DRL Lecture 7 – Sparse Reward – notes – Hung-yi Lee
深度强化学习中的奖励稀疏
To solve sparse reward problems, three directions:
1. Reward Shaping
环境有真正的reward,但自己设计额外的reward
Ex: for a child:
Take “Play”,
,
Take “Study”,
,
Design: Take “Study”,
Vizdoom: A First-person shooting game
 活着:-0.008(负数是为了强迫agent变得“好战”)
活着:-0.008(负数是为了强迫agent变得“好战”)
掉血:-0.05
弹药损失:-0.04
捡血:0.04
捡弹药:0.15
待在原地:-0.03
(参数是调出来的)
1.1 Curiosity
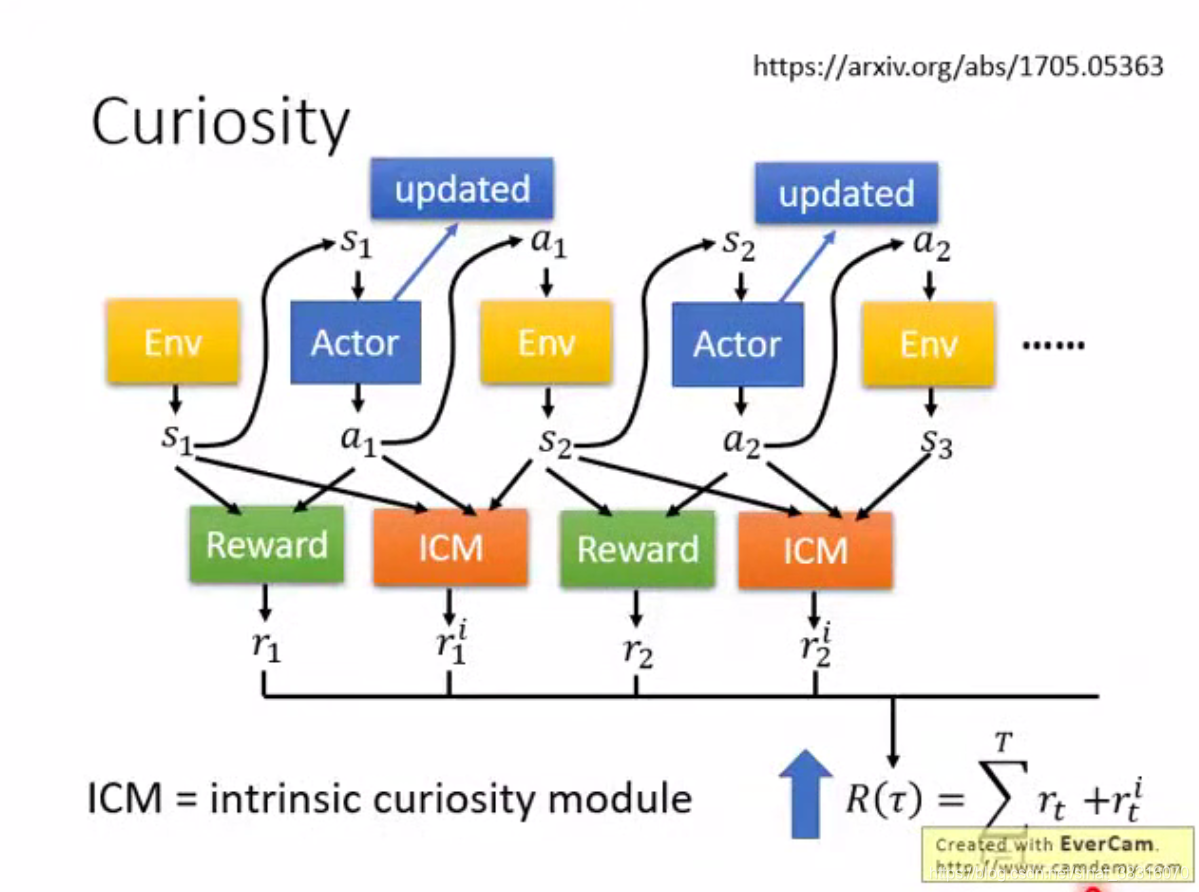 同时希望
,
越大越好
同时希望
,
越大越好
ICM = intrinsic curiosity module 代表着Curiosity
ICM的设计:
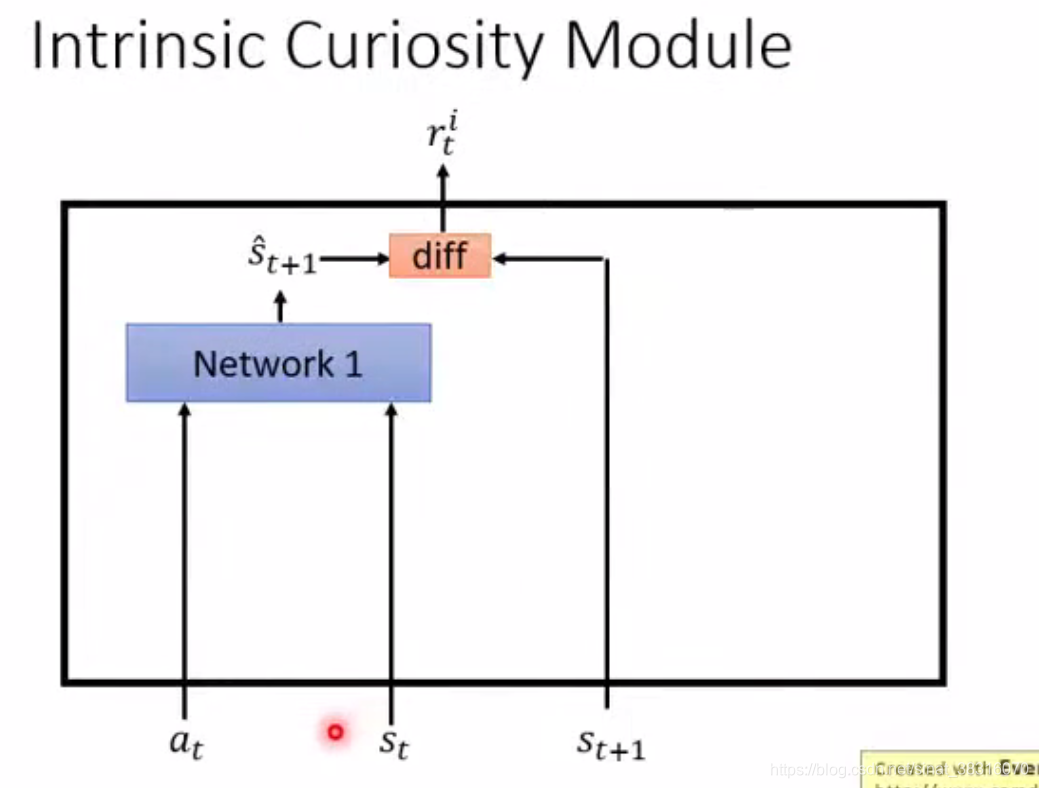 Input:
(现在的state),
(现在state采取的action),
(下一个state)
Input:
(现在的state),
(现在state采取的action),
(下一个state)
Output:
Network1: 根据
,
,预测下一个state:
(Network1是另外train出来的,apply到agent互动时,ICM会把它固定住)
