Advantage Actor-Critic (A2C)
- Policy network (actor): π ( a ∣ s ; θ ) \pi(a|s; \theta) π(a∣s;θ)
\; It is an approximation to the policy function, π ( a ∣ s ) \pi(a|s) π(a∣s).
\; It controls the agent. - Value network (critic): v ( s ; w ) v(s;w) v(s;w)
\; It is an approximation to the state-value function, V π ( s ) V_{\pi}(s) Vπ(s).
\; It evaluates how good the state s s s is.
注意:A2C与AC不一样,AC里面用的是动作价值Q,A2C用的是状态价值V。动作价值Q依赖于状态s和动作a,而状态价值v只依赖于状态s,所以V比Q更好训练。
A2C的策略和价值网络输入都是状态s。策略网络输出的是各动作的概率,agent执行的动作就是从这里面抽样出来的;价值网络的输出为一个实数,它可以评价当前状态的好坏。两个网络用的架构一样,区别在于如何训练这两个网络。

Training of A2C
- Observe a transition ( s t , a t , r r , s t + 1 s_t,a_t,r_r,s_{t+1} st,at,rr,st+1).
- TD target: y t = r t + γ ⋅ v ( s t + 1 ; w ) y_t=r_{t}+\gamma·v(s_{t+1};w) yt=rt+γ⋅v(st+1;w).
- TD error: δ t = v ( s t ; w ) − y t \delta_t=v(s_t;w)-y_t δt=v(st;w)−yt.
- Update the policy network (actor) by:
θ ⟵ θ − β ⋅ δ t ⋅ ∂ l n π ( a t ∣ s t ; θ ) ∂ θ . \theta \longleftarrow\theta-\beta·\delta_t·\frac{\partial ln\pi(a_t|s_t;\theta)}{\partial\theta}. θ⟵θ−β⋅δt⋅∂θ∂lnπ(at∣st;θ). - Update the value network (critic) by:
w ⟵ w − α ⋅ δ t ⋅ ∂ v ( s t ; w ) ∂ w . w \longleftarrow w-\alpha·\delta_t·\frac{\partial v(s_t;w)}{\partial w}. w⟵w−α⋅δt⋅∂w∂v(st;w).
Approximate Policy Gradient
g ( a t ) ≈ ∂ l n π ( a t ∣ s t ; θ ) ∂ θ ⋅ ( r t + γ ⋅ v ( s t + 1 ; w ) − v ( s t ; w ) ) . g(a_t) \approx\frac{\partial ln\pi(a_t|s_t;\theta)}{\partial\theta}·(r_t+\gamma·v(s_{t+1};w)-v(s_t;w)). g(at)≈∂θ∂lnπ(at∣st;θ)⋅(rt+γ⋅v(st+1;w)−v(st;w)).
- ( r t + γ ⋅ v ( s t + 1 ; w ) (r_t+\gamma·v(s_{t+1};w) (rt+γ⋅v(st+1;w) depends on a t a_t at
- v ( s t ; w ) v(s_t;w) v(st;w) independent of a t a_t at
- If a t a_t at is good, v ( s t + 1 ; w ) v(s_{t+1};w) v(st+1;w) is biger than v ( s t ; w ) v(s_t;w) v(st;w), so their difference (TD-error) is positive.
- their difference (TD-error) is called as advantage, which be evaluated by the critic. And it can be used to teach policy network to update.
Procedure

