YOLOv7使用onnx导出成openvino模型,并调用接口进行摄像头推理预测
0.引言
OpenVINO是英特尔推出的一款全面的工具套件,用于快速部署应用和解决方案,支持计算机视觉的CNN网络结构超过200余种。openvino官方文档
本文将介绍使用yolov7+openvino在cpu上快速部署检测模型,如果还不会训练的朋友可以移步至另一篇博客:
YOLOv7系列教程:一、基于自定义数据集训练专属于自己的目标检测模型(保姆级教程,含数据集预处理),包含对train.py/test.py/detect.py/export.py详细说明
项目在github上开源,项目地址:yolov7_openvino_python
1.安装环境
进入自己的虚拟环境,使用pip快速安装,安装成功即可进入下一步:
pip install -r requirements.txt
安装完成截图:

2.转换模型
使用mo工具,可以快速将onnx中间模型导出成openvino模型,目前只试过p5的模型进行openvino部署,具体可以参考mo使用说明
mo --input_model weights/best.onnx --output_dir yolov7_openvino
–input_model是输入的onnx模型,路径改成自己的路径
–output_dir是输出文件夹,此时会生成一个yolov7_openvino文件夹 ,并将.xml/.bin/.mapping文件保存于此
转换完成截图:
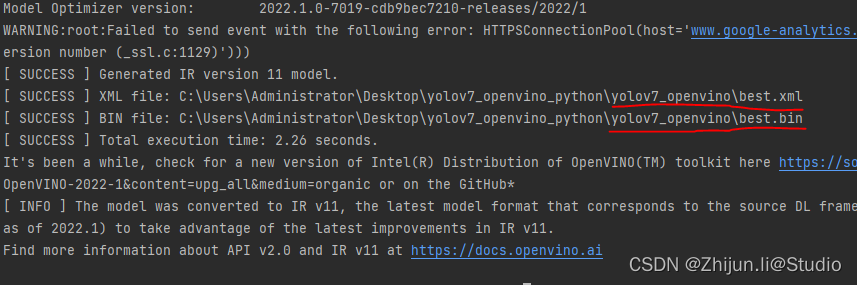
3.运行代码
先确保主机上有板载摄像头或者外接USB摄像头,运行如下命令即可:
python detect.py
运行成功截图:
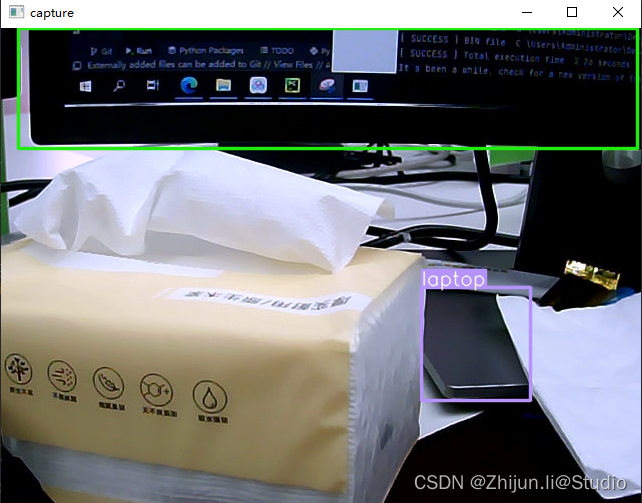
4.代码详情
(1)主代码
主要是配置变量,并且进行opencv读图循环
扫描二维码关注公众号,回复:
15871447 查看本文章

import os
import cv2
from model.yolov7 import YOLOV7_OPENVINO
if __name__ == "__main__":
class_list = [
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"
]
ov_name = "yolov7_openvino/best.xml"
ov_path = os.path.join(os.getcwd(), "model", ov_name)
yolov7_detector=YOLOV7_OPENVINO(class_list, ov_path)
cap = cv2.VideoCapture(0)
while True:
# get a frame
ret, frame = cap.read()
# infer
yolov7_detector.infer_image(frame)
# show a frame
cv2.imshow("capture", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
(2)yolov7_openvino版代码
from openvino.runtime import Core
import cv2
import numpy as np
import random
import time
from openvino.preprocess import PrePostProcessor, ColorFormat
from openvino.runtime import Layout, AsyncInferQueue, PartialShape
class YOLOV7_OPENVINO(object):
def __init__(self, class_list, model_path):
# set the hyperparameters
self.classes = class_list
self.batchsize = 1
self.grid = False
self.img_size = (640, 640)
self.conf_thres = 0.5
self.iou_thres = 0.6
self.class_num = len(self.classes)
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.classes]
self.stride = [8, 16, 32]
self.anchor_list = [[12, 16, 19, 36, 40, 28], [36, 75, 76, 55, 72, 146], [142, 110, 192, 243, 459, 401]]
self.anchor = np.array(self.anchor_list).astype(float).reshape(3, -1, 2)
area = self.img_size[0] * self.img_size[1]
device = 'CPU'
nireq = 2
self.size = [int(area / self.stride[0] ** 2), int(area / self.stride[1] ** 2), int(area / self.stride[2] ** 2)]
self.feature = [[int(j / self.stride[i]) for j in self.img_size] for i in range(3)]
ie = Core()
self.model = ie.read_model(model_path)
self.input_layer = self.model.input(0)
new_shape = PartialShape([self.batchsize, 3, self.img_size[0], self.img_size[1]])
self.model.reshape({
self.input_layer.any_name: new_shape})
self.pre_api = True
if (self.pre_api == True):
# Preprocessing API
ppp = PrePostProcessor(self.model)
# Declare section of desired application's input format
ppp.input().tensor() \
