理约束条件在设计奖励函数时是一个重要的考虑因素。约束条件可以是关于状态或动作的限制,强制智能体在任务执行过程中满足某些条件。
一种常见的处理方法是在奖励函数中引入罚函数(penalty function),以惩罚智能体违反约束条件的行为。具体而言,当智能体违反约束条件时,可以为奖励函数增加一个负的罚分项,使得智能体在优化过程中更倾向于遵守约束。
以下是一种基本的奖励函数设计方法,用于处理约束条件:
-
正向奖励(Positive Rewards):为智能体在任务中达到良好状态或完成目标时提供正的奖励。这些奖励可以鼓励智能体遵循约束条件以及取得良好的任务执行结果。
-
罚函数(Penalty Functions):为智能体违反约束条件时提供负的奖励。这些罚分项可以根据约束的严重程度和违反程度来设定。违反约束条件时,罚函数的值可以根据违反程度的不同而线性或非线性地增加。
-
约束惩罚权重(Constraint Penalty Weighting):可以调整约束罚函数在奖励函数中的权重。通过调整权重,可以平衡正向奖励和违反约束的惩罚,确保智能体在优化过程中兼顾任务目标和约束条件。
需要根据具体的约束条件和任务情况来设计奖励函数和罚函数的形式、权重和系数。同时,需要在训练过程中不断优化奖励函数,以使智能体能够学习到合适的行为策略,同时满足约束条件。
另外,约束条件的处理也可以结合其他技术,如优化算法中的投影法(projection),约束优化算法等,以更直接地确保智能体在执行过程中满足约束。这些方法可以根据具体问题的要求进行选择和调整。
(2)稀疏奖励
- 稀疏奖励的问题是,代理可能在很长的时期内蹒跚而行,尝试不同的动作,经历许多不同的状态,沿途却没有得到任何奖励,因此,在该过程中没有学到任何东西。
- 可通过奖励重塑改进稀疏奖励,即提供较小的中间奖励,引导代理沿正确的道路前进。
- 不过,奖励重塑也有它自己的问题。如果我们给优化算法提供一条捷径,算法就会采取这条捷径。而捷径隐藏在奖励函数内,当我们开始重塑奖励时,更有可能出现。奖励函数设计得不好可能造成代理收敛到一个不理想的解,即使该解会为代理获得最多的奖励。看上去我们的中间奖励可能引导机器人成功地走向10米的目标,但最优解可能不是向那第一个奖励走去。反而可能朝它笨拙地跌倒,收取该奖励,从而强化该行为。除此以外,机器人可能趋向于缓慢地沿地面蠕动,以收取其余的奖励。对代理来说,这是合情合理的高奖励的解,但是对设计者来说,这显然不是首选结果。
(3)强化学习中获得负奖励时,应不应该结束回合呢
强化学习中获得负奖励时,是否应该结束回合,取决于你的任务目标和奖励函数的设计。一般来说,有以下几种情况:
- 如果负奖励代表了任务失败或终止的条件,例如机器人摔倒或汽车撞墙,那么结束回合是合理的,因为代理无法从当前状态继续执行动作1。
- 如果负奖励代表了任务中的惩罚或代价,例如机器人消耗能量或汽车偏离路线,那么结束回合可能不是一个好主意,因为代理可能还有机会从当前状态恢复或改进1。
- 如果负奖励是由于人为截断Episode的长度而产生的伪终态,例如在Mountain Car环境中,如果代理在200步内不能到达山顶,那么结束回合可能会引入不必要的偏差或不稳定2。这种情况下,可以采用以下方法来避免或减轻伪终态的影响2:
- 把当前步数或时间作为状态观测量之一,让代理知道自己离终止还有多远。
- 对最后一个样本进行特殊处理,避免使用错误的Q值估计或目标值。
- 对伪终态给予一个非常低的奖励,让代理尽量避免进入这种状态。
- 使用轮回方式来处理终态,即在目标值中加上初始状态或某种特殊状态的价值函数。
(4)奖励的设置注意项
