智能体的目标是最大化期望累计奖励

我们把在时间t的回报定义为Gt,在t时间的时候智能体会选择动作At来使期望Gt最大化。通常智能体无法完全肯定地预测未来的奖励怎么样,他必须依赖于预测和估算
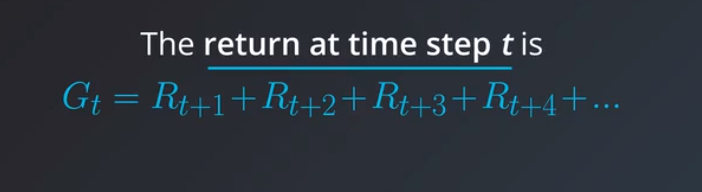
我们可以给公式乘上折扣率,来表示对未来回报的关注度,当gama靠近0表示只关注与眼前的利益,当gamma靠近1表示
对未来的回报和当前回报一样地注重。这在连续性任务中是十分重要滴,因为没有停止点,折扣率防止了智能体无限地关注未来的回报。


强化学习之奖励reward
猜你喜欢
转载自blog.csdn.net/weixin_43236007/article/details/89292596
今日推荐
周排行