模型无关学习
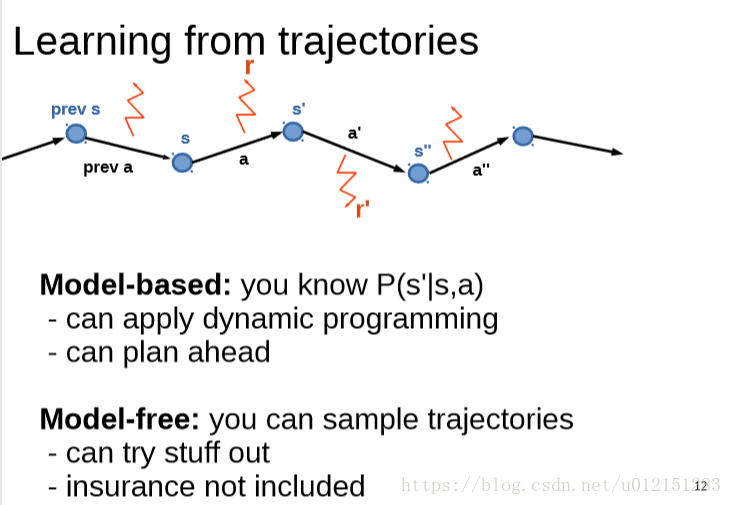
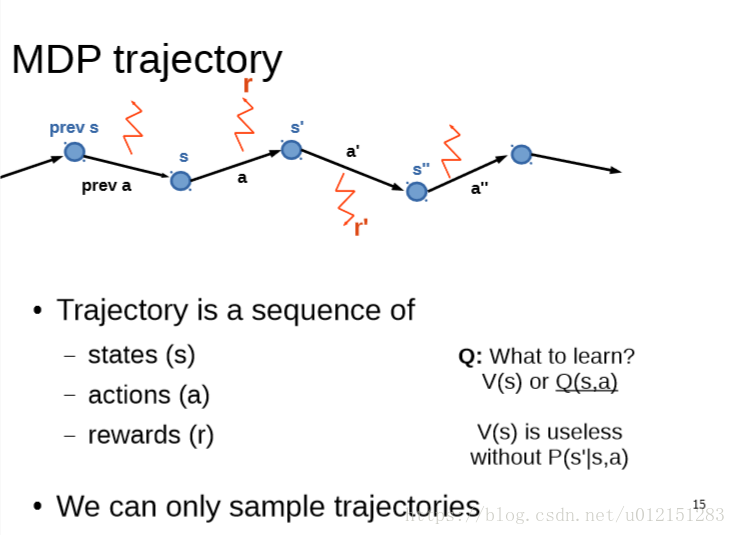
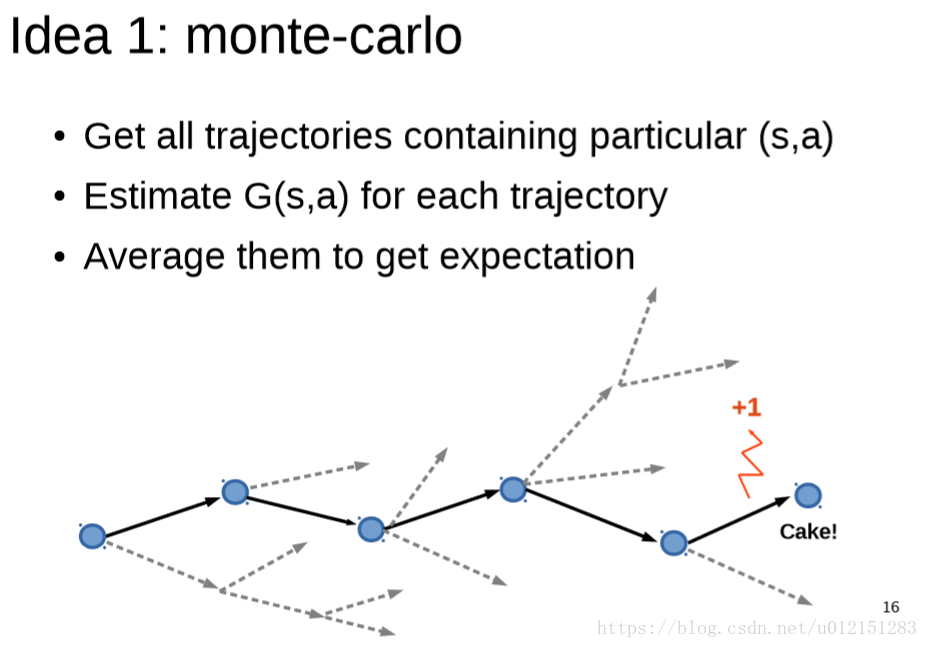
Monte-Carlo & Temporal Difference; Q-learning




探索与利用


on-policy 和 off-policy
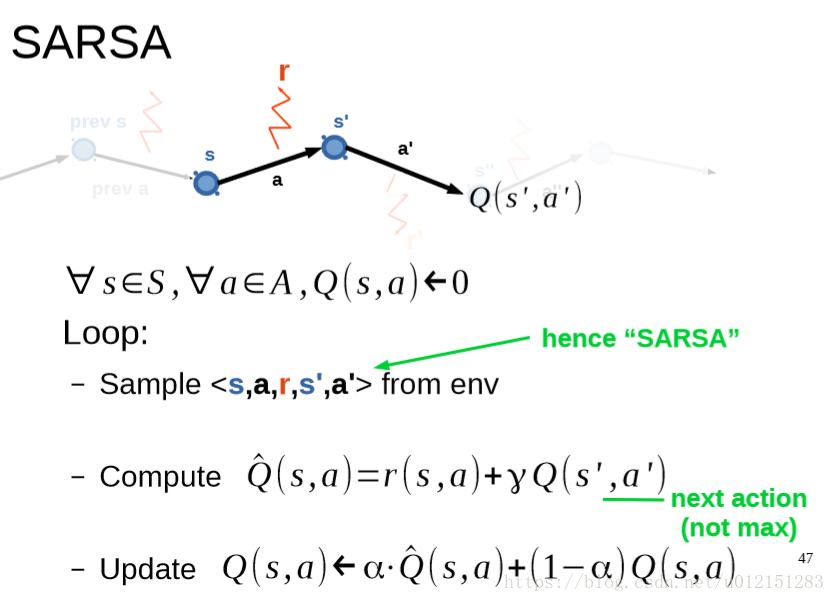
SARSA
Expected value SARSA
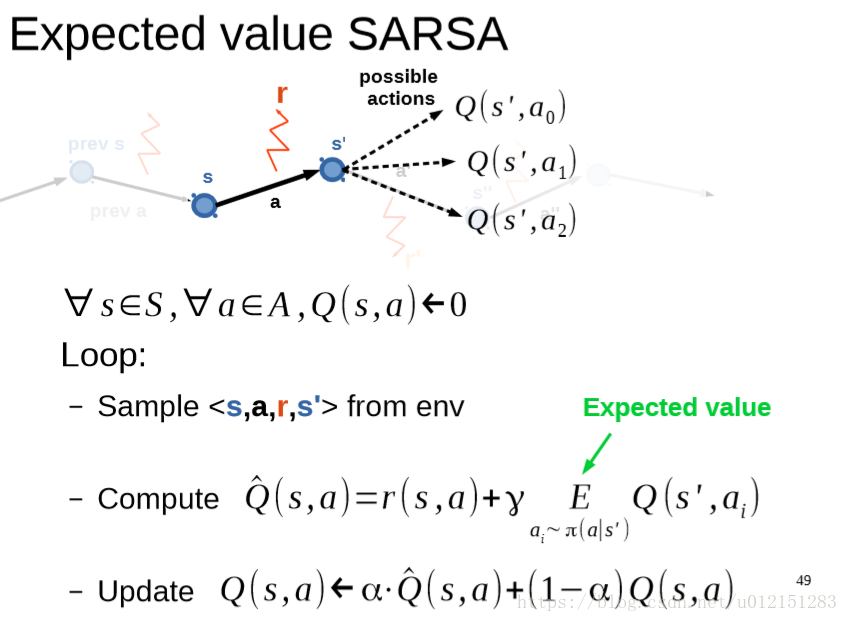
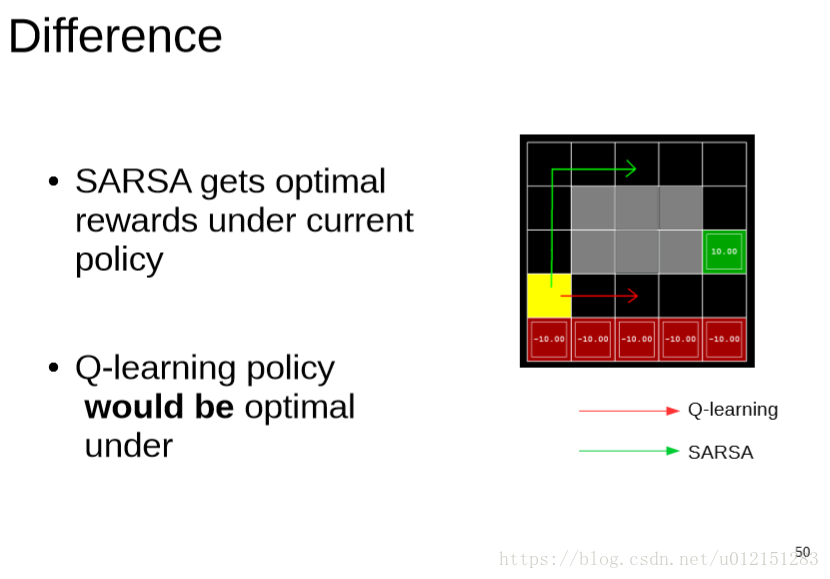
SARSA和Q-Learning对比
on-policy和off-policy对比
| on-policy | off-policy |
|---|---|
| Agent 可以选择动作 | Agent 不能 选择动作 |
| Most obvious setup | Learning with exploration,playing without exploration |
| Agent always follows his own policy | Learning from expert(expert is imperfect) |
| Learning from sessions(recorded data) | |
| can’t learn from off-policy | can learn from on-policy |
| SARSA | Q-learning |
| more… | Expected Value SARSA |
经验回放
略