奖励函数应该与目标任务相关。奖励函数应该鼓励智能体在任务中达到目标,例如在游戏中获得高分,或在机器人控制中达到目标位置等。
-
奖励函数应该可测量。奖励函数应该能够根据智能体的行为和环境的状态计算出相应的奖励值。这使得智能体能够学习如何最大化奖励。
-
奖励函数应该简单。奖励函数的设计应该越简单越好,这可以减少算法的复杂性并减少可能出现的问题。例如,避免设计过于复杂的计算或嵌套条件。
-
奖励函数应该具有鲁棒性。奖励函数应该对环境中可能出现的噪声或异常情况具有一定的鲁棒性,以确保算法的训练和性能不会受到干扰。
-
奖励函数应该避免奖励稀疏性。奖励函数应该尽可能避免只在任务完成时提供奖励,而应该在任务执行过程中提供适当的奖励,以鼓励智能体的探索和学习。
-
奖励函数应该避免副作用。奖励函数的设计应该避免不必要的副作用,例如鼓励智能体采取可能有害的行为,或者不鼓励智能体采取可能有益的行为。
综上所述,奖励函数的设计应该根据具体的任务和环境进行,需要在设计时考虑各种可能的情况,并确保奖励函数的设计合理、简单、鲁棒性强、避免稀疏性和副作用。
(5)奖励的正负和大小
-
正负选择
奖励可以是正的、负的或零。正奖励表示智能体做出的行为对任务有益,负奖励表示行为有害,而零奖励表示行为没有影响。通常来说,正奖励应该比负奖励多,因为任务的目标通常是为了获得好的结果。但是,在某些情况下,负奖励可以用来惩罚某些不良行为或鼓励智能体避免特定的行为。 -
大小选择
奖励的大小应该根据任务和环境进行选择。过小的奖励可能无法提供足够的鼓励,从而导致智能体无法学会任务,过大的奖励可能会导致智能体出现过度拟合的现象,或者出现在任务中没有意义的行为。通常来说,奖励的大小应该尽可能接近任务的实际目标。例如,在一个控制机器人的任务中,如果目标是机器人移动到特定的位置,则可以将奖励大小设置为机器人距离目标位置的负值,以便智能体能够学会如何尽快到达目标位置。
除此之外,还需要考虑奖励的稀疏性和鲁棒性。稀疏的奖励可能会导致智能体无法学习到正确的行为,而鲁棒的奖励可以帮助智能体克服环境中的噪声和异常情况,提高训练和性能的鲁棒性。
总的来说,奖励的正负和大小需要根据具体任务和环境进行选择,并需要考虑奖励的稀疏性和鲁棒性。
五、问题
1、动作空间大
强化学习中,如果动作空间太大,会给学习带来很多困难,例如计算复杂度高,泛化能力差,探索效率低等。针对这个问题,有一些解决方案,例如:
2、约束问题
(1)
在使用强化学习方法时,如果模型有约束,例如安全性、多样性、预算等,那么需要使用一些特殊的算法来处理这些约束,以免违反它们。0论文有一些方法可以处理这些约束,例如:
-
使用代理目标函数,将约束转化为奖励或惩罚的一部分,然后使用标准的强化学习算法来优化这个目标函数。1论文
-
使用截断的优势函数,限制策略更新的幅度,从而避免过度优化奖励而忽略约束。2
-
使用多目标强化学习,将约束视为额外的目标,然后使用一些方法来平衡或协调不同的目标。
-
使用无奖励强化学习,先学习环境的动态特性,然后根据约束来选择合适的策略。
-
正则化方法,通过在损失函数中加入对模型参数的约束,以避免模型过拟合的问题。常见的正则化方法包括L1正则化、L2正则化、Dropout正则化等。1
-
安全强化学习方法,通过在优化目标中加入安全约束,以保证模型在探索环境时不会产生危险或不可逆的行为。常见的安全强化学习方法包括惩罚法、屏障函数法、可信度集法等。2
-
偏好强化学习方法,通过从人类反馈中学习偏好函数,以代替或辅助奖励函数,从而实现更符合人类期望的优化目标。常见的偏好强化学习方法包括偏好查询法、偏好反馈法、偏好逆向强化学习法等。3