diff: 真实的
与预测的
越不相似,奖励
越大
Large reward if
is hard to predict. => 鼓励冒险
问题:Some states is hard to predict, but not important.
只鼓励agent去冒险是不够的,要让agent知道什么是真正重要的。
引入: Feature Ext
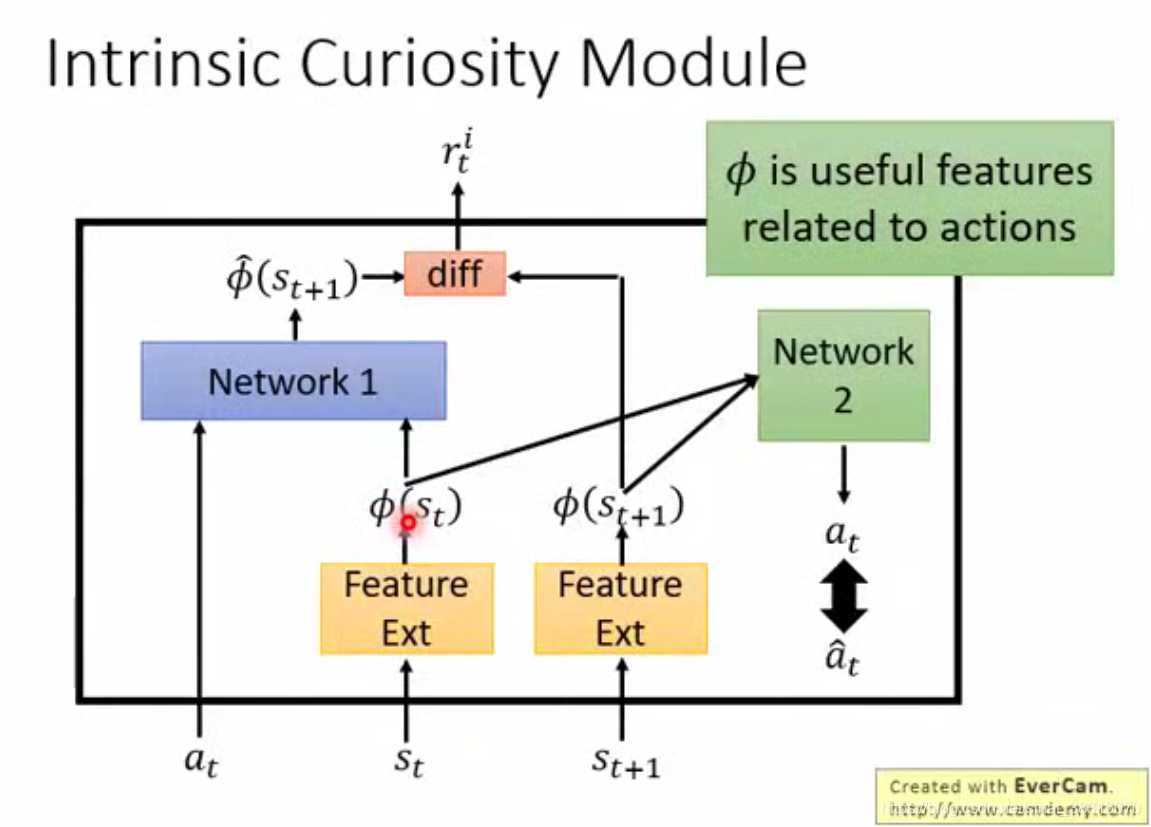 Feature Ext 作用是把无意义的画面state 过滤掉(例如,风吹草动)
Feature Ext 作用是把无意义的画面state 过滤掉(例如,风吹草动)
is useful features related to actions
Network2, 输入是
和
, 输出
, 与真实的动作