策略网络也叫actor,它根据状态s,来计算动作a的概率分布,从而控制agent。
agent与环境交互,执行动作a后,环境会做状态转移,给出新的状态。

我们还需要价值网络来评价动作a的好坏,价值网络被称为critic,价值网络会评估相邻两个状态,从而得出动作a带来的Advantage,价值网络会把优势告诉策略网络。
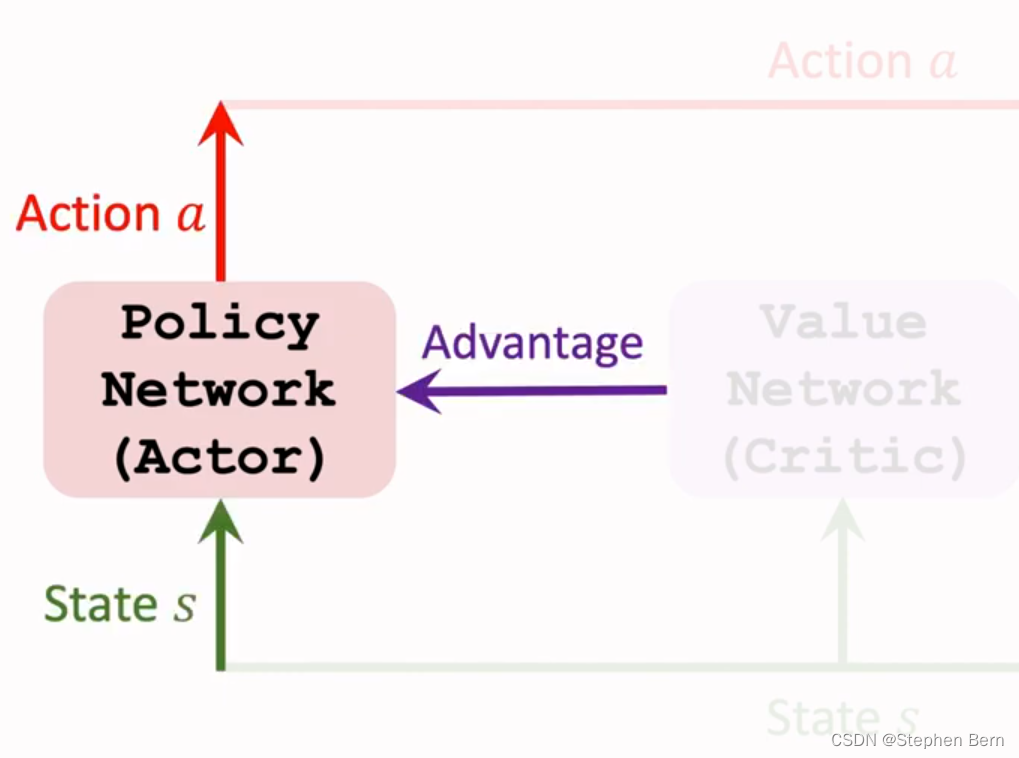
训练策略网络,要用到状态s、动作a、以及价值网络提供的Advantage。用策略梯度来更新策略网络中的 θ \theta θ,让策略网络做出的动作越来越好。
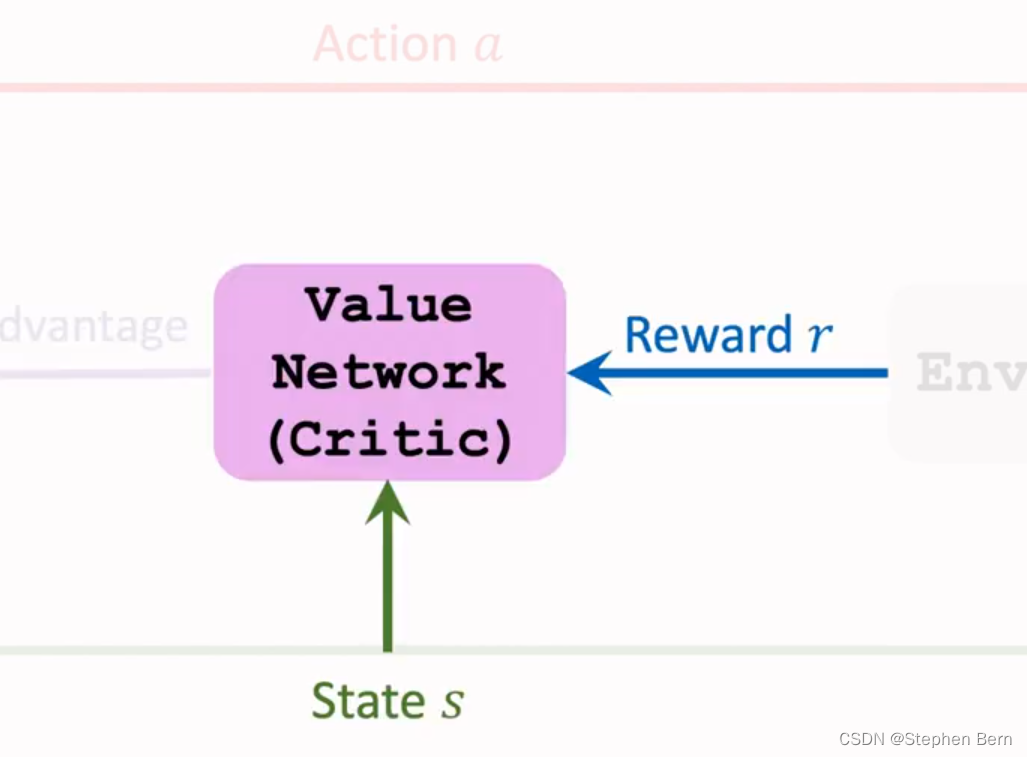
训练价值网络要用到状态s和奖励r,用TD算法更新价值网络中的w,让价值网络对状态价值的预测越来越准。