-
一种方法是将约束条件转化为惩罚项,加到目标函数中,形成一个无约束优化问题。这种方法的优点是简单易实现,缺点是需要调节惩罚系数,以平衡目标函数和约束条件的重要性。例如,( Achiam et al., 2017) 提出了一种基于惩罚项的安全强化学习算法1。
-
另一种方法是将约束条件作为一个辅助的目标函数,与主要的目标函数同时优化,形成一个多目标优化问题。这种方法的优点是可以同时考虑多个约束条件,缺点是需要定义一个合适的偏好函数,以平衡不同目标函数的权重。例如,( Tessler et al., 2018) 提出了一种基于多目标强化学习的约束满足算法2。
(2)详细点
强化学习是一种让智能体通过与环境交互来学习最优策略的方法。但是,在一些实际场景中,智能体的行为可能需要满足一些约束条件,比如安全性、可行性、成本等。这时,智能体的目标不仅是最大化奖励,还要避免违反约束1。
有一些方法可以处理强化学习中的约束问题,比如:
-
将约束问题转化为受限马尔可夫决策过程(Constrained Markov Decision Process,CMDP),在满足长期代价约束的条件下最大化长期奖励14。
-
使用原始对偶优化(Primal-Dual Optimization,PDO)或受限策略优化(Constrained Policy Optimization,CPO)等算法,在原始域和对偶域中交替更新策略参数和拉格朗日乘子14。
(3)对偶梯度
- 在强化学习中,对偶梯度可以用来优化带约束的目标函数,例如最大化累积奖励或者最小化轨迹代价。对偶梯度的基本思想是将原始问题转化为一个无约束的拉格朗日对偶问题,然后使用梯度上升法来更新拉格朗日乘子,同时使用其他优化方法来更新原始变量。这样可以交替地进行两种计算,直到收敛到最优解。
- 在强化学习中,一个常见的应用场景是轨迹优化问题,即给定一个初始状态和一个目标状态,找到一条最优的轨迹,使得轨迹代价最小。轨迹代价可以是轨迹长度、能量消耗、碰撞风险等。这个问题通常可以用以下形式表示:
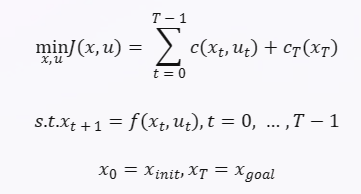
其中 x t xt xt 是状态变量, u t ut ut 是控制变量, c ( x t , u t ) c(xt,ut) c(xt,ut) 是每一步的代价函数, c T ( x T ) c_T(x_T) cT(xT) 是终端代价函数, f ( x t , u t ) f(xt,ut) f(xt,ut) 是状态转移函数, T T T 是轨迹长度, x i n i t x_{init} xinit 和 x g o a l x_{goal} xgoal 是初始状态和目标状态。
为了使用对偶梯度法求解这个问题,我们可以引入拉格朗日乘子 λ t λt λt 来处理等式约束,并定义拉格朗日函数:
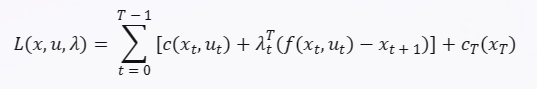

为了解决这些问题,一些研究者提出了对偶策略的概念,即同时使用两个策略来学习和探索:一个主策略和一个辅助策略。主策略是用来优化目标函数的,而辅助策略是用来提供探索信号的。对偶策略可以利用动作空间的结构信息,比如相似性、层次性或可分解性等,来提高学习效率和探索能力。对偶策略也可以利用对偶学习的思想,即通过最小化主策略和辅助策略之间的距离或散度来实现互相促进和约束。
对偶策略的具体实现方式有很多种,比如:
-
使用基于生成模型或逆强化学习的辅助策略来提供多样或有指导性的探索信号,从而提高动作空间的利用率 。
(4)学习率
如果平均约束大于目标约束,说明策略过于随机,需要减小学习率