越接近越好,如果输出
与真实
无关,则滤掉这一画面。
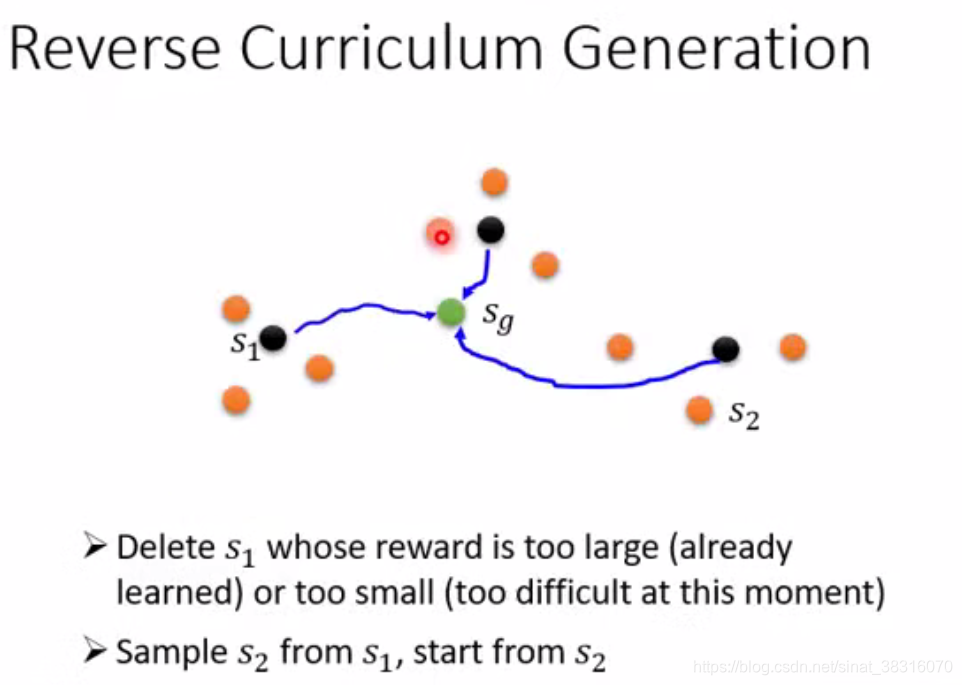
2. Curriculum Learning
为机器的学习做规划,顺序给予training data, 通常由易到难。
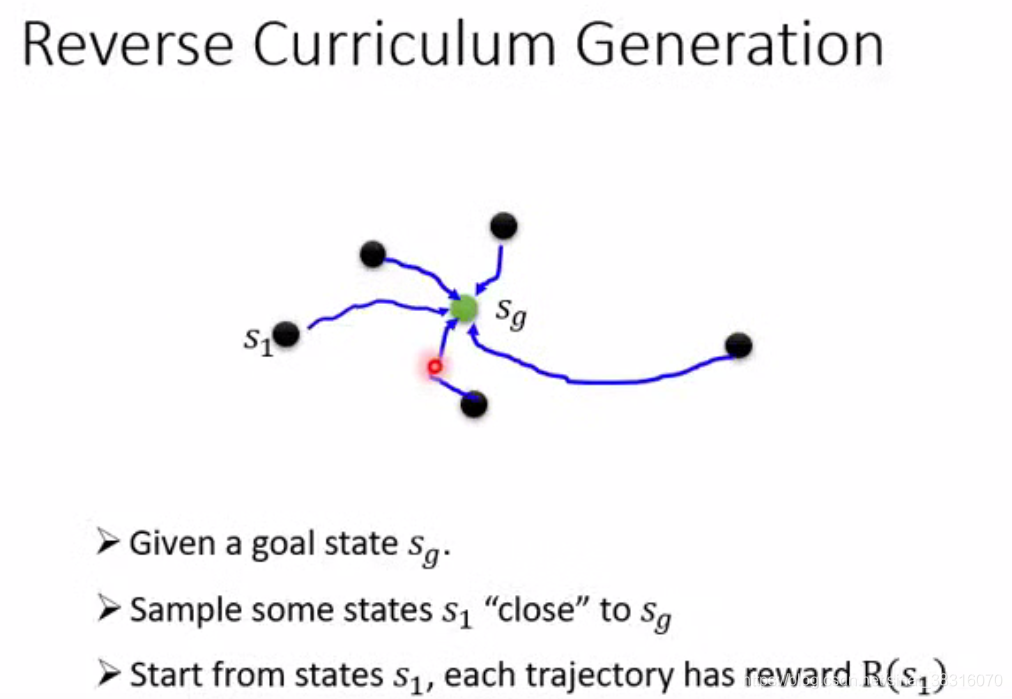
 Reverse Curriculum Generation
Reverse Curriculum Generation
3. Hierarchical Reinforcement Learning
阶层式强化学习:将大的task分解为小tasks
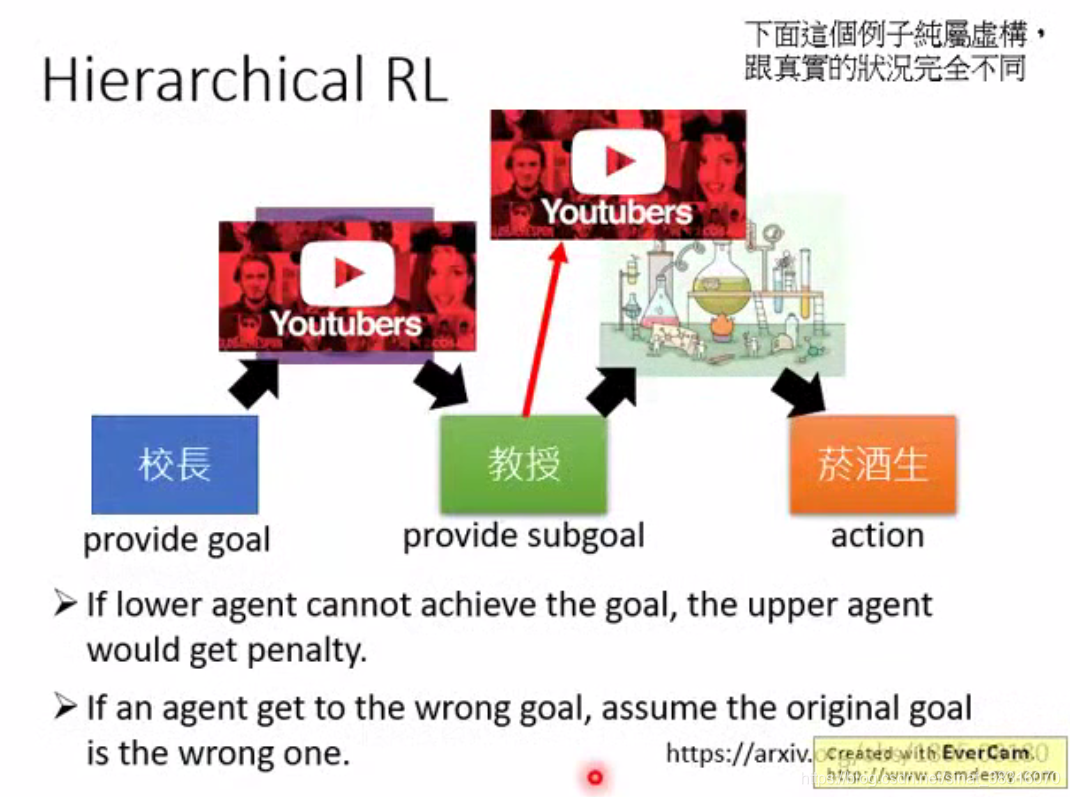
 粉红色代表 上层提出来的goal
粉红色代表 上层提出来的goal