.set_layout(Layout("NHWC")) \
.set_color_format(ColorFormat.BGR)
# Here, it is assumed that the model has "NCHW" layout for input.
ppp.input().model().set_layout(Layout("NCHW"))
# Convert current color format (BGR) to RGB
ppp.input().preprocess() \
.convert_color(ColorFormat.RGB) \
.scale([255.0, 255.0, 255.0])
self.model = ppp.build()
print(f'Dump preprocessor: {
ppp}')
self.compiled_model = ie.compile_model(model=self.model, device_name=device)
self.infer_queue = AsyncInferQueue(self.compiled_model, nireq)
def letterbox(self, img, new_shape=(640, 640), color=(114, 114, 114)):
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - \
new_unpad[1] # wh padding
# divide padding into 2 sides
dw /= 2
dh /= 2
# resize
if shape[::-1] != new_unpad:
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# add border
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color)
return img
def xywh2xyxy(self, x):
# Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def nms(self, prediction, conf_thres, iou_thres):
predictions = np.squeeze(prediction[0])
# Filter out object confidence scores below threshold
obj_conf = predictions[:, 4]
predictions = predictions[obj_conf > conf_thres]
obj_conf = obj_conf[obj_conf > conf_thres]
# Multiply class confidence with bounding box confidence
predictions[:, 5:] *= obj_conf[:, np.newaxis]
# Get the scores
scores = np.max(predictions[:, 5:], axis=1)
# Filter out the objects with a low score
valid_scores = scores > conf_thres
predictions = predictions[valid_scores]
scores = scores[valid_scores]
# Get the class with the highest confidence
class_ids = np.argmax(predictions[:, 5:], axis=1)
# Get bounding boxes for each object
boxes = self.xywh2xyxy(predictions[:, :4])
# Apply non-maxima suppression to suppress weak, overlapping bounding boxes
# indices = nms(boxes, scores, self.iou_threshold)
indices = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), conf_thres, iou_thres)
return boxes[indices], scores[indices], class_ids[indices]
def clip_coords(self, boxes, img_shape):
# Clip bounding xyxy bounding boxes to image shape (height, width)
boxes[:, 0].clip(0, img_shape[1]) # x1
boxes[:, 1].clip(0, img_shape[0]) # y1
boxes[:, 2].clip(0, img_shape[1]) # x2
boxes[:, 3].clip(0, img_shape[0]) # y2
def scale_coords(self, img1_shape, img0_shape, coords, ratio_pad=None):
# Rescale coords (xyxy) from img1_shape to img0_shape
# gain = old / new
if ratio_pad is None:
gain = min(img1_shape[0] / img0_shape[0],
img1_shape[1] / img0_shape[1])
padding = (img1_shape[1] - img0_shape[1] * gain) / \
2, (img1_shape[0] - img0_shape[0] * gain) / 2
else:
gain = ratio_pad[0][0]
padding = ratio_pad[1]
coords[:, [0, 2]] -= padding[0] # x padding
coords[:, [1, 3]] -= padding[1] # y padding
coords[:, :4] /= gain
self.clip_coords(coords, img0_shape)
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def plot_one_box(self, x, img, color=None, label=None, line_thickness=None):
# Plots one bounding box on image img
tl = line_thickness or round(
0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(
label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3,
[225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def draw(self, img, boxinfo):
for i, (xyxy, conf, cls) in enumerate(boxinfo):
self.plot_one_box(xyxy, img, label=self.classes[int(cls)], color=self.colors[int(cls)], line_thickness=2)
# cv2.putText()
print(i)
# cv2.imshow('Press ESC to Exit', img)
# cv2.waitKey(1)
def postprocess(self, infer_request, info):
t3 = time.time()
src_img_list, src_size = info
for batch_id in range(self.batchsize):
if self.grid:
results = np.expand_dims(infer_request.get_output_tensor(0).data[batch_id], axis=0)
else:
output = []
# Get the each feature map's output data
output.append(self.sigmoid(infer_request.get_output_tensor(0).data[batch_id].reshape(-1, self.size[0]*3, 5+self.class_num)))
output.append(self.sigmoid(infer_request.get_output_tensor(1).data[batch_id].reshape(-1, self.size[1]*3, 5+self.class_num)))
output.append(self.sigmoid(infer_request.get_output_tensor(2).data[batch_id].reshape(-1, self.size[2]*3, 5+self.class_num)))
# Postprocessing
grid = []
for _, f in enumerate(self.feature):
grid.append([[i, j] for j in range(f[0]) for i in range(f[1])])
result = []
for i in range(3):
src = output[i]
xy = src[..., 0:2] * 2. - 0.5
wh = (src[..., 2:4] * 2) ** 2
dst_xy = []
dst_wh = []
for j in range(3):
dst_xy.append((xy[:, j * self.size[i]:(j + 1) * self.size[i], :] + grid[i]) * self.stride[i])
dst_wh.append(wh[:, j * self.size[i]:(j + 1) *self.size[i], :] * self.anchor[i][j])
src[..., 0:2] = np.concatenate((dst_xy[0], dst_xy[1], dst_xy[2]), axis=1)
src[..., 2:4] = np.concatenate((dst_wh[0], dst_wh[1], dst_wh[2]), axis=1)
result.append(src)
results = np.concatenate(result, 1)
boxes, scores, class_ids = self.nms(results, self.conf_thres, self.iou_thres)
img_shape = self.img_size
self.scale_coords(img_shape, src_size, boxes)
# Draw the results
self.draw(src_img_list[batch_id], zip(boxes, scores, class_ids))
t4 = time.time()
print(f"post time{
(t4-t3)*1000}")
def infer_image(self, src_img):
src_img_list = []
src_img_list.append(src_img)
img = self.letterbox(src_img, self.img_size)
src_size = src_img.shape[:2]
img = img.astype(dtype=np.float32)
if (self.pre_api == False):
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # BGR to RGB
img /= 255.0
img.transpose(2, 0, 1) # NHWC to NCHW
input_image = np.expand_dims(img, 0)
# Set callback function for postprocess
self.infer_queue.set_callback(self.postprocess)
# Do inference
self.infer_queue.start_async({
self.input_layer.any_name: input_image}, (src_img_list, src_size))
self.infer_queue.wait